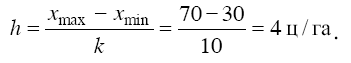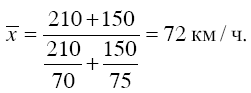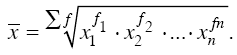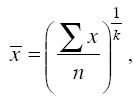|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Предмет и метод статистики как общественной наукиСтр 1 из 17Следующая ⇒
СТАТИСТИКА
Статистическое наблюдение
Понятие о статистическом наблюдении, этапы его проведения Глубокое всестороннее исследование любого экономического или социального процесса предполагает измерение его количественной стороны и характеристику его качественной сущности, места, роли и взаимосвязей в общей системе общественных отношений. Прежде чем приступить к использованию статистических методов изучения явлений и процессов общественной жизни, необходимо иметь в своем распоряжении исчерпывающую информационную базу, в полной мере и достоверно описывающую объект исследования. Процесс статистического исследования предполагает проведение следующих этапов:
Статистическое наблюдение – первый и исходный этап статистического исследования, который представляет собой систематический, планомерно организуемый на научной основе процесс сбора первичных данных о различных явлениях социальной и экономической жизни. Планомерность статистического наблюдения заключается в том, что оно проводится по специально разработанному плану, который включает в себя вопросы, связанные с организацией и техникой сбора статистической информации, контроля ее качества и достоверности, представления итоговых материалов. Массовый характер статистического наблюдения обеспечивается наиболее полным охватом всех случаев проявления изучаемого явления или процесса, т. е. в процессе статистического наблюдения подвергаются измерению и регистрации количественные и качественные характеристики не отдельных единиц изучаемой совокупности, а всей массы единиц совокупности. Систематичность статистического наблюдения означает, что оно должно проводиться не случайным образом, т. е. стихийно, а выполняться либо непрерывно, либо регулярно через равные промежутки времени. Процесс проведения статистического наблюдения представлен на рис. 2.1.
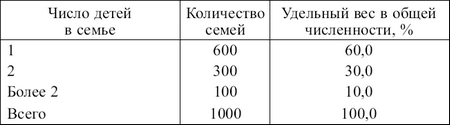
Рис. 2.1. Схема проведения статистического наблюдения Процесс подготовки статистического наблюдения предполагает определение цели и объекта наблюдения, состава признаков, подлежащих регистрации, выбора единицы наблюдения. Также необходимо разработать бланки документов для сбора данных и выбрать средства и методы их получения. Таким образом, статистическое наблюдение представляет собой трудоемкую и кропотливую работу, требующую привлечения квалифицированных кадров, всесторонне продуманной ее организации, планирования, подготовки и проведения. Точность наблюдения и методы проверки достоверности данных Каждое конкретное измерение величины данных, осуществляемое в процессе наблюдения, дает, как правило, приближенное значение величины явления, в той или иной мере отличающееся от истинного значения этой величины. Степень соответствия действительной величине какого-либо показателя или признака, полученного по материалам наблюдения, называется точностыю статистического наблюдения. Расхождение между результатом наблюдения и истинным значением величины наблюдаемого явления называется ошибкой наблюдения. В зависимости от характера, стадии и причин возникновения различают несколько типов ошибок наблюдения (табл. 2.1). Таблица 2.1 Применение дискретного ряда распределения
В случае непрерывной вариации величина признака может принимать любые значения в определенном интервале, например распределение работников фирмы по уровню дохода (табл. 3.6). Таблица 3.6 Случай непрерывной вариации
При построении интервального вариационного ряда необходимо выбрать оптимальное число групп (интервалов признака) и установить длину интервала. Оптимальное число групп выбирается так, чтобы отразить многообразие значений признака в совокупности. Чаще всего число групп устанавливается по формуле k = 1 + 3, 32lg N = 1, 44ln N + 1, где k – число групп; N – численность совокупности. Например, необходимо построить вариационный ряд сельскохозяйственных предприятий по урожайности зерновых культур. Число сельскохозяйственных предприятий – 143. Как определить число групп? k = 1 + 3, 32lg N = 1 + 3, 32lg143 = 8, 16. Число групп может быть только целым числом, в данном случае – 8 или 9. Пример. Минимальная урожайность составляет 30 ц/га, максимальная – 70 ц/га, а число намеченных групп – 10. Величину интервала можно рассчитать по формуле (3.1):
