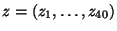|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Дифференциальные уравнения с разделяющимися переменнымиСтр 1 из 6Следующая ⇒
Дифференциальные уравнения с разделяющимися переменными Дифференциальное уравнение вида
или
называется дифференциальным уравнением с разделяющимися переменными. Заметим, что в данных дифференциальных уравнениях каждая из функций зависит только от одной переменной, т.е. происходит разделение переменных. Для решения такого дифференциального уравнения необходимо домножить или разделить обе части дифференциального уравнения на такое выражение, чтобы в одну часть уравнения входили только функции от
Следует заметить, что при делении обеих частей дифференциального уравнения на выражение, содержащее неизвестные Обратим внимание, что дифференциальные уравнения с разделяющимися переменными легко сводятся к интегрированию. В общем случае получаем получаем два неопределенных интеграла. Пример 1 - решить дифференциальное уравнение Заметим, что в дифференциальном уравнении можно разделить переменные, т.е. получаем, дифференциальное уравнение с разделяющимися переменными.
Однородные!
Решить дифференциальное уравнение Решение: В данном примере переменные разделить нельзя (можете попробовать поперекидывать слагаемые из части в часть, повыносить множители за скобки и т.д.). Кстати, в данном примере, тот факт, что переменные разделить нельзя, достаточно очевиден ввиду наличия множителя Возникает вопрос – как же решить этот диффур? Нужно проверить, а не является ли данное уравнение однородным? Проверка несложная, и сам алгоритм проверки можно сформулировать так: В исходное уравнение: вместо
Буква лямбда – это некоторый абстрактный числовой параметр, дело не в самих лямбдах, и не в их значениях, а дело вот в чём: Если в результате преобразований удастся сократить ВСЕ «лямбды» (т.е. получить исходное уравнение), то данное дифференциальное уравнение является однородным. Очевидно, что лямбды сразу сокращаются в показателе степени: Обе части уравнения можно сократить на эту самую лямбду: В результате все лямбды исчезли как сон, как утренний туман, и мы получили исходное уравнение. Вывод: Данное уравнение является однородным Поначалу рекомендую проводить рассмотренную проверку на черновике, хотя очень скоро она будет получаться и мысленно. В 19-ти случаях из 20-ти решение однородного уравнения записывают в виде общего интеграла. Ответ: общий интеграл:
ОДНОРОДНЫЕ ЛИНЕЙНЫЕ ДИФФЕРЕНЦИАЛЬНЫЕ УРАВНЕНИЯ ВТОРОГО ПОРЯДКА С ПОСТОЯННЫМИ КОЭФИЦИЕНТАМИ. 6-
Элементарное событие В теории вероятностей элементарные события или события-атомы — это исходы случайного эксперимента, из которых в эксперименте происходит ровно один. Множество всех элементарных событий обычно обозначается Всякое подмножество множества В определении вероятностного пространства на множестве случайных событий вводится сигма-аддитивная конечная мера, называемая вероятностью. Элементарные события могут иметь вероятности, которые строго положительны, нули, неопределенны, или любая комбинация из этих вариантов. Например, любое дискретноевероятностное распределение определяется вероятностями того, что может быть названо элементарными событиями. Напротив, все элементарные события имеют вероятность нуль длянепрерывного распределения. Смешанные распределения, не будучи ни непрерывными, ни дискретными, могут содержать атомы, которые могут мыслиться как элементарные (то естьсобытия-атомы) события с ненулевой вероятностью. В теории меры в определении вероятностного пространства вероятность произвольного элементарного события не могла быть определена до тех пор, пока математики не увидели различие между пространством исходов S и событиями, которые представляют интерес, и которые определяются как элементы σ -алгебры событий из S. Формально говоря, элементарное событие — это подмножество пространства исходов случайного эксперимента, которое состоит только из одного элемента; то есть элементарное событие — это всё ещё множество, но