
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Основные свойства линейных кодов
1. Произведение любого кодового слова
2. Произведение некоторого кодового слова 3. Между порождающей и проверочной матрицами в систематическом виде существует однозначное соответствие, а именно: 4. Кодовое расстояние d0 (n, k) - кода равно минимальному числу линейно зависимых столбцов проверочной матрицы 5. Произведение информационного слова на порождающую матрицу дает кодовое слово кода 6. Два кода называются эквивалентными, если их порождающие матрицы отличаются перестановкой координат, т.е. порождающие матрицы получаются одна за другой перестановкой столбцов и элементарных операций над строками. 7. Кодовое расстояние любого линейного (n, k) - кода удовлетворяет неравенству Оптимальное кодирование Кодирование, минимизирующее избыточность кода, называется оптимальным Вопрос существования таких кодов составляет суть одной из основных теорем теории информации – теоремы кодирования, доказанной К. Шенноном. Приведем одну из эквивалентных формулировок данной теоремы. Теорема кодирования. Сообщения произвольного источника информации Z с энтропией H(Z) всегда можно закодировать последовательностями в алфавите B, состоящем из M символов, так, что средняя длина кодового слова lср будет сколь угодно близка к величине Доказательство этой теоремы в силу его сложности не рассматривается. Теорема утверждает, что разность (lср – lmin) можно сделать как угодно малой. В этом и заключается задача методов оптимального кодирования. Вернемся к рассмотрению алфавитного источника информации, генерирующего сообщения в символах алфавита А. Поскольку избыточность кода L задается формулой
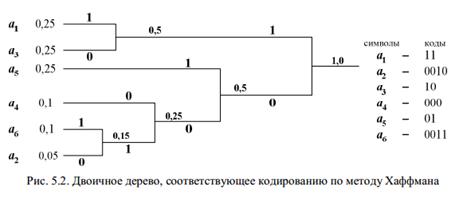
очевидно, что чем меньше lср, тем оптимальнее код. Для уменьшения lср следует кодировать часто встречающиеся символы более короткими словами и наоборот. На соблюдении этого требования основаны все методы оптимального кодирования. Кроме того, для обеспечения декодирования неравномерного кода важно соблюдать принцип префиксности: никакое кодовое слово не должно являться началом другого кодового слова. Приведем два наиболее известных метода оптимального побуквенного кодирования. Для простоты изложения возьмем двоичный алфавит B = {0, 1} в качестве кодового. Метод Шеннона – Фано Шаг 1. Упорядочиваем символы исходного алфавита в порядке невозрастания их вероятностей. (Записываем их в строку.) Шаг 2. Не меняя порядка символов, делим их на две группы так, чтобы суммарные вероятности символов в группах были по возможности равны. Шаг 3. Приписываем группе слева " 0", а группе справа " 1" в качестве элементов их кодов. Шаг 4. Просматриваем группы. Если число элементов в группе более одного, идем на Шаг 2. Если в группе один элемент, построение кода для него завершено. Рассмотрим работу описанного алгоритма на примере кодирования алфавита Очевидно, что процесс построения кода в общем случае содержит неоднозначность, так как мы не всегда можем поделить последовательность на два равновероятных подмножества. Либо слева, либо справа сумма вероятностей будет больше. Критерием лучшего варианта является меньшая избыточность кода. Заметим также, что правильное считывание кода – от корня дерева к символу – обеспечит его префиксность. Метод Хаффмана Шаг 1. Упорядочиваем символы исходного алфавита в порядке невозрастания их вероятностей. (Записываем их в столбец.) Шаг 2. Объединяем два символа с наименьшими вероятностями. Символу с большей вероятностью приписываем " 1", символу с меньшей – " 0" в качестве элементов их кодов. Шаг 3. Считаем объединение символов за один символ с вероятностью, равной сумме вероятностей объединенных символов. Шаг 4. Возвращаемся на Шаг 2 до тех пор, пока все символы не будут объединены в один с вероятностью, равной единице. Закодируем тот же 6-буквенный алфавит методом Хаффмана, изобразив соответствующее двоичное дерево (рис. 5.2).
