
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
СТАТИСТИЧЕСКИЕ ОЦЕНКИ ПАРАМЕТРОВ РАСПРДЕЛЕНИЯ. НЕСМЕЩЕННЫЕ, ЭФФЕКТИВНЫЕ И СОСТОЯТЕЛЬНЫЕ ОЦЕНКИ.
Пусть требуется изучить количественный признак генеральной совокупности. Допустим, что из теоретических соображений удалось установить, какое именно распределение имеет признак. Возникает задача оценки параметров, которыми определяется это распреде- ление. Например, если наперед известно, что изучаемый признак распределен в генеральной совокупности нормально, то необходимо оценить (приближенно найти) математическое ожидание и среднее квадратическое отклонение, так как эти два параметра полностью определяют нормальное распределение; если есть основания считать, что признак имеет, например, распределение Пуассона, то необходимо оценить параметр λ, которым это распределение определяется. Обычно в распоряжении имеются лишь данные выборки, например значе- ния количественного признака x1, x2, ..., xn, полученные в результате n на- блюдений. Через эти данные и выражают оцениваемый параметр. Рассматривая x1, x2, ..., xn, как независимые случайные величины X1, X2, ..., Xn, можно ска- зать, что найти статистическую оценку неизвестного параметра теоретического распределения - это значит найти функцию от наблюдаемых случайных вели- чин, которая и дает приближенное значение оцениваемого параметра. Определение 41. Статистической оценкой неизвестного параметра теоре- тического распределения называется функция от наблюдаемых случайных величин. 12.2. Несмещенные, эффективные и состоятельные оценки Для того чтобы статистические оценки давали хорошие приближения оценива- емых параметров, они должны удовлетворять определенным требованиям. Пусть Θ ∗ - статистическая оценка неизвестного параметра Θ теоретического распределения. Допустим, что по выборке объема n найдена оценка Θ ∗ . Повторим опыт, т. е. извлечем из генеральной совокупности другую выборку того же объе- ма и по ее данным найдем оценку Θ ∗ . Повторяя опыт многократно, получим числа Θ ∗ , Θ ∗ , ..., Θ ∗ k ,, которые, вообще говоря, различны между собой. Таким образом, оценку Θ ∗ , можно рассматривать как случайную величину, а числа Θ ∗ , Θ ∗ , ..., Θ ∗ k , - как ее возможные значения. Представим, что оценка Θ ∗ дает приближенное значение Θ с избытком; тогда каждое найденное по данным выборок число Θ ∗ i (i = 1, 2, ..., k больше истинного значения Θ. Ясно, что в этом случае и математическое ожидание (среднее значение) случайной величины Θ ∗ больше, чем Θ, т. е. M[Θ ∗ ] > Θ. Если Θ ∗ дает оценку с недостатком, то M[Θ ∗ ] < Θ. Таким образом, использование статистической оценки, математическое ожи- дание которой не равно оцениваемому параметру, привело бы к систематическим (одного знака) ошибкам. По этой причине естественно потребовать, чтобы ма- тематическое ожидание оценки Θ ∗ было равно оцениваемому параметру. Хотя соблюдение этого требования не устранит ошибок (одни значения Θ ∗ больше,
24 Закон больших чисел
Практика изучения случайных явлений показывает, что хотя результаты отдельных наблюдений, даже проведенных в одинаковых условиях, могут сильно отличаться, в то же время средние результаты для достаточно большого числа наблюдений устойчивы и слабо зависят от результатов отдельных наблюдений. Теоретическим обоснованием этого замечательного свойства случайных явлений является закон больших чисел. Общий смысл закона больших чисел - совместное действие большого числа случайных факторов приводит к результату, почти не зависящему от случая.
Центральная предельная теорема
Теорема Ляпунова объясняет широкое распространение нормального закона распределения и поясняет механизм его образования. Теорема позволяет утверждать, что всегда, когда случайная величина образуется в результате сложения большого числа независимых случайных величин, дисперсии которых малы по сравнению с дисперсией суммы, закон распределения этой случайной величины оказывается практически нормальным законом. А поскольку случайные величины всегда порождаются бесконечным количеством причин и чаще всего ни одна из них не имеет дисперсии, сравнимой с дисперсией самой случайной величины, то большинство встречающихся в практике случайных величин подчинено нормальному закону распределения.
