
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Классификация информационных систем.Стр 1 из 14Следующая ⇒
Классификация информационных систем. Понятие информационных систем. Информационная система - это совокупность взаимосвязанных элементов, представляющих собой информационные, кадровые и материальные ресурсы, процессы, которые обеспечивают сбор, обработку, преобразование, хранение и передачу информации в организации. Разнообразие задач, решаемых с помощью ИС, привело к появлению множества разнотипных систем, отличающихся принципами построения и заложенными в них правилами обработки информации. Структура информационных систем. Структуру информационной системы составляет совокупность отдельных ее частей, называемых подсистемами. Подсистема - это часть системы, выделенная по какому-либо признаку. По масштабам применения – настольные, офисные и корпоративные. Неструктурированная (не формализуемая) задача - задача, в которой невозможно выделить элементы и установить между ними связи. . Классификация информационных систем по признаку структурированности решаемых зада Информационные системы, используемые для решения частично структурированных задач, подразделяютсяна два вида (Рис. 1.5): - создающие управленческие отчеты и ориентированные главным образом на обработку данных (поиск, сортировку, агрегирование, фильтрацию). Используя сведения, содержащиеся в этих отчетах, управляющийпринимает решение; - разрабатывающие возможные альтернативы решения. Принятие решения при этом сводится к выбору одной из предложенных альтернатив. Экспертные информационные системы обеспечивают выработку и оценку возможных альтернатив пользователем за счет создания экспертных систем, связанных с обработкой знаний. Экспертная поддержка принимаемых пользователем решений реализуется на двух уровнях. КЛАССИФИКАЦИЯ ИНФОРМАЦИОННЫХ СИСТЕМ ПО ФУНКЦИОНАЛЬНОМУ ПРИЗНАКУ И УРОВНЯМ УПРАВЛЕНИЯ Функциональный признак определяет назначение подсистемы, а также ее основные цели, задачи и функции. Производственная деятельность связана с непосредственным выпуском продукции и направлена на создание и внедрение в производство научно-технических новшеств. Маркетинговая деятельность включает в себя: анализ рынка производителей и потребителей выпускаемой продукции, анализ продаж; организацию рекламной кампании по продвижению продукции; рациональную организацию материально-технического снабжения. Финансовая деятельность связана с организацией контроля и анализа финансовых ресурсов фирмы на основе бухгалтерской, статистической, оперативной информации. Кадровая деятельность направлена на подбор и расстановку необходимых фирме специалистов, а также ведение служебной документации по различным аспектам.
Типы информационных систем в зависимости от функционального признака с учетом уровней управления и квалификации персонала
Классификация по степени автоматизации Классификация информационных систем по разным признакам Построение ИС на ранней стадии Развития.
С появлением ПИ произошло изменение в сфере человек – ЭВМ. Поскольку на ранней стадии этого не было, то ИС была одного пользователя. ИС была слаба.
«Файл – серверное» построение ИС. ЛС – локальная сеть. ФС – файловый сервер. Особенность построения ИС является то, что она позволяет получить доступ к данным многих пользователей. С другой стороны, взаимообмен ПО с данными осуществляется с одного или несколькими сетевыми уровнями. Вся обработка осуществляется на сетевых уровнях. Это значит, что любая элементарная операция над данными приводит к повышению трафика локальной сети.
Схема «клиент – сервер». Вместо файловой системы для хранения данных используется сервер БД. Особенностью СБД является то, что он способен выполнять запрос на обработку данных. Один такой запрос может содержать в себе множество элементарных операций над данными. Кроме этого, на сервере БД могут храниться программы – модули, состоящие из произвольного количества операторов, определен язык программирования, которые могут быть выставлены на команде с сетевого компьютера. Вся обработка данных переместилась на 1 комп, что привело к уменьшению нагрузки на СК и сетевые компы. Теперь для увеличения производительности ИС достаточно понять производительность одного компа, где располагается сервер БД. Схема (рис. 3) широко используется при построении современных ИС.