Считывание кода идет от корня двоичного дерева к его вершинам с обозначением символов. Это обеспечивает префиксность кода. Метод Хаффмана также содержит неоднозначность, поскольку в алфавите могут оказаться несколько символов с одинаковой вероятностью, и код будет зависеть от того, какие символы мы будем объединять в первую очередь. Мы видим, что код Шеннона – Фано и код Хаффмана для заданного алфавита отличаются. На вопрос, какой из них лучше, даст ответ проверка на оптимальность. Описанные методы легко применить не только для двоичного кодирования, но и для кодирования алфавитом, содержащим произвольное число символов M. В этом случае в методе Шеннона – Фано идет разбиение последовательности символов на M равновероятных групп, в методе Хаффмана – объединение в группы по M символов. Проверка кода на оптимальность. Для оценивания оптимальности кода используют разные критерии. Основным показателем является коэффициент относительной оптимальности kопт, вычисляемый по формуле, Из теоремы кодирования следует, что эта величина не превышает единицы. И чем меньше она отличается от единицы, тем более эффективным считается код. Следующая характеристика оптимальности кода обусловлена оценкой распределения символов кодового алфавита: код тем ближе к оптимальному, чем меньше различаются вероятности появления различных символов кодового алфавита в закодированном сообщении. Среднее число появлений
где N – объем кодового алфавита;
Сверточные коды В последние годы усиленно разрабатываются сверточные коды. Формирование проверочных символов в таких кодах осуществляется по рекуррентным правилам, поэтому сверточные коды часто называют рекуррентными или цепными. Особенностью сверточных кодов является то, что они формируются непрерывно, и в них проверочные символы перемежаются с информационными по всей длине кодовой последовательности, подчиняясь одному и тому же рекуррентному соотношению. Максимальное число информационных символов, участвующих в формировании каждого выходного символа сверточного кода, определяемое числом ячеек регистра сдвига, носит название длины кодовых ограничений. Эта характеристика близка по смыслу к длине блока информационных символов для блочных кодов. Непрерывные коды не разбиваются на блоки. Операции кодирования и декодирования производятся над непрерывной последовательностью символов. Самые распространенные и удобные для практического применения среди непрерывных - сверточные коды. В непрерывных кодах процесс кодирования и декодирования носит непрерывный характер. Каждый избыточный ( проверочный) символ формируется по двум или нескольким информационным символам. Проверочные символы размещаются в определенном порядке между информационными символами исходной последовательности. Этот класс кодов появился совсем недавно и не получил пока широкого развития. Циклические коды Циклический код — линейный код, обладающий свойством цикличности, то есть каждая циклическая перестановка кодового слова также является кодовым словом. Используется для преобразования информации для защиты еѐ от ошибок Циклические коды составляют большую группу наиболее широко используемых на практике линейных, систематических кодов. Их основное свойство, давшее им название, состоит в том, что каждый вектор, получаемый из исходного кодового вектора путем циклической перестановки его символов, также является разрешенным кодовым вектором. Принято описывать циклические коды (ЦК) при помощи порождающих полиномов G(Х) степени m = n – k, где m – число проверочных символов в кодовом слове. В связи с этим ЦК относятся к разновидности полиномиальных кодов. Операции кодирования и декодирования ЦК сводятся к известным процедурам умножения и деления полиномов. Для двоичных кодов