|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Технологии распределенной обработки данных
Распределенная обработка данных позволяет разместить базу данных (или несколько баз) в различных узлах компьютерной сети. Таким образом, каждый компонент базы данных располагается по месту наличия техники и ее обработки. Например, при организации сети филиалов какой-либо организационной структуры удобно обрабатывать данные в месте расположения филиала. Распределение данных осуществляется по разным компьютерам в условиях реализации вертикальных и горизонтальных связей для организаций со сложной структурой. Распределенная обработка данных (distributed data processing) - обработка данных, проводимая в распределенной системе, при которой каждый из технологических или функциональных узлов системы может независимо обрабатывать локальные данные и принимать соответствующие решения. При выполнении отдельных процессов узлы распределенной системы могут обмениваться информацией через каналы связи с целью обработки данных или получения результатов анализа, представляющего для них взаимный интерес. Распределенная обработка данных (РОД) характерна для сетей ППЭВМ и создаваемых на их основе АРМ РОД и позволяет решать сложные задачи с использованием схемы распараллеливания вычислительного процесса. РОД характеризуется децентрализацией обработки информации с помощью рассредоточенных микро - ЭВМ, которые соединены линиями связи и имеют программно-информационную совместимость. РОД позволяет строить системы, в которых гибко сочетаются достоинства централизации и децентрализации. При разделении вычислительного потенциала системы между несколькими подразделениями предприятия предоставляется возможность локального решения отдельных задач. Так, 80 % задач бухгалтерского учета на предприятии решаются каждым звеном самостоятельно. Затраты, связанные с передачей данных, обычно незначительны. Преимущества распределенной обработки данных выражаются в: · увеличении числа удаленных взаимодействующих пользователей, выполняющих функции сбора, обработки, хранения, передачи информации; · снятии пиковых нагрузок с централизованной базы путем распределения обработки и хранения локальных баз данных на разных ЭВМ; · обеспечении доступа информационному работнику к вычислительным ресурсам сети ЭВМ; · обеспечении обмена данными между удаленными пользователями. Формализация концептуальной схемы данных повлекла за собой возможность классификации моделей представления данных на иерархические, сетевые и реляционные. Это отразилось в понятии архитектуры систем управления базами данных (СУБД) и технологии обработки. Для обработки данных, размещенных на удаленных компьютерах, разработаны сетевые СУБД, а сама база данных называется распределенной. Распределенная обработка и распределенная база данныхне являются синонимами.Если при распределенной обработке производится работа с базой, то подразумевается, что представление данных, содержательная обработка данных базы выполняются на компьютере клиента, а поддержание базы в актуальном состоянии - на файл-сервере. Распределенная база данных может размещаться на нескольких серверах и для доступа к удаленным данным надо использовать сетевую СУБД. Если сетевая СУБД не используется, то реализуется распределенная обработка данных. При распределенной обработке клиент может послать запрос к собственной локальной базе или удаленной. Удаленный запрос- это единичный запрос к одному серверу. Несколько удаленных запросов к одному серверу объединяются в удаленную транзакцию.Если отдельные запросы транзакции обрабатываются различными серверами, то транзакцияназывается распределенной.При этом запрос транзакции обрабатывается одним сервером. Если запространзакции обрабатывается несколькими серверами, он называется распределенным. Только обработка распределенного запроса поддерживает концепцию распределенной базы данных. Существуют разные технологии распределенной обработки данных. Централизованная архитектура. При использовании этой технологии база данных, СУБД и прикладная программа (приложение) располагаются на одном компьютере (мэйнфрейме или персональном компьютере) (Рис.16). Для такого способа организации не требуется поддержки сети и все сводится к автономной работе. Работа построена следующим образом: · База данных в виде набора файлов находится на жестком диске компьютера. · На том же компьютере установлены СУБД и приложение для работы с БД. · Пользователь запускает приложение. Используя предоставляемый приложением пользовательский интерфейс, он инициирует обращение к БД на выборку/обновление информации. · Все обращения к БД идут через СУБД, которая инкапсулирует внутри себя все сведения о физической структуре БД. · СУБД инициирует обращения к данным, обеспечивая выполнение запросов пользователя (осуществляя необходимые операции над данными). · Результат СУБД возвращает в приложение. · Приложение, используя пользовательский интерфейс, отображает результат выполнения запросов.
