
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Примитивный 2-ичный (15,7,5) код
Пусть q=2 требуемая длина кода Код Рида-Соломона Коды Рида — Соломона являются важным частным случаем БЧХ-кода, корни порождающего полинома которого лежат в том же поле, над каким и строится код (m=1) Пусть α — элемент поля GF(q) порядка n. Если α — примитивный элемент, то его порядок равен q-1 то есть Где — Длина полученного кода n, минимальное расстояние d (минимальное расстояние d линейного кода является минимальным из всех расстояний Хемминга всех пар кодовых слов, см. Линейный код). Код содержит r= d – 1= Таким образом d= n-k-1 и код Рида — Соломона является разделимым кодом с максимальным расстоянием. Кодовый полином c(x) может быть получен из информационного полинома m(x), Свойства Код Рида — Соломона над GF(q), исправляющий t ошибок, требует 2t проверочных символов и с его помощью исправляются произвольные пакеты ошибок длиной t и меньше. Согласно теореме о границе Рейгера, коды Рида — Соломона являются оптимальными с точки зрения соотношения длины пакета и возможности исправления ошибок. Теорема (граница Рейгера). Каждый линейный блоковый код, исправляющий все пакеты длиной t и менее, должен содержать, по меньшей мере, 2t проверочных символов. Исправление многократных ошибок Код Рида — Соломона является одним из наиболее мощных кодов, исправляющих многократные пакеты ошибок. Применяется в каналах, где пакеты ошибок могут образовываться столь часто, что их уже нельзя исправлять с помощью кодов, исправляющих одиночные ошибки. Пример построения: 16-ричный (15, 11) код Рида — Соломона Пусть t = 2, l0 = 1. Тогда g(x) = (x − α )(x − α 2)(x − α 3)(x − α 4) = x4 + α 13x3 + α 6x2 + α 3x + α 10. Степень g(x) равна 4, n − k = 4 и k = 11. Каждому элементу поля GF(16) можно сопоставить 4 бита. Информационный многочлен является последовательностью 11 символов из GF(16), что эквивалентно 44 битам, а все кодовое слово является набором из 60 бит. Кодирование При операции кодирования информационный полином умножается на порождающий многочлен. Умножение исходного слова S длины k на неприводимый полином при систематическом кодировании можно выполнить следующим образом: · К исходному слову приписываются 2t нулей, получается полином · Этот полином делится на порождающий полином G, находится остаток R, · Этот остаток и будет корректирующим кодом Рида — Соломона, он приписывается к исходному блоку символов. Полученное кодовое слово Кодировщик строится из сдвиговых регистров, сумматоров и умножителей. Сдвиговый регистр состоит из ячеек памяти, в каждой из которых находится один элемент поля Галуа.
Декодирование Декодировщик, работающий по авторегрессивному спектральному методу декодирования, последовательно выполняет следующие действия: · Вычисляет синдром ошибки · Строит полином ошибки · Находит корни данного полинома · Определяет характер ошибки · Исправляет ошибки Вычисление синдрома ошибки Вычисление синдрома ошибки выполняется синдромным декодером, который делит кодовое слово на порождающий многочлен. Если при делении возникает остаток, то в слове есть ошибка. Остаток от деления является синдромом ошибки. Построение полинома ошибки Вычисленный синдром ошибки не указывает на положение ошибок. Степень полинома синдрома равна 2t, что много меньше степени кодового слова n. Для получения соответствия между ошибкой и ее положением в сообщении строится полином ошибок. Полином ошибок реализуется с помощью алгоритма Берлекэмпа — Месси, либо с помощью алгоритма Евклида. Алгоритм Евклида имеет простую реализацию, но требует больших затрат ресурсов. Поэтому чаще применяется более сложный, но менее затратоемкий алгоритм Берлекэмпа — Месси. Коэффициенты найденного полинома непосредственно соответствуют коэффициентам ошибочных символов в кодовом слове. Нахождение корней На этом этапе ищутся корни полинома ошибки, определяющие положение искаженных символов в кодовом слове. Реализуется с помощью процедуры Ченя, равносильной полному перебору. В полином ошибок последовательно подставляются все возможные значения, когда полином обращается в ноль — корни найдены. Определение характера ошибки и ее исправление По синдрому ошибки и найденным корням полинома с помощью алгоритма Форни определяется характер ошибки и строится маска искаженных символов. Эта маска накладывается на кодовое слово с помощью операции XOR и искаженные символы восстанавливаются. После этого отбрасываются проверочные символы и получается восстановленное информационное слово. Выбор образующего многочлена в циклическом коде Порождающим полиномом циклического ( n, k ) кода C называется такой ненулевой полином: из C, степень которого наименьшая и коэффициент при старшей степени Теорема 1 Если C – циклический (n, k) код и где степень m(x) меньше или равна k-1 Теорема 2