не сам элемент. Однако элементарные события обычно записываются как элементы, а не как множества с целью упрощения, когда это не может вызвать недоразумения. Примеры Примеры пространств исходов эксперимента, § Если объекты счётны, а пространство исходов § Если монета бросается дважды, § Если Случа́ йное собы́ тие — подмножество множества исходов случайного эксперимента; при многократном повторении случайного эксперимента частота наступления события служит оценкой его вероятности. Случайное событие, которое никогда не реализуется в результате случайного эксперимента, называется невозможным и обозначается символом Аксиоматическое определение вероятности. Пусть задано пространство элементарных событий Е и каждому событию А
Тогда говорят, что на событиях в множестве Е задана вероятность, а число Р ( А ) называется вероятностью события А. Аксиоматическое определение вероятности. Def: говорят, что на алгебре событий F задана вероятность. Распределение вероятностей, если каждому событию 1) 2) 3) Если A1…Ak попарно несовместны, то вероятность их суммы равна сумме вероятностей. Поскольку Следовательно, Доказательство Так как в результате Обозначим
При этом вероятность каждой комбинации равна произведению вероятностей:
Применяя теорему сложения вероятностей несовместных событий, получим окончательную Формулу Бернулли:
14 – ДИСКРЕТНЫЕ СЛУЧАЙНЫЕ ВЕЛИЧИНЫ. ФУНКЦИЯ РАСПРЕДЕЛЕНИЯ, ЕЕ СВОЙСТВА. Реальное содержание понятия « случайная величина » может быть выражено с помощью такого определения: случайной величиной, связанной с данным опытом, называется величина, которая при каждом осуществлении этого опыта принимает то или иное числовое значение, причем заранее неизвестно, какое именно. Случайные величины будем обозначать буквами Определение. Говорят, что задана дискретная случайная величина
и каждому из этих чисел
Числа Таблица
называется законом распределения дискретной случайной величины Для наглядности закон распределения дискретной случайной величины изображают графически, для чего в прямоугольной системе координат строят точки Если возможными значениями дискретной случайной величины
ОПРЕДЕЛЕНИЕ. Законом распределения дискретной случайной величины называют соответствие между возможными значениями и их вероятностями; его можно задать таблично, аналитически (в виде формулы) и графически. При табличном задании закона распределения дискретной случайной величины первая строка таблицы содержит возможные значения, а вторая – их вероятности:
Пример 2. В денежной лотерее выпущено 100 билетов. Разыгрывается один выигрыш в 50 тыс. тенге и десять выигрышей по 1тыс. тенге. Найти закон распределения случайных величин Х- стоимости возможного выигрыша для владельца одного лотерейного билета. Решение: Напишем возможные значения х: х1=50, х2=1, х3=0. Вероятности этих возможных значений таковы: Р1=1/100=0, 01, Р2=10/100=0, 1, Р3=89/100=0, 89. Напишем искомый закон распределения:
Контроль: 0, 01+0, 1+0, 89=1. НЕРАВЕНСТВО ЧЕБЫШЕВА
Рассмотрим сначала вспомогательные теоремы: лемму и неравенство Чебышева, с помощью которых легко доказывается закон больших чисел в форме Чебышева. Лемма (Чебышев). Если среди значений случайной величины Х нет отрицательных, то вероятность того, что она примет какое-нибудь значение, превосходящее положительное число А, не больше дроби, числитель которой — математическое ожидание случайной величины, а знаменатель - число А:
Доказательство. Пусть известен закон распределения случайной величины Х:
По отношению к числу А значения случайной величины разбиваются на две группы: одни не превосходят А, а другие больше А. Предположим, что к первой группе относятся первые
Так как
Поскольку
то
Далее,
что и требовалось доказать. Случайные величины могут иметь различные распределения при одинаковых математических ожиданиях. Однако для них лемма Чебышева даст одинаковую оценку вероятности того или иного результата испытания. Этот недостаток леммы связан с ее общностью: добиться лучшей оценки сразу для всех случайных величин невозможно.