Там обычно используют такую систему (рис 4): В общем случае может быть построены n - уровневая схема построения ИС, если учесть, что СБД может обращаться с другой СБД. Под системой понимают любой объект, который одновременно рассматривается и как единое целое, и как объединённая в интересах достижения поставленных целей совокупность разнородных элементов.В информатике понятие " система" имеет множество смысловых значений. Чащё всего оно используется применительно к набору технических средств и программ. Системой может называться аппаратная часть компьютера. Системой может считаться множество программ для решения конкретных прикладных задач, дополненных процедур ведения документации и управления расчётами.Добавление к понятию " система" слова " информационная" отражает цель её создания и функционирования. Информационныё системы обеспечивают сбор, хранение, обработку, поиск, выдачу информации, необходимой в процессе принятия решений задач из любой области. Они помогают анализировать проблемы и создавать новые продукты. Информационная система - взаимосвязанная совокупность средств, методов и персонала, используемых для хранения, обработки, выдачи информации в интересах достижения поставленной цели. Современное понимание информационной системы предполагает использование в качестве основного технического средства переработки информации персонального компьютера. В крупных организациях наряду с персональным компьютером в состав технической базы информационной системы может входить мэйнфрэйм или супер ЭВМ. Кроме того, техническое воплощение информационной системы само по себе ничего не будет значить, если не учтена роль человека, для которого предназначена производимая информация и без которого невозможно её получение и представление.Необходимо понимать разницу между компьютерами и информационными системами. Компьютеры, оснащённые специализированными программными средствами, являются технической базой и инструментом для информационных систем. Информационная система немыслима без персонала, взаимодействующего с компьютерами и телекоммуникациями.Информационная система, установленная в фирме, занимающейся продажей времени в эфире, отслеживает освободившееся место для рекламы, стоимость определённого времени в эфире и возможности эфира. Это позволяет максимально выгодно использовать время рекламы, предложение согласно спросу, максимизация прибыли и экономия времени. Массивы
Записи (Структуры)
С математической точки зрения массив представляет собой функцию с конечной областью определения. Например, рассмотрим конечное множество натуральных чисел
называемое множеством индексов. Отображение
из множества во множество вещественных чисел задает одномерный вещественный массив. Значение этой функции для некоторого значения индекса называется элементом массива, соответствующим. Аналогично можно задавать многомерные массивы.
Запись (или структура) представляет собой кортеж из некоторого декартового произведения множеств. Действительно, запись представляет собой именованный упорядоченный набор элементов, каждый из которых принадлежит типу. Таким образом, запись есть элемент множества. Объявляя новые типы записей на основе уже имеющихся типов, пользователь может конструировать сколь угодно сложные типы данных[3].
Общим для структурированных типов данных является то, что они имеют внутреннюю структуру, используемую на том же уровне абстракции, что и сами типы данных.
При работе с массивами или записями можно манипулировать массивом или записью и как с единым целым (создавать, удалять, копировать целые массивы или записи), так и поэлементно. Для структурированных типов данных есть специальные функции - конструкторы типов, позволяющие создавать массивы или записи из элементов более простых типов.
Работая же с простыми типами данных, например с числовыми, мы манипулируем ими как неделимыми целыми объектами. Чтобы " увидеть", что числовой тип данных на самом деле сложен (является набором битов), нужно перейти на более низкий уровень абстракции. На уровне программного кода это будет выглядеть как ассемблерные вставки в код на языке высокого уровня или использование специальных побитных операций.
Ссылочный тип данных (указатели) предназначен для обеспечения возможности указания на другие данные. Указатели характерны для языков процедурного типа, в которых есть понятие области памяти для хранения данных. Ссылочный тип данных предназначен для обработки сложных изменяющихся структур, например деревьев, графов, рекурсивных структур.
