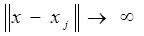|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Обобщенные нечеткие когнитивные карты
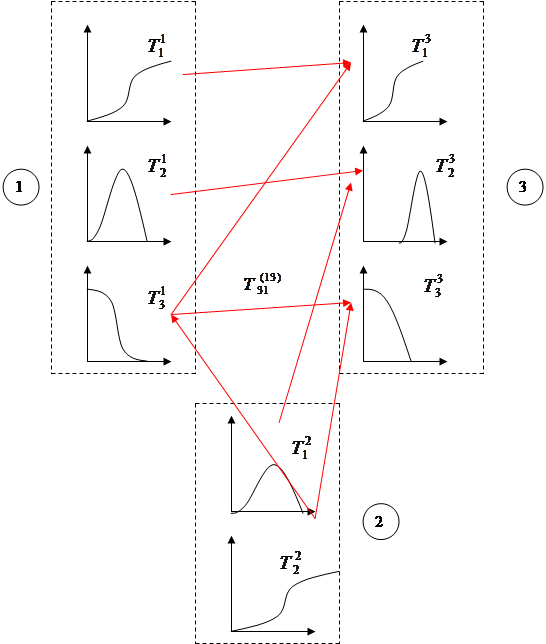
В обобщенных нечетких когнитивных картах концепты описывается при помощи набора возможных их состояний, причем, каждое состояние описывается при помощи нечеткого множества. Связи между концептами представляет собой множество связей между отдельными состояниями (термами) данных концептов. Связи характеризуют силу связей между термами, и также представляет нечеткие множества. Пример: Пусть имеется три концепта, характеризующиеся тремя состояниями: 1) низкий 2) средний 3) высокий
Т - терн Имея обобщенную нечеткую когнитивную карту и задавая конкретные состояния концептов (из тернов), можно получить нечеткую когнитивную карту как частный случай, таким образом рассматривать различные ситуации. На основе обобщенной нечеткой когнитивной карты можно построить систему нечетких продукционных правил (СНПП). СНПП с помощью процедуры нечеткого логического вывода позволит определить зависимость входных характеристик от выходных.
Классификация объектов, явлений и ситуаций Классификация (распознавание) – отнесение объекта или ситуации к некоторому классу. Классы – это множество объектов сгруппированных по определенным признакам. Задача классификации характеризуется тремя показателями:
где S – это количество рассмотренных классов (алфавит);
При построении классификаторов используются три основных подхода: · подход без обучения; · обучение с учителем; · Обучение без учителя. Построение классификатора без обучения используется в том случае, когда четко определено количество классов и их границы. Процедура обучения с учителем используется, когда классы S известны, однако заранее не определены их границы. Пример: Пусть имеется выборка объектов с известными признаками
. . .
Указанные данные делятся на две части, тогда на первом этапе классификации предъявляются объекты ОВ и показывается какому классу они относятся, таким образом определяются границы класса. На втором этапе каждый объект из ТВ (его входные характеристики Определяется погрешность классификатора Процедура обучения без учителя используется в тех случаях, когда не известны не границы не их количество (классов). Такая задача называется кластеризация. Интерпретировать полученные кластеры: высокий уровень дохода, низкий уровень дохода.
Постановка задачи Алгоритм задачи основан на мере близости. Вводится расстояние в пространстве признаков, тогда если существует В качестве L рассматривается эвклидого расстояние классификации объекта, то каждый элемент принадлежит определенному классу. Расстояние:
где
Алгоритм построения эталонов Эталон – это обобщенный образ класса, полученный путем усреднения всех объектов класса по всем признакам классификации. Эталон может не совпадать не с одним элементом класса. Абстрактным образ называется потому, что он может не совпадать не с одним объектом генеральной совокупности. Признаки эталона:
где где
Распознавания осуществляются следующим образом: на вход системы поступает объект (набор признаков x*), принадлежность которого к тому или иному образу системы неизвестно. От этого объекта измеряются расстояния до эталона всех образов, и считается принадлежащим тому образу расстояние, до которого минимально. Расстояние вычисляется в той метрике, которая введена для постоянной задачи распознавания образов.