Неравенство Чебышева. Вероятность того, что отклонение случайной величины от ее математического ожидания превзойдет по абсолютной величине положительное число
Доказательство. Поскольку
Далее:
что и требовалось доказать.
Следствие. Поскольку
и
то
Примем без доказательства факт, что лемма и неравенство Чебышева верны и для непрерывных случайных величин. Неравенство Чебышева лежит в основе качественных и количественных утверждений закона больших чисел. Оно определяет верхнюю границу вероятности того, что отклонение значения случайной величины от ее математического ожидания больше некоторого заданного числа. Замечательно, что неравенство Чебышева дает оценку вероятности события для случайной величины, распределение которой неизвестно, известны лишь ее математическое ожидание и дисперсия.
Теорема. (Закон больших чисел в форме Чебышева) Если дисперсии независимых случайных величин
Теорему примем без доказательства. Следствие 1. Если независимые случайные величины имеют одинаковые, равные
То, что за приближенное значение неизвестной величины принимают среднюю арифметическую результатов достаточно большого числа ее измерений, произведенных в одних и тех же условиях, можно обосновать этой теоремой. Действительно, результаты измерений являются случайными, так как на них действует очень много случайных факторов. Отсутствие систематических ошибок означает, что математические ожидания отдельных результатов измерений одинаковые и равны (Напомним, что ошибки называются систематическими, если они искажают результат измерения в одну и ту же сторону по более или менее ясному закону. К ним относятся ошибки, появляющиеся в результате несовершенства инструментов (инструментальные ошибки), вследствие личных особенностей наблюдателя (личные ошибки) и др.)
Следствие 2. (Теорема Бернулли.) Если вероятность
Теорема Бернулли, утверждает, что если вероятность события одинакова во всех испытаниях, то с увеличением числа испытаний частота события стремится к вероятности события и перестает быть случайной.
На практике сравнительно редко встречаются опыты, в которых вероятность появления события в любом опыте неизменна, чаще она разная в разных опытах. К схеме испытаний такого типа относится теорема Пуассона: Следствие 3. (Теорема Пуассона.) Если вероятность
Теорема Пуассона утверждает, что частота события в серии независимых испытаний стремится к среднему арифметическому его вероятностей и перестает быть случайной. В заключение заметим, что ни одна из рассмотренных теорем не дает ни точного, ни даже приближенного значения искомой вероятности, а указывается лишь нижняя или верхняя граница ее. Поэтому, если требуется установить точное или хотя бы приближенное значение вероятностей соответствующих событий, возможности этих теорем весьма ограничены. Приближенные значения вероятностей при больших значениях Теоретическое значение теоремы Чебышева, являющейся весьма общей формулировкой закона больших чисел, велико. Однако если мы будем применять ее при решении вопроса о возможности применить закон больших чисел к последовательности независимых случайных величин, то при утвердительном ответе теорема часто будет требовать, чтобы случайных величин было гораздо больше, чем необходимо для вступления в силу закона больших чисел. Указанный недостаток теоремы Чебышева объясняется общим характером ее. Поэтому желательно иметь теоремы, которые точнее указывали бы нижнюю (или верхнюю) границу искомой вероятности. Их можно получить, если наложить на случайные величины некоторые дополнительные ограничения, которые для встречающихся на практике случайных величин обычно выполняются.