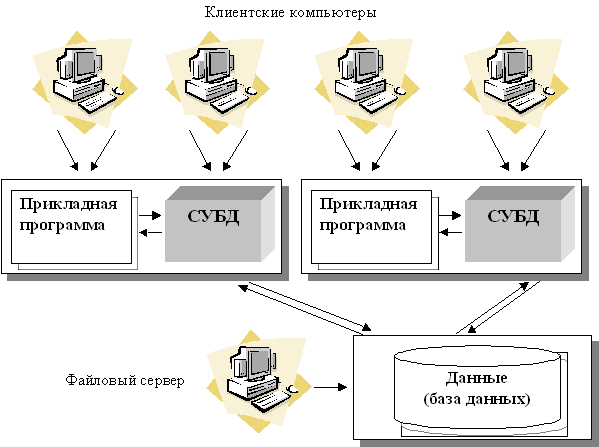
Рис.16. Централизованная архитектура Подобная архитектура использовалась в первых версиях СУБД: DB2; Oracle; Ingres. Многопользовательская технология работы обеспечивалась либо режимом мультипрограммирования, либо режимом разделения времени. Такая технология была распространена в период господства больших. Основным недостатком этой модели является резкое снижение производительности при увеличении числа пользователей. Архитектура «файл-сервер». Эта архитектура баз данных с сетевым доступом предполагает назначение одного из компьютеров сети в качестве выделенного сервера, на котором будут храниться файлы базы данных. В соответствии с запросами пользователей файлы с файл-сервера передаются на рабочие станции пользователей, где и осуществляется основная часть обработки данных. Центральный сервер выполняет в основном только роль хранилища файлов, не участвуя в обработке самих данных (Рис.17). Работа построена следующим образом: · База данных в виде набора файлов находится на жестком диске специально выделенного компьютера (файлового сервера). · Существует локальная сеть, состоящая из клиентских компьютеров, на каждом из которых установлены СУБД и приложение для работы с БД. · На каждом из клиентских компьютеров пользователи имеют возможность запустить приложение. Используя предоставляемый приложением пользовательский интерфейс, он инициирует обращение к БД на выборку/обновление информации. · Все обращения к БД идут через СУБД, которая инкапсулирует внутри себя все сведения о физической структуре БД, расположенной на файловом сервере. · СУБД инициирует обращения к данным, находящимся на файловом сервере, в результате которых часть файлов БД копируется на клиентский компьютер и обрабатывается, что обеспечивает выполнение запросов пользователя (осуществляются необходимые операции над данными). · При необходимости (в случае изменения данных) данные отправляются назад на файловый сервер с целью обновления БД. · Результат СУБД возвращает в приложение. · Приложение, используя пользовательский интерфейс, отображает результат выполнения запросов.
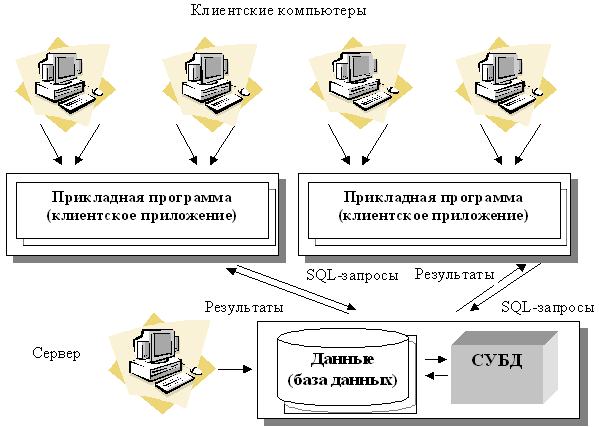
Рис.17. Архитектура «файл-сервер» В рамках архитектуры " файл-сервер " были выполнены первые версии популярных так называемых настольных СУБД, таких, как dBase и Microsoft Access. Отметим основные недостатки данной архитектуры: · При одновременном обращении множества пользователей к одним и тем же данным производительность работы резко падает, т.к. необходимо дождаться пока пользователь, работающий с данными, завершит свою работу. В противном случае возможно затирание исправлений, сделанных одними пользователями, изменениями других пользователей. · Вся тяжесть вычислительной нагрузки при доступе к БД ложится на приложение клиента, так как при выдаче запроса на выборку информации из таблицы вся таблица БД копируется на клиентскую машину и выборка осуществляется на клиенте. Таким образом, неоптимально расходуются ресурсы клиентского компьютера и сети. В результате возрастает сетевой трафик и увеличиваются требования к аппаратным мощностям пользовательского компьютера. · Как правило, используется навигационный подход, ориентированный на работу с отдельными записями. · В БД на файл-сервере гораздо проще вносить изменения в отдельные таблицы, минуя приложения, непосредственно из инструментальных средств (например, из утилиты Database Desktop фирмы Borland для файлов Paradox и dBase); подобная возможность облегчается тем обстоятельством, что фактически у таких СУБД база данных – понятие более логическое, чем физическое, поскольку под БД понимается набор отдельных таблиц, сосуществующих в отдельном каталоге на диске. Все это позволяет говорить о низком уровне безопасности – как с точки зрения хищения и нанесения вреда, так и с точки зрения внесения ошибочных изменений. · Недостаточно развитый аппарат транзакций служит потенциальным источником ошибок в плане нарушения смысловой и ссылочной целостности информации при одновременном внесении изменений в одну и ту же запись. Технология «клиент – сервер». Использование технологии «клиент – сервер» предполагает наличие некоторого количества компьютеров, объединенных в сеть, один из которых выполняет особые управляющие функции (является сервером сети). Так, архитектура «клиент – сервер» разделяет функции приложения пользователя (называемого