эти операции легко реализуются технически с помощью линейных переключательных схем (ЛПС), при этом получаются относительно простые схемы кодеков, в чем состоит одно из практических достоинств ЦК. Эффективное кодирование Эффективное кодирование устраняет избыточность, приводит к сокращению длины сообщений, а значит, позволяет уменьшить время передачи или объем памяти, необходимой для их хранения. Рассмотрим код Хаффмана и алгоритм Шеннона-Фано . Код Хаффмана - статистический способ сжатия, который дает снижение средней длины кода используемого для представления символов фиксированного алфавита. Код Хаффмана является примером кода, оптимального в случае, когда все вероятности появления символов в сообщении - целые отрицательные степени двойки. Код Хаффмана может быть построен по следующему алгоритму: 1. Выписываем в ряд все символы алфавита в порядке возрастания или убывания вероятности их появления в тексте; 2. Последовательно объединяем два символа с наименьшими вероятностями появления в новый составной символ, вероятность появления которого полагается равной сумме вероятностей составляющих его символов; в конце концов, мы построим дерево, каждый узел которого имеет суммарную вероятность всех узлов, находящихся ниже него; 3. Прослеживаем путь к каждому листу дерева помечая направление к каждому узлу (например, направо - 1, налево - 0). Для заданного распределения частот символов может существовать несколько возможных кодов Хаффмана, - это дает возможность определить каноническое дерево Хаффмана, соответствующее наиболее компактному представлению исходного текста. Близким по технике построения к коду Хаффмана являются коды Шеннона-Фано, предложенные Шенноном и Фано в 1948-49 гг. независимо друг от друга. Их построение может быть осуществлено следующим образом: 1. Выписываем в ряд все символы в порядке возрастания вероятности появления их в тексте; 2. Последовательно делим множество символов на два подмножества так, чтобы сумма вероятностей появления символов одного подмножества была примерно равна сумме вероятностей появления символов другого. Для левого подмножества каждому символу приписываем " 0", для правого - " 1". Дальнейшие разбиения повторяются до тех пор, пока все подмножества не будут состоять из одного элемента. Алгоритм создания кода Хаффмана называется " снизу-вверх", а Шеннона-Фано - " сверху-вниз". Преимуществами данных методов являются их очевидная простота реализации и, как следствие этого, высокая скорость кодирования/декодирования. Основным недостатком - неоптимальность в общем случае. Помехоустойчивое кодирование Для обеспечения высокой достоверности передачи информации по каналу с помехами применяют помехоустойчивое кодирование. Помехоустойчивые коды должны обеспечивать как обнаружение, так и исправление ошибок (корректирующие коды), т.е. кодирование должно осуществляться так, чтобы сигнал, соответствующий последовательности символов, после воздействия на него предполагаемой в канале помехи оставался ближе к сигналу, соответствующему конкретной переданной последовательности символов, чем к сигналам, соответствующим другим возможным последовательностям. Степень близости обычно определяется по числу разрядов, в которых последовательности отличаются друг от друга. Это достигается ценой введения при кодировании избыточности (избыточных, дополнительных символов), которая позволяет так выбрать передаваемые последовательности символов, чтобы они удовлетворяли дополнительным условиям, проверка которых на приемной стороне дает возможность обнаружить и исправить ошибки. Все помехоустойчивые коды можно разделить на два типа: - обнаруживающие (проверочные EDC – Error Detection Code); - корректирующие (ECC – Error Correction Code).