26 – ВЫБОРОЧНАЯ СРЕДНЯЯ И ВЫБОРОЧНАЯ ДИСПЕРСИЯ Иногда исследователь ставит перед собой более конкретную проблему: как, основываясь на выборке, оценить интересующие его числовые характеристики неизвестного распределения, не прибегая к приближению этого распределения как такового, то есть без построения выборочных функций распределения, гистограмм и т.п. В данном параграфе мы обсудим простые (но, как увидим в дальнейшем, весьма хорошие) выборочные аппроксимации для математического ожидания и дисперсии. Замечательно то, что они применимы в очень общей ситуации. Мы будем предполагать, что независимая выборка Определение 6.2 Величины, вычисляемые по выборке,
и
называются выборочным средним и выборочной дисперсией. Следует особо подчеркнуть, что определенные выше величины зависят только от выборки. Следующее предложение объясняет, почему естественно считать Предложение 6.1 Математические ожидания
Дисперсия Доказательство. Используя линейность математического ожидания, получим
Так как выборка независимая, то Покажем теперь, что
Теперь, проводя очевидные преобразования и применяя свойства математического ожидания, легко получаем необходимое утверждение
Это утверждение свидетельствует о том, что Замечание 6.4 Для оценивания дисперсии по выборке может быть использована также функция
Формально ее можно получить, заменив в определении дисперсии Предложение 6.2 При росте объема выборки
Доказательство. Как и при доказательстве Предложения 6.1 без ограничения общности будем считать, что
Применяя закон больших чисел в форме Хинчина к последовательности
В силу предположения
Замечание 6.5 Здесь мы воспроизводим замечание о вычислениях, приведенное в [12, с. 116]. Из соотношения (33) вытекает следующее представление для
Математически формулы (30) и (34) дают одно и то же значение. Но, если нам необходимовручную вычислить выборочную дисперсию, то следует это делать только по формуле (30), так как вычисления по формуле (34) потребовали бы учета намного большего числа значащих цифр, чем в случае применения формулы (30). Имеется большое число практически важных приемов, призванных облегчить вычислительную работу с конкретными числовыми выборками. Для знакомства с ними рекомендуем читателю обратиться к книге [11]. В настоящее время существует много прикладных компьютерных программ, которые можно и нужно использовать для обработки числовых данных. С некоторыми наиболее популярными специализированными статистическими пакетами (Stadia, StatGraphics) можно познакомиться по книге [13], к которой также приводится их сравнение. Для статистической обработки небольших массивов данных вполне подойдет любой хороший универсальный математический пакет (Mathematica, Maple, Matlab). Пример 6.5 Вычислим выборочное среднее и выборочную дисперсию для числовых данных Примера 6.4 на странице
и для выборки
Полезной величиной является также корень из выборочной дисперсии как оценка среднеквадратичного уклонения:
27 – Интервальная оценка параметров распределения. Доверительный интервал. Сущность задачи интервального оценивания параметров Интервальный метод оценивания параметров распределения случайных величин заключается в определении интервала (а не единичного значения), в котором с заданной степенью достоверности будет заключено значение оцениваемого параметра. Интервальная оценка характеризуется двумя числами – концами интервала, внутри которого предположительно находится истинное значение параметра. Иначе говоря, вместо отдельной точки для оцениваемого параметра можно установить интервал значений, одна из точек которого является своего рода " лучшей" оценкой. Интервальные оценки являются более полными и надежными по сравнению с точечными, они применяются как для больших, так и для малых выборок. Совокупность методов определения промежутка, в котором лежит значение параметра Т, получила название методов интервального оценивания. К их числу принадлежит метод Неймана. Постановка задачи интервальной оценки параметров заключается в следующем [3, 11]. Имеется: выборка наблюдений (x1, x2, …, xn) за случайной величиной Х. Объем выборки n фиксирован. Необходимо с доверительной вероятностью g = 1– a определить интервал t0 – t1 (t0 < t1), который накрывает истинное значение неизвестного скалярного параметра Т(здесь, как и ранее, величина Т является постоянной, поэтому некорректно говорить, что значение Т попадает в заданный интервал). Ограничения: выборка представительная, ее объем достаточен для оценки границ интервала. |
Последнее изменение этой страницы: 2017-03-14; Просмотров: 393; Нарушение авторского права страницы

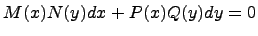
 и
и  , в другую часть уравнения - только функции от
, в другую часть уравнения - только функции от  ,
,  . Затем в полученном дифференциальном уравнении надо проинтегрировать обе части:
. Затем в полученном дифференциальном уравнении надо проинтегрировать обе части: 
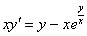
 .