Если полученная группировка не удовлетворяет требованиям анализа, то можно произвести перегруппировку. Не следует стремиться к очень большому количеству групп, так как в такой группировке часто исчезают различия между группами. Также надо избегать образования и слишком малочисленных групп, включающих несколько единиц совокупности, потому что в таких группах перестает действовать закон больших чисел и возможно проявление случайности. Когда не удается сразу наметить возможные группы, собранный материал сначала разбивают на значительное количество групп, а затем укрупняют их, уменьшая количество групп и создавая качественно однородныле группыл. Таким образом, группировки во всех случаях должны быть построены так, чтобы образованные в них группы как можно полнее отвечали действительности, были видны различия между группами и в одну группу не объединялись существенно различающиеся между собой явления. Статистические таблицы После того как данные статистического наблюдения собраны и даже сгруппированы, их трудно воспринимать и анализировать без определенной, наглядной систематизации. Результаты статистических сводок и группировок получают оформление в виде статистических таблиц. Статистическая таблица дает количественную характеристику статистической совокупности и представляет собой форму наглядного отображения полученных в результате статистической сводки и группировки числовых (цифровых) данных. По внешнему виду таблица представляет собой комбинацию вертикальных и горизонтальных строк. В ней обязательно должны быть общие боковые и верхние заголовки. Еще одной особенностью статистической таблицы является наличие подлежащего (характеристика статистической совокупности) и сказуемого (показатели, характеризующие совокупности). Статистические таблицы являются наиболее рациональной формой изложения результатов сводки или группировки. Подлежащее таблицы представляет ту статистическую совокупность, о которой идет речь в таблице, т. е. перечень отдельных или всех единиц совокупности либо их групп. Чаще всего подлежащее помещается в левой части таблицы и содержит перечень строк. Сказуемое таблицы – это те показатели, с помощью которых дается характеристика явления, отображаемого в таблице. Подлежащее и сказуемое таблицы могут располагаться по-разному, главное, чтобы таблица была легко читаемой, компактной и легко воспринималась. В статистической практике и исследовательских работах используются таблицы различной сложности. Это зависит от характера изучаемой совокупности, объема имеющейся информации, задач анализа. Если в подлежащем таблицы содержится простой перечень каких-либо объектов или территориальных единиц, таблица называется простой. В подлежащем простой таблицы нет каких-либо группировок статистических данных. Эти таблицы имеют самое широкое применение в статистической практике, например характеристика городов РФ по численности населения, средней зарплате и т. п. Если подлежащее простой таблицы содержит перечень территорий, например областей, краев, автономных округов, республик и т. д., то такая таблица называется территориальной. Простая таблица содержит только описательные сведения, ее аналитические возможности ограничены. Глубокий анализ исследуемой совокупности, взаимосвязей признаков предполагает построение более сложных таблиц – групповых и комбинационных. Групповые таблицы в отличие от простых содержат в подлежащем не простой перечень единиц объекта наблюдения, а их группировку по одному существенному признаку. Простейшим видом групповой таблицы являются таблицы, в которых представлены ряды распределения (см. табл. 3.6). Групповая таблица может быть более сложной, если в сказуемом приводится не только число единиц в каждой группе, но и ряд других важных показателей, количественно и качественно характеризующих группы подлежащего. Такие таблицы часто используются в целях сопоставления обобщающих показателей по группам, что позволяет сделать определенные практические выводы. Более широкими аналитическими возможностями располагают комбинационные таблицы. Комбинационными называются статистические таблицы, в подлежащем которых группы единиц, образованные по одному признаку, подразделяются на подгруппы