У подавляющего большинства существующих в настоящее время помехоустойчивых кодов избыточность является следствием их алгебраической структуры. В связи с этим их называют алгебраическими кодами. Алгебраические коды можно подразделить на два больших класса: блоковые и непрерывные. В случае блоковых кодов процедура кодирования заключается в сопоставлении каждой букве сообщения (или, что чаще, последовательности из k двоичных символов, соответствующих этой букве) блока из n двоичных символов. Блоковый код называют равномерным, если n остается постоянным для всех букв сообщения. Отношение k/n определяют как относительную скорость кода. Различают разделимые и неразделимые блоковые коды. При кодировании разделимыми кодами выходные последовательности состоят из символов, роль которых может быть четко разграничена. Это, во-первых, k информационных символов, совпадающих с символами последовательности, поступающей на вход кодера, во-вторых, (n-k) избыточных (проверочных) символов, вводимых в исходную последовательность кодером, и служащих для обнаружения и исправления ошибок. При кодировании неразделимыми кодами разделить символы выходной последовательности на информационные и проверочные невозможно. Непрерывными (древовидными) называют такие коды, в которых введение избыточных символов в кодируемую последовательность информационных символов осуществляется непрерывно, без разделения ее на независимые блоки. Использование избыточности для обнаружения ошибок Пусть на вход кодера поступает последовательность из k информационных двоичных символов. На выходе ей соответствует последовательность из n двоичных символов, причем n> k. Всего может быть 2k различных входных и 2n различных выходных последовательностей. Из общего числа 2n выходных последовательностей только 2k последовательностей соответствуют входным. Назовем их разрешенными кодовыми комбинациями. Остальные 2n-2k возможные выходные последовательности для передачи не используются. Они могут возникнуть лишь в результате ошибки передачи. Назовем их запрещенными комбинациями. Каждая из 2k разрешенных комбинаций в результате действия помех может трансформироваться в любую другую, всего имеется 2k2n возможных случаев передачи. В это число входят: · 2k случаев безошибочной передачи ( ); · 2k(2k-1) случаев перехода в другие разрешенные комбинации, что соответствует необнаруживаемым ошибкам ( ); · 2k(2n-2k) случаев перехода в неразрешенные комбинации, которые могут быть обнаружены ( ).
Большинство разработанных до настоящего времени кодов предназначено для корректирования взаимно-независимых ошибок определенной кратности и пачек (пакетов) ошибок. Взаимно-независимыми ошибками будем называть такие искажения в передаваемой последовательности символов, при которых вероятность появления любой комбинации искаженных символов зависит только от числа искаженных символов r и вероятности искажения одного символа p. Эти ошибки чаще всего вызываются флуктуационными помехами. Кратностью ошибки называют количество искаженных символов в кодовой комбинации. Наиболее вероятны ошибки меньшей кратности. Их и следует обнаруживать и исправлять в первую очередь. Геометрический подход к кодированию Методам вычисления скорости передачи информации R и пропускной способности С дискретного канала без памяти, может быть дано геометрическое толкование, которое приводит к новым результатам и новому пониманию свойств этих величин. Пусть канал определен матрицей
Можно рассматривать каждую строку этой матрицы как вектор или точку в (b—1)-мерном равностороннем симплексе – Таким образом, с входом i связывается точка или вектор
Вектору или точке Q симплекса соответствуют также вероятности букв на выходе. Тогда j-я компонента этого вектора равна
Поскольку Теперь для удобства обозначений определим энтропию точки или вектора из симплекса как энтропию барицентрических координат точки, интерпретированных как вероятности. Таким образом, имеем
В этих обозначениях скорость передачи R для данной системы вероятностей на входе
Функция
является отрицательно определенной формой. Это справедливо для пространства всех неотрицательных Следовательно, скорость R, о которой шла речь выше, всегда неотрицательна. Н строго выпукла (без плоских участков), и R положительна, если только Процесс вычисления R может быть легко изображен наглядно в случае двух или трех букв на выходе. Если на выходе имеется три буквы, то представим себе равносторонний треугольник на некоторой основной плоскости. Это будет симплекс, содержащий точки Популярное:
|
Последнее изменение этой страницы: 2016-04-11; Просмотров: 2435; Нарушение авторского права страницы
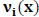 на транспонированную проверочную матрицу дает нулевой вектор размерности
на транспонированную проверочную матрицу дает нулевой вектор размерности 
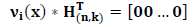
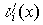 , т.е. с ошибкой, на транспонированную проверочную матрицу называется синдромом и обозначается Si(x) Термодинамический потенциал Гиббса Лекции по физике
, т.е. с ошибкой, на транспонированную проверочную матрицу называется синдромом и обозначается Si(x) Термодинамический потенциал Гиббса Лекции по физике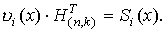


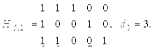
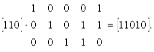
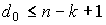 (граница Сингтона). Линейный (n, k) - код, удовлетворяющий равенству
(граница Сингтона). Линейный (n, k) - код, удовлетворяющий равенству 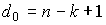 , называется кодом с максимальным расстоянием.
