
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Дисперсия функции нескольких измеряемых величин ⇐ ПредыдущаяСтр 3 из 3
Пусть случайная величина г = f(x, y) является линейной функцией независимых случайных величин (измерений) х и у, например гср = ахср + Ьуср, где а и Ъ — постоянные величины. Определив средние арифметические
Пример 4. З начения х равны 10, 11, 12, а у — 6, 8, 10. Определить □ Среднее арифметическое независимых переменных Дисперсии:
Тогда для функции г, которая может принять девять значений, найдем согласно (15) и (16)
Критерий значимости. Пусть известна некоторая фактическаячастота события (результата измерений одного и того же состояния объекта). Если эта частота для данной данной партии (серии) отлична от теоретической, то случайно ли такое отклонение? Например известно, что процент брака при выпуске некоторой продукции в среднем равен а, что является теоретическим прогнозом для других партий. В данной партии фактический процент брака составил β, где β ≠ а. Можно ли объяснить расхождение случайными причинами или причина есть результат влияния новых, неизвестных факторов? Меру расхождения принято называть критерием значимости, численное значение которого определяется выражением
где Ф — фактически полученное значение частоты; Е — ожидаемая частота события. Суммирование производится по всем сериям или всем возможным состояниям в каждой серии. Теоретическим путем критерий
Пример 5. Две серии измерений N1 = 1000 и N2 = 500 были получены при автоматическом кондуктометрическом контроле электропроводности турбинного конденсата энергоблока, работающего в базовом режиме. В первой серии наблюдались Ф1 = 20 случаев превышения установленного норматива, во второй Ф2 = 15. Можно ли считать, что количественные расхождения превышений норматива в двух сериях случайны, или они отражают различия водно-химических режимов в этих сериях, например, из-за увеличения присосов охлаждающей воды в конденсаторе турбины? □ Всего на 1500 измерений имеем 35 случаев превышения норматива. Следовательно, вероятности нормативных изерений
Тогда теоретические числа нормативных Enor и превысивших норматив измерений Eex составят для: - первой серии (Enor)1 = - второй серии (Enor)2 = Значение критерия значимости χ 2расчитывается по формуле (17) χ 2 = (20 – 23, 3)2/23, 3 + (15 – 11, 6)2/11, 6 + (980 – 976, 7)2/976, 7 + (485 – 488, 4)2/488, 4 = 1, 5. Теперь находим число степеней свободы К. В нашем случае имеем два класса m показаний: «в норме» и «превышение нормы», т.е. т = 2. Но, при известном общем числе измерений произвольным может быть только один класс, другой определяется по разности. Так, в первой серии превышения нормы составили Ф1 = 20 случаев (произвольный класс jarb), а показания «в норме» определились как разность: N1 - Ф1 = 1000 - 20 = 980 измерений (непроизвольный класс jinv). Таким образом, число степеней свободы К = т -jinv= 2 – 1 = 1. Далее из табл. П.1 по числам χ 2= 1, 5 и К = 1 находим значение вероятности события, которое оказывается равным р ≈ 0, 2. Так как 0, 2 > 0, 1, то расхождение показаний кондуктометра в двух сериях измерений следует признать случайным. ■ Критерий Фишера. Измеряя одни и те же величины различными способами или в различные периоды времени, получаем, как правило, отличающиеся друг от друга значения. Поскольку каждое измерение выполнено с некоторой погрешностью, абсолютное значение и знак которой неизвестны, то возникает неопределенность в объяснении причин расхождения при сопоставлении результатов измерений: - наблюдаемое расхождение соответствует различию между измеряемыми параметрами; - получены два значения одной случайной величины, а их видимое различие определяется только случайными колебаниями неконтролируемых параметров. Для раскрытия этой неопределенности следует ответить на два взаимосвязаных вопроса: - равноточны ли измерения в разных сериях опытов (оценка различия воспроизводимых результатов); - какова оценка значимости различия средних значений результатов в сериях. Равноточность двух серий измерений определяется сопоставлением дисперсий Расчетное значение критерия Фишера F сравнивают с его критической величиной Fcr(α, К1, К2), значение которой представлено в табл.