по одному или нескольким признакам. В отличие от простых и групповых таблиц комбинационные позволяют проследить зависимость показателей сказуемого от нескольких признаков, которые легли в основу комбинационной группировки в подлежащем. Наряду с перечисленными выше таблицами в статистической практике применяют таблицы сопряженности, или таблицы частот. В основе построения таких таблиц лежит группировка единиц совокупности по двум или более признакам, которые называются уровнями. Например, население делится по полу (мужской, женский) и т. п. Таким образом, признак А имеет n градаций (или уровней): A1, A2, An (в нашем примере n = 2). Далее изучается взаимодействие признака А с другим признаком – В, который подразделяется на m градаций (факторов): B1, B2, ..., Bm. В нашем примере признак В – принадлежность к какой-либо профессии, а B1, B2, Bm принимают конкретные значения (доктор, водитель, учитель, строитель и т. д.). Группировка по двум и более признакам используется для оценки взаимосвязей между признаками А и В. Результаты наблюдений можно представить таблицей сопряженности, состоящей из n строк и m столбцов, в ячейках которых проставлены частоты событий nij, т. е. количество объектов выборки, обладающих комбинацией уровней Aj и Bj. Если между переменными A и B имеется взаимно-однозначная прямая или обратная функциональная связь, то все частоты nij концентрируются по одной из диагоналей таблицы. При не столь сильной связи некоторое число наблюдений попадает и на недиагональные элементы. В этих условиях перед исследователем стоит задача: выяснить, насколько точно можно предсказать значение одного признака по величине другого. Таблица частот называется одномерной, если в ней табулирована только одна переменная. Таблица, в основе которой лежит группировка по двум признакам (уровням), которые табулируются по двум признакам (факторам), называется таблицей с двумя входами. Таблицы частот, в которых табулируются значения двух или более признаков, называются таблицами сопряженности. Из всех видов статистических таблиц наиболее широкое применение имеют простые таблицы, реже применяются групповые и особенно комбинационные статистические таблицы, а таблицы сопряженности строят для проведения специальных видов анализа. Статистические таблицы служат одним из важных способов выражения и изучения массовых общественных явлений, но лишь при условии правильного их построения. Форма любой статистической таблицы должна наилучшим образом отвечать сущности выражаемого ею явления и целям его изучения. Это достигается путем соответствующей разработки подлежащего и сказуемого таблицы. Внешне таблица должна быть небольшой и компактной, иметь название, указание единиц измерения, а также времени и места, к которым относятся сведения. Заголовки строк и граф в таблице даются кратко, но четко. Чрезмерное загромождение таблицы цифровыми данными, неряшливое оформление затрудняют ее чтение и анализ. Перечислим основные правила построения статистических таблиц:
В случае необходимости дополнительной информации статистические таблицы сопровождаются сносками и примечаниями, в которых разъясняются, например, сущность специфического показателя, примененной методологии и т. д. Сносками пользуются для того, чтобы указать на ограниченные обстоятельства, которые надо принять во внимание при чтении таблицы. При соблюдении этих правил статистическая таблица становится основным средством представления, обработки и обобщения статистической информации о состоянии и развитии изучаемых социально-экономических явлений. Виды средних величин В статистике используют различные виды средних величин, которые делятся на два больших класса:
Для вычисления степенных средних необходимо использовать все имеющиеся значения признака. Мода и медиана определяются лишь структурой распределения, поэтому их называют структурными, позиционными средними. Медиану и моду часто используют как среднюю характеристику в тех совокупностях, где расчет средней степенной невозможен или нецелесообразен. Самый распространенный вид средней величины – средняя арифметическая. Под средней арифметической понимается такое значение признака, которое имела бы каждая единица совокупности, если бы общий итог всех значений признака был распределен равномерно между всеми единицами совокупности. Вычисление данной величины сводится к суммированию всех значений варьирующего признака и делению полученной суммы на общее количество единиц совокупности. Например, пять рабочих выполняли заказ на изготовление деталей, при этом первый изготовил 5 деталей, второй – 7, третий – 4, четвертый – 10, пятый– 12. Поскольку в исходных данных значение каждого варианта встречалось только один раз, для определения средней выработки одного рабочего следует применить формулу простой средней арифметической:
т. е. в нашем примере средняя выработка одного рабочего равна
Наряду с простой средней арифметической изучают среднюю арифметическую взвешенную. Например, рассчитаем средний возраст студентов в группе из 20 человек, возраст которых варьируется от 18 до 22 лет, где xi – варианты осредняемого признака, fi – частота, которая показывает, сколько раз встречается i-е значение в совокупности (табл. 5.1). Таблица 5.1 Средний возраст студентов
Применяя формулу средней арифметической взвешенной, получаем:
Для выбора средней арифметической взвешенной существует определенное правило: если имеется ряд данных по двум показателям, для одного из которых надо вычислить среднюю величину, и при этом известны численные значения знаменателя ее логической формулы, а значения числителя неизвестны, но могут быть найдены как произведение этих показателей, то средняя величина должна высчитывать-ся по формуле средней арифметической взвешенной. В некоторых случаях характер исходных статистических данных таков, что расчет средней арифметической теряет смысл и единственным обобщающим показателем может служить только другой вид средней величины – средняя гармоническая. В настоящее время вычислительные свойства средней арифметической потеряли свою актуальность при расчете обобщающих статистических показателей в связи с повсеместным внедрением электронно-вычислительной техники. Большое практическое значение приобрела средняя гармоническая величина, которая тоже бывает простой и взвешенной. Если известны численные значения числителя логической формулы, а значения знаменателя неизвестны, но могут быть найдены как частное деление одного показателя на другой, то средняя величина вычисляется по формуле средней гармонической взвешенной. Например, пусть известно, что автомобиль прошел первые 210 км со скоростью 70 км/ч, а оставшиеся 150 км со скоростью 75 км/ч. Определить среднюю скорость автомобиля на протяжении всего пути в 360 км, используя формулу средней арифметической, нельзя. Так как вариантами являются скорости на отдельных участках xj = 70 км/ч и Х2 = 75 км/ч, а весами (fi) считаются соответствующие отрезки пути, то произведения вариантов на веса не будут иметь ни физического, ни экономического смысла. В данном случае смысл приобретают частные от деления отрезков пути на соответствующие скорости (варианты xi), т. е. затраты времени на прохождение отдельных участков пути (fi/xi). Если отрезки пути обозначить через fi, то весь путь выразиться как Σ fi, а время, затраченное на весь путь, – как Σ fi/xi , Тогда средняя скорость может быть найдена как частное от деления всего пути на общие затраты времени:
В нашем примере получим:
Если при использовании средней гармонической веса всех вариантов (f) равны, то вместо взвешенной можно использовать простую (невзвешенную) среднюю гармоническую:
где xi – отдельные варианты; n – число вариантов осредняемого признака. В примере со скоростью простую среднюю гармоническую можно было бы применить, если бы были равны отрезки пути, пройденные с разной скоростью. Любая средняя величина должна вычисляться так, чтобы при замене ею каждого варианта осредняемого признака не изменялась величина некоторого итогового, обобщающего показателя, который связан с осредняемым показателем. Так, при замене фактических скоростей на отдельных отрезках пути их средней величиной (средней скоростью) не должно измениться общее расстояние. Форма (формула) средней величины определяется характером (механизмом) взаимосвязи этого итогового показателя с осредняемым, поэтому итоговый показатель, величина которого не должна изменяться при замене вариантов их средней величиной, называется определяющим показателем. Для вывода формулы средней нужно составить и решить уравнение, используя взаимосвязь осредняемого показателя с определяющим. Это уравнение строится путем замены вариантов осредняемого признака (показателя) их средней величиной. Кроме средней арифметической и средней гармонической в статистике используются и другие виды (формы) средней величины. Все они являются частными случаями степенной средней. Если рассчитывать все виды степенных средних величин для одних и тех же данных, то значения их окажутся одинаковыми, здесь действует правило мажо-рантности средних. С увеличением показателя степени средних увеличивается и сама средняя величина. Наиболее часто применяемые в практических исследованиях формулы вычисления различных видов степенных средних величин представлены в табл. 5.2. Таблица 5.2 Виды степенных средних
