|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Основная надстройка над FAT-32, это длинные имена файлов.
Для каждого файла стали присваивать два имени: 1. Короткое 8+3 для совместимости с MS-DOS 2. Длинное имя файла, в формате Unicode Доступ к файлу может быть получен по любому имени. Если файлу дано длинное имя (или используются пробелы), то система делает следующие шаги: o берет первые шесть символов o преобразуются в верхний регистр ASCII, удаляются пробелы, лишние точки, некоторые символы преобразуются в " _" o добавляется суффикс ~1 o если такое имя есть, то используется суффикс ~2 и т.д. Короткие имена хранятся в в обычном дескрипторе файла. Длинные имена хранятся в дополнительных каталоговых записях, идущих перед основным описателем файла. Каждая такая запись содержит 13 символов формата Unicode (для символа Unicode нужно два байта).
Формат каталогов записи с фрагментом длинного имени файла в Windows 98 Поле " Атрибуты" позволяет отличить фрагмент длинного имени (значение 0х0F) от дескриптора файла. Старые программы MS-DOS каталоговые записи со значением поля атрибутов 0х0F, просто игнорируют. Последовательность - порядковый номер в последовательности фрагментов. Длина имени файла ограничена 260 символами не из-за порядкового номера (1 байт), для номера используются только 6 бит 6х13=819 символов. Контрольная сумма нужна для выявления ошибок, т.к. файл с длинным именем может удалить MS-DOS и создать новый, и тогда останутся не удаленные записи, которые " прилипнут" к новому файлу. Т.к. это поле один байт, есть вероятность 1/256 что Windows 98 не заметит подмены. 3.3Файловая системаNTFS Файловая система NTFS была разработана для Windows NT. Особенности: o 64-разрядные адреса, т.е. теоретически может поддерживать 2^64*2^16 байт (1 208 925 819 Пбайт~1Йбайт(280)). o Размеры блока (кластера) от 512байт до 64 Кбайт, для большинства используется 4Кбайта. o Поддержка больших файлов. o Имена файлов ограничены 255 символами Unicode. o Длина пути ограничивается 32 767 (2^15) символами Unicode. o Имена чувствительны к регистру, my.txt и MY.TXT это разные файлы (но из-за Win32 API использовать нельзя), это заложено на будущее. o Журналируемая файловая система, т.е. не попадет в противоречивое состояние после сбоев. o Контроль доступа к файлам и каталогам. o Поддержка жестких и символических ссылок. o Поддержка сжатия и шифрования файлов. o Поддержка дисковых квот. Главная файловая таблица MFT (Master File Table) - главная структура данных в каждом томе, записи фиксированные по 1Кбайту. Каждая запись описывает один каталог или файл. Для больших файлов могут использоваться несколько записей, первая запись называется - базовой записью. MFT представляет собой обычный файл (размером до 2^48 записей), который может располагаться в любом месте на диске.