Для реляционной модели данных тип используемых данных не важен. Требование, чтобы тип данных был простым, нужно понимать так, что в реляционных операциях не должна учитываться внутренняя структура данных. Конечно, должны быть описаны действия, которые можно производить с данными как с единым целым, например, данные числового типа можно складывать, для строк возможна операция конкатенации и т.д.
С этой точки зрения, если рассматривать массив, например, как единое целое и не использовать поэлементных операций, то массив можно считать простым типом данных. Более того, можно создать свой, сколь угодно сложных тип данных, описать возможные действия с этим типом данных, и, если в операциях не требуется знание внутренней структуры данных, то такой тип данных также будет простым с точки зрения реляционной теории. Например, можно создать новый тип - комплексные числа как запись вида, где. Можно описать функции сложения, умножения, вычитания и деления, и все действия с компонентами и выполнять только внутри этих операций. Тогда, если в действиях с этим типом использовать только описанные операции, то внутренняя структура не играет роли, и тип данных извне выглядит как атомарный.
Именно так в некоторых пост-реляционных СУБД реализована работа со сколь угодно сложными типами данных, создаваемых пользователями.
Домены
В реляционной модели данных с понятием тип данных тесно связано понятие домена, которое можно считать уточнением типа данных.
Домен - это семантическое понятие. Домен можно рассматривать как подмножество значений некоторого типа данных имеющих определенный смысл. Домен характеризуется следующими свойствами:
Домен имеет уникальное имя (в пределах базы данных).
Домен определен на некотором простом типе данных или на другом домене.
Домен может иметь некоторое логическое условие, позволяющее описать подмножество данных, допустимых для данного домена.
Домен несет определенную смысловую нагрузку.
Например, домен, имеющий смысл " возраст сотрудника" можно описать как следующее подмножество множества натуральных чисел:
Если тип данных можно считать множеством всех возможных значений данного типа, то домен напоминает подмножество в этом множестве.
Отличие домена от понятия подмножества состоит именно в том, что домен отражает семантику, определенную предметной областью. Может быть несколько доменов, совпадающих как подмножества, но несущие различный смысл. Например, домены " Вес детали" и " Имеющееся количество" можно одинаково описать как множество неотрицательных целых чисел, но смысл этих доменов будет различным, и это будут различные домены[4].
Основное значение доменов состоит в том, что домены ограничивают сравнения. Некорректно, с логической точки зрения, сравнивать значения из различных доменов, даже если они имеют одинаковый тип. В этом проявляется смысловое ограничение доменов. Синтаксически правильный запрос " выдать список всех деталей, у которых вес детали больше имеющегося количества" не соответствует смыслу понятий " количество" и " вес".
Понятие домена помогает правильно моделировать предметную область. При работе с реальной системой в принципе возможна ситуация когда требуется ответить на запрос, приведенный выше. Система даст ответ, но, вероятно, он будет бессмысленным.