. подставляем
подставляем  , вместо
, вместо  подставляем
подставляем 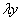 , производную не трогаем:
, производную не трогаем: 



 .
.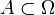 , если (элементарный) исход эксперимента является элементом
, если (элементарный) исход эксперимента является элементом  .
. (натуральные числа), то элементарные события — это любые множества
(натуральные числа), то элементарные события — это любые множества  , где
, где  .
. ,
, 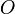 для орла, а
для орла, а  для решки, то элементарные события:
для решки, то элементарные события: 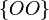 ,
,  ,
, 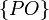 и
и  .
. — это нормально распределенные случайные величины,
— это нормально распределенные случайные величины, 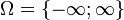 , реальные числа, то элементарные события — любые множества
, реальные числа, то элементарные события — любые множества  , где
, где  . Этот пример показывает, что непрерывное вероятностное распределение не определяется вероятностями событий-атомов, поскольку здесь вероятности всех элементарных событий равны нулю.
. Этот пример показывает, что непрерывное вероятностное распределение не определяется вероятностями событий-атомов, поскольку здесь вероятности всех элементарных событий равны нулю. . Случайное событие, которое всегда реализуется в результате случайного эксперимента, называется достоверным и обозначается символом
. Случайное событие, которое всегда реализуется в результате случайного эксперимента, называется достоверным и обозначается символом  Е поставлено в соответствие единственное число Р ( А ) такое, что:
Е поставлено в соответствие единственное число Р ( А ) такое, что: 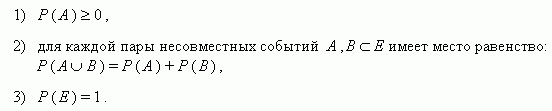
 поставлено в соответствие число Р(А), называют вероятностью события А так, что выполнены аксиомы:
поставлено в соответствие число Р(А), называют вероятностью события А так, что выполнены аксиомы: 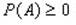

 , то
, то 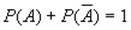 .
. .
. независимых испытаний, проведенных в одинаковых условиях, событие
независимых испытаний, проведенных в одинаковых условиях, событие  , следовательно противоположное ему событие с вероятностью
, следовательно противоположное ему событие с вероятностью  .
. — наступление события
— наступление события  . Так как условия проведения опытов одинаковые, то эти вероятности равны. Пусть в результате
. Так как условия проведения опытов одинаковые, то эти вероятности равны. Пусть в результате  раз, тогда остальные
раз, тогда остальные  раз это событие не наступает. Событие
раз это событие не наступает. Событие  .
. .
. , где
, где  .
.
 , если указано конечное или счетное множество чисел
, если указано конечное или счетное множество чисел
 поставлено в соответствие некоторое положительное число
поставлено в соответствие некоторое положительное число  , причем
, причем
 называются возможными значениями случайной величины
называются возможными значениями случайной величины  - вероятностями этих значений (
- вероятностями этих значений (  ).
).
 и соединяют последовательно отрезками прямых. Получающаяся при этом ломаная линия называется многоугольником распределения случайной величины
и соединяют последовательно отрезками прямых. Получающаяся при этом ломаная линия называется многоугольником распределения случайной величины  .
. (i = 1, 2, ...,
(i = 1, 2, ...,  ), причем значения случайной величины мы считаем расположенными в возрастающем порядке.
), причем значения случайной величины мы считаем расположенными в возрастающем порядке.
 значений случайной величины (
значений случайной величины (  ).
).