Главная файловая таблица MFT, каждая запись ссылается на файл или каталог. Первые 16 записей MFT зарезервированы для файлов метаданных. Каждая запись описывает нормальный файл, имена этих файлов начинаются с символа " $". Каждая запись представляет собой последовательность пар (заголовок атрибута, значение). Некоторые записи метаданных в MFT: 0) Первая запись описывает сам файл MFT, и содержит все блоки файла MFT. Номер первого блока файла MFT содержится в загрузочном блоке. 1) Дубликат файла MFT, резервная копия. 2) Журнал для восстановления, например, перед созданием, удалением каталога делается запись в журнал. Система не попадет в противоречивое состояние после сбоев. 3) Информация о томе (размер, метка и версия) 4) Определяются атрибуты для MFT записей. 6) Битовый массив использованных блоков - для учета свободного места на диске 7) Указывает на файл начальной загрузки Атрибуты, используемые в записях MFT: o Стандартная информация - флаговые биты (только чтение, архивный), временные штампы и т.д. o Имя файла - имя файла в кодировке Unicode, файлы могут повторятся в формате MS-DOS 8+3. o Список атрибутов - расположение дополнительных записей MFT o Идентификатор объекта - 64-разрядный идентификатор файла, уникальный для данного тома. o Точка повторного анализа - используется для символьных ссылок и монтирования устройств. o Название тома o Версия тома o Корневой индекс - используется для каталогов o Размещение индекса - используется для очень больших каталогов o Битовый массив - используется для очень больших каталогов o Поток данных утилиты регистрации - используется для шифрования o Данные - поточные данные, может повторяться, используется для хранения самого файла. За заголовком следует список дисковых адресов, определяющий положение файла на диске, если файл очень маленький (несколько сотен байт), то следует сам файл (такой файл называется - непосредственный файл ). Как привило, все данные файла не помещаются в запись MFT. Дисковые блоки файлам назначаются по возможности в виде серий последовательных блоков ( сегментов файлов ). В идеале файл должен быть записан в одну серию (не фрагментированный файл), файл, состоящий из n блоков, может быть записан от 1 до n серий.
Запись MFT для 9-блочного файла, состоящего из трех сегментов (серий). Заголовок содержит количество блоков (9 блоков). Каждая серия записывается в виде пары, дисковый адрес - количество блоков (20-4, 64-2, 80-3). Каждая пара, при отсутствие сжатия, это два 64-разрядные числа (16 байт на пару). Многие адреса содержат большое количество нулей, сжатие делается за счет убирания нулей в старших байтах. В результате для пары требуется чаще всего 4байта. Если файл сильно фрагментирован, требуется несколько записей MFT.
Три записи MFT для сильно фрагментированного файла. Может потребоваться очень много индексов MFT, так что индексы не поместятся в запись. В этом случае список хранится не в MFT, а в файле.
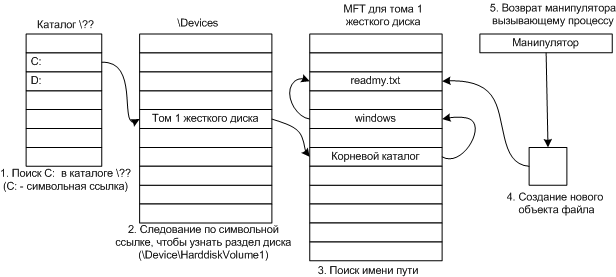
Запись MFT для небольшого каталога Поиск файла в каталоге по имени состоит в последовательном переборе имен файлов. Для больших каталогов используется другой формат. Используется дерево В+, обеспечивающее поиск в алфавитном порядке. Поиск файла по имени При создании файла, программа обращается к библиотечной процедуре CreateFile(" C: \windows\readmy.txt", ...) Этот вызов попадает в совместно используемую библиотеку уровня пользователя kernel32.dll, где \?? \ помещается перед именем файла, и получается строка: \?? \C: \windows\readmy.txt Это имя пути передается системному вызову NtFileCreate в качестве параметра.
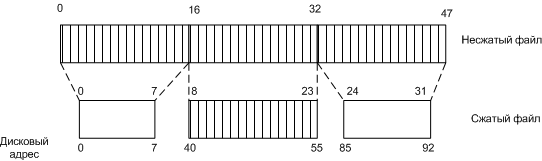
Этапы поиска файла C: \windows\readmy.txt 3.3.2Сжатие файлов Если файл помечен как сжатый, то система автоматически сжимает при записи, а при чтении происходит декомпрессия. Алгоритм работы: 1. Берутся для изучения первые 16 блоков файла (не зависимо от сегментов файла). 2. При меняется к ним алгоритм сжатия. 3. Если полученные данные можно записать хотя бы в 15 блоков, они записываются в сжатом виде. 4. Алгоритм повторяется для следующих 16 блоков.