Не все домены обладают логическим условием, ограничивающим возможные значения домена. В таком случае множество возможных значений домена совпадает с множеством возможных значений типа данных. Трансляция сетевых адресов. NAT (от англ. Network Address Translation — «преобразование сетевых адресов») — это механизм в сетях TCP/IP, позволяющий преобразовывать IP-адреса транзитных пакетов. Также имеет названия IP Masquerading, Network Masquerading и Native Address Translation. Преобразование адреса методом NAT может производиться почти любым маршрутизирующим устройством — маршрутизатором, сервером доступа, межсетевым экраном. Наиболее популярным является SNAT, суть механизма которого состоит в замене адреса источника (англ. source) при прохождении пакета в одну сторону и обратной замене адреса назначения (англ. destination) в ответном пакете. Наряду с адресами источник/назначение могут также заменяться номера портов источника и назначения. Принимая пакет от локального компьютера, роутер смотрит на IP-адрес назначения. Если это локальный адрес, то пакет пересылается другому локальному компьютеру. Если нет, то пакет надо переслать наружу в интернет. Но ведь обратным адресом в пакете указан локальный адрес компьютера, который из интернета будет недоступен. Поэтому роутер «на лету» транслирует (подменяет) обратный IP-адрес пакета на свой внешний (видимый из интернета) IP-адрес и меняет номер порта (чтобы различать ответные пакеты, адресованные разным локальным компьютерам). Комбинацию, нужную для обратной подстановки, роутер сохраняет у себя во временной таблице. Через некоторое время после того, как клиент и сервер закончат обмениваться пакетами, роутер сотрет у себя в таблице запись о n-ом порте за сроком давности. Помимо source NAT (предоставления пользователям локальной сети с внутренними адресами доступа к сети Интернет) часто применяется также destination NAT, когда обращения извне транслируются межсетевым экраном на компьютер пользователя в локальной сети, имеющий внутренний адрес и потому недоступный извне сети непосредственно (без NAT). Существует 3 базовых концепции трансляции адресов: статическая (Static Network Address Translation), динамическая (Dynamic Address Translation), маскарадная (NAPT, NAT Overload, PAT). Статический NAT — Отображение незарегистрированного IP-адреса на зарегистрированный IP-адрес на основании один к одному. Особенно полезно, когда устройство должно быть доступным снаружи сети. Динамический NAT — Отображает незарегистрированный IP-адрес на зарегистрированный адрес из группы зарегистрированных IP-адресов. Динамический NAT также устанавливает непосредственное отображение между незарегистрированным и зарегистрированным адресом, но отображение может меняться в зависимости от зарегистрированного адреса, доступного в пуле адресов, во время коммуникации. Перегруженный NAT (NAPT, NAT Overload, PAT, маскарадинг) — форма динамического NAT, который отображает несколько незарегистрированных адресов в единственный зарегистрированный IP-адрес, используя различные порты. Известен также как PAT (Port Address Translation). При перегрузке каждый компьютер в частной сети транслируется в тот же самый адрес, но с различным номером порта. Основные понятия теории систем (система, элемент, структура, функция системы, целостность) ТИС базируется на общей теории систем. Основой общей теории систем является системный подход, который предполагает рассмотрение исследуемого или проектируемого объекта в качестве некоторой системы. Элемент – это минимальная неделимая часть системы. Элемент можно использовать только как целое. Неделимость элемента рассматривается как нецелесообразность учета в пределах модели данной системы его внутреннего строения. Объекты называются элементами по соглашению, принимаемому с целью получения ответов на вопросы, стоящие перед исследователем. То есть неделимость элемента – это просто удобное понятие, а не физическое свойство. Каждый элемент характеризуется конкретными свойствами, которые определяют его в данной системе однозначно. Система – это совокупность связанных элементов любой природы, объединённых в одно целое для достижения определённой цели. Связь – совокупность зависимостей свойств одного элемента от свойств других элементов системы. Установить связь между двумя элементами – это значит выявить наличие зависимостей их свойств. Связь характеризуется направлением, силой и характером (или видом). По первым двум признакам связи можно разделить на направленные и ненаправленные, сильные и слабые, а по характеру - на связи подчинения, наследования, равноправные (или безразличные), связи управления. Связи можно разделить также по месту приложения (внутренние и внешние), по направленности процессов в системе в целом или в отдельных ее подсистемах (прямые и обратные). Прямые связи предназначены для заданной функциональной передачи вещества, энергии, информации или их комбинаций — от одного элемента к другому в направлении основного процесса. Обратные связи, в основном, выполняют осведомляющие функции, отражая изменение состояния системы в результате управляющего воздействия на нее. Процессы управления, адаптации, саморегулирования, самоорганизации, развития невозможны без использования обратных связей.
