|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Современное состояние аппаратного обеспечения нейросетевых алгоритмов
Базовая нейросетевая парадигма EBP. Выбор сети и ее параметров. В роли базовой нейросетевой парадигмы для системы управления выберем сеть с обратным распространением ошибки (error back propagation – EBP). Этот выбор можно объяснить следующими характеристиками сети: − достаточно простой алгоритм функционирования; − относительно высокая скорость обучения; − возможность преобразования до системы управления. Будем использовать нейроны с сигмоидной (логистической) характеристикой с нулевым порогом:
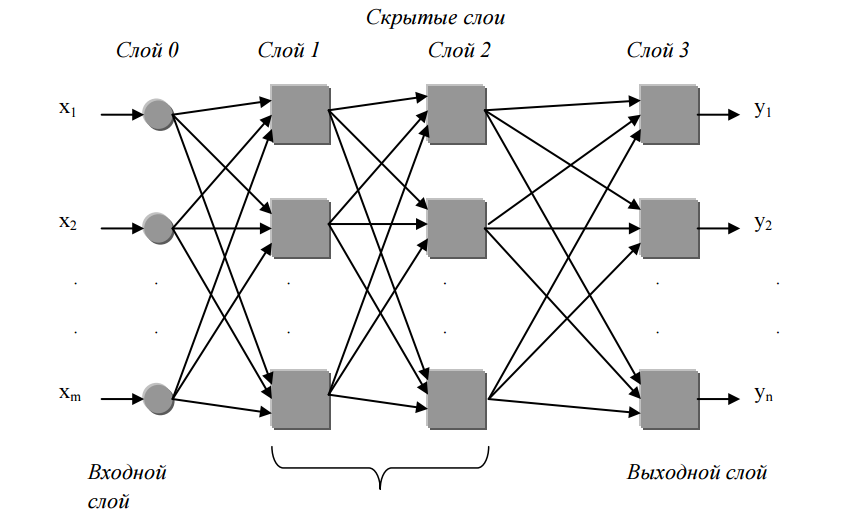
Рисунок сигмоидная характеристика с нулевым порогом В сравнении с другими нейронами данная характеристика обладает следующими преимуществами: − имитация порога – т. е. области со скачкообразным изменением функции; − особенность усиливать слабые сигналы и ослаблять сильные; − функция обладает простой рпоизводной: y(1 – y). Общий вид сети EBP приведен на рисунке Здесь под входным слоем (слой 0) понимается так называемый «мнимый слой», т. е. это не слой отдельных нейронов, а точки разветвления входных сигналов, направляемых к скрытому слою. Данная условность служит для придания большей наглядности обозначениям связей между нейронами скрытого слоя и входами сети: W0i, где i – номер нейрона скрытого слоя.
Для нашего варианта будем использовать сеть с двумя скрытыми слоями, что обеспечит нам возможность описать практически любую область в пространстве состояний сети. Количество нейронов в скрытых слоях одинаково, по этой причине скрытый блок в геометрической интерпретации будет представляться прямоугольником размером 2 × k, где k – количество нейронов в скрытых слоях, определяющее емкость системы знаний сети. Обучение сети. Процесс обучения состоит в закреплении на входе и выходе сети необходимых значений и перенастройке весов связей сети таким образом, чтобы она исполняла функцию изменения входного вектора в выходной с минимальными потерями. Сжато алгоритм обучения можно описать так: 1) приготовить обучающую выборку, т. е. совокупность входных и выходных векторов сети; 2) всем связям сети назначить небольшие случайные значения; 3) выбрать некоторую обучающую пару и зафиксировать ее на входе – выходе сети; 4) найти действительный выход сети, произведя ее пересчет; 5) найти разность между действительным и желаемым выходом сети; 6) произвести изменение веса сети для минимизации ошибки; 7) циклично повторять пункты 3–6 до тех пор, пока общая ошибка сети не станет минимальной. Закон обучения сети представлен следующим выражением:
где Wij – значение веса связи между i-м и j-м нейронами; η – скорость обучения; δ j – ошибка j-го нейрона; yi – выход i-го нейрона. Ошибка выходного слоя определяется соотношением
где f – характеристика нейрона; yж, y – желаемое и действительное возбуждения нейрона. Для сигмоидной характеристики производная
Пересчет сети. Напишем процедуру на алгоритмическом языке Паскаль, производящую пересчет сети. procedure calculate; const New=1; Old=0; var i, j: integer; {Глобальные переменные: AllRel – число связей сети; AllNeuron – число нейронов сети; Neuron – массив, хранящий возбуждения нейронов; Relat – массив, хранящий проводимость связей; } begin for i: =1 to AllRel do for j: =1 to AllRel do {распространение возбуждения нейронов по сети} Neuron[New, i]: =Neuron[New, i]+Neuron[Old, j]*Relat[j, i]; for i: =1 to AllNeuron do begin Neuron[Old, i]: =Neuron[New, i]; Neuron[New, i]: =0; end;