Пример 48-блочного файла, сжатого до 32 блоков
Запись MFT для предыдущего файла. Недостатки сжатия: o Как видно из рисунка, сжатие приводит к сильной фрагментации. o Чтобы прочитать сжатый блок системе придется распаковать весь сегмент. Поэтому сжатие применяют к 16 блокам, если увеличить количество блоков, уменьшится производительность (но возрастет эффективность сжатия). 3.3.3Шифрование файлов Любую информацию, если она не зашифрована, можно прочитать, получив доступ. Поэтому самая надежная защита информации от несанкционированного доступа - шифрование. Даже если у вас украдут винчестер, прочесть данные не смогут (большинство не сможет). Если файл помечен как шифрованный, то система автоматически шифрует при записи, а при чтении происходит дешифрация. Шифрование и дешифрование выполняет не сама NTFS, а специальный драйвер EFS (Encrypting File System). Каждый блок шифруется отдельно. В Windows 2000 используется случайно сгенерированный 128-разрядный ключ для каждого файла. Этот ключ шифруется открытым ключом пользователя и сохраняется на диске.
Шифрование файлов в NTFS
3.1 Файловая системаUNIX V7 Хотя это старая файловая система основные элементы используются и современных UNIX системах. Особенности: o Имена файлов ограничены 14 символами ASCII, кроме косой черты " /" и NUL - отсутствие символа. (в последующих версиях расширены до 255) o Поддержка ссылок. o Контроль доступа к файлам и каталогам. o Имена чувствительны к регистру, my.txt и MY.TXT это разные файлы. o Используется схема i-узлов. o Не делается различий между разными файлами (текстовыми, двоичными и д.р.). o Поддерживаются символьные специальные файлы (для символьных устройств ввода-вывода). o Поддерживаются блочные специальные файлы (для блочных устройств ввода-вывода, например /dev/hd1). o Позволяет монтировать разделы в любое место дерева системы.
Расположение файловой системы UNIX Суперблок содержит: o Количество i-узлов o Количество дисковых блоков o Начало списка свободных блоков диска При уничтожении суперблока, файловая система становится не читаемой. Каждый i-узел имеет 64 байта в длину и описывает один файл (в том числе каталог). Каталог содержит по одной записи для каждого файла.
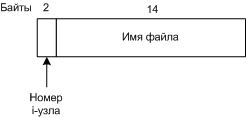
Каталоговая запись UNIX V7 в 16 байт Структура i-узела
Первые 10 дисковых блоков файла хранятся в самом i-узле, при блоке в 1Кбайт, файл может быть 10Кбайт. Дополнительные блоки для i-узла, в случае больших файлов: o Одинарный косвенный блок - дополнительный блок с адресами блоков файла, если файл не сильно большой, то один из адресов в i-узле указывает на дополнительный блок с адресами. Файл может быть 266Кбайт=10Кбайт+256Кбайт (256Кбайт < = 256 (2^8)-адресов блоков = 1Кбайт-размер блока / 4байта-размер адреса) o Двойной косвенный блок - дополнительный блок с адресами одинарных косвенных блоков, если одного дополнительного блока не хватает. Файл может быть 65Мбайт=10Кбайт+2^8Кбайт+2^16Кбайт. o Тройной косвенный блок - дополнительный блок с адресами двойных косвенных блоков, если одного одинарного косвенного блока не хватает. Файл может быть 16Гбайт=10Кбайт+2^8Кбайт+2^16Кбайт+2^24Кбайт.
i-узел UNIX V7 Поиск файла
Этапы поиска файла по абсолютному пути /usr/sbin/mc При использовании относительного пути, например sbin/mc, поиск начинается с рабочего каталога /usr. Блокировка данных файла Блокирование осуществляется по блочно. Стандартом POSIX два типа блокировки: o Блокировка с монополизацией - больше ни один процесс эти блоки заблокировать не может. o Блокировка без монополизации - могут блокировать и другие процессы.