Рис. Пример обратной связи С помощью обратной связи сигнал (информация) с выхода системы (объекта управления) передается в орган управления. Здесь этот сигнал, содержащий информацию о работе, выполненной объектом управления, сравнивается с сигналом, задающим содержание и объем работы (например, план). В случае возникновения рассогласования между фактическим и плановым состоянием работы принимаются меры по его устранению. Входы и выходы - материальные или информационные потоки входящие и выходящие из системы. Под целью понимается совокупность результатов, определяемых назначением системы. Важнейшим свойством системы является её целостность. Целостность означает принципиальную несводимость свойств системы к сумме свойств составляющих её элементов. Взаимодействие элементов системы порождает качественно новые функции и свойства системы, которых не было у отдельных элементов. Множество элементов, составляющих систему, нельзя разбить на несвязанные подмножества. Удаление из системы одного или нескольких элементов приведёт к изменению свойств в направлении, отличном от цели. Искусственные (инженерные) системы описывают путём определения их функций и структур. Функция системы – это правило получения результатов, предписанных целью системы. Функция устанавливает, что делает система для достижения поставленной цели и не определяет, как устроена система. Структура системы – это фиксированная совокупность элементов системы и связей между ними. Наиболее часто структура изображается в виде графа, где элементы – вершины, а связи – дуги. 20. Понятие и свойства сложной системы. Информационные системы, динамика которых зависит от человека, принимающего решения, которые описываются большим числом параметров и на работу которых существенно влияют случайные факторы, относятся к классу сложных систем. Продолжительность эксперимента с такими системами обычно велика, сравнима со сроком их жизни. Проведение активных экспериментов с такой системой иногда недопустимо, к тому же невозможны чистые опыты и систему приходится изучать во всём многообразии действующих факторов. Сложные системы имеют следующие особенности: 1. Уникальность. Сложные системы – это уникальные объекты. Существующие аналоги заметно отличаются друг от друга. 2. Слабая структурированность теоретических и физических знаний о системе. Т.к. сложные системы уникальны, то процесс накопления знаний о них затруднён. 3. Составной характер системы. При изучении сложных систем приходится выполнять её разбиение на подсистемы. Это делается для упрощения процесса исследований. При этом нужно учитывать взаимодействие подсистем между собой и с внешней средой. 4. Разнородность подсистем и элементов, составляющих систему. 1) Физическая разнородность, т.е. подсистемы и элементы имеют различную физическую природу. 2) Разнородность математических моделей, описывающих функционирование различных элементов и подсистем. 5. Большая размерность системы. Наличие большого числа взаимосвязанных и взаимодействующих элементов. 6. Многокритериальность оценок процессов, происходящих в системе. Невозможность однозначной оценки объясняется следующими обстоятельствами: · Наличием множества подсистем, каждая из которых в общем случае оценивается по своим критериям. · Множественностью показателей, иногда противоречивых, характеризующих работу всей системы. · Наличие неформализуемых критериев, используемых при принятии решений (в случае когда решения основаны на практическом опыте лиц, принимающих решение). 