Остановимся подробнее на содержании теорем каждой из этих групп
В практических исследованиях очень важно знать, в каких случаях можно гарантировать, что вероятность события будет или достаточно мала, или как угодно близка к единице. Под законом больших чисел и понимается совокупность предложений, в которых утверждается, что с вероятностью, как угодно близкой к единице (или нулю), произойдет событие, зависящее от очень большого, неограниченно увеличивающегося числа случайных событий, каждое из которых оказывает на него лишь незначительное влияние. Точнее, под законом больших чисел понимается совокупность предложений, в которых утверждается, что с вероятностью, как угодно близкой к единице, отклонение средней арифметической достаточно большого числа случайных величин от постоянной величины - средней арифметической их математических ожиданий, не превзойдет заданного как угодно малого числа. Отдельные, единичные явления, которые мы наблюдаем в природе и в общественной жизни, часто проявляются как случайные (например, регистрируемый смертный случай, пол родившегося ребенка, температура воздуха и др.) вследствие того, что на такие явления действует много факторов, не связанных с существом возникновения или развития явления. Предсказать суммарное действие их на наблюдаемое явление нельзя, и они различно проявляются в единичных явлениях. По результатам одного явления нельзя ничего сказать о закономерностях, присущих многим таким явлениям. Однако давно было замечено, что средняя арифметическая числовых характеристик некоторых признаков (относительные частоты появления события, результатов измерений и т. д.) при большом числе повторений опыта подвержена очень незначительным колебаниям. В средней как бы проявляется закономерность, присущая существу явлений, в ней взаимно погашается влияние отдельных факторов, которые делали случайными результаты единичных наблюдений. Теоретически объяснить такое поведение средней можно с помощью закона больших чисел. Если будут выполнены некоторые весьма общие условия относительно случайных величин, то устойчивость средней арифметической будет практически достоверным событием. Эти условия и составляют наиболее важное содержание закона больших чисел.
Первым примером действия этого принципа и может служить сближение частоты наступления случайного события с его вероятностью при возрастании числа испытаний – факт, установленный в теореме Бернулли (швейцарский математик Якоб Бернулли (1654- 1705)).Теорема Бернулл является одной из простейших форм закона больших чисел и часто используется на практике. Например, частоту встречаемости какого-либо качества респондента в выборке принимают за оценку соответствующей вероятности).
Выдающийся французский математик Симеон Денни Пуассон (1781- 1840) обобщил эту теорему и распространил ее на случай, когда вероятность событий в испытании меняется независимо от результатов предшествующих испытаний. Он же впервые употребил термин «закон больших чисел». Великий русский математик Пафнутий Львович Чебышев (1821 - 1894) доказал, что закон больших чисел действует в явлениях с любой вариацией и распростаняется также на закономерность средней. Дальнейшее обобщение теорем закона больших чисел связано с именами А.А.Маркова, С.Н.Бернштейна, А.Я.Хинчина и А.Н.Колмлгорова.
Общая современная постановка задачи, формулировка закона больших чисел, развитие идей и методов доказательства теорем, относящихся к этому закону, принадлежит русским ученым П. Л. Чебышеву, А. А. Маркову и А. М. Ляпунову.
НЕРАВЕНСТВО ЧЕБЫШЕВА
Рассмотрим сначала вспомогательные теоремы: лемму и неравенство Чебышева, с помощью которых легко доказывается закон больших чисел в форме Чебышева. Лемма (Чебышев). Если среди значений случайной величины Х нет отрицательных, то вероятность того, что она примет какое-нибудь значение, превосходящее положительное число А, не больше дроби, числитель которой — математическое ожидание случайной величины, а знаменатель - число А:
Доказательство. Пусть известен закон распределения случайной величины Х:
По отношению к числу А значения случайной величины разбиваются на две группы: одни не превосходят А, а другие больше А. Предположим, что к первой группе относятся первые
Так как
Поскольку
то
Далее,
что и требовалось доказать. Случайные величины могут иметь различные распределения при одинаковых математических ожиданиях. Однако для них лемма Чебышева даст одинаковую оценку вероятности того или иного результата испытания. Этот недостаток леммы связан с ее общностью: добиться лучшей оценки сразу для всех случайных величин невозможно.
Неравенство Чебышева. Вероятность того, что отклонение случайной величины от ее математического ожидания превзойдет по абсолютной величине положительное число
Доказательство. Поскольку
Далее:
что и требовалось доказать.