Рассмотрим основные трудности, которые связаны с обучением нейросети. Паралич сети. Когда веса всех связей нейрона стремятся к единице, выход нейрона начнет также стремиться к единице. В этой точке производная характеристики нейрона стремится к нулю, и, как показано в формулах (1.7, 1.9), ошибка нейрона также будет стремиться к нулю, что повлечет за собой уменьшение скорости его обучения. Для устранения этой проблемы используется следующий алгоритм: когда выход нейрона стремится к единице, то все его связи изменяются в соответствии с формулой
Локальный минимум. Описанный выше закон обучения сети (1.6) сглаживает минимизацию общей ошибки работы сети ε алгоритмом градиентного спуска в пространстве весов. В этом случае сеть может попасть в своеобразный «локальный минимум», т. е. в зону с неоптимальным минимумом ошибки. Из этой «ямы» абослютно любой путь ведет к уве- личению ошибки сети, в связи с этим алгоритм обучения может распознать это за оптимум и остановить обучение. Для решения данной проблемы исправляют скорость обучения η: в самом начале обучения ей присваивают максимальное значение (чуть больше единицы), а далее, в процессе обучения, данная величина уменьшается. Скорость обучения. Скорость обучения является одной из самых острых проблем практически для всех нейросетевых парадигм, невзирая на некоторое преимущество сети EBP. Для получения требуемой точности надо предъявлять обучающую выборку около 60 раз. есть несколько различных методик обхода данной проблемы, мы же будем использовать только два: 1. Метод импульса, заключающийся во введении инерционного члена в закон обучения сети (1.6), который является аналогом кратковременной памяти. При этом обучение сети будет происходить по следующему правилу:
где α – коэффициент импульса, равен около 0, 1. После происходит приведение выходов нейронов от диапазона [0... 1] к диапазону [–0, 5 … 0, 5]. В это время функция нейрона преобразуется в следующую:
Ускорение обучения, которое достигается с помощью такого метода, приобретает значение, равное около 30–50%. 2. Комбинирование сети обратного распространения и машины Коши. Эффективно решить такую проблему обучения сети, как локальный минимум, разрешает добавление к конфигурированию связей некоторой случайной, затухающей во времени величины xс, которая определяется по формуле:
где β – весовой коэффициент (если он равен 0, то это обучение Коши). Если при вычислении весов связей суммарная ошибка сети возрастает, то изменения сохраняются, в обратном случае они сохраняются с вероятностью распределения Больцмана: ( ), kT W P W e ∆ − ∆ = где k – коэффициент распределения.
На графике рис. 1.5 показано данное распределение как функция от изменения связей и температуры. Очевидно, что при нулевом изменении вероятность всегда будет равна единице; при изменении, отличном от нуля, вероятность будет уменьшаться с падением температуры до нуля. Обучение Будет продолжаться до того момента, пока температура не упадет до уже мзаданной величины. При этом процесс обучения будет выглядеть так, как он изображен на рис. 1.5.
Популярное:
|
Последнее изменение этой страницы: 2017-03-03; Просмотров: 447; Нарушение авторского права страницы