
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
При моделировании выделяют две задачи
– параметрический и структурный синтез модели То есть необходимо найти структуру Однако на практике применяються несколько другие две задачи: 1. расчета вектора коэфф 2. более практическая задача, когда ищем и структуру По поводу различных структур – Пример – какие ниже стуктуры одинаковые а какие разные 1.У= з-х+х3 2. у= 3х-х2 3.у= 3+х2+х3 4. у=3х-х3 При фиксированой структуре эффективность найденных параметров модели – один из вариантов - функционалом
где С адекватностью понятно –в дискретном случае это может быть “ обьясненная дисперсия”, коэфф детерминации (мах) или отн. норм.среднекв.ошибка (мин) Ну а причем здесь плотность распределения
Обычно для построения -(обращаю внимание на то, что нужно очень много данных, Когда же мы имеем такую роскошную возможность иметь столько данных? – когда имеем длинный сигнал (временной ряд), например, в медицинских приборах, и вообще работа в реале с накоплением данных об объекте.
Если наша задача – построить прогнозирующий фильтр (прогнозирующую модель)– тогда для Р(х) учитывают данные всей доступной кривой, а прогнозирующую модель расчитывают используя ограниченный скользящий участок методами стохастической аппроксимации, - то есть взвешивая невязки в соответствие с плотностью. Когда нет доступа к такому большому количествку данных то чаще обходятся без Если теперь функционал качества задачи моделирования выбрать в виде суммы квадратичных. невязок J (а)= придем к для поиска параметров а к обычному механизму МНК
Но будем помнить что принцип взвешивания невязок в МНК – важное ответвление РА (называемое взвешенный МНК ), и используется он в задачах моделирования при непрерывном поступлении новых данных в систему – это моделироваие сигналов, временных рядов под. которые необходимо подстроить их модели для дальнейшей обработки - например для прогноза ряда, или очистки сигнала от шума и т.д. Вернемся к обычному МНК Напомним Постановку задачи для поиска коэффициентов по методу наименьших квадратов ( МНК) при фиксированной структуре модели:
(**) и вектор выхода
1.Введем предположеие – достаточно сильное и тем неприятное - – предположим что модель линейна по параметрам
Предположение вводится в основном потому что мы умеем решать такие задачи, а не потому что это как то обосновано, Здесь есть нечто общее с тем что « будем искать потеряное под.фонарем, потому что там видно а не потому что там потеряли». 2 Наконец предполагаем что нам известна структура
Если тепер, как мы говорили выше, функционал качества задачи моделирования выбрать в виде сумм квадратичных. невязок J(у) = то для определения вектора параметров Действительно вспомним условия экстремума функций, тогда понятно откуда получена система (*О *) Обратим внимание что систему получим линейную отностельно аj Все достаточно просто.Решая эту систему получаем наилучший вектор парамеров а который дает минимум функционалу (**) Таким образом решается задача параметрического синтеза. Для частного случая одномерной регресии У=ах+в, его решение МНК можно получить как простые формулы для
№2 Но если регрессия не одномерная, то никто в наше время в расчетах не записывает функционал в скалярном виде, не берут производные, не составляют системы скалярных уравнений и тд. Для решения задачи поиска параметров регрессии пользуются матричные представления данных и операций. Я пользовался выше скалярной записью, только затем, что-бы в начале было проще показать смысл процедур поиска параметров.
Напомним 1.– Для умножения матриц А и В – А*В=С
–то есть получения элемента 2. Траспонирование – столбцы делает строками, строки столбцами (в квадратной матрице – просто зеркально отображаем относительно гл диагонали) 3.Обратная матрица А-1 матрицы А это такая матрица для которой выполняется А-1 *А=Е, где
Итак имеем матрицу Х и вектор выхода У
Уже понимаем почему пишем Х а а не а Х
В скалярном виде это соответствует наилучшему приближению
………… в n -ой точке -
Умножим слева и справа на ХТ получим Теперь поскольку ХТХ – квадратная – можем ее умножить на обратную - слева и справа на (Х ХТ)-1
и окончательно имеем для а
Все - И все расчеты проводятся по этой формуле - в любых инжененых пакетах реализованы матричные операции - все очень просто (мы поработаем на практике) и не очень просто в связи с операцией взятия обратной матрицы и понятием плохой обусловленности матрицы. Что это - плохая обусловленность матрицы: напомним о так наз. собственных числах матрицы /А-лЕ/=0. .....для опред Л - решаем степенное уравнение соответствующего порядка напомним на примере 2-го порядка ПлОбМа возникает когда λ min < < λ max. и численно мера ПОМ выражается их отношением или близостью к нулю ее детерминанта - Этот эффект ПОМ обычно набл когда в А одновременно присутствуют очень большие и очень малые числа - тогда при операции нахождения обратной матрицы обусловленность резко ухудшается (очень малые числа деляться на очень большие) и лавинообразно растет погрешность (изза выхода значущих цифр за пределы разрядной сетки ВМ)- решение теряется в эффекте ПлОбМа Это одна из причин что РА только начинается а не заканчивается на формуле для а. Преодоление ПОМ - различные алгоритмы регуляризации матрицы А......желательно с минимальной потерей ее эквивалентности Другие проблемы больше связаны с задачей структурного синтеза - об этом позже А пока более строгий вывод, который повторяет логику, изложенную для скалярного вида: Пусть размерность задачи m переменных и n точек Критерий по которому работает МНК: минимировать сумму квадратов ошибок еi =Уi-(ао+а1х1i+…+аmxmi ) модели У=ао+а1х1+…+аmxm в заданных точках. В матричном виде, модель У=Ха должна минимизировать критерий в матричной форме:
Дифференцируя эту функцию по вектору параметров и приравняв производные к нулю, получим систему уравнений (в матр. форме) В расшифрованном матричном виде эта система уравнений имеет вид
Где все суммы берутся по количеству точек Если в модель включен свободный член то Это и есть т.н. нормальная система уравнений |
Последнее изменение этой страницы: 2017-04-12; Просмотров: 382; Нарушение авторского права страницы