Следствие. Поскольку
и
то
Примем без доказательства факт, что лемма и неравенство Чебышева верны и для непрерывных случайных величин. Неравенство Чебышева лежит в основе качественных и количественных утверждений закона больших чисел. Оно определяет верхнюю границу вероятности того, что отклонение значения случайной величины от ее математического ожидания больше некоторого заданного числа. Замечательно, что неравенство Чебышева дает оценку вероятности события для случайной величины, распределение которой неизвестно, известны лишь ее математическое ожидание и дисперсия.
Теорема. (Закон больших чисел в форме Чебышева) Если дисперсии независимых случайных величин
Теорему примем без доказательства. Следствие 1. Если независимые случайные величины имеют одинаковые, равные
То, что за приближенное значение неизвестной величины принимают среднюю арифметическую результатов достаточно большого числа ее измерений, произведенных в одних и тех же условиях, можно обосновать этой теоремой. Действительно, результаты измерений являются случайными, так как на них действует очень много случайных факторов. Отсутствие систематических ошибок означает, что математические ожидания отдельных результатов измерений одинаковые и равны (Напомним, что ошибки называются систематическими, если они искажают результат измерения в одну и ту же сторону по более или менее ясному закону. К ним относятся ошибки, появляющиеся в результате несовершенства инструментов (инструментальные ошибки), вследствие личных особенностей наблюдателя (личные ошибки) и др.)
Следствие 2. (Теорема Бернулли.) Если вероятность
Теорема Бернулли, утверждает, что если вероятность события одинакова во всех испытаниях, то с увеличением числа испытаний частота события стремится к вероятности события и перестает быть случайной.
На практике сравнительно редко встречаются опыты, в которых вероятность появления события в любом опыте неизменна, чаще она разная в разных опытах. К схеме испытаний такого типа относится теорема Пуассона: Следствие 3. (Теорема Пуассона.) Если вероятность
Теорема Пуассона утверждает, что частота события в серии независимых испытаний стремится к среднему арифметическому его вероятностей и перестает быть случайной. В заключение заметим, что ни одна из рассмотренных теорем не дает ни точного, ни даже приближенного значения искомой вероятности, а указывается лишь нижняя или верхняя граница ее. Поэтому, если требуется установить точное или хотя бы приближенное значение вероятностей соответствующих событий, возможности этих теорем весьма ограничены. Приближенные значения вероятностей при больших значениях Теоретическое значение теоремы Чебышева, являющейся весьма общей формулировкой закона больших чисел, велико. Однако если мы будем применять ее при решении вопроса о возможности применить закон больших чисел к последовательности независимых случайных величин, то при утвердительном ответе теорема часто будет требовать, чтобы случайных величин было гораздо больше, чем необходимо для вступления в силу закона больших чисел. Указанный недостаток теоремы Чебышева объясняется общим характером ее. Поэтому желательно иметь теоремы, которые точнее указывали бы нижнюю (или верхнюю) границу искомой вероятности. Их можно получить, если наложить на случайные величины некоторые дополнительные ограничения, которые для встречающихся на практике случайных величин обычно выполняются.
