
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Перевод целых чисел из десятичной системы счисления в систему счисления с другим основанием
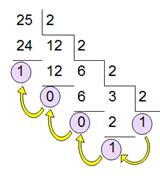
Для осуществления такого перевода необходимо делить число с остатком на основание системы счисления до тех пор, пока частное больше основания системы счисления. Пример перевода десятичного числа 25(10) в двоичный вид показан на рисунке 16. Результат перевода записывается в обратном порядке, т.е. начиная с последнего результата деления.
Шестнадцатеричная система счисления Система счисления с основанием 16 интересна тем, что она включает в себя больше разрядов, чем десятичная, и соответственно десяти арабских цифр недостаточно для алфавита этой системы счисления, поэтому в качестве недостающих цифр в ней используются буквы латинского алфавита. Для обозначения того, что запись является шестнадцатеричным числом, принято использовать также символ #. Таблица 7.
Для шестнадцатеричной системы счисления действуют те же правила перевода, что и для всякой позиционной системы счисления.
Вавилонская (шестидесятеричная) система счисления Исторический интерес представляет так называемая «вавилонская», или шестидесятеричная система счисления, весьма сложная, существовавшая в Древнем Вавилоне, за две тысячи лет до н.э. Это первая известная нам система счисления, основанная на позиционном принципе. Система вавилонян сыграла большую роль в развитии математики и астрономии, ее следы сохранились до наших дней. Так, мы до сих пор делим час на 60 минут, а минуту на 60 секунд. Точно так же, следуя примеру вавилонян, окружность мы делим на 360 частей (градусов). Задачи 1. Числа в двоичной системе счисления имеют вид 11(2) и 101(2). Чему равно их произведение в десятичном виде? Варианты: 60, 15, 1111, 8. 2. Чему равна разность 25 - & 1101. Варианты: & 1100, 13. 3. В десятичной - 8; - в двоичной - [ ]; - в восьмеричной - [ ]; - в шестнадцатеричной - [ ]. 4. Количество чисел, которое можно закодировать нулями и единицами в 10 позициях, равно: 128, 256, 1024, 2048? 5. Укажите истинное высказывание: - #a < & 1100; - #a > & 1100; - #a = & 1100. 6. Дано равенство 23(k)+33(k)=122(k). Чему равно k? Варианты: 2, 3, 4, 10. 7. Какое число предшествует шестнадцатеричному числу #6afa? Варианты: #6afb, #6a10, #6af9, #5afa. 8. Шестнадцатеричное число #4d в десятичной системе счисления это: 43, 77, 177, 176? 9. Прочитайте стихотворение. Переведите встречающиеся в нем числительные из двоичной системы счисления в десятичную.
Необыкновенная девчонка
Ей было тысяча сто лет,
Когда, пыля десятком ног, Она ловила каждый звук
И десять темно-синих глаз
10. За праздничным столом собрались 4 поколения одной семьи: дед, отец, сын и внук. Их возраст в различных системах счисления записывается так 88 лет, 66 лет, 44 года и 11 лет. Сколько им лет в десятичной системе счисления, если через год их возраст в тех системах счисления можно будет записать как 100? Кодирование двоичным кодом Информация любого типа: символьная, графическая, звуковая, командная для представления на электронных носителях кодируется на основании алфавита, состоящего только из двух символов (0, 1). Информация представленная в аналоговом виде, для того, чтобы быть сохраненной в электронной памяти, оцифровывается и приводится к двоичному коду. Каждая ячейка электронной памяти обладает информационной ёмкостью 1 бит. Физически, в зависимости от способа регистрации информации, это может быть конденсатор, находящийся в одном из двух состояний: разряжен (0), заряжен (1); элемент магнитного носителя: размагничен (0), намагничен (1); элемент поверхности оптического диска: нет лунки (0), есть лунка (1). Одним из первых носителей информации, представленной в двоичном коде, была бумажная перфокарта, пробитое отверстие на которой означало 1, а цельная поверхность 0. Кодирование символов. Байт. На основании одной ячейки информационной ёмкостью 1 бит можно закодировать только 2 различных состояния. Для того чтобы каждый символ, который можно ввести с клавиатуры в латинском регистре, получил свой уникальный двоичный код, требуется 7 бит. На основании последовательности из 7 бит, в соответствии с формулой Хартли, может быть получено N=27=128 различных комбинаций из нулей и единиц, т.