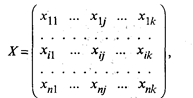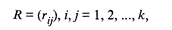|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
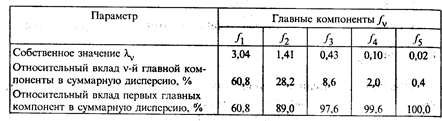
Собственные значения главных компонент
Ограничимся экономической интерпретацией двух первых главных компонент, общий вклад которых в суммарную дисперсию составляет 89, 0%. В матрице факторных нагрузок
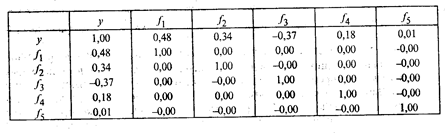
звездочкой указаны элементы аjv = rxjfv, учитывающиеся при интерпретации главных компонент fv, где j, v = 1, 2, ..., 5. Из матрицы факторных нагрузок А следует, что первая главная компонента наиболее тесно связана со следующими показателями: x1 — число колесных тракторов на 100 га (a11 = rx1f1 = 0, 95); х2 — число зерноуборочных комбайнов на 100 га (rx2f1 = 0, 97); х3 — число орудий поверхностной обработки почвы на 100 га (rx3f1 = 0, 94). В этой связи первая главная компонента — f1 — интерпретирована как уровень механизации работ. Вторая главная компонента — f2 — тесно связана с количеством удобрений (х4) и химических средств оздоровления растений (x5), расходуемых на гектар, и интерпретирована как уровень химизации растениеводства. Уравнение регрессии на главных компонентах строится по данным вектора значений результативного признака Y и матрицы F значений главных компонент. Некоррелированность главных компонент между собой и тесноту их связи с результативным признаком у показывает матрица парных коэффициентов корреляции (табл. 53.3). Анализ матрицы парных коэффициентов корреляции свидетельствует о том, что результативный признак у наиболее тесно связан с первой (ryf1 = 0, 48), третьей (ryf3 = 0, 37) и. второй (ryf2 = 0, 34) главными компонентами. Можно предположить, что толькоэти главные компоненты войдут в регрессионную модель у.
Таблица 53.3 Матрица парных коэффициентов корреляции
Первоначально в модель у включают все главные компоненты (в скобках указаны расчетные значения t-критерия):
Качество модели характеризуют: множественный коэффициент детерминации r Если значимость уравнения регрессии (гипотеза Н0: β 1 = β 2 = β 3 = β 4 = 0проверялась при α = 0, 05, то значимость коэффициентов регрессии, т.е. гипотезы H0: β j = 0 (j = 1, 2, 3, 4), следует проверять при уровне значимости, большем, чем 0, 05, например при α = 0, 1. Тогда при α = 0, 1, v = 14 величина tкр = 1, 76, и значимыми, как следует из уравнения (53.41), являются коэффициенты регрессии β 1, β 2, β 3. Учитывая, что главные компоненты не коррелированы между собой, можно сразу исключить из уравнения все незначимые коэффициенты, и уравнение примет вид
Сравнив уравнения (53.41) и (53.42), видим, что исключение незначимых главных компонент f4 и f5, не отразилось на значениях коэффициентов уравнения b0 = 9, 52, b1 = 0, 93, b2 = 0, 66 и соответствующих tj (j = 0, 1, 2, 3). Это обусловлено некоррелированностью главных компонент. Здесь интересна параллель уравнений регрессии по исходным показателям (53.22), (53.23) и главным компонентам (53.41), (53.42). Уравнение (53.42) значимо, поскольку Fнабл = 194 > Fкр = 3, 01, найденного при α = 0, 05, v1 = 4, v2 = 16. Значимы и коэффициенты уравнения, так как tj > tкр. = 1, 746, соответствующего α = 0, 01, v = 16 для j = 0, 1, 2, 3. Коэффициент детерминации r Уравнение (53.42) характеризуется средней относительной ошибкой аппроксимации Уравнение регрессии на главных компонентах (53.42) обладает несколько лучшими аппроксимирующими свойствами по сравнению с регрессионной моделью (53.23) по исходным показателям: r
Кластерный анализ
В статистических исследованиях группировка первичных данных является основным приемом решения задачи классификации, а поэтому и основой всей дальнейшей работы с собранной информацией. Традиционно эта задача решается следующим образом. Из множества признаков, описывающих объект, отбирается один, наиболее информативный, с точки зрения исследователя, и производится группировка данных в соответствии со значениями этого признака. Если требуется провести классификацию по нескольким признакам, ранжированным между собой по степени важности, то сначала осуществляется классификация по первому признаку, затем каждый из полученных классов разбивается на подклассы по второму признаку и т.д. Подобным образом строится большинство комбинационных статистических группировок. В тех случаях, когда не представляется возможным упорядочить классификационные признаки, применяется наиболее простой метод многомерной группировки — создание интегрального показателя (индекса), функционально зависящего от исходных признаков, с последующей классификацией по этому показателю. Развитием этого подхода является вариант классификации по нескольким обобщающим показателям (главным компонентам), полученным с помощью методов факторного или компонентного анализа. При наличии нескольких признаков (исходных или обобщенных) задача классификации может быть решена методами кластерного анализа, которые отличаются от других методов многомерной классификации отсутствием обучающих выборок, т.