
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Операторы, используемые в Microsoft Excel
Для ввода формулы в ячейку необходимо выполнить следующие действия: 1) Выделить нужную ячейку. 2) Указать в качестве первого символа знак равенства; для этого ввести знак = или щелкнуть мышью по знаку = в строке формул. 3) Ввести часть формулы до той позиции, в которой должна указываться первая ссылка. 4) Задать ссылку на нужную ячейку или диапазон ячеек. При этом могут использоваться два способа: ссылка на эти элементы вводится посимвольно с клавиатуры или ввод осуществляется щелчком мыши на нужной ячейке (методом указания). Последний способ предпочтительней, поскольку ввод ссылок с клавиатуры требует больших временных затрат и сопряжен с ошибками. 5) Ввести оставшуюся часть формулы. Завершить ввод нажатием клавиши < Enter>. В ячейке при правильном вводе формулы появляется результат вычисления. Саму формулу можно увидеть теперь в строке формул.
Если формула введена с ошибками или вычисление результата по формуле невозможно, то в ячейке появляется сообщение об ошибке (Таблица 8.2).
Таблица 8.2 Сообщения об ошибках в формуле
Для поиска ошибок в формулах Excel предоставляет специальный режим, в котором на экране графически отображаются связи между влияющими и зависимыми ячейками. Для включения этого режима надо воспользоваться пунктом меню Вид/Панели инструментов/Настройка/Зависимости, и тогда можно визуально наблюдать, какие ячейки влияют на содержимое той или иной ячейки (выявить влияющие ячейки) и на содержимое каких ячеек она сама влияет (выявить зависимые ячейки).
Рис. 8.4. Пример использования ссылок
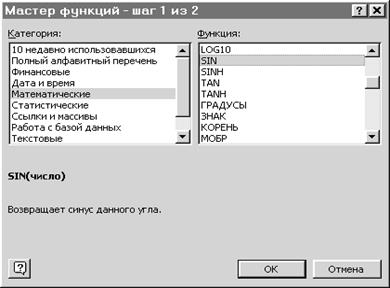
В примере на рис. 8.4 в ячейки A1: C2 введены числа, а в ячейке A3 записана формула =A1+A2, т.е. сумма элементов первого столбца, и в ячейке D1 – формула =A1+B1+C1, т.е. сумма элементов первой строки. Обе формулы имеют относительные ссылки. При вычислении по этим формулам в ячейках A3 и D1 будут отображены значения 79 и 56, соответственно. Если использовать режим заполнения, указав ячейку A3 и заполнив ячейки B3 и C3, то в них появятся формулы =B1+B2 и =C1+C2, т.е. суммы второго и третьего столбца соответственно. При копировании ячейки D1 в ячейку D2 в последней будет записана формула =A2+B2+C2, т.е. сумма второй строки, равная 75. Изменим ссылки в обеих исходных формулах. В ячейку A3 запишем формулу =$A$1+A2, а в ячейку D1 – формулу = A1+$B$1+C$1. При копировании первой формулы в ячейки B3 и C3 в них появятся записи =$A$1+B2 и =$A$1+C2, соответственно. При копировании второй формулы в ячейку D2 в последней появится запись = A2+$B$1+C$1. Так как в формулах указаны абсолютные ссылки (перед номером строки или именем столбца стоит знак $), то при копировании формулы из одной ячейки в другую такая ссылка в формуле не изменяется. Если надо найти сумму соседних ячеек, то можно воспользоваться кнопкой ∑ (автосуммирование) панели инструментов Стандартная. Для этого требуется выделить ячейки, которые надо сложить, вместе с ячейкой, в которой будет находиться результат суммирования, и нажать кнопку ∑. Excel содержит обширный список функций, по которым выполняются вычисления. Для вычисления значений функций используются аргументы. Аргументы функций записываются в скобках, причем задаваемые аргументы должны иметь допустимые для данного аргумента значения. Функция вводится в ячейку как часть формулы. Если функция стоит в самом начале формулы, то ей должен предшествовать знак =, как и во всякой другой формуле. Чтобы выполнить расчет, используя функцию, нужно предпринять следующие действия: 1) Выбрать меню Вставка/Функция или нажать кнопку fx панели инструментов Стандартная. 2) Выделить в левом окне нужную категорию, а в правом требуемую функцию и щелкнуть дважды по имени функции или нажать кнопку ОК (Рис. 8.5). 3) Указать аргументы.