клиентом) и сервера. Приложение-клиент формирует запрос к серверу, на котором расположена БД, на структурном языке запросов SQL (Structured Query Language), являющемся промышленным стандартом в мире реляционных БД. Удаленный сервер принимает запрос и переадресует его SQL-серверу БД. SQL-сервер – специальная программа, управляющая удаленной базой данных. SQL-сервер обеспечивает интерпретацию запроса, его выполнение в базе данных, формирование результата выполнения запроса и выдачу его приложению-клиенту. При этом ресурсы клиентского компьютера не участвуют в физическом выполнении запроса; клиентский компьютер лишь отсылает запрос к серверной БД и получает результат, после чего интерпретирует его необходимым образом и представляет пользователю. Так как клиентскому приложению посылается результат выполнения запроса, по сети перемещаются только те данные, которые необходимы клиенту. В итоге снижается нагрузка на сеть. Поскольку выполнение запроса происходит там же, где хранятся данные (на сервере), нет необходимости в пересылке больших пакетов данных. Кроме того, SQL-сервер, если это возможно, оптимизирует полученный запрос таким образом, чтобы он был выполнен в минимальное время с наименьшими накладными расходами. Архитектура системы представлена на Рис.18.
Рис.18. Архитектура «клиент-сервер» Все это повышает быстродействие системы и снижает время ожидания результата запроса. При выполнении запросов сервером существенно повышается степень безопасности данных, поскольку правила целостности данных определяются в базе данных на сервере и являются едиными для всех приложений, использующих эту БД. Таким образом, исключается возможность определения противоречивых правил поддержания целостности. Мощный аппарат транзакций, поддерживаемый SQL-серверами, позволяет исключить одновременное изменение одних и тех же данных различными пользователями и предоставляет возможность откатов к первоначальным значениям при внесении в БД изменений, закончившихся аварийно. Итак, в результате работа построена следующим образом: · База данных в виде набора файлов находится на жестком диске специально выделенного компьютера (сервера сети). · СУБД располагается также на сервере сети. · Существует локальная сеть, состоящая из клиентских компьютеров, на каждом из которых установлено клиентское приложение для работы с БД. · На каждом из клиентских компьютеров пользователи имеют возможность запустить приложение. Используя предоставляемый приложением пользовательский интерфейс, он инициирует обращение к СУБД, расположенной на сервере, на выборку/обновление информации. Для общения используется специальный язык запросов SQL, т.е. по сети от клиента к серверу передается лишь текст запроса. · СУБД инкапсулирует внутри себя все сведения о физической структуре БД, расположенной на сервере. · СУБД инициирует обращения к данным, находящимся на сервере, в результате которых на сервере осуществляется вся обработка данных и лишь результат выполнения запроса копируется на клиентский компьютер. Таким образом, СУБД возвращает результат в приложение. · Приложение, используя пользовательский интерфейс, отображает результат выполнения запросов. В архитектуре «клиент – сервер» работают так называемые «промышленные» СУБД. Промышленными они называются из-за того, что именно СУБД этого класса могут обеспечить работу ИС масштаба среднего и крупного предприятия, организации, банка. К разряду промышленных СУБД принадлежат MS SQL Server, Oracle, Gupta, Informix, Sybase, DB2, InterBase и ряд других. Как правило, SQL-сервер обслуживается отдельным сотрудником или группой сотрудников (администраторы SQL-сервера). Они управляют физическими характеристиками баз данных, производят оптимизацию, настройку и переопределение различных компонентов БД, создают новые БД, изменяют существующие и т.