7. Случайность и неопределённость факторов, действующих в системе. Основным источником случайных воздействий являются факторы внешней среды и отклонения от нормальных режимов функционирования, возникающие внутри системы. К факторам внешней среды относятся: · Физические факторы (случайные изменения погоды), случайные колебания нагрузки (изменяют условия функционирования системы). · Случайные отклонения от нормальных режимов функционирования появляются за счёт ошибок приборов, внутренних шумов аппаратуры, отказов в работе некоторых элементов системы, нарушения синхронизации. Учёт случайных факторов приводит к резкому усложнению задач и увеличивает трудоёмкость вычислений. Сложные системы представляются в виде тройки (A, S, T): A – множество элементов; S – множество допустимых связей между элементами; T – множество рассматриваемых моментов времени. Для сложных систем допускается переменность состава системы и переменность её структуры. В каждый момент времени Т выделяется подмножество Этап 2. Синтез приоритетов Это один из способов решения проблемы многокритериальности. Синтез приоритетов (СП) – это вычисление собственных векторов, которые после нормализации и являются векторами приоритетов. Собственные векторы искать сравнительно трудоемко, поэтому достаточно близкие оценки можно получить с помощью геометрического среднего, для чего элементы каждой строки перемножаются и из результата извлекается корень n-й степени. Например, для Кр1 в матрице целей: Кр1: 1*1/2*1/3*1/4*4*3 = ½ Þ Кр2: 2*1*1/2*1/3*1/4*1/4 = 0, 0417 Þ Кр3: 3*2*1*1/3*1*1/2 = 1 Þ Кр4: 4*3*3*1*1*1/2 = 18 Þ Кр5: ¼ *4*1*1*1*1 = 1 Þ Кр6: 1/3*4*2*2*1*1 = 16/3 Þ Далее оценки нормируются путем деления на сумму α 1 = 0, 917 / 6, 193 = 0, 148; α 4 = 1, 435 / 6, 193 = 0, 23; α 2 = 0, 616 / 6, 193 = 0, 1; α 5 = 1 / 6, 193 = 0, 16; α 3 = 1 / 6, 193 = 0, 16; α 6 = 1, 23 / 6, 193 = 0, 198. Полученные оценки – это матрица – строка приоритетов критериевα 1х6. Далее для каждого из домов (альтернатив) рассчитываются приоритеты в смысле каждого из критериев: Для критерия Кр1 получим: для А: для В: для С: для D: Сумма равна 0, 76 + 1 + 1, 56 + 1 = 4, 32, поэтому нормированные значения приоритетов:
Аналогично для остальных критериев получим β 21, …, β 24; β 3, …, β 34; β 41, …, β 44; β 51, …, β 54; β 61, …, β 64. Данные приоритеты образуют матрицу В 6х4. Приоритеты альтернатив с учетом двух уровней, т.е. матриц α и В, получаются путем перемножения Ц = α х В, где Ц – матрица-строка глобальных приоритетов, т.е. оценки с точки зрения цели. Генетические алгоритмы. Генетические алгоритмы – перспективное и динамично развивающееся направление интеллектуальной обработки данных, связанное с решением задач поиска и оптимизации. Область применения генетических алгоритмов достаточно обширна. Финансовые компании используют их для прогнозирования развития финансовых рынков при управлении пакетами ценных бумаг. Генетические алгоритмы применяются для решения комбинаторных задач, для оценки значений непрерывных параметров моделей большой размерности, для оптимизации моделей, включающих одновременно непрерывные и дискретные параметры. Другая область применения – использование в системах извлечения новых знаний из больших баз данных, обучение нейронных сетей, оценка параметров в задачах многомерного статистического анализа. Сейчас при решении очень сложных задач основной целью является поиск уже не оптимального, а более «хорошего» решения по сравнению с решением, полученным ранее или заданным в качестве начального. Именно для этих целей и применяются генетические алгоритмы. Они не гарантируют обнаружения глобального экстремума целевой функции (или оптимального решения) за определенное время. Основное их преимущество в том, что они позволяют найти более “хорошие” решения очень трудных задач за меньшее время, чем другие методы. Генетические алгоритмы оказались достаточно эффективными для решения ряда реальных задач инженерного проектирования, планирования, маршрутизации и размещения, управления портфелями ценных бумаг, прогнозирования, а также во многих других областях. Отрицательной чертой генетических алгоритмов является то, что они представляют собой скорее подход к решению задач оптимизации, чем алгоритм. И вследствие этого требуют адаптации к каждому конкретному классу задач путем выбора определенных характеристик и параметров. Основные определения и свойства Генетические алгоритмы имеют целью нахождение не оптимального, а лучшего решения по сравнению с