|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Сравнение P2P и клиент-серверной технологий⇐ ПредыдущаяСтр 16 из 16
В отличие от традиционной клиент-серверной архитектуры в P2P-сетях каждый узел, входящий в вычислительную сеть, может являться как клиентом, так и сервером, предоставляя или используя ресурсы сети. На рис. 55 представ- лены связи в сетях с P2P и с централизованной архитектурой [49].
Можно выделить следующие проблемы клиент-серверной архитектуры, связанные с наличием централизованного сервера, обеспечивающего обработку запросов от множества клиентов: Проблемы масштабируемости. При увеличении количества клиентов рас- тут требования к мощности сервера и пропускной способности канала. Единственным вариантом решения данной задачи является наращивание пропускной способности канала до сервера и использование более высоко- производительных решений для аппаратной платформы сервера; Зависимость. Стабильная работа всех клиентов зависит от загруженности и функционирования одного сервера. При выходе из строя или отключе- нии сервера, клиенты не смогут выполнять функциональные обязанности. Этим проблемам можно противопоставить следующие преимущества P2P: отсутствие зависимости от централизованных сервисов и ресурсов; система может пережить серьезное изменение в структуре сети; высокая масштабируемость модели одноранговых вычислений. На рис. 56 представлена диаграмма, позволяющая сравнить принципы этих архитектур. На основе этой диаграммы можно сделать предположение, что нет четкой границы между архитектурой P2P и клиент-серверной архитектурой. Обе модели могут быть построены с реализацией в различной степени каких- либо характеристик (например, управляемость), функциональности, структур (например, иерархии и сети) и др. Они могут выполняться на различных плат- формах (Интернет, Интранет и др.), и обе могут служить в качестве базы для приложений. Таким образом, понятие P2P чрезвычайно тесно переплетено с другими существующими технологиями.
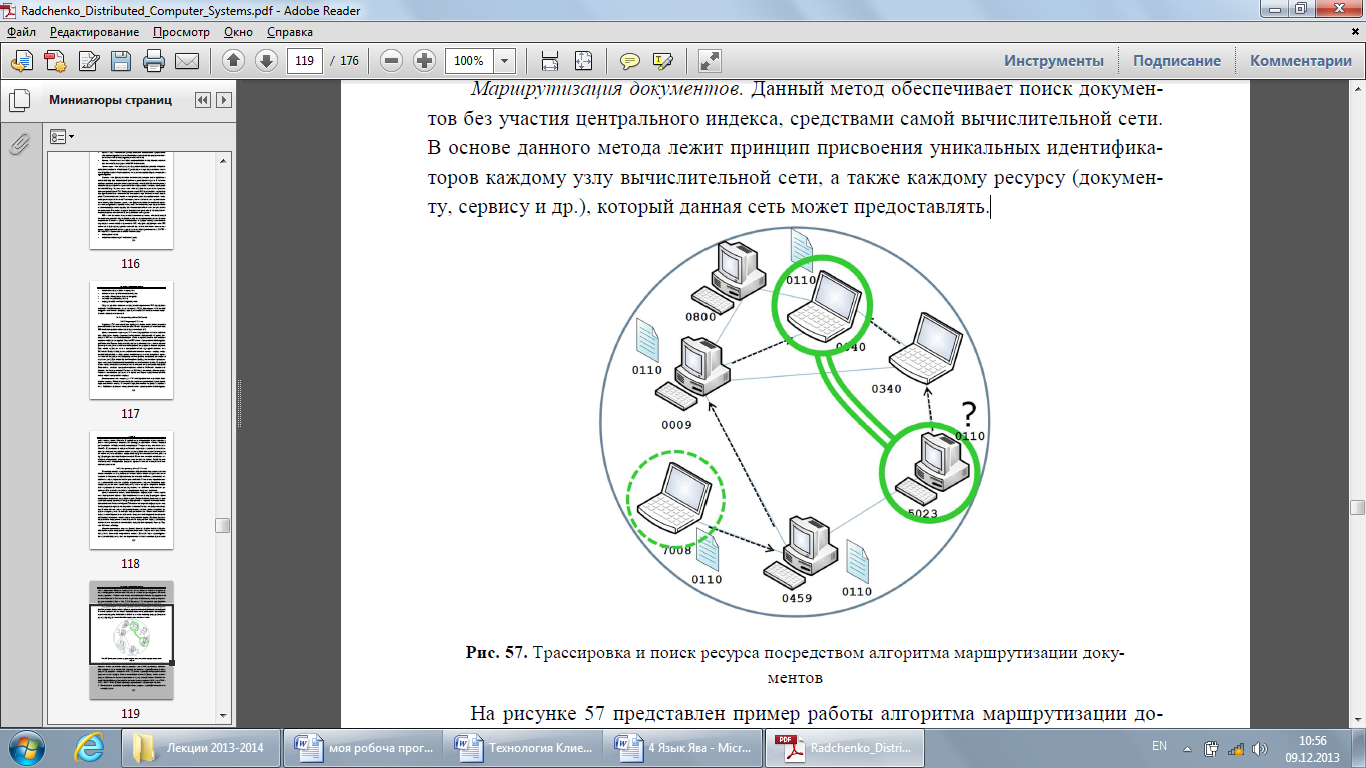
Рис. 56. Сравнение P2P и централизованной (клиент-серверной) архитектур Задачи P2P сетей Можно выделить следующие основные задачи, которые с легкостью ре- шают P2P сети: 1. Уменьшение/распределение затрат. Серверы централизованных систем, которые обслуживают большое количество клиентов, обычно несут на себе основной объем затрат ресурсов (денежных, вычислительных и др.) на поддержание вычислительной системы. P2P архитектура может помочь распределить эти затраты между узлами сети. Так как узлы, как правило, автономны, важно, чтобы затраты были распределены справедливо. 2. Объединение ресурсов. Каждый узел в P2P-системе обладает определен- ными ресурсами (вычислительные мощности, объем памяти). Приложения, которым необходимо большое количество ресурсов, например ресурсоза- тратные задачи моделирования или распределенные файловые системы, используют возможность объединения ресурсов всей сети для решения своей задачи. При этом важны как объем дискового пространства для хра- нения данных, так и пропускная способность сети. 3. Повышенная