Средняя геометрическая применяется, когда имеется n коэффициентов роста, при этом индивидуальные значения признака представляют собой, как правило, относительные величины динамики, построенные в виде цепных величин, как отношение к предыдущему уровню каждого уровня в ряду динамики. Средняя характеризует, таким образом, средний коэффициент роста. Средняя геометрическая простая рассчитывается по формуле
Формула средней геометрической взвешенной имеет следующий вид:
Приведенные формулы идентичны, но одна применяется при текущих коэффициентах или темпах роста, а вторая – при абсолютных значениях уровней ряда. Средняя квадратическая применяется при расчете с величинами квадратных функций, используется для измерения степени колеблемости индивидуальных значений признака вокруг средней арифметической в рядах распределения и вычисляется по формуле
Средняя квадратическая взвешенная рассчитывается по другой формуле:
Средняя кубическая применяется при расчете с величинами кубических функций и вычисляется по формуле
средняя кубическая взвешенная:
Все рассмотренные выше средние величины могут быть представлены в виде общей формулы:
где – средняя величина; – индивидуальное значение; n – число единиц изучаемой совокупности; k – показатель степени, определяющий вид средней. При использовании одних и тех же исходных данных, чем больше k в общей формуле степенной средней, тем больше средняя величина. Из этого следует, что между величинами степенных средних существует закономерное соотношение:
Средние величины, описанные выше, дают обобщенное представление об изучаемой совокупности и с этой точки зрения их теоретическое, прикладное и познавательное значение бесспорно. Но бывает, что величина средней не совпадает ни с одним из реально существующих вариантов, поэтому кроме рассмотренных средних в статистическом анализе целесообразно использовать величины конкретных вариантов, занимающие в упорядоченном (ранжированном) ряду значений признака вполне определенное положение. Среди таких величин наиболее употребительными являются структурные, или описательные, средние – мода (Мо) и медиана (Ме). Мода – величина признака, которая чаще всего встречается в данной совокупности. Применительно к вариационному ряду модой является наиболее часто встречающееся значение ранжированного ряда, т. е. вариант, обладающий наибольшей частотой. Мода может применяться при определении магазинов, которые чаще посещаются, наиболее распространенной цены на какой-либо товар. Она показывает размер признака, свойственный значительной части совокупности, и определяется по формуле
где х0 – нижняя граница интервала; h – величина интервала; fm – частота интервала; fm_1 – частота предшествующего интервала; fm+1 – частота следующего интервала. Медианой называется вариант, расположенный в центре ранжированного ряда. Медиана делит ряд на две равные части таким образом, что по обе стороны от нее находится одинаковое количество единиц совокупности. При этом у одной половины единиц совокупности значение варьирующего признака меньше медианы, у другой – больше ее. Медиана используется при изучении элемента, значение которого больше или равно или одновременно меньше или равно половине элементов ряда распределения. Медиана дает общее представление о том, где сосредоточены значения признака, иными словами, где находится их центр. Описательный характер медианы проявляется в том, что она характеризует количественную границу значений варьирующего признака, которыми обладает половина единиц совокупности. Задача нахождения медианы для дискретного вариационного ряда решается просто. Если всем единицам ряда придать порядковые номера, то порядковый номер медианного варианта определяется как (п +1) / 2 с нечетным числом членов п. Если же количество членов ряда является четным числом, то медианой будет являться среднее значение двух вариантов, имеющих порядковые номера n / 2 и n / 2 + 1. При определении медианы в интервальных вариационных рядах сначала определяется интервал, в котором она находится (медианный интервал). Этот интервал характерен тем, что его накопленная сумма частот равна или превышает полусумму всех частот ряда. Расчет медианы интервального вариационного ряда производится по формуле
