
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Теоретический подход к решению задачи формирования необходимого и достаточного набора типовых систем защиты информации.
В соответствии с изложенным выше, рассматриваемая ситуация структурирована до формирования множества потенциально возможных вариантов сочетаний значений существенно значимых факторов и разработки методики оценки значимости вариантов. Следующая задача заключается в рациональном делении множества возможных вариантов на классы таким образом, чтобы в пределах каждого класса находились однородные в определенном смысле варианты. При этом однородность вариантов класса определяется главным образом возможностью предъявления единых требований по защите информации ко всем вариантам соответствующего класса. Нетрудно видеть, что сформулированная выше задача иначе может быть названа задачей формирования необходимого и достаточного набора типовых систем защиты информации (СЗИ). Поскольку данный вопрос имеет принципиальное значение в широком спектре проблем защиты информации, то уделим ему повышенное внимание. В соответствии с изложенным постановка рассматриваемой задачи может быть сформулирована как формирование такого набора типовых СЗИ, который удовлетворял бы требованиям к защите информации при любом потенциально возможном варианте значений существенно значимых факторов. Естественно, что число типовых СЗИ должно быть возможно меньшим. Основываясь на результатах теоретических исследований и опыте решения сформулированной задачи можно выделить три возможных подхода к ее решению: теоретический, эмпирический и комбинированный, т.е. теоретико-эмпирический. Рассмотрим основные положения названных подходов. Теоретический подход. Задачи деления элементов множества на классы изучаются уже продолжительное время, и для их решения в классической теории систем разработан достаточно представительный арсенал различных методов. Наиболее общим из этих методов является так называемый кластерный анализ, который определяется как классификация объектов по осмысленным, т.е. соответствующим четко сформулированным целям группам. Основная суть кластерного анализа заключается в том, что элементы множества делятся на классы в соответствии с некоторой мерой сходства между различными элементами. Процедура кластеризации в общем виде может быть представлена последовательностью пяти шагов следующего содержания: 1) формирование множества элементов, подлежащих делению на классы; 2) определение множества признаков, по которым должны оцениваться элементы множества; 3) определение меры сходства между элементами множества; 4) деление элементов множества на классы; 5) проверка соответствия полученного решения поставленным цепям. Нетрудно видеть, что применительно к рассматриваемой здесь задаче первые два шага сделаны на предыдущих занятиях. Рассмотрим возможныеподходы к осуществлению следующих шагов приведенной процедуры. Третий шаг, как это сформулировано выше, заключается в определении меры сходства между элементами классифицируемого множества. Нет необходимости доказывать, что выбором меры сходства элементов в решающей степени определяется результат классификации, его соответствие поставленным целям, поэтому данный шаг считается центральным. В теоретическом плане решение этой задачи заключается в формировании соответствующей метрики, т.е. представление элементов множества точками некоторого координатного пространства, в котором различие и сходство элементов определяется метрическим расстоянием между соответствующими элементами. Любая метрика должна удовлетворять совокупности следующих условий: 1) симметричности:
где x и у - различные элементы множества,
2) неравенства треугольника:
где x, y, z - различные элементы множества; 3) различимости неидентичных элементов:
4) неразличимости идентичных элементов: Нетрудно показать, что показатель важности варианта условий Что касается самого значения меры сходства, то наибольшее распространение получили следующие три: коэффициент корреляции, расстояние и коэффициент ассоциативности. Коэффициент корреляции между элементами с номерами j и
где Под расстоянием dij как мерой сходства понимается величина
или
где Коэффициент ассоциативности (S) используется для оценки меры сходства элементов, описываемых бинарными переменными. Вычисляется он по зависимости:
причем значения входящих в нее величин берутся из матрицы:
где 1 означает наличие соответствующей переменной, а 0 - ее отсутствие. Нетрудно видеть, что при d=0 выражение для коэффициента ассоциативности имеет вид:
Основная задача кластерного анализа заключается в рациональном делении анализируемого множества элементов на кластеры (классы) в соответствии с выбранной мерой сходства. Основными характеристиками, по которым оцениваются выделенные кластеры считаются: плотность, дисперсия, размеры, форма и отделимость. Популярное:
|
Последнее изменение этой страницы: 2016-03-17; Просмотров: 971; Нарушение авторского права страницы

 - расстояние между элементами х и у ;
- расстояние между элементами х и у ;  ,
,  где х, у - идентичные элементы;
где х, у - идентичные элементы;  , где x и x’ - идентичные элементы.
, где x и x’ - идентичные элементы. отвечает всем приведенным выше условиям метрики.
отвечает всем приведенным выше условиям метрики. вычисляется по следующей зависимости:
вычисляется по следующей зависимости:  , (11.1)
, (11.1) и
и  - значения i -йпеременной для элементов j и k соответственно,
- значения i -йпеременной для элементов j и k соответственно, 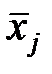 и
и  - среднее всех значений соответствующих элементов, n - число элементов.
- среднее всех значений соответствующих элементов, n - число элементов. , (11.2)
, (11.2) , (11.3)
, (11.3) и
и  - значения i -й переменной для i -го и j -гоэлементов соответственно, р - число переменных в оценке элементов.
- значения i -й переменной для i -го и j -гоэлементов соответственно, р - число переменных в оценке элементов. , (11.4)
, (11.4)

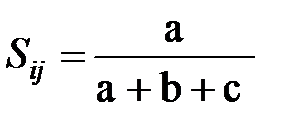 . (11.5)
. (11.5)