 и параметры модели
и параметры модели 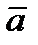 .
.
 оценивают по разному
оценивают по разному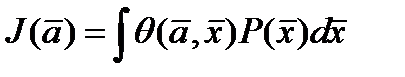 или
или  (*)
(*) 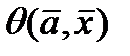 - функция адекватности модели, а
- функция адекватности модели, а 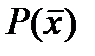 - плотность распределения.
- плотность распределения. – а?
– а? 

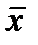 - вектор и
- вектор и  - многомерная плотность)
- многомерная плотность)
 , считая в (*), что
, считая в (*), что  , считая все слагаемые равноправными таким образом принимая что плотность равномерна.
, считая все слагаемые равноправными таким образом принимая что плотность равномерна.  и при виде моделии
и при виде моделии 
 Задана матрица значений аргументов
Задана матрица значений аргументов  ,
, 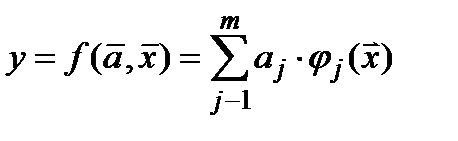
 то есть сейчас мы занимаемся задачей параметрического синтеза
то есть сейчас мы занимаемся задачей параметрического синтеза 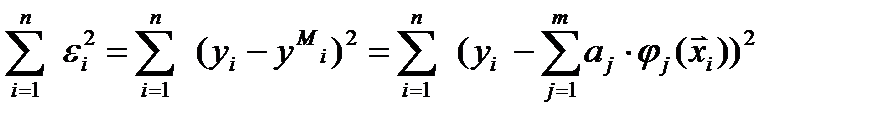 (**)
(**) (*О*)
(*О*) , где
, где 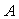 - коэффициент регрессии,
- коэффициент регрессии,  ,
,  -коэффициент корреляции х, у,
-коэффициент корреляции х, у,  и
и  ,
,  выборочные среднеквадратические отклонения и выборочные математические ожидания случайных величин
выборочные среднеквадратические отклонения и выборочные математические ожидания случайных величин  и
и 
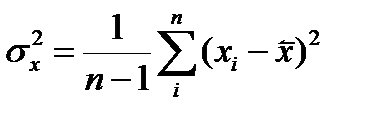 ,
,  ,
, 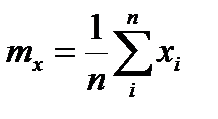 ,
, 

 Упрощенный вывод формулы МНК в матричном виде
Упрощенный вывод формулы МНК в матричном виде  необходимо взять в А (первой матрице) j-тую строку
необходимо взять в А (первой матрице) j-тую строку  и в В (второй матрице) k-тый столбец
и в В (второй матрице) k-тый столбец 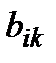 и образовать скаляное поизведение
и образовать скаляное поизведение  .
. единичная матрица
единичная матрица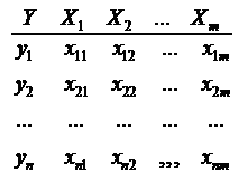
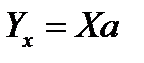 необходимо построить модель линейной структуры
необходимо построить модель линейной структуры При этом необходимо максимально приблизить с помощью вектора а матричное соотношение (***)
При этом необходимо максимально приблизить с помощью вектора а матричное соотношение (***)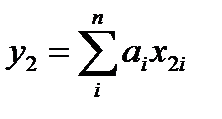 в первой точке
в первой точке 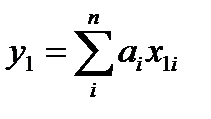
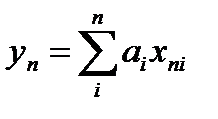 (***)
(***) 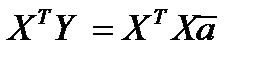 Для того что-бы освободить а (умножить то что при а на обратную Х матрицу и получить в результате Е – ед матрицу ) надо чтобы при а стояла квадратная матрица.
Для того что-бы освободить а (умножить то что при а на обратную Х матрицу и получить в результате Е – ед матрицу ) надо чтобы при а стояла квадратная матрица. 

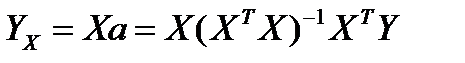 и для модели
и для модели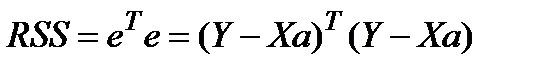
 , отсюда
, отсюда  (** ) и далее решая (**) можем найти вектор а=(хтх)-1хту
(** ) и далее решая (**) можем найти вектор а=(хтх)-1хту 
 =
=  X и XTX - осн
X и XTX - осн
 для всех
для всех 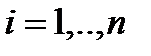 i
i