масштабируемость. Поскольку в сетях Р2Р отсутствует сильный центральный механизм, важной задачей является повышение масштабируемости и надежности системы. Масштабируемость определяет количество систем, которые могут быть достигнуты из одного узла, сколь- ко систем могут функционировать одновременно, сколько пользователей может пользоваться сетью, сколько памяти может быть использовано. Надежность сети определяется такими параметрами как количество сбоев в работе сети, отношение времени простоя к общему времени работы, до- ступностью ресурсов и т.д. Таким образом, основной проблемой становит- ся разработка новых алгоритмов обнаружения ресурсов, на которых бази- руются новые P2P платформы. 4. Анонимность. Бывает, пользователь не желает, чтобы другие пользователи или поставщики услуг знали о его нахождении в сети. При использовании центрального сервера трудно обеспечить анонимность, так как серверу, как правило, необходимо идентифицировать клиента, по крайней мере через интернет адрес. При использования P2P-сети пользователи могут избежать предоставления любой информацию о себе. FreeNet является ярким при- мером того, как механизмы анонимности могут быть встроены в P2P- приложения. В системе FreeNet используется схема переадресации сооб- щений при которой невозможно отследить первого отправителя. Также степень анонимности увеличивается за счет использования вероятностных алгоритмов. Основные элементы P2P сетей Пир (Peer) – это фундаментальный составляющий блок любой одноранго- вой сети: каждый пир имеет уникальный идентификатор; __ каждый пир принадлежит одной или нескольким группам; каждый пир может взаимодействовать с другими пирами, как в своей так и в других группах. Можно выделить следующие виды пиров: Простой пир: обеспечивает работу конечного пользователя, предоставляя ему сервисы других пиров и обеспечивая предоставление ресурсов пользо- вательского компьютера другим участникам сети; Роутер: обеспечивает механизм взаимодействия между пирами, отделен- ными от сети брандмауэрами или NAT-системами. Группа пиров – это набор пиров, сформированный для решения общей за- дачи или достижения общей цели. Группы пиров могут предоставлять членам своей группы такие наборы сервисов, которые недоступны пирам, входящим в другие группы. Сервисы – это функциональные возможности, которые может привлекать отдельный пир для полноценной работы с удаленными пирами. В качестве примера сервисов, которые может предоставлять отдельный пир можно указать сервисы передачи файлов, предоставления информации о статусе, проведения вычислений и др. Сервисы пира – это такие сервисы, которые может предоста- вить конкретный узел P2P. Каждый узел в сети P2P предоставляет определен- ные функциональные возможности, которыми могут воспользоваться другие узлы. Эти возможности зависят от конкретного узла и доступны только тогда, когда узел подключен к сети. Как только узел отключается, его сервисы стано- вятся недоступны. Сервисы группы – это функциональные возможности, предо- ставляемые группой входящим в нее узлам. Возможности могут предоставлять- ся несколькими узлами