Блокировки данных файла без монополизации Если процесс К попытается блокировать блок 6 с монополизацией, то сам процесс будет заблокирован до разблокирования блока 6 всеми процессами. Создание и работа с файлом fd=creat(" abc", mode) - Пример создания файла abc с режимом защиты, указанном в переменной mode (какие пользователи имеют доступ). Используется системный вызов creat. Успешный вызов возвращает целое число fd - дескриптор файла. Который хранится в таблице дескрипторов файла, открывшего процесса. После этого можно работать с файлом, используя системные вызовы write и read. n=read(fd, buffer, nbytes) n=write(fd, buffer, nbytes) У обоих вызовов всего по три параметра: o fd - дескриптор файла, указывающий на открытый файл o buffer - адрес буфера, куда писать или откуда читать данные o nbytes - счетчик байтов, сколько прочитать или записать байт Теперь нужно по дескриптору получить указатель на i-узел и указатель на позицию в файле для записи или чтения. Таблица открытых файлов - создана для хранения указателей на i-узел и на позицию в файле. И позволяет родительскому и дочернему процессам совместно использовать один указатель в файле, но для посторонних процессов выделять отдельные указатели.
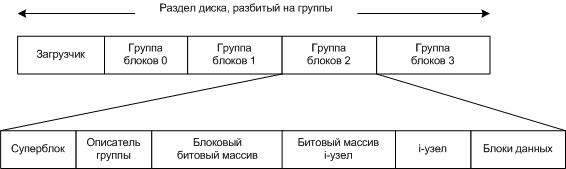
Связь между таблицей дескрипторов файлов, таблицей открытых файлов и таблицей i-узлов. Файловая система BSD Основу составляет классическая файловая система UNIX. Особенности (отличие от предыдущей системы): o Увеличена длина имени файла до 255 символов o Реорганизованы каталоги o Было добавлено кэширование имен файлов, для увеличения производительности. o Применено разбиение диска на группы цилиндров, чтобы i-узлы и блоки данных были поближе друг к другу, для каждой группы были свои: o Используются блоки двух размеров, для больших файлов использовались большие блоки, для маленьких маленькие. Каталоговые записи ни как не отсортированы и следуют друг за другом.
Каталог BSD с тремя каталоговыми записями для трех файлов и тот же каталог после удаления файла zip, увеличивается длина первой записи. Файловые системы LINUX Изначально использовалась файловая система MINIX с ограничениями: 14 символов для имени файла и размер файла 64 Мбайта. После была создана файловая система EXT с расширением: 255 символов для имени файла и размер файла 2Гбайта. Система была достаточно медленной. Файловая система EXT2 Эта файловая система стала основой для LINUX, она очень похожа BSD систему. Вместо групп цилиндров используются группы блоков.