Метод дробящихся этапов На первом этапе в обучающей выборке «охватывают» все объекты каждого класса гиперсферой возможно меньшего радиуса. Строится эталон каждого класса. Вычисляется расстояние от эталона до всех объектов данного класса. Выбирается максимальное из этих расстояний Эта процедура проводится для всех классов. Если гиперсферы различным образом пересекаются и в области перекрытия оказываются объекты более чем одного образа, то для них строится гиперсфера второго уровня. Затем третьего и так далее до тех пор, пока область окажется не пересекающейся, либо в области пересечения будут присутствовать объекты только одного образа. Распознавание идет следующим образом: определяется место каждого объекта относительно гиперсфер первого уровня. При попадании объекта в гиперсферу соответствующего одному и только одному гиперобразу, процедура распознавания прекращается. Если объект оказывается в области перекрытия гиперсферы, которая при обучении содержала объекты более чем одного образа, то осуществляется переход к гиперсферам второго уровня, и проводятся те же действия, что и для гиперсфер первого уровня. Процесс продолжается до тех пор, пока принадлежность неизвестного объекта к тому или иному образу определяется однозначно. Следует отметить, что неизвестный объект может не попасть ни в одну из гиперсфер какого-либо уровня. Необходима корректировка решающих правил. Данный метод по сравнению с предыдущим представляется более точным, но трудоемким ввиду большого числа определенных и использованных эталонов. Возможность в применении в задаче динамического распознавания, что и у метода построения эталонов.
Метод ближайших соседей Обучение в данном случае состоит в запоминании всех объектов в обучающей выборке. Если системе предъявлен нераспознаваемый объект Х*, то она относит этот объект тому образу, чей «представитель» оказался ближе всех к Х*. Это правило называется «правилом ближайшего соседа». Правило состоит в том, что строится гиперсфера объемом V с центром Х*. Распознавание осуществляется по большому числу «представителей» какого-либо образа оказавшегося внутри гиперсферы. Метод ближайшего соседа имеет недостаток, так как необходимо хранить всю обучающую выборку. Другим недостатком является большая величина ошибки, при x* близкой к границе X, то есть на границе сферы. Использование данного метода в задаче динамического распознавания представляется проблематичным. Метод потенциальных функций
Название метода связано с аналогией: пусть распознается два образа. Объекты являются точками
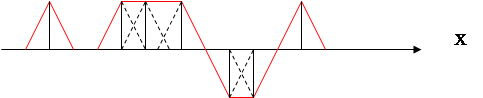
где K (X; Данный метод иллюстрирует рисунок:
------ - потенциальная функция, порождаемая одиночным объектом; ____ - суммарная потенциальная функция, порождаемая обучающей последовательностью. Чаще всего в виде потенциальной функции используется функция, имеющая максимум при образе
При предъявлении новых объектов рассматривается новый потенциал. Если g(x*) > 0, то объект относится к классу 1. Если g(x*) < 0, то объект относится к классу 2. Недостаток: сложность реализации при наличии большого количества классов.
|
Последнее изменение этой страницы: 2017-03-17; Просмотров: 687; Нарушение авторского права страницы
 ,
,  – признаки объекта или ситуации, которые рассматриваются при классификации (словарь признаков);
– признаки объекта или ситуации, которые рассматриваются при классификации (словарь признаков); 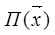 – решающее правило отнесения объекта к тому или иному классу.
– решающее правило отнесения объекта к тому или иному классу.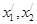 .
. обучающая выборка (ОВ)
обучающая выборка (ОВ)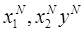 тестирующая выборка (ТВ)
тестирующая выборка (ТВ)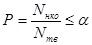 .
.
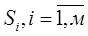 , то объект
, то объект 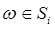 , если расстояние
, если расстояние 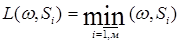 .
.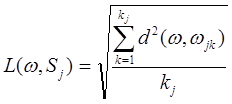 ,
, 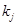 - количество элементов в j классе;
- количество элементов в j классе; 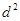 - эвклидого расстояние.
- эвклидого расстояние. ,
,  ,
,  - значение j признака i образа в k примере обучающей выборке;
- значение j признака i образа в k примере обучающей выборке;  - количество объектов образа
- количество объектов образа  в обучающей выборке.
в обучающей выборке.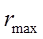 . Строится гиперсфера с центром в эталоне и радиусом, охватывающая все объекты данного класса
. Строится гиперсфера с центром в эталоне и радиусом, охватывающая все объекты данного класса 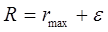 .
.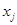 некоторого пространства X. В эти точки будем помещать заряды
некоторого пространства X. В эти точки будем помещать заряды 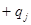 , если объект принадлежит образу
, если объект принадлежит образу 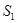 и
и 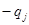 образу
образу 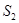 . Функцию, описывающую распределение электростатического потенциала в таком поле можно использовать для распознавания (построение решающего правила). Если потенциал в точке X создаваемый единичным зарядом находится в
. Функцию, описывающую распределение электростатического потенциала в таком поле можно использовать для распознавания (построение решающего правила). Если потенциал в точке X создаваемый единичным зарядом находится в 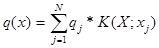 ,
, 
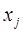 - некоторые образы;
- некоторые образы;