в группе, для обеспечения избыточного доступа к этим возможностям. Как только к группе подключается узел, обеспечивающий необ- ходимый сервис, он становиться доступной для всей группы. P2P — это не только сети, но еще и сетевой протокол, обеспечивающий возможность создания и функционирования сети равноправных узлов, их взаи- модействия. Множество узлов, объединенных в единую систему и взаимодей- ствующих в соответствии с протоколом P2P, образуют пиринговую сеть. P2P относятся к прикладному уровню сетевых протоколов и являются наложенной сетью, использующей существующие транспортные протоколы стека TCP/IP – TCP или UDP. Протоколы сети P2P обеспечивают: поиск узлов в сети; получение списка служб отдельного узла; __ получение информации о статусе узла; использование службы на отдельном узле; создание, объединение и выход из групп; создание соединений с узлами; маршрутизацию сообщений другим узлам. Одну из удачных попыток стандартизации протоколов P2P предприняла компания Sun Microsystems в рамках проекта JXTA. Платформа JXTA позици- онируется как базовая платформа для организации P2P сетей на основе гетеро- генных вычислительных сетей. Алгоритмы работы P2P сетей Структура P2P сети Структура P2P сети определяет принципы поиска новых узлов и замены узлов вышедших из состава сети новыми. Можно выделить два основных типа P2P сетей: централизованные и децентрализованные [46]. Централизованная структура P2P сети подразумевает наличие выделен- ного индексного сервера (трекера) собирающего информацию об узлах, вхо- дящих в P2P-сеть и обеспечивающего поиск и предоставление необходимых сервисов одних узлов другим. Первой P2P сетью с централизованной структу- рой была сеть Napster, центральный узел которой отвечал за хранение иденти- фикаторов всех узлов в сети и списков файлов, доступных на каждом из узлов. Еще одним примером сети с централизованной структурой является сеть BitTorrent. Центральным узлом данной сети является трекер – сервер, содер- жащий информацию о списке узлов, подключенных к сети, и сервисах, предо- ставляемых каждым узлом (например, список файлов, доступных для загрузки с данного узла). Для получения необходимого файла, узел посылает трекеру за- прос, содержащий уникальный идентификатор необходимого файла. На данный запрос трекер возвращает список узлов, на которых доступен требуемый файл. Естественно, степень централизованности системы BitTorrent значительно меньше, чем была у системы Napster, т.к. BitTorrent позволяет работать сразу с большим количеством трекеров, в то время как Napster предполагал наличие только одного центрального сервера. Децентрализованная структура P2P сети предполагает отсутствие выде- ленного сервера. Поиск и предоставление сервисов производится путем проце- дуры пошагового поиска, в которой могут участвовать все узлы, входящие в сеть. Типичным примером одноранговой сети с децентрализованной структу-__ рой является система Gnutella. В данной сети, обнаружение и подключение к узлам сети происходит посредством процедуры случайного обхода. Каждый узел содержит таблицу соседей, содержащую IP