е. априорной информации о распределении генеральной совокупности. Различия между схемами решения задачи по классификации во многом определяются тем, что понимают под понятиями «сходство» и «степень сходства». После того как сформулирована цель работы, естественно попытаться определить критерии качества, целевую функцию, значения которой позволят сопоставить различные схемы классификации. В экономических исследованиях целевая функция, как правило, должна минимизировать некоторый параметр, определенный на множестве объектов (например, целью классификации оборудования может явиться группировка, минимизирующая совокупность затрат времени и средств на ремонтные работы). В случаях когда формализовать цель задачи не удается, критерием качества классификации может служить возможность содержательной интерпретации найденных групп. Рассмотрим следующую задачу. Пусть исследуется совокупность п объектов, каждый из которых характеризуется k измеренными признаками. Требуется разбить эту совокупность на однородные в некотором смысле группы (классы). При этом практически отсутствует априорная информация о характере распределения k-мерного вектора Х внутри классов. Полученные в результате разбиения группы обычно называются кластерами* (таксонами**, образами), методы их нахождения — кластер-анализом (соответственно численной таксономией или распознаванием образов с самообучением). * Clаster (англ.) — группа элементов, характеризуемых каким-либо общимсвойством. **Тахоп (англ.) — систематизированная группа любой категории.
Необходимо с самого начала четко представлять, какая из двух задач классификации подлежит решению. Если решается обычная задача типизации, то совокупность наблюдений разбивают на сравнительно небольшое число областей группирования (например, интервальный вариационный ряд в случае одномерных наблюдений) так, чтобы элементы одной такой области находились друг от друга по возможности на небольшом расстоянии. Решение другой задачи заключается в определении естественного расслоения результатов наблюдений на четко выраженные кластеры, лежащие друг от друга на некотором расстоянии. Если первая задача типизации всегда имеет решение, то во втором случае может оказаться, что множество наблюдений не обнаруживает естественного расслоения на кластеры, т.е. образует один кластер. Хотя многие методы кластерного анализа довольно элементарны, основная часть работ, в которых они были предложены, относится к последнему десятилетию. Это объясняется тем, что эффективное решение задач поиска кластеров, требующее выполнения большого числа арифметических и логических операций, стало возможным только с возникновением и развитием вычислительной техники. Обычной формой представления исходных данных в задачах кластерного анализа служит матрица
каждая строка которой представляет результаты измерений k рассматриваемых признаков у одного из обследованных объектов. В конкретных ситуациях может представлять интерес как группировка объектов, так и группировка признаков. В тех случаях, когда разница между двумя этими задачами не существенна, например при описании некоторых алгоритмов, мы будем пользоваться только термином «объект», включая в это понятие и термин «признак». Матрица Х не является единственным способом представления данных в задачах кластерного анализа. Иногда исходная информация задана в виде квадратной матрицы
элемент rij которой определяет степень близости i-го объекта к j-му. Большинство алгоритмов кластерного анализа полностью исходит из матрицы расстояний (или близостей) либо требует вычисления отдельных ее элементов, поэтому если данные представлены в форме X, то первым этапом решения задачи поиска кластеров будет выбор способа вычисления расстояний, или близости, между объектами или признаками. Несколько проще решается вопрос об определении близости между признаками. Как правило, кластерный анализ признаков преследует те же цели, что и факторный анализ: выделение групп связанных между собой признаков, отражающих определенную сторону изучаемых объектов. Мерой близости в этом случае служат различные статистические коэффициенты связи. Популярное:
|
Последнее изменение этой страницы: 2017-03-03; Просмотров: 821; Нарушение авторского права страницы

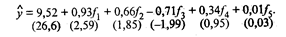 (53.41)
(53.41) = 0, 517, средняя относительная ошибка аппроксимации
= 0, 517, средняя относительная ошибка аппроксимации  = 10, 4%, остаточная дисперсия s2 = 1, 79 и Fнабл = 121. Ввиду того что Fнабл > Fкр =2, 85 при α = 0, 05, v1 = 6, v2 = 14, уравнение регрессии значимо и хотя бы один из коэффициентов регрессии — β 1, β 2, β 3, β 4 — не равен нулю.
= 10, 4%, остаточная дисперсия s2 = 1, 79 и Fнабл = 121. Ввиду того что Fнабл > Fкр =2, 85 при α = 0, 05, v1 = 6, v2 = 14, уравнение регрессии значимо и хотя бы один из коэффициентов регрессии — β 1, β 2, β 3, β 4 — не равен нулю.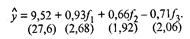 (53.42)
(53.42)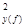 = 0, 486 > r
= 0, 486 > r 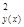 = 0, 469;
= 0, 469; 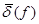 = 9, 99% <
= 9, 99% <