 , то все члены суммы
, то все члены суммы  неотрицательны. Поэтому, отбрасывая первые
неотрицательны. Поэтому, отбрасывая первые  получим неравенство:
получим неравенство: 
 ,
, 

 , не больше дроби, числитель которой - дисперсия случайной величины, а знаменатель - квадрат
, не больше дроби, числитель которой - дисперсия случайной величины, а знаменатель - квадрат 
 случайная величина, которая не принимает отрицательных значений, то применим неравенство
случайная величина, которая не принимает отрицательных значений, то применим неравенство  из леммы Чебышева для случайной величины
из леммы Чебышева для случайной величины  при
при  :
: 

 ,
,  ,
, 
 - другая форма неравенства Чебышева
- другая форма неравенства Чебышева  ограничены одной константой С, а число их достаточно велико, то как угодно близка к единице вероятность того, что отклонение средней арифметической этих случайных величин от средней арифметической их математических ожиданий не превзойдет по абсолютной величине данного положительного числа
ограничены одной константой С, а число их достаточно велико, то как угодно близка к единице вероятность того, что отклонение средней арифметической этих случайных величин от средней арифметической их математических ожиданий не превзойдет по абсолютной величине данного положительного числа  .
. , математические ожидания, дисперсии их ограничены одной и той же постоянной С, а число их достаточно велико, то, сколько бы мало на было данное положительное число
, математические ожидания, дисперсии их ограничены одной и той же постоянной С, а число их достаточно велико, то, сколько бы мало на было данное положительное число 
 . Следовательно, по закону больших чисел средняя арифметическая достаточно большого числа измерений практически будет как угодно мало отличаться от истинного значения искомой величины.
. Следовательно, по закону больших чисел средняя арифметическая достаточно большого числа измерений практически будет как угодно мало отличаться от истинного значения искомой величины. наступления события А в каждом из
наступления события А в каждом из 
 появления события
появления события  в
в  -ом испытании не меняется, когда становятся известными результаты предыдущих испытаний, а их число достаточно велико, то сколь угодно близка к единице вероятность того, что частота появления события как угодно мало отличается от средней арифметической вероятностей
-ом испытании не меняется, когда становятся известными результаты предыдущих испытаний, а их число достаточно велико, то сколь угодно близка к единице вероятность того, что частота появления события как угодно мало отличается от средней арифметической вероятностей 
 взята из неизвестного распределения, у которого существует математическое ожидание и дисперсия (обозначим эти неизвестные значения через
взята из неизвестного распределения, у которого существует математическое ожидание и дисперсия (обозначим эти неизвестные значения через  и
и  соответственно).
соответственно).

 выборочным аналогом математического ожидания, а
выборочным аналогом математического ожидания, а 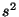 -- выборочным аналогом дисперсии.
-- выборочным аналогом дисперсии.

 . Следовательно,
. Следовательно,  при
при  .
. . Первое замечание состоит в том, что
. Первое замечание состоит в том, что  и
и  одинаковы. Поэтому без ограничения общности мы будем считать, что
одинаковы. Поэтому без ограничения общности мы будем считать, что  . При этом предположении
. При этом предположении







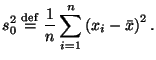
 оператор математического ожидания средним арифметическим. Ясно, что величина
оператор математического ожидания средним арифметическим. Ясно, что величина 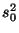 в отличие от
в отличие от  . Хотя для больших выборок эта смещенность не очень существенна.
. Хотя для больших выборок эта смещенность не очень существенна.
 . Из (32) вытекает, что
. Из (32) вытекает, что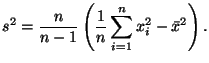
 , имеем
, имеем
 при
при  . Отсюда вытекает, что
. Отсюда вытекает, что  .
.
 . Подставив данные в формулы (29) и (30), найдем для выборки
. Подставив данные в формулы (29) и (30), найдем для выборки