адрес и порт известного узла Gnutella. При запуске новый узел Gnutella переходит в режим начальной за- грузки, в котором посредством одного из доступных источников (список узлов на одном из узлов интернет; внутренний предустановленный список узлов и др.) формирует начальный список соседей. После чего, соседям высылается со- общение обнаружения, пересылаемое далее по цепочке систем. Таким образом обеспечивается обнаружение ресурсов, предоставляемых всеми узлами под- ключенными к сети. Алгоритмы работы P2P сетей Поскольку сегодня в перенасыщенном информацией мире задача полноты поиска отводится на второй план, то главная задача поиска в пиринговых сетях сводится к быстрому и эффективному нахождению наиболее релевантных от- кликов на запрос, передаваемый от узла всей сети. В частности, актуальна зада- ча — уменьшение сетевого трафика, порождаемого запросом (например, пере- сылки запроса по многочисленным узлам), и в то же время получение наилуч- ших характеристик выдаваемых документов, т.е. наиболее качественного ре- зультата. Для решения данной задачи применяют несколько подходов. Централизованный индекс: узлы публикуют информацию о своих серви- сах в центральном индексе. При подключении к сети, пир формирует список документов и сервисов, доступных на узле. Данный список передается на цен- тральный сервер, хранящий полную информацию о текущем состоянии вычис- лительной сети. Когда любой узел P2P-сети хочет получить информацию о том, какие ресурсы доступны, он отправляет поисковый запрос на центральный сер- вер. В ответ на этот запрос, центральный сервер выдает список доступных ре- сурсов и адреса узлов, на которых они располагаются. Недостатком является малая масштабируемость сети (в связи с возрастающей нагрузкой на централь- ный сервер) и высокая зависимость от центрального сервера. Данные недостат- ки решаются посредством масштабирования центрального сервера (например, использование нескольких независимых центральных серверов). Пример: Napster, BitTorrent, eDonkey. Широковещательные запросы (Breadth Search): процесс поиска информа- ции производится посредством отправки поискового запроса всем подключен- ным узлам, известным отправителю запроса. Данный запрос транслируется всем дальнейшим узлам, пока не получен ответ или не достигнут предел коли- чества пересылок. Недостатками данного метода является большая нагрузка на сеть, генерируемая поисковыми запросами, а также негарантируемая достижи- мость результата. Однако есть метод, позволяющий избежать перегрузки всей сети сообщениями. Он заключается в приписывании каждому запросу парамет- ра времени жизни (time-to-live, TTL). Параметр TTL определяет максимальное число переходов, по которому можно пересылать запрос. Пример: Gnutella Маршрутизация документов. Данный метод обеспечивает поиск докумен- тов без участия центрального индекса, средствами самой вычислительной сети. В основе данного метода лежит принцип присвоения уникальных идентифика- торов каждому узлу вычислительной сети, а также каждому ресурсу (докумен- ту, сервису и др.), который данная сеть может предоставлять.