Размещение файловой системы EXT2 на диске Другие особенности: o Размер блока 1 Кбайт o Размер каждого i-узла 128 байт. o i-узел содержит 12 прямых и 3 косвенных адресов, длина адреса в i-узле стала 4 байта, что обеспечивает поддержку размера файла чуть более 16Гбайт. Особенности работы файловой системы: o Создание новых каталогов распределяется равномерно по группам блоков, чтобы в каждой группе было одинаковое количество каталогов. o Новые файлы старается создавать в группе, где и находится каталог. o При увеличении файла система старается новые блоки записывать ближе к старым. Благодаря этому файловую систему не нужно дефрагментировать, она не способствует фрагментации файлов (в отличии от NTFS), что проверено многолетним использованием. Файловая система EXT3 В отличие от EXT2, EXT3 является журналируемой файловой системой, т.е. не попадет в противоречивое состояние после сбоев. Но она полностью совместима с EXT2. Разработанная в Red Hat В данный момент является основной для LINUX. Драйвер Ext3 хранит полные точные копии модифицируемых блоков (1КБ, 2КБ или 4КБ) в памяти до завершения операции. Это может показаться расточительным. Полные блоки содержат не только изменившиеся данные, но и не модифицированные. Такой подход называется " физическим журналированием ", что отражает использование " физических блоков" как основную единицу ведения журнала. Подход, когда хранятся только изменяемые байты, а не целые блоки, называется " логическим журналированием " (используется XFS). Поскольку ext3 использует " физическое журналирование", журнал в ext3 имеет размер больший, чем в XFS. За счет использования в ext3 полных блоков, как драйвером, так и подсистемой журналирования нет сложностей, которые возникают при " логическом журналировании". Типы журналирования поддерживаемые Ext3, которые могут быть активированы из файла /etc/fstab: o data=journal (full data journaling mode) - все новые данные сначала пишутся в журнал и только после этого переносятся на свое постоянное место. В случае аварийного отказа журнал можно повторно перечитать, приведя данные и метаданные в непротиворечивое состояние. o data=ordered - записываются изменения только мета-данных файловой системы, но логически metadata и data блоки группируются в единый модуль, называемый transaction. Перед записью новых метаданных на диск, связанные data блоки записываются первыми. Этот режим журналирования ext3 установлен по умолчанию. o data=writeback (metadata only) - записываются только изменения мета-данных файловой системы. Самый быстрый метод журналирования. С подобным видом журналирования вы имеете дело в файловых системах XFS, JFS и ReiserFS. 3.3.3 Файловая системаXFS XFS - журналируемая файловая система разработанная Silicon Graphics, но сейчас выпущенная открытым кодом (open source). Официальная информация на http: //oss.sgi.com/projects/xfs/ XFS была создана в начале 90ых (1992-1993) фирмой Silicon Grapgics (сейчас SGI) для мультимедийных компьютеров с ОС Irix. Файловая система была ориентирована на очень большие файлы и файловые системы. Особенностью этой файловой системы является устройство журнала - в журнал пишется часть метаданных самой файловой системы таким образом, что весь процесс восстановления сводится к копированию этих данных из журнала в файловую систему. Размер журнала задается при создании системы, он должен быть не меньше 32 мегабайт; а больше и не надо - такое количество незакрытых транзакций тяжело получить. Некоторые особенности: o Более эффективно работает с большими файлами. o Имеет возможность выноса журнала на другой диск, для повышения производительности. o Сохраняет данные кэша только при переполнении памяти, а не периодически как остальные. o В журнал записываются только мета-данные. o Используются B+ trees. o Используется логическое журналирование 3.3.4 Файловая системаRFS RFS (RaiserFS) - журналируемая файловая система разработанная Namesys. Официальная информация на RaiserFS Некоторые особенности: o Более эффективно работает с большим количеством мелких файлов, в плане производительности и эффективности использования дискового пространства. o Использует специально оптимизированные b* balanced tree (усовершенствованная версия B+ дерева) o Динамически ассигнует i-узлы вместо их статического набора, образующегося при создании " традиционной" файловой системы. o Динамические размеры блоков. 3.3.4 Файловая системаJFS JFS (Journaled File System) - журналируемая файловая система разработанная IBM для ОС AIX, но сейчас выпущенная как открытый код. Официальная информация на Journaled File System Technology for Linux Некоторые особенности: o Журналы JFS соответствуют классической модели транзакций, принятой в базах данных o В журнал записываются только мета-данные o Размер журнала не больше 32 мегабайт. o Асинхронный режим записи в журнал - производится в моменты уменьшения трафика ввода/вывода o Используется логическое журналирование. 3.4 Сравнительная таблица некоторых современных файловых систем
Файловая система NFS NFS (Network File System) - сетевая файловая система. Создана для объединения файловых систем по сети. Популярное:
|
Последнее изменение этой страницы: 2016-05-28; Просмотров: 782; Нарушение авторского права страницы