П.2 для разных уровней значимости α и степеней свободы К1 = n1 – 1 и К2 = n2 – 1, где n1 и n2 — количество параллельных измерений в сериях опытов с наибольшей и наименьшей дисперсией. Из сопоставления вытекает: - если F > Fcr, то с доверительной вероятностью β = 1 – α, можно полагать, что дисперсии в первой и второй сериях опытов статистически неодинаковы, воспроизводимость опытов во второй серии выше, т.е. разброс данных относительно среднего меньше; - если F < Fcr, то данные измерений не дают основания полагать, что разброс значений во второй серии меньше, чем в первой. Для оценки значимости различия средних значений результатов в сериях измерений отметим, что существует риск погрешности в признании двух дисперсий статистически неравными при F > Fcr. Этот риск равен α только в том случае, если есть основания полагать, что в одной серии опытов разброс результатов относительно среднего меньше, чем в другой. В частности, это может быть при применении более совершенной измерительной аппаратуры или более сложных методик измерения. Если подобного заранее утверждать нельзя, то используются двухсторонние доверительные границы. При этом a priori полага.n, что разброс данных, т.е. дисперсия в одной серии опытов, может быть как больше, так и меньше, чем в другой. Тогда, из табл.П.2, определяющих значения Fcr с односторонними пределами уровня значимости α, получим риск погрешности равный 2α. Распределение Стьюдента. При малом количестве измерений (п < 20) фактическое распределение отличается от нормального тем сильнее, чем меньше количество измерений. Пусть, которыйхарактеризует отношение отклонения среднего значения Критерий t можно использовать для сравнения выборок n1 Пример 6. В табл.2 представлены результаты анализа двух выборок твердого топлива на ТЭС, взятых с некоторым временным интервалом. Каждая выборка содержала по 5 проб с определением одного и того же свойства (влажность, зольность, выход летучих и др.). Определить, как отличаются средние значения определяемого свойства в двух выборках, если качество анализа одинаково во всех пробах. Таблица 2 Результаты анализа твёрдого топлива на зольность
□ Отличия среднего арифметического в двух выборках ищем путём определения критерия t. При отсутствии отличий разность средних для двух выборок должна стремиться к нулю. Заносим в табл.2 значения S1 = (1545, 4/4 – (87, 9)2/(5·4))0, 5 = 0, 175, S2 = (14795, 9/4 – (85, 9)2/(5·4))0, 5 = 0, 187, t = (17, 58 – 17, 18)·((0, 1752 + 0, 1872)/5)-1/2 = 3, 67. По табл. П.З при К = 8 (из 5 анализов 4 независимы для каждой из двух выборок) и при вычисленном значении t = 3, 67 находим р ≈ 0, 01 < 0, 1. Следовательно, вероятность погрешности слишком мала и приходится признать, что различия анализируемого свойства в двух выборках не случайны. ■
Доверительный интервал. По данным выборки с нормальным законом распределения требуется оценить исследуемое свойство величины Если определена требуемая вероятность ошибки отклонения значения ( где t определено с доверительной вероятностью α = 1 - р (если р = 0, 05, то α = 0, 95 или 95 %). Величина S (п)-1/2 есть среднеквадратическое отклонение среднего арифметического S0 (13), т.е. ( Поскольку t S0 = ζ, то доверительный интервал можно записать как Пример 7. По результатам восьми титрований параметра xi, см3, представленных в табл.3, определить доверительный интервал, в котором с доверительной вероятностью α = 0, 95 располагается истинное значение измеряемого параметра М(x). □ Искомое значение доверительного интервала равно ζ = t S0, где t критерий Стьюдента, а S0 среднеквадратичное отклонение среднего арифметического Результаты вспомогательных, для определения t и S0, расчётов занесены в табл.3. Таблица 3. Исходные данные и результаты их обработки.