, называется кодом с максимальным расстоянием.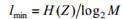 , но не меньше нее.
, но не меньше нее.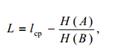
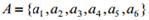 , символы которого встречаются с вероятностями (0, 25; 0, 05; 0, 25; 0, 1; 0, 25; 0, 1) соответственно. Результат кодирования изображен на рис. 5.1.
, символы которого встречаются с вероятностями (0, 25; 0, 05; 0, 25; 0, 1; 0, 25; 0, 1) соответственно. Результат кодирования изображен на рис. 5.1. 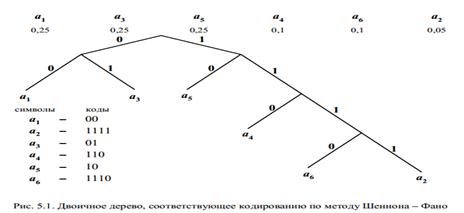
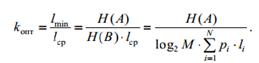
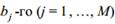 символа кодового алфавита можно оценить по формуле
символа кодового алфавита можно оценить по формуле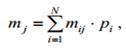
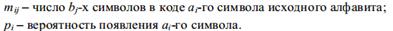
 вероятностей перехода от буквы i на входе к букве j на выходе
вероятностей перехода от буквы i на входе к букве j на выходе
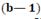 -мерный аналог отрезка прямой, равностороннего треугольника, тетраэдра и т. д. Координатами точки являются ее расстояния от граней, в сумме равные единице. Они известны под названием барицентрических координат.
-мерный аналог отрезка прямой, равностороннего треугольника, тетраэдра и т. д. Координатами точки являются ее расстояния от граней, в сумме равные единице. Они известны под названием барицентрических координат. Его компоненты равны вероятностям различных букв на выходе, если используются все входы. Если использованы все входы (с вероятностью
Его компоненты равны вероятностям различных букв на выходе, если используются все входы. Если использованы все входы (с вероятностью  то вероятности букв на выходе даются компонентами векторной суммы.
то вероятности букв на выходе даются компонентами векторной суммы.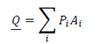
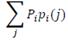
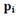 неотрицательны и в сумме дают единицу, то точки Q лежат в выпуклой оболочке (или барицентрической оболочке) точек
неотрицательны и в сумме дают единицу, то точки Q лежат в выпуклой оболочке (или барицентрической оболочке) точек 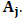 Более того, любая точка в этой выпуклой оболочке может быть получена при подходящем выборе
Более того, любая точка в этой выпуклой оболочке может быть получена при подходящем выборе 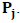
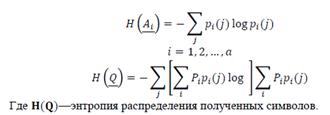
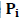 задается формулой
задается формулой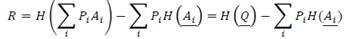
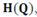 где Q — точка симплекса, является выпуклой кверху функцией. Так, если компоненты Q равны
где Q — точка симплекса, является выпуклой кверху функцией. Так, если компоненты Q равны 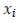 то имеем:
то имеем: 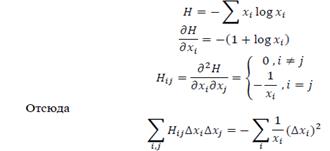
 и отсюда, конечно, и для подпространства, в котором
и отсюда, конечно, и для подпространства, в котором 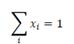
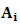 не равно Q для всех тех i, для которых
не равно Q для всех тех i, для которых 
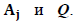 Сверху этот треугольник покрыт куполообразной поверхностью, как показано на рис. 1.
Сверху этот треугольник покрыт куполообразной поверхностью, как показано на рис. 1.