26 – ВЫБОРОЧНАЯ СРЕДНЯЯ И ВЫБОРОЧНАЯ ДИСПЕРСИЯ Иногда исследователь ставит перед собой более конкретную проблему: как, основываясь на выборке, оценить интересующие его числовые характеристики неизвестного распределения, не прибегая к приближению этого распределения как такового, то есть без построения выборочных функций распределения, гистограмм и т.п. В данном параграфе мы обсудим простые (но, как увидим в дальнейшем, весьма хорошие) выборочные аппроксимации для математического ожидания и дисперсии. Замечательно то, что они применимы в очень общей ситуации. Мы будем предполагать, что независимая выборка Определение 6.2 Величины, вычисляемые по выборке,
и
называются выборочным средним и выборочной дисперсией. Следует особо подчеркнуть, что определенные выше величины зависят только от выборки. Следующее предложение объясняет, почему естественно считать Предложение 6.1 Математические ожидания
Дисперсия Доказательство. Используя линейность математического ожидания, получим
Так как выборка независимая, то Покажем теперь, что
Теперь, проводя очевидные преобразования и применяя свойства математического ожидания, легко получаем необходимое утверждение
Это утверждение свидетельствует о том, что Замечание 6.4 Для оценивания дисперсии по выборке может быть использована также функция
Формально ее можно получить, заменив в определении дисперсии Предложение 6.2 При росте объема выборки
Доказательство. Как и при доказательстве Предложения 6.1 без ограничения общности будем считать, что
Применяя закон больших чисел в форме Хинчина к последовательности
В силу предположения
Замечание 6.5 Здесь мы воспроизводим замечание о вычислениях, приведенное в [12, с. 116]. Из соотношения (33) вытекает следующее представление для
Математически формулы (30) и (34) дают одно и то же значение. Но, если нам необходимовручную вычислить выборочную дисперсию, то следует это делать только по формуле (30), так как вычисления по формуле (34) потребовали бы учета намного большего числа значащих цифр, чем в случае применения формулы (30). Имеется большое число практически важных приемов, призванных облегчить вычислительную работу с конкретными числовыми выборками. Для знакомства с ними рекомендуем читателю обратиться к книге [11]. В настоящее время существует много прикладных компьютерных программ, которые можно и нужно использовать для обработки числовых данных. С некоторыми наиболее популярными специализированными статистическими пакетами (Stadia, StatGraphics) можно познакомиться по книге [13], к которой также приводится их сравнение. Для статистической обработки небольших массивов данных вполне подойдет любой хороший универсальный математический пакет (Mathematica, Maple, Matlab). Пример 6.5 Вычислим выборочное среднее и выборочную дисперсию для числовых данных Примера 6.4 на странице
и для выборки
Полезной величиной является также корень из выборочной дисперсии как оценка среднеквадратичного уклонения:
27 – Интервальная оценка параметров распределения. Доверительный интервал. Сущность задачи интервального оценивания параметров Интервальный метод оценивания параметров распределения случайных величин заключается в определении интервала (а не единичного значения), в котором с заданной степенью достоверности будет заключено значение оцениваемого параметра. Интервальная оценка характеризуется двумя числами – концами интервала, внутри которого предположительно находится истинное значение параметра. Иначе говоря, вместо отдельной точки для оцениваемого параметра можно установить интервал значений, одна из точек которого является своего рода " лучшей" оценкой. Интервальные оценки являются более полными и надежными по сравнению с точечными, они применяются как для больших, так и для малых выборок. Совокупность методов определения промежутка, в котором лежит значение параметра Т, получила название методов интервального оценивания. К их числу принадлежит метод Неймана. Постановка задачи интервальной оценки параметров заключается в следующем [3, 11]. Имеется: выборка наблюдений (x1, x2, …, xn) за случайной величиной Х. Объем выборки n фиксирован. Необходимо с доверительной вероятностью g = 1– a определить интервал t0 – t1 (t0 < t1), который накрывает истинное значение неизвестного скалярного параметра Т(здесь, как и ранее, величина Т является постоянной, поэтому некорректно говорить, что значение Т попадает в заданный интервал). Ограничения: выборка представительная, ее объем достаточен для оценки границ интервала. Эта задача решается путем построения доверительного утверждения, которое состоит в том, что интервал от t0 до t1 накрывает истинное значение параметра Т с доверительной вероятностью не менее g. Величины t0 и t1 называются нижней и верхней доверительными границами (НДГ и ВДГ соответственно). Доверительные границы интервала выбирают так, чтобы выполнялось условие P(t0 £ q £ t1) = g. В инженерных задачах доверительную вероятность g назначают в пределах от 0, 95 до 0, 99. В доверительном утверждении считается, что статистики t0 и t1 являются случайными величинами и изменяются от выборки к выборке. Это означает, что доверительные границы определяются неоднозначно, существует бесконечное количество вариантов их установления. На практике применяют два варианта задания доверительных границ: устанавливают симметрично относительно оценки параметра, т.