имеющимся решением задачи. Это связано с тем, что для сложной задачи часто требуется найти хоть какое-нибудь удовлетворительное решение, а проблема достижения оптимума отходит на второй план. При этом другие методы, ориентированные на поиск именно оптимального решения, вследствие чрезвычайной сложности задачи становятся вообще неприменимыми. Основные отличия генетических алгоритмов от традиционных методов: 1. Генетические алгоритмы работают с кодами, в которых представлен набор параметров, напрямую зависящих от аргументов целевой функции. Причем интерпретация этих кодов происходит только перед началом работы алгоритма и после завершения его работы для получения результата. Впроцессе работы манипуляции с кодами происходят независимо от их интерпретации, код рассматривается просто как битовая строка. 2. Для поиска генетический алгоритм использует несколько точек поискового пространства одновременно, а не переходит от точки к точке, как это делается в традиционных методах. Это позволяет преодолеть один из их недостатков – опасность попадания в локальный экстремум целевой функции, если она не является унимодальной, т. е. имеет несколько таких экстремумов. 3. Генетические алгоритмы в процессе работы не используют никакой дополнительной информации, что повышает скорость работы. Единственной используемой информацией может быть область допустимых значений параметров и целевой функции в произвольной точке. 4. Генетический алгоритм использует как вероятностные правила для порождения новых точек, так и детерминированные правила для перехода от одних точек к другим. Одновременное использование элементов случайности и детерминированности дает значительно больший эффект, чем раздельное. Прежде чем рассматривать непосредственно работу генетического алгоритма, введем ряд терминов, которые широко используются в данной области. Выше было показано, что генетический алгоритм работает с кодами безотносительно их смысловой интерпретации. Поэтому сам код и его структура описываются понятием генотип, а его интерпретация, с точки зрения решаемой задачи, – понятием фенотип. Каждый код представляет, по сути, точку пространства поиска. С целью максимально приблизиться к биологическим терминам, экземпляр кода называют хромосомой, особью или индивидуумом. На каждом шаге работы генетический алгоритм использует несколько точек поиска одновременно. Совокупность этих точек является набором особей, который называется популяцией. Количество особей в популяции называют размером популяции. Размер популяции является фиксированным и представляет одну из характеристик генетического алгоритма. На каждом шаге работы генетический алгоритм обновляет популяцию путем создания новых особей и уничтожения ненужных. Чтобы отличать популяции на каждом из шагов и сами эти шаги, их называют поколениями и обычно идентифицируют по номеру. Например, популяция, полученная из исходной популяции после первого шага работы алгоритма, является первым поколением, после следующего шага – вторым и т. д. В процессе работы алгоритма генерация новых особей происходит на основе моделирования процесса размножения. При этом, естественно, порождающие особи называются родителями, а порожденные – потомками. Родительская пара порождает пару потомков. Непосредственная генерация новых кодовых строк из двух выбранных происходит за счет работы оператора скрещивания. При порождении новой популяции оператор скрещивания может применяться не ко всем парам родителей. Часть этих пар может переходить в популяцию следующего поколения непосредственно. Насколько часто будет возникать такая ситуация, зависит от значения вероятности применения оператора скрещивания, которая является одним из параметров генетического алгоритма. Моделирование процесса мутации новых особей осуществляется за счет работы оператора мутации. Основным параметром оператора мутации также является вероятность мутации. Поскольку размер популяции фиксирован, то порождение потомков должно сопровождаться уничтожением