Среднеквадратичное отклонение S = Ширина доверительного интервала ζ = t S0 = 2, 365·0, 099 = 0, 234, что составляет коэффициент вариации серии измерений δ = 100 ζ (
Популярное:
|
Последнее изменение этой страницы: 2016-03-22; Просмотров: 1190; Нарушение авторского права страницы
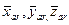 , и их дисперсии σ x, σ y, σ z, можно показать, что
, и их дисперсии σ x, σ y, σ z, можно показать, что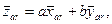 (15)
(15)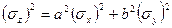 (16)
(16)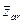 и
и  , если
, если 
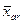 = (10 + 11 + 12)/3 = 11
= (10 + 11 + 12)/3 = 11 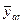 = (6 + 8 + 10)/3 = 8.
= (6 + 8 + 10)/3 = 8.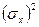 = ((10 – 11)2 + (11 – 11)2 + (12 – 11)2)/(3 – 1) = 0, 66,
= ((10 – 11)2 + (11 – 11)2 + (12 – 11)2)/(3 – 1) = 0, 66, 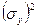 = ((6 – 8)2 + (8 – 8)2 + (10 – 8)2)/(3 – 1) = 2, 66.
= ((6 – 8)2 + (8 – 8)2 + (10 – 8)2)/(3 – 1) = 2, 66. , (17)
, (17)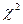 можно получить по двум параметрам: вероятности р и числу степеней свободы К (см..табл. П.1). В этом случае оценка случайность — неслучайность определяется по следующей схеме. По формуле (17) определяют
можно получить по двум параметрам: вероятности р и числу степеней свободы К (см..табл. П.1). В этом случае оценка случайность — неслучайность определяется по следующей схеме. По формуле (17) определяют  и превышений норматива
и превышений норматива 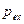 в обоих сериях соответственно равны:
в обоих сериях соответственно равны: 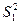 и
и 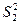 их результатов, где
их результатов, где 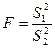 . (18)
. (18)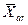 есть среднее арифметическое некоторого количества измерений во всем множестве измерений N, т.е. истинное значение, а
есть среднее арифметическое некоторого количества измерений во всем множестве измерений N, т.е. истинное значение, а  , (19)
, (19) .
. 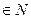 и n2
и n2 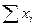
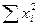
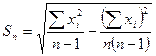 и
и 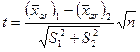 , где n = 1, 2, 3, 4, 5.
, где n = 1, 2, 3, 4, 5.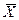 как центра генеральной совокупности (или истинного значения данного свойства всего множества), если для неё известны число элементов п, среднее квадратическое отклонение S и среднее арифметическое
как центра генеральной совокупности (или истинного значения данного свойства всего множества), если для неё известны число элементов п, среднее квадратическое отклонение S и среднее арифметическое 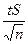 ) <
) < 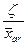 .
. = 612, 37/8 = 76, 546 см3.
= 612, 37/8 = 76, 546 см3.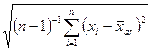 = (0, 554/7)0, 5 = 0, 281, а среднеквадратичное отклонение среднего арифметического S0 =
= (0, 554/7)0, 5 = 0, 281, а среднеквадратичное отклонение среднего арифметического S0 = 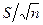 = 0, 281 (8)-0, 5 = 0, 099. Теперь, при вероятности погрешности р = 1 – α = 1 – 0, 95 = 0, 05 и числе степеней свободы К = 8 – 1 = 7, в соответствии с табл.П.3, критерий t = 2, 365.
= 0, 281 (8)-0, 5 = 0, 099. Теперь, при вероятности погрешности р = 1 – α = 1 – 0, 95 = 0, 05 и числе степеней свободы К = 8 – 1 = 7, в соответствии с табл.П.3, критерий t = 2, 365.