Рис. 57. Трассировка и поиск ресурса посредством алгоритма маршрутизации доку- ментов На рисунке 57 представлен пример работы алгоритма маршрутизации до- кумента. Когда какой-либо пир (на рисунке – узел 7008) производит публика- цию ресурса в сети, каким-либо образом вычисляется идентификатор данного ресурса (на рисунке – документ 0110). При этом, идентификаторы узлов сети и ресурсов имеют единую область возможных значений. Далее, копия данного ресурса (или ссылка на него) трассируется к узлу, который имеет наиболее по- хожий идентификатор (на рисунке показана трасса документа 0110: узлы 7008 – 0459 – 0009 – 0040). Данная процедура производится следующим образом: 1. Производится сравнение идентификатора ресурса с идентификаторами всех соседних узлов. 2. Если идентификатор текущего узла ближе всего (по некоторой метрике) к идентификатору документа, то процесс трассировки завершается. 3. Если один из идентификаторов соседних узлов ближе к идентификатору до- кумента, чем идентификатор текущего узла, то ссылка на данный ресурс ко- пируется на узел с более близким идентификатором и процесс повторяется с п. 1. В результате данной процедуры ссылка на документ отправляется на вы- числительный узел, идентификатор которого больше всего соответствует иден- тификатору документа, среди соседей начального узла (узел 0040 на рисунке). Поиск ресурса производится по аналогичному алгоритму, но вместо копи- рования документа происходит трансляция запроса (в запросе содержится идентификатор запрашиваемого ресурса, например 0110 на рисунке 57) от узла, инициировавшего запрос (на рисунке – узел 5203) к узлу, идентификатор кото- рого ближе всего соответствует идентификатору запрашиваемого документа. Соответственно, в процессе трансляции данного запроса должен появиться та- кой узел, который хранит информацию об интересуемом документе, если дан- ный документ находится в соответствующей части сети. К недостаткам такого подхода можно отнести необходимость знания точ- ного идентификатора документа, который необходимо найти в сети (невозмож- ность поиска по отдельным атрибутам документа), а также возможность обра- зования «островов», затрудняющих алгоритм поиска. Примеры: FreeNet, прото- кол DHT. Отдельно стоит отметить алгоритм обхода брандмауэров и NAT, приме- няющийся при работе с конечными узлами, установка внешнего соединения с которыми затруднена или невозможна. Для обеспечения обмена информацией, необходимо использовать возможности узла-роутера для трансляции сообще- ний во внешнюю сеть и получения информации из внешней сети. Узел-роутер буферизует всю информацию, предназначенную конечному узлу до момента, пока не получит от него запрос на загрузку. Как только получен запрос на за- грузку, узел-роутер отвечает, выгружая всю накопившуюся информацию на ко- нечный узел. Применение технологий P2P Наибольшее распространение одноранговых сетей наблюдается в систе- мах, обрабатывающих большие объемы данных и обеспечивающих индивиду-__ альный обмен информацией между пользователями. В настоящий момент, тех- нологии P2P наиболее ярко представлены в 3-х направлениях: Распределенные вычисления: разбиение общей задачи на большое число независимых в обработке подзадач (проекты на платформе BOINC [9]); Файлообменные сети: P2P выступают альтернативой FTP-архивам, кото- рые утрачивают перспективу ввиду значительных информационных пере- грузок (однако требуются эффективные механизмы поиска) (Gnutella [33], eDonkey, BitTorrent [8]); Приложения для совместной работы: требуют обеспечения прозрачных механизмов для совместной работы. (Skype [36, 59], Groove [17]). Распределенные вычисления В основном, к данному типу проектов относят системы типа проекта SETI@home (распределенный поиск внеземных цивилизаций), который проде- монстрировал огромный вычислительный потенциал для распараллеливаемых задач. В настоящий момент в нем принимают участие свыше трех миллионов пользователей на бесплатной основе. Данная система основана на платформе BOINC. BOINC (англ. Berkeley Open Infrastructure for Network Computing — от- крытая программная платформа Беркли для распределённых вычислений) — некоммерческое межплатформенное ПО для организации распределённых вы- числений . Система состоит из двух основных частей: сервер BOINC – это набор PHP-сценариев для организации и управления проектом: регистрация участников, распределение заданий, получение ре- зультатов; клиент BOINC – это пользовательское приложение, позволяющее