е. двоичных кодов. Поставив в соответствие каждому символу его двоичный код, мы получим кодировочную таблицу. Человек оперирует символами, компьютер – их двоичными кодами. Для латинской раскладки клавиатуры такая кодировочная таблица одна на весь мир, поэтому текст, набранный с использованием латинской раскладки, будет адекватно отображен на любом компьютере. Эта таблица носит название ASCII (American Standard Code of Information Interchange) по-английски произносится [э́ ски], по-русски произносится [а́ ски]. Ниже приводится вся таблица ASCII, коды в которой указаны в десятичном виде. По ней можно определить, что когда вы вводите с клавиатуры, скажем, символ “*”, компьютер его воспринимает как код 42(10), в свою очередь 42(10)=101010(2) – это и есть двоичный код символа “*”. Коды с 0 по 31 в этой таблице не задействованы. Таблица 8. Таблица символов ASCII
Чтобы хранить также и коды национальных символов каждой страны (в нашем случае – символов кириллицы) требуется добавить еще 1 бит, что увеличит количество уникальных комбинаций из нулей и единиц вдвое, т.е. в нашем распоряжении дополнительно появится 128 свободных кодов (со 128-го по 255-й), в соответствие которым можно поставить символы русского алфавита. Таким образом, отведя под хранение информации о коде каждого символа 8 бит, мы получим N=28=256 уникальных двоичных кодов, что достаточно, чтобы закодировать все символы, которые можно ввести с клавиатуры. Так мы подошли к необходимости познакомиться с еще одной базовой единицей измерения – байтом. Байт - последовательность из 8 бит. 1 байт = 23 бит = 8 бит. На основании одного байта можно получить 28=256 уникальных двоичных кодов. В современных кодировочных таблицах под хранение информации о коде каждого символа отводится 1 байт. 1 символ = 1 байт. В байтах измеряется объем данных (V) при их хранении и передаче по каналам связи. Например, текст “Добрый день! ” занимает объем равный 12 байтам. Биты в байте нумеруются с конца с 0-го по 7-й. Минимальная комбинация на основании одного байта – восемь нулей, максимальная – восемь единиц. Рис. 18а. 11111111(2)=27+26+25+24+23+22+21+20=128+64+32+16+8+4+2+1=255(10) При хранении на физическом уровне каждый байт может быть реализован, например, на базе восьми конденсаторов, каждый из которых либо разряжен (0), либо заряжен (1). Рис. 18b.
Возвращаясь к кодировочным таблицам, заметим, что на сегодняшний день в использовании не одна, а несколько кодировочных таблиц, включающих коды кириллицы, – это стандарты, выработанные в разные годы и различными учреждениями. В этих таблицах различен порядок, в котором расположены друг за другом символы кирилличного алфавита, поэтому одному и тому же коду соответствуют разные символы. По этой причине, мы иногда сталкиваемся с текстами, которые состоят из русских букв, но в бессмысленной для нас последовательности. Например, текст “Компьютерные вирусы”, введенный в кодировке Windows-1251 в кодировке КОИ-8 будет отображен так: ”лПНРШАФЕТОШЕ ЧЙТХУЩ”. Таблица 9. Несоответствие кодов символов в различных кодировках кириллицы.
Эта проблема разрешима - на каждом компьютере найдутся все основные кодировочные таблицы, и если тест выглядит неадекватно, нужно попробовать перекодировать его, просто указав использовать другую кодировочную таблицу. Но наличие такой проблемы, конечно, вносит неудобства. Используя 8-битную кодировочную таблицу мы не сможем адекватно увидеть на мониторе и тексты, созданные на тех языках, где используются символы, отличные от латинских и кирилличных, например символы с умляутами в немецком языке. Юникод. UTF-8
Юникод включает практически все современные письменности, в том числе: арабскую, армянскую, бенгальскую, бирманскую, греческую, грузинскую, деванагари, иврит, кириллицу, коптскую, кхмерскую, латинскую, тамильскую, хангыль, хань (Китай, Япония, Корея), чероки, эфиопскую, японскую (катакана, хирагана, кандзи) и другие. С академической целью добавлены многие исторические письменности, в том числе: древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит. В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм. Для символов кириллицы в Юникоде выделено два диапазона кодов: Cyrillic (#0400 — #04FF) Cyrillic Supplement (#0500 — #052F). Но внедрение таблицы Unicode в чистом виде сдерживается по той причине, что если код одного символа будет занимать не один байт, а два байта, что для хранения текста понадобится вдвое больше дискового пространства, а для его передачи по каналам связи – вдвое больше времени. Поэтому сейчас на практике больше распространено представление Юникода UTF-8 (Unicode Transformation Format). UTF-8 обеспечивает наилучшую совместимость с системами, использующими 8-битные символы. Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 4 байтов. В целом, так как самые распространенные в мире символы – символы латинского алфавита - в UTF-8 по-прежнему занимают 1 байт, такое кодирование экономичнее, чем чистый Юникод. Задачи 1. В кодируемом английском тексте используется только 26 букв латинского алфавита и еще 6 знаков пунктуации. В этом случае текст, содержащий 1000 символов можно гарантированно сжать без потерь информации до размера: - 8000 бит; - 7000 бит; - 5000 бит; - 1000 бит. 2. Словарь Эллочки – «людоедки» (персонаж романа «Двенадцать стульев») составляет 30 слов. Сколько бит достаточно, чтобы закодировать весь словарный запас Эллочки? Варианты: 8, 5, 3, 1. 4.4. Единицы измерения объема данных и ёмкости памяти: килобайты, мегабайты, гигабайты… Итак, в мы выяснили, что в большинстве современных кодировок под хранение на электронных носителях информации одного символа текста отводится 1 байт. Т.е. в байтах измеряется объем (V), занимаемый данными при их хранении и передаче (файлы, сообщения). Объем данных (V) – количество байт, которое требуется для их хранения в памяти электронного носителя информации. Память носителей в свою очередь имеет ограниченную ёмкость, т.е. способность вместить в себе определенный объем. Ёмкость памяти электронных носителей информации, естественно, также измеряется в байтах. Однако байт – мелкая единица измерения объема данных, более крупными являются килобайт, мегабайт, гигабайт, терабайт… Следует запомнить, что приставки “кило”, “мега”, “гига”… не являются в данном случае десятичными. Так “кило” в слове “килобайт” не означает “тысяча”, т.е. не означает “103”. Бит – двоичная единица, и по этой причине в информатике удобно пользоваться единицами измерения кратными числу “2”, а не числу “10”. 1 байт = 23 =8 бит, 1 килобайт = 210 = 1024 байта. В двоичном виде 1 килобайт = & 10000000000 байт. Т.е. “кило” здесь обозначает ближайшее к тысяче число, являющееся при этом степенью числа 2, т.е. являющееся “круглым” числом в двоичной системе счисления. Таблица 10.
В связи, с тем, что единицы измерения объема и ёмкости носителей информации кратны 2 и не кратны 10, большинство задач по этой теме проще решается тогда, когда фигурирующие в них значения представляются степенями числа 2. Рассмотрим пример подобной задачи и ее решение:
В текстовом файле хранится текст объемом в 400 страниц. Каждая страница содержит 3200 символов. Если используется кодировка KOI-8 (8 бит на один символ), то размер файла составит: - 1 Mb; - 1, 28 Mb; - 1280 Kb; - 1250 Kb. Решение 1) Определяем общее количество символов в текстовом файле. При этом мы представляем числа, кратные степени числа 2 в виде степени числа 2, т.е. вместо 4, записываем 22 и т.п. Для определения степени можно использовать Таблицу 7.
2) По условию задачи 1 символ занимает 8 бит, т.е. 1 байт => файл занимает 27*10000 байт. 3) 1 килобайт = 210 байт => объем файла в килобайтах равен:
Задачи 1. Сколько бит в одном килобайте? - & 1000; - & 10000; - & 10000000; - & 10000000000000. 2. Чему равен 1 Мбайт? - 1024 байта; - 1024 килобайта; - 1000000 бит; - 1000000 байт. 3. Сколько бит в сообщении объемом четверть килобайта? Варианты: 250, 512, 2000, 2048. 4. Объем текстового файла 640 Kb. Файл содержит книгу, которая набрана в среднем по 32 строки на странице и по 64 символа в строке. Сколько страниц в книге: 160, 320, 540, 640, 1280? 5. Досье на сотрудников занимают 8 Mb. Каждое из них содержит 16 страниц (32 строки по 64 символа в строке). Сколько сотрудников в организации: 256; 512; 1024; 2048? Популярное:
|
Последнее изменение этой страницы: 2016-04-09; Просмотров: 1273; Нарушение авторского права страницы




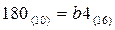


 Теоретически давно существует решение этих проблем. Оно называется Unicode (Юникод). Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т.е. 16 бит. На основании такой таблицы может быть закодировано N=216=65 536 символов.
Теоретически давно существует решение этих проблем. Оно называется Unicode (Юникод). Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т.е. 16 бит. На основании такой таблицы может быть закодировано N=216=65 536 символов. символов.
символов.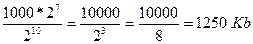 .
.