е. t0 = q – Еg , t1 = q + Еg , где Еg выбирают так, чтобы выполнялось доверительное утверждение. Следовательно, величина абсолютной погрешности оценивания Еg равна половине доверительного интервала; устанавливают из условия равенства вероятностей выхода за верхнюю и нижнюю границу Р(Т > q + Е1, g )=Р(Т < q – Е2, g )=a /2. В общем случае величина Е1, g не равнаЕ2, g. Для симметричных распределений случайного параметра q в целях минимизации величины интервала значения Е1, g и Е2, g выбирают одинаковыми, следовательно, в таких случаях оба варианта эквивалентны. Нахождение доверительных интервалов требует знания вида и параметров закона распределения случайной величины q. Для ряда практически важных случаев этот закон можно определить из теоретических соображений. Общий метод построения доверительных интервалов Метод позволяет по имеющейся случайной выборке построить функцию и(Т, q ), распределенную асимптотически нормально с нулевым математическим ожиданием и единичной дисперсией. В основе метода лежат следующие положения. Пусть: f(х, q ) – плотность распределения случайной величины Х; ln [L(x, q )] – логарифм функции правдоподобия;
А2 =М(у)2 – дисперсия у. Если математическое ожидание М(у) = 0 и дисперсия у конечна, то распределение случайной величины w = Пример 4.4. Построить доверительный интервал с надежностью g =1– a для оценки m 1математического ожидания m1 случайной величины х, имеющей экспоненциальное распределение с функцией плотности f(x, l) = lехр(– lх). Решение. Известно, что для экспоненциального закона распределения математическое ожидание т1= 1/l, а дисперсия т2= 1/l2. Обозначим через l оценку параметра l. Определим оценку математического ожидания m 1, вспомогательную переменную у, производную от логарифма функции правдоподобия: m 1 = (х1+ х2+ … + хп)/п = 1/l; М(l ) = l; т1 = М(1/l ); у =
Оценка m 1 параметра т1 является состоятельной и несмещенной, следовательно: М(у)=М(l –1 – х) = 0; значение А2 = М(l –1– х)2 =l –2 конечно. Тогда случайная величина w = распределена нормально с параметрами 0 и 1. Нормальное распределение симметрично, поэтому границы интервала следует выбрать симметрично относительно нулевой точки. Вероятность g =1 – a того, что модуль величины w не превысит некоторого заданного значения d, составит
где Ф(d ) – значение функции нормального распределения в точке d. Величина d равна квантили u1–a /2 стандартного нормального распределения уровня 1– a /2. Значение абсолютной погрешности оценивания E = | m1 – m 1| =d /(l n0, 5) =u1– a /2 /(l n0, 5). Итак, имея достаточный объем выборки ЭД и задаваясь определенным уровнем надежности g можно определить доверительный интервал t0 = m 1 – Е, t1 =m 1 + Е, который с заданной вероятностью содержит неизвестный параметр т1. Аналогичные результаты для некоторых параметров распределения можно получить, используя более простые рассуждения. Доверительный интервал для математического ожидания Пусть по выборке достаточно большого объема, n > 30, и при заданной доверительной вероятности 1– a необходимо определить доверительный интервал для математического ожидания m1, в качестве оценки которого используется среднее арифметическое Закон распределения оценки математического ожидания близок к нормальному (распределение суммы независимых случайных величин с конечной дисперсией асимптотически нормально). Если потребовать абсолютную надежность оценки математического ожидания, то границы доверительного интервала будут бесконечными [– ¥ , ¥ ]. Выбор любых более узких границ связан с риском ошибки, вероятность которой определяется уровнем значимости a. Интерес представляет максимальная точность оценки, т.е. наименьшее значение интервала. Для симметричных функций минимальный интервал тоже будет симметричным относительно оценки m 1. В этом случае выражение для доверительной вероятности имеет вид P(| m 1 – m1 | £ Е) = 1– a, где Е – абсолютная погрешность оценивания. Нормальный закон полностью определяется двумя параметрами – математическим ожиданием и дисперсией. Величина m 1 является несмещенной, состоятельной и эффективной оценкой математического ожидания, поэтому ее значение принимаем за значение математического ожидания. Определим оценку дисперсии случайного параметра m 1, учитывая, что этот параметр равен среднему арифметическому одинаково распределенных случайных величин xi (следовательно, их дисперсии D(xi) одинаковы и равны m 2)
|
Последнее изменение этой страницы: 2017-03-14; Просмотров: 538; Нарушение авторского права страницы
 .
. (i = 1, 2, ...,
(i = 1, 2, ...,  ), причем значения случайной величины мы считаем расположенными в возрастающем порядке.
), причем значения случайной величины мы считаем расположенными в возрастающем порядке.
 значений случайной величины (
значений случайной величины (  ).
).