д., а также выдают привилегии (разрешения на доступ определенного уровня к конкретным БД, SQL-серверу) различным пользователям. Рассмотрим основные достоинства данной архитектуры по сравнению с архитектурой «файл-сервер»: · Существенно уменьшается сетевой трафик. · Уменьшается сложность клиентских приложений (большая часть нагрузки ложится на серверную часть), а, следовательно, снижаются требования к аппаратным мощностям клиентских компьютеров. · Наличие специального программного средства – SQL-сервера – приводит к тому, что существенная часть проектных и программистских задач становится уже решенной. · Существенно повышается целостность и безопасность БД. К числу недостатков можно отнести более высокие финансовые затраты на аппаратное и программное обеспечение, а также то, что большое количество клиентских компьютеров, расположенных в разных местах, вызывает определенные трудности со своевременным обновлением клиентских приложений на всех компьютерах-клиентах. Тем не менее, архитектура «клиент – сервер» хорошо зарекомендовала себя на практике, в настоящий момент существует и функционирует большое количество БД, построенных в соответствии с данной архитектурой. Трехзвенная (многозвенная) архитектура «клиент – сервер». Трехзвенная (в некоторых случаях многозвенная ) архитектура (N-tier или multi-tier) представляет собой дальнейшее совершенствование технологии «клиент – сервер». Рассмотрев архитектуру «клиент – сервер», можно заключить, что она является 2-звенной: первое звено – клиентское приложение, второе звено – сервер БД + сама БД. В трехзвенной архитектуре вся бизнес-логика (деловая логика), ранее входившая в клиентские приложения, выделяется в отдельное звено, называемое сервером приложений. При этом клиентским приложениям остается лишь пользовательский интерфейс. Так, в качестве клиентского приложения в большинстве современных систем выступает Web-браузер. Что улучшается при использовании трехзвенной архитектуры? Теперь при изменении бизнес-логики больше нет необходимости изменять клиентские приложения и обновлять их у всех пользователей. Кроме того, максимально снижаются требования к аппаратуре пользователей. Итак, в результате работа организована следующим образом: · База данных в виде набора файлов находится на жестком диске специально выделенного компьютера (сервера сети). · СУБД располагается также на сервере сети. · Существует специально выделенный сервер приложений, на котором располагается программное обеспечение (ПО) делового анализа (бизнес-логика). · Существует множество клиентских компьютеров, на каждом из которых установлен так называемый " тонкий клиент" – клиентское приложение, реализующее интерфейс пользователя. · На каждом из клиентских компьютеров пользователи имеют возможность запустить приложение – тонкий клиент. Используя предоставляемый приложением пользовательский интерфейс, он инициирует обращение к ПО делового анализа, расположенному на сервере приложений. · Сервер приложений анализирует требования пользователя и формирует запросы к БД. Для общения используется специальный язык запросов SQL, т.е. по сети от сервера приложений к серверу БД передается лишь текст запроса. · СУБД инкапсулирует внутри себя все сведения о физической структуре БД, расположенной на сервере. · СУБД инициирует обращения к данным, находящимся на сервере, в результате которых результат выполнения запроса копируется на сервер приложений. · Сервер приложений возвращает результат в клиентское приложение (пользователю). · Приложение, используя пользовательский интерфейс, отображает результат выполнения запросов. Платформу сервера баз данных определяют операционная система компьютера клиента и сетевая операционная система. Под платформойпонимают тип процессора, операционной системы, добавочного оборудования и поддерживающих его программных средств, на которых можно установить новое приложение. Сетевые операционные системы серверов баз данных - Unix, Windows 2003 и выше, Linux, FreeBSD и др. В настоящее время наиболее популярными серверами баз данных являются Microsoft SQL-server, SQLbase-server, Oracle-server и др. Совмещение гипертекстовой технологии с технологией баз данных позволило создать распределенные гипертекстовые базы данных. Разрабатываются гипертекстовые модели внутренней структуры базы данных и размещения баз данных на серверах. Гипертекстовые базы данных содержат гипертекстовые документы и обеспечивают самый быстрый доступ к удаленным данным. Гипертекстовые документы могут быть текстовыми, цифровыми, графическими, аудио- и видеофайлами. Тем самым создаются распределенные мультимедийные базы. Гипертекстовые базы данных созданы по многим предметным областям. Практически ко всем обеспечивается доступ через интернет. Примерами гипертекстовых баз данных являются правовые системы: Гарант, Юсис, КонсультантПлюс и др. Популярное:
|
Последнее изменение этой страницы: 2016-04-10; Просмотров: 1761; Нарушение авторского права страницы