Следствия: таким образом в качестве порождающего полинома можно выбирать любой полином, делитель Кодер (декодер) Витерби Сущность метода. Наилучшей схемой декодирования корректирующих кодов является декодирование методом максимального правдоподобия, когда декодер определяет набор условных вероятностей Для двоичного симметричного канала без памяти (канала, в котором вероятности передачи 0 и 1, а также вероятности ошибок вида 0 -> 1 и 1 -> 0 одинаковы, ошибки в j -м и i -м символах кода независимы) декодер максимального правдоподобия сводится к декодеру минимального хеммингова расстояния. Последний вычисляет расстояние Хемминга между принятой последовательностью r и всеми возможными кодовыми векторами Принцип работы декодера На вход декодера поступает сегмент последовательности r длиной b, превышающей кодовую длину блока n. Назовем b окном декодирования. Сравним все кодовые слова данного кода (в пределах сегмента длиной b ) с принятым словом и выберем кодовое слово, ближайшее к принятому. Первый информационный кадр выбранного кодового слова принимается в качестве оценки информационного кадра декодированного слова. После этого в декодер вводится n0 новых символов, а введенные ранее самые старые n0символов сбрасываются, и процесс повторяется для определения следующего информационного кадра. Таким образом, декодер Витерби последовательно обрабатывает кадр за кадром, двигаясь по решетке, аналогичной используемой кодером. В каждый момент времени декодер не знает, в каком узле находится кодер, и не пытается его декодировать. Вместо этого декодер по принятой последовательности определяет наиболее правдоподобный путь к каждому узлу и определяет расстояние между каждым таким путем и принятой последовательностью. Это расстояние называется мерой расходимости пути. В качестве оценки принятой последовательности выбирается сегмент, имеющий наименьшую меру расходимости. Путь с наименьшей мерой расходимости называется выжившим путем. Популярное:
|
Последнее изменение этой страницы: 2016-04-11; Просмотров: 2045; Нарушение авторского права страницы
 и минимальное расстояние
и минимальное расстояние  Возьмем α — примитивный элемент поля GF(16) и
Возьмем α — примитивный элемент поля GF(16) и  — четыре подряд идущих степеней элемента α . Они принадлежат двум циклотомическим классам над полем GF(2), которыми соответствуют неприводимые полиномы
— четыре подряд идущих степеней элемента α . Они принадлежат двум циклотомическим классам над полем GF(2), которыми соответствуют неприводимые полиномы  Тогда полином
Тогда полином  имеет в качестве корней элементы
имеет в качестве корней элементы  и является порождающим полиномом БЧХ-кода с параметрами (15, 7, 5).
и является порождающим полиномом БЧХ-кода с параметрами (15, 7, 5). 
 Тогда нормированный полином
Тогда нормированный полином  минимальной степени над полем
минимальной степени над полем  корнями которого являются d-1 подряд идущих степеней
корнями которого являются d-1 подряд идущих степеней  элемента α, является порождающим полиномом кода Рида — Соломона над полем GF(q).
элемента α, является порождающим полиномом кода Рида — Соломона над полем GF(q). 
 некоторое целое число (в том числе 0 и 1), с помощью которого иногда удается упростить кодер. Обычно полагается
некоторое целое число (в том числе 0 и 1), с помощью которого иногда удается упростить кодер. Обычно полагается  . Степень многочлена равна
. Степень многочлена равна  d-1.
d-1.  проверочных символов, где
проверочных символов, где  обозначает степень полинома; число информационных символов k=n–r=n –d+ 1.
обозначает степень полинома; число информационных символов k=n–r=n –d+ 1. 
 код Рида — Соломона над полем
код Рида — Соломона над полем 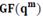 кодовым расстоянием
кодовым расстоянием  можно рассматривать как
можно рассматривать как  код над полем GF(q) который может исправлять любую комбинацию ошибок, сосредоточенную в t или меньшем числе блоков из m символов. Наибольшее число блоков длины m, которые может затронуть пакет длины, где
код над полем GF(q) который может исправлять любую комбинацию ошибок, сосредоточенную в t или меньшем числе блоков из m символов. Наибольшее число блоков длины m, которые может затронуть пакет длины, где  не превосходит
не превосходит  поэтому код, который может исправить t блоков ошибок, всегда может исправить и любую комбинацию из p пакетов общей длины l, если
поэтому код, который может исправить t блоков ошибок, всегда может исправить и любую комбинацию из p пакетов общей длины l, если 


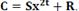

 1
1 его порождающий полином, тогда степень
его порождающий полином, тогда степень  равна
равна  и каждое кодовое слово может быть единственным образом представлено в виде
и каждое кодовое слово может быть единственным образом представлено в виде
 — порождающий полином циклического ( n, k ) кода является делителем двучлена
— порождающий полином циклического ( n, k ) кода является делителем двучлена 
 Степень выбранного полинома будет определять количество проверочных символов r, число информационных символов
Степень выбранного полинома будет определять количество проверочных символов r, число информационных символов 
 соответствующих всем возможным кодовым векторам
соответствующих всем возможным кодовым векторам  и решение принимает в пользу кодового слова, соответствующего максимальному
и решение принимает в пользу кодового слова, соответствующего максимальному 
 и выносит решение в пользу того вектора, который оказывается ближе к принятому. Естественно, что в общем случае такой декодер оказывается очень сложным и при больших размерах кодов n и k практически нереализуемым. Характерная структура сверточных кодов (повторяемость структуры за пределами окна длиной n ) позволяет создать вполне приемлемый по сложности декодер максимального правдоподобия.
и выносит решение в пользу того вектора, который оказывается ближе к принятому. Естественно, что в общем случае такой декодер оказывается очень сложным и при больших размерах кодов n и k практически нереализуемым. Характерная структура сверточных кодов (повторяемость структуры за пределами окна длиной n ) позволяет создать вполне приемлемый по сложности декодер максимального правдоподобия.