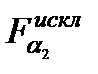|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Замечание: во избежание зацикливания процесса включения исключения значимость включения устанавливается меньше значимости исключения
В ШАМР для отбора лучших структур используют - порог критерия качества модели (связанный с уровнем значимости) и - коррекцию формулы расчета критерия качества модели, учитывающий штраф за сложность модели. Подход имеет недостаток в том смысле что не формализует очевидным образом выбор порога в зависимости от условий моделирования (дисперсия и параметры шума, степень коррелированности входов и тд) А используемый механизм штрафи за сложность – (деление на n-m) мало чувствителен к условиям моделирования при больших и средних значениях n –кол. точек
Остается привести формулу расчета статистики Фишера (F теста) который был создан для сравнения и выводов о различие дисперсий. Введем обозначения
ее в методе шаговой регрессии где
Есть есть и есть разница Сумма квадратов регрессий при введении полезного аргумента Поэтому аргумент с большим приростом Соответственно рассматриваются Тогда статистку Вопрос: Зачем для определения порога отсева аргументов рассматривать отношение При реализации процедуры включения аргумента - р ассматривается гипотеза H0, что улучшение качества модели незначимо. То есть Н0 состоит в том что введенный аргумент - ложный. Проверка гипотезы H0 сводиться к последовательности действий: 1. Задаемся уровнем значимости 2. По специальным таблицам находим -процентную точку Сравниваем точку
 тем меньше уровень значимости тем меньше уровень значимости  - ошибк.1 род). - ошибк.1 род).
На рис. видим что зона допуст. расчетных значений
Аналогично при процедуре исключения аргументов из модели р ассматривается гипотеза H0, что ухудшение качества модели незначимо Соответственно выбранный уровень значимости ----------- ==== |
Последнее изменение этой страницы: 2017-04-12; Просмотров: 376; Нарушение авторского права страницы

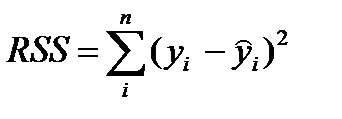 ·
·  — сумма квадратов ошибок, - здесь
— сумма квадратов ошибок, - здесь - наблюдаемые значения,
- наблюдаемые значения,  - значения модели
- значения модели ·
· 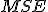 — среднеквадратичная ошибка, - в завис. от шага использования -
— среднеквадратичная ошибка, - в завис. от шага использования - - количество точек,
- количество точек,  - количество оцениваемых параметров модели
- количество оцениваемых параметров модели  - число степеней свободы модели, (-2). – потому что учитывается свободный член модели и одна степень свободы у среднего
- число степеней свободы модели, (-2). – потому что учитывается свободный член модели и одна степень свободы у среднего  .
. - сумма квадратов регрессии
- сумма квадратов регрессии до ввода регрессора претендента в модель -
до ввода регрессора претендента в модель -  ,
, 

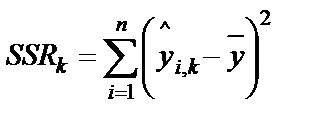 увеличивается и стремится к значению
увеличивается и стремится к значению 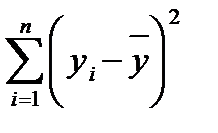
 - лучше.
- лучше. и
и  - значение среднеквадратичной ошибки до и после ввода регрессора в модель
- значение среднеквадратичной ошибки до и после ввода регрессора в модель (*) называют критерием или F-тестом Фишера. применительно к шаговой регрессии. Доказано что данная статистика f - есть случайная величина (сумма
(*) называют критерием или F-тестом Фишера. применительно к шаговой регрессии. Доказано что данная статистика f - есть случайная величина (сумма  делить на сумму
делить на сумму  ), распределенная по закону Фишера и ее используют для определения порога отсева аргументов по значению улучшения дисперсии модели.
), распределенная по закону Фишера и ее используют для определения порога отсева аргументов по значению улучшения дисперсии модели. (*) а не просто улучшение ошибки
(*) а не просто улучшение ошибки  или прирост
или прирост  ????. – Резон в том что это отношение расределено по известному закону Фишера и для определения состава аргументов модели привлекают механизм проверки статистических гипотез:
????. – Резон в том что это отношение расределено по известному закону Фишера и для определения состава аргументов модели привлекают механизм проверки статистических гипотез:  , например 0, 01 или 0, 05.
, например 0, 01 или 0, 05.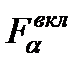 распределения Фишера со степенями свободы d1=1 d = n-k-2 (для формулы (**) степень свободы определяется как d1=(п-k)-(n-k-1)=1). Это значение будет являться нашим пороговым для статистики (*).
распределения Фишера со степенями свободы d1=1 d = n-k-2 (для формулы (**) степень свободы определяется как d1=(п-k)-(n-k-1)=1). Это значение будет являться нашим пороговым для статистики (*).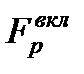 .
.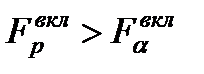 , то делается вывод о значимости введенного признака и, соответственно, его следует включить в модель (отдается предпочтение гипотезе H1 с вероятностью
, то делается вывод о значимости введенного признака и, соответственно, его следует включить в модель (отдается предпочтение гипотезе H1 с вероятностью  , то принимается решение о неэффективности включения переменной в модель, то есть гипотеза H0 принимается с вероятностью
, то принимается решение о неэффективности включения переменной в модель, то есть гипотеза H0 принимается с вероятностью  как не противоречащая экспериментальным данным.
как не противоречащая экспериментальным данным.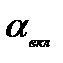


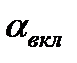 (площадь под хвостом)-должна быть меньше порогового уровня уровня значения ошибки 1-ого рода -
(площадь под хвостом)-должна быть меньше порогового уровня уровня значения ошибки 1-ого рода -  . Таким образом задавая в Stepwise
. Таким образом задавая в Stepwise  =допустим 0.05 (или соответств
=допустим 0.05 (или соответств  ) -что есть вероятность вкл. ложного аргумента (вер ош 1 рода) мы этим параметром полностью доопределяем процедуру включения аргументов в модель.
) -что есть вероятность вкл. ложного аргумента (вер ош 1 рода) мы этим параметром полностью доопределяем процедуру включения аргументов в модель. =допустим 0.1 (или соотв
=допустим 0.1 (или соотв  ) - есть вероятность исключения истинного аргумента (вер ошибки 2-го рода). Соответственно решение о принятии H0 " гипотезы о незначимости аргумента" - и исключении аргумента из модели реализуется при выполнении условия
) - есть вероятность исключения истинного аргумента (вер ошибки 2-го рода). Соответственно решение о принятии H0 " гипотезы о незначимости аргумента" - и исключении аргумента из модели реализуется при выполнении условия  . То есть область допустимых для исключения значений
. То есть область допустимых для исключения значений  лежит слева от
лежит слева от