 , то все члены суммы
, то все члены суммы  неотрицательны. Поэтому, отбрасывая первые
неотрицательны. Поэтому, отбрасывая первые  получим неравенство:
получим неравенство: 
 ,
, 

 , не больше дроби, числитель которой - дисперсия случайной величины, а знаменатель - квадрат
, не больше дроби, числитель которой - дисперсия случайной величины, а знаменатель - квадрат 
 случайная величина, которая не принимает отрицательных значений, то применим неравенство
случайная величина, которая не принимает отрицательных значений, то применим неравенство  из леммы Чебышева для случайной величины
из леммы Чебышева для случайной величины  при
при  :
: 

 ,
,  ,
, 
 - другая форма неравенства Чебышева
- другая форма неравенства Чебышева  ограничены одной константой С, а число их достаточно велико, то как угодно близка к единице вероятность того, что отклонение средней арифметической этих случайных величин от средней арифметической их математических ожиданий не превзойдет по абсолютной величине данного положительного числа
ограничены одной константой С, а число их достаточно велико, то как угодно близка к единице вероятность того, что отклонение средней арифметической этих случайных величин от средней арифметической их математических ожиданий не превзойдет по абсолютной величине данного положительного числа  .
. , математические ожидания, дисперсии их ограничены одной и той же постоянной С, а число их достаточно велико, то, сколько бы мало на было данное положительное число
, математические ожидания, дисперсии их ограничены одной и той же постоянной С, а число их достаточно велико, то, сколько бы мало на было данное положительное число 
 . Следовательно, по закону больших чисел средняя арифметическая достаточно большого числа измерений практически будет как угодно мало отличаться от истинного значения искомой величины.
. Следовательно, по закону больших чисел средняя арифметическая достаточно большого числа измерений практически будет как угодно мало отличаться от истинного значения искомой величины. наступления события А в каждом из
наступления события А в каждом из 
 появления события
появления события  в
в  -ом испытании не меняется, когда становятся известными результаты предыдущих испытаний, а их число достаточно велико, то сколь угодно близка к единице вероятность того, что частота появления события как угодно мало отличается от средней арифметической вероятностей
-ом испытании не меняется, когда становятся известными результаты предыдущих испытаний, а их число достаточно велико, то сколь угодно близка к единице вероятность того, что частота появления события как угодно мало отличается от средней арифметической вероятностей 
 взята из неизвестного распределения, у которого существует математическое ожидание и дисперсия (обозначим эти неизвестные значения через
взята из неизвестного распределения, у которого существует математическое ожидание и дисперсия (обозначим эти неизвестные значения через  и
и  соответственно).
соответственно).

 выборочным аналогом математического ожидания, а
выборочным аналогом математического ожидания, а 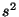 -- выборочным аналогом дисперсии.
-- выборочным аналогом дисперсии.

 . Следовательно,
. Следовательно,  при
при  .
. . Первое замечание состоит в том, что
. Первое замечание состоит в том, что  и
и  одинаковы. Поэтому без ограничения общности мы будем считать, что
одинаковы. Поэтому без ограничения общности мы будем считать, что  . При этом предположении
. При этом предположении

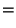






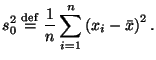
 оператор математического ожидания средним арифметическим. Ясно, что величина
оператор математического ожидания средним арифметическим. Ясно, что величина 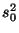 в отличие от
в отличие от  . Хотя для больших выборок эта смещенность не очень существенна.
. Хотя для больших выборок эта смещенность не очень существенна.
 . Из (32) вытекает, что
. Из (32) вытекает, что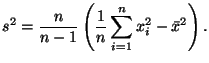
 , имеем
, имеем
 при
при  . Отсюда вытекает, что
. Отсюда вытекает, что  .
.
 . Подставив данные в формулы (29) и (30), найдем для выборки
. Подставив данные в формулы (29) и (30), найдем для выборки 
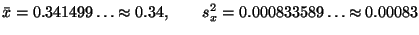
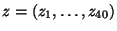


 ;
;  асимптотически нормально с параметрами 0 и 1 при п ®¥ .
асимптотически нормально с параметрами 0 и 1 при п ®¥ . ;
; 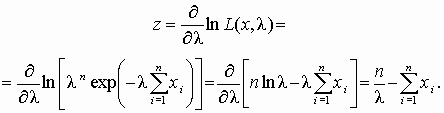

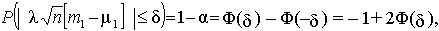
 .
. .
.