других особей. Выбор пар родителей из популяции для порождения потомков производит оператор отбора, а выбор особей для уничтожения – оператор редукции. Основным параметром их работы является качество особи, которое определяется значением целевой функции в точке пространства поиска, описываемой этой особью. Таким образом, можно перечислить основные понятия и термины, используемые в области генетических алгоритмов: • генотип и фенотип; • особь и качество особи; • популяция и размер популяции; • поколение; • родители и потомки. К характеристикам генетического алгоритма относятся: • размер популяции; • оператор скрещивания и вероятность его использования; • оператор мутации и вероятность мутации; • оператор отбора; • оператор редукции; • критерий останова. Операторы отбора, скрещивания, мутации и редукции называют еще генетическими операторами. Критерием останова работы генетического алгоритма может быть одно из трех событий: 1. Сформировано заданное пользователем число поколений. 2. Популяция достигла заданного пользователем качества (например, значение качества всех особей превысило заданный порог). 3. Достигнут некоторый уровень сходимости, т. е. особи в популяции стали настолько подобными, что дальнейшее их улучшение происходит чрезвычайно медленно. Характеристики генетического алгоритма выбираются таким образом, чтобы обеспечить малое время работы, с одной стороны, и поиск как можно лучшего решения, с другой. 24.Классификация интеллектуальных информационных систем Для интеллектуальных информационных систем характерны следующие признаки: - развитые коммуникативные способности; - умение решать сложные плохо формализуемые задачи; - способность к самообучению; - адаптивность. Коммуникативные способности определяют способ взаимодействия пользователя с системой. Решение сложных плохо формализуемых задач требует построения оригинальных алгоритмов решения в зависимости от конкретной ситуации, характеризующейся неопределенностью и динамичностью данных и знаний. Способность к самообучению – умение системы автоматически извлекать знания из накопленного опыта и применять их для решения задач. Популярное:
|
Последнее изменение этой страницы: 2016-07-12; Просмотров: 1478; Нарушение авторского права страницы
 С появлением сетей появились возможности ИС общего пользователя.
С появлением сетей появились возможности ИС общего пользователя. Т.е. с увеличением компьютеров, устойчивых в обработке, а так же с ростом объема хранимых данных, нагрузка на локальную сеть может вырасти настолько, что это приведет к замедлению работы всей системы, а чтобы как-то увеличить производимость системы придется наращивать производительность системы, ФС, ЛС и сетевых компьютеров.
Т.е. с увеличением компьютеров, устойчивых в обработке, а так же с ростом объема хранимых данных, нагрузка на локальную сеть может вырасти настолько, что это приведет к замедлению работы всей системы, а чтобы как-то увеличить производимость системы придется наращивать производительность системы, ФС, ЛС и сетевых компьютеров. Систему называют 2-х уровневой. Широко используют при построении ИС в сети Internet.
Систему называют 2-х уровневой. Широко используют при построении ИС в сети Internet.
 . Иногда в качестве Т удобно выбирать счётное множество T={0, 1, 2, ….} или T={0, h, 2h, ….}, где h – фиксированное значение.
. Иногда в качестве Т удобно выбирать счётное множество T={0, 1, 2, ….} или T={0, h, 2h, ….}, где h – фиксированное значение. элементов, из которых в данный момент состоит система, и
элементов, из которых в данный момент состоит система, и  , указывающее, какие связи реализованы в момент времени Т.
, указывающее, какие связи реализованы в момент времени Т. ,
,  ,
,  ,
, 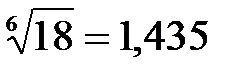 ,
,  ,
,  .
.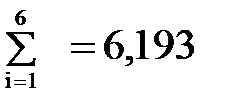 ;
; 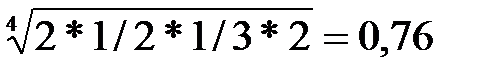 ,
, 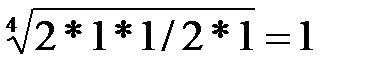 ,
,  ,
, 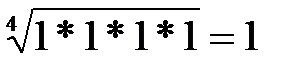 .
.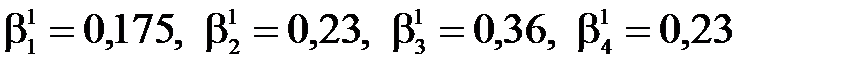 .
.