где X0 – нижняя граница интервала; h – величина интервала; fm – частота интервала; f– число членов ряда; ∫ m-1 – сумма накопленных членов ряда, предшествующих данному. Наряду с медианой для более полной характеристики структуры изучаемой совокупности применяют и другие значения вариантов, занимающих в ранжированном ряду вполне определенное положение. К ним относятся квартили и децили. Квартили делят ряд по сумме частот на 4 равные части, а децили – на 10 равных частей. Квартилей насчитывается три, а децилей – девять. Медиана и мода в отличие от средней арифметической не погашают индивидуальных различий в значениях варьирующего признака и поэтому являются дополнительными и очень важными характеристиками статистической совокупности. На практике они часто используются вместо средней либо наряду с ней. Особенно целесообразно вычислять медиану и моду в тех случаях, когда изучаемая совокупность содержит некоторое количество единиц с очень большим или очень малым значением варьирующего признака. Эти, не очень характерные для совокупности значения вариантов, влияя на величину средней арифметической, не влияют на значения медианы и моды, что делает последние очень ценными для экономико-статистического анализа показателями. Показатели вариации Целью статистического исследования является выявление основных свойств и закономерностей изучаемой статистической совокупности. В процессе сводной обработки данных статистического наблюдения строят ряды распределения. Различают два типа рядов распределения – атрибутивные и вариационные, в зависимости от того, является ли признак, взятый за основу группировки, качественным или количественным. Вариационными называют ряды распределения, построенные по количественному признаку. Значения количественных признаков у отдельных единиц совокупности не постоянны, более или менее различаются между собой. Такое различие в величине признака носит название вариации. Отдельные числовые значения признака, встречающиеся в изучаемой совокупности, называют вариантами значений. Наличие вариации у отдельных единиц совокупности обусловлено влиянием большого числа факторов на формирование уровня признака. Изучение характера и степени вариации признаков у отдельных единиц совокупности является важнейшим вопросом всякого статистического исследования. Для описания меры изменчивости признаков используют показатели вариации. Другой важной задачей статистического исследования является определение роли отдельных факторов или их групп в вариации тех или иных признаков совокупности. Для решения такой задачи в статистике применяются специальные методы исследования вариации, основанные на использовании системы показателей, с помощью которых измеряется вариация. В практике исследователь сталкивается с достаточно большим количеством вариантов значений признака, что не дает представления о распределении единиц по величине признака в совокупности. Для этого проводят расположение всех вариантов значений признака в возрастающем или убывающем порядке. Этот процесс называют ранжированием ряда. Ранжированный ряд сразу дает общее представление о значениях, которые принимает признак в совокупности. Недостаточность средней величины для исчерпывающей характеристики совокупности заставляет дополнять средние величины показателями, позволяющими оценить типичность этих средних путем измерения колеблемости (вариации) изучаемого признака. Использование этих показателей вариации дает возможность сделать статистический анализ более полным и содержательным и тем самым глубже понять сущность изучаемых общественных явлений. Самыми простыми признаками вариации являются минимум и максимум – это наименьшее и наибольшее значение признака в совокупности. Число повторений отдельных вариантов значений признаков называют частотой повторения. Обозначим частоту повторения значения признака fi, сумма частот, равная объему изучаемой совокупности будет:
где k – число вариантов значений признака. Частоты удобно заменять частостями – wi. Частость – относительный показатель частоты – может быть выражен в долях единицы или процентах и позволяет сопоставлять вариационные ряды с различным числом наблюдений. Формально имеем:
Для измерения вариации признака применяются различные абсолютные и относительные показатели. К абсолютным показателям вариации относятся среднее линейное отклонение, размах вариации, дисперсия, среднее квадратическое отклонение. Размах вариации (R) представляет собой разность между максимальным и минимальным значениями признака в изучаемой совокупности: R = Xmax – Xmin. Этот показатель дает лишь самое общее представление о колеблемости изучаемого признака, так как показывает разницу только между предельными значениями вариантов. Он совершенно не связан с частотами в вариационном ряду, т. е. с характером распределения, а его зависимость может придавать ему неустойчивый, случайный характер только от крайних значений признака. Размах вариации не дает никакой информации об особенностях исследуемых совокупностей и не позволяет оценить степень типичности полученных средних величин. Область применения этого показателя ограничена достаточно однородными совокупностями, точнее, характеризует вариацию признака показатель, основанный на учете изменчивости всех значений признака. Для характеристики вариации признака нужно обобщить отклонения всех значений от какой-либо типичной для изучаемой совокупности величины. Такие показатели вариации, как среднее линейное отклонение, дисперсия и среднее квадратическое отклонение, основаны на рассмотрении отклонений значений признака отдельных единиц совокупности от средней арифметической. Среднее линейное отклонение представляет собой среднюю арифметическую из абсолютных значений отклонений отдельных вариантов от их средней арифметической:
– абсолютное значение (модуль) отклонения варианта от средней арифметической; f– частота. Первая формула применяется, если каждый из вариантов встречается в совокупности только один раз, а вторая – в рядах с неравными частотами. Существует и другой способ усреднения отклонений вариантов от средней арифметической. Этот очень распространенный в статистике способ сводится к расчету квадратов отклонений вариантов от средней величины с их последующим усреднением. При этом мы получаем новый показатель вариации – дисперсию. Дисперсия (σ 2) – средняя из квадратов отклонений вариантов значений признака от их средней величины:
Вторая формула применяется при наличии у вариантов своих весов (или частот вариационного ряда). В экономико-статистическом анализе вариацию признака принято оценивать чаще всего с помощью среднего квадратического отклонения. Среднее квадратическое отклонение (σ ) представляет собой корень квадратный из дисперсии:
Среднее линейное и среднее квадратическое отклонения показывают, на сколько в среднем колеблется величина признака у единиц исследуемой совокупности, и выражаются в тех же единицах измерения, что и варианты. В статистической практике часто возникает необходимость сравнения вариации различных признаков. Например, большой интерес представляет сравнение вариаций возраста персонала и его квалификации, стажа работы и размера заработной платы и т. д. Для подобных сопоставлений показатели абсолютной колеблемости признаков – среднее линейное и среднее квадртическое отклонение – не пригодны. Нельзя, в самом деле, сравнивать колеблемость стажа работы, выражаемую в годах, с колеблемостью заработной платы, выражаемой в рублях и копейках. При сравнении изменчивости различных признаков в совокупности удобно применять относительные показатели вариации. Эти показатели вычисляются как отношение абсолютных показателей к средней арифметической (или медиане). Используя в качестве абсолютного показателя вариации размах вариации, среднее линейное отклонение, среднее квадратическое отклонение, получают относительные показатели колеблемости:
– наиболее часто применяемый показатель относительной колеблемости, характеризующий однородность совокупности. Совокупность считается однородной, если коэффициент вариации не превышает 33 % для распределений, близких к нормальному. Индексный анализ
Средние индексы Популярное:
|
Последнее изменение этой страницы: 2016-08-24; Просмотров: 557; Нарушение авторского права страницы