участво- вать в одном или нескольких проектах. Обычно представляет собой храни- тель экрана, который производит вычисления в моменты простоя компью- тера. Наиболее популярные проекты, реализованные на основе BOINC: SETI@home — анализ радиосигналов с радиотелескопа Аресибо для поис- ка инопланетных цивилизаций. Einstein@Home — проверка гипотезы Альберта Эйнштейна о гравитаци- онных волнах с помощью анализа гравитационных полей пульсаров или нейтронных звёзд. Climate Prediction — построение модели климата Земли для предсказания его изменений на 50 лет вперёд. World Community Grid — Различные проекты. Организатор — IBM. Malaria Control Project — Контроль распространения Малярии в Африке (AFRICA@home). Predictor@home — моделирование 3-хмерной структуры белка из последо- вательностей аминокислот. LHC@home — расчёты для ускорителя заряженных частиц в CERN (Centre Europeen de Recherche Nucleaire). Файлообменные сети По статистическим данным на конец 2006 года объем трафика, генерируе- мого файлообменными сетями на базе P2P-сетей, составил более 70% всего се- тевого трафика. На сегодняшний день существует большое число P2P-сетей, ориентированных на обмен файлами между пользователями. Они могут разви- ваться и функционировать как в глобальном сетевом пространстве, так и в от- дельных подсетях. Самым ярким примером таких сетей, является система BitTorrent. Прото- кол BitTorrent был разработан в 2001 Брэмом Коэном. В соответствии с прото- колом BitTorrent файлы передаются не целиком, а частями, причем каждый клиент, закачивая эти части, в это же время отдает их другим клиентам, что снижает нагрузку и зависимость от каждого клиента-источника и обеспечивает избыточность данных. Если узел хочет опубликовать файл или набор файлов, то программа- клиент BitTorrent сети разделяет передаваемые файлы на части и создает файл метаданных (идентификатор раздачи), который содержит следующую инфор- мацию: URL трекера; Общая информация о файлах (имя, длина и пр.); Хеш-суммы SHA1 сегментов раздаваемых файлов; Passkey пользователя – ключ, который однозначно определяет пользовате- ля загрузившего файл; Хеш-суммы файлов целиком (не обязательно); Альтернативные источники – адреса альтернативных трекеров, на которых можно найти информацию по данному файлу (не обязательно). Алгоритм загрузки документа производится следующим образом: клиент подключается к трекеру по URL из файла метаданных; сообщает хеш-идентификатор требуемого файла; получает адреса пиров скачивающих и раздающих данный файл; клиенты соединяются между собой и обмениваются информацией без уча- стия трекера. В последнее время стала распространяться альтернативная технология по- иска и загрузки документов на основе «магнитных ссылок» (magnet links) и подхода распределенных хеш-таблиц (Distributed Hash Table — DHT) по сути дела представляющих собой реализацию алгоритма маршрутизации докумен- тов, описанную ранее. Причина возникновения этой технологии – дальнейшее развитие деперсонализации и попытка торрент-трекеров защититься от юриди- ческого преследования правообладателей. Торрент-файл для такой раздачи со- здаётся без адреса трекера и клиенты находят друг друга через распределенные хеш-таблицы. DHT – это система распределенного хранения данных о скачиваемых фай- лах. Все клиенты, подключенные к DHT-сети и сами становятся «узлами», чем- то вроде мини-трекеров. Каждый узел имеет уникальный идентификатор – «node ID». Все узлы хранят информацию об узлах, «близких к ним», кроме того узел должен хранить информацию о пирах в раздачах, чей хеш напоминает «node ID». При этом торренты представляют собой Magnet-ссылки, которые в основ- ном идентифицируют файлы не по их расположению или имени, а по содержа- нию, точнее — по хеш-коду. Одно из преимуществ magnet-ссылок — их открытость и независимость от платформы: ссылка может быть использована для загрузки файла при помощи разнообразных приложений на практически всех операционных системах. Бла- годаря тому, что magnet-ссылка представляет собой короткую строку текста, пользователи могут использовать обычные операции копирования-вставки и отправить ее по электронной почте или программе мгновенного обмена сооб- щениями. Популярное:
|
Последнее изменение этой страницы: 2016-05-28; Просмотров: 2653; Нарушение авторского права страницы
 Рис. 55. Сравнение вида связей P2P и централизованной (клиент-серверной) архитек- тур
Рис. 55. Сравнение вида связей P2P и централизованной (клиент-серверной) архитек- тур