Рис. 8.5. Окно, содержащее список функций
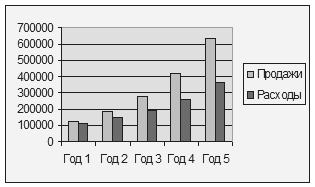
На первом шаге выбрана математическая функция SIN(), на втором шаге указывается аргумент функции. Данные, содержащиеся в таблице, можно отобразить графически в виде диаграммы. Построение диаграмм выполняется с помощью Мастера диаграмм, который можно вызвать кнопкой панели инструментов Стандартная или с помощью меню Вставка/Диаграмма. Диаграмма отображает зависимость значений, образующих ряды данных, от признаков, называемых категориями. Например, на любой диаграмме, которая показывает изменение величин во времени, категорией будет время. Ряды данных могут быть в строках или столбцах таблицы. Категории часто размещаются в первом столбце или в первой строке. Для примера приведена таблица 8.3. В ней ряды данных – Продажи, Расходы, категории данных – Годы. На рис. 8.6 показаны соответствующие диаграммы. Таблица 8.3 Ряды и категории данных
Рис. 8.6. Диаграммы в виде графиков и гистограмм
Рис. 8.7. Окно выбора типа и вида диаграммы
Построение диаграмм состоит из следующих шагов: 1) выделить диапазон, содержащий ряды данных с подписями – с именами строк или столбцов, 2) вызвать мастер диаграмм (с помощью кнопки на панели инструментов Стандартная), 3) выбрать тип и вид диаграммы (Рис. 8.7), нажать кнопку Далее, 4) во вкладке Диапазон данных (шаг 2 мастера диаграмм) уточнить (при необходимости) положение рядов данных, а во вкладке Ряд указать местоположение подписей оси Х – категорий, 5) ввести необходимые заголовки (название диаграммы, названия осей) и условные обозначения, если они необходимы, 6) разместить диаграмму на том же листе, где находится таблица или на отдельном листе. Форматирование элементов диаграммы выполняется следующим образом. Щелкнув правой кнопкой мыши на элементе диаграммы, надо выбрать команду Формат, а затем требуемую вкладку для форматирования диаграммы. 8.5. Сортировка, консолидация данных, сводные таблицы Сортировка данных в таблице выполняется по возрастанию или убыванию. Для того чтобы отсортировать строки таблицы по значениям в определенном столбце, надо выделить таблицу или ее фрагмент, подлежащий сортировке, затем, используя меню Данные/Сортировка, выбрать столбец, по которому требуется сортировка, и режим: по возрастанию или по убыванию. Если сортировка производится по значениям в первом числовом столбце, то можно воспользоваться кнопкой Сортировка по возрастанию или Сортировка по убыванию на панели инструментов Стандартная. Консолидация данных позволяет создать таблицу-сводку по одной или нескольким категориям данных, используя один или несколько блоков данных. При выполнении консолидации надо задать тип функции (например, СУММ или СРЗНАЧ), по которой будут вычисляться итоговые значения. Рассмотрим смысл консолидации на примере компьютерной фирмы, имеющей три филиала (Таблица 8.4). Надо построить таблицу, содержащую консолидированные данные по всем филиалам, т.е. суммарный объем продаж компьютеров, мониторов, процессоров и материнских плат. Для получения этой таблицы надо выполнить следующие действия: 1) Выделить ячейку, которая будет соответствовать левому верхнему углу таблицы консолидированных данных. В нашем примере пусть это будет ячейка A22. 2) Выбрать пункт меню Данные/Консолидация (Рис. 8.8). 3) В окне Консолидация указать функцию. 4) В строке Ссылка щелкнуть мышью по стрелке в правом углу и выделить первую исходную область, в примере – A6: E9 – она оконтурится мерцающим пунктиром. 5) Щелкнуть кнопку Добавить. 6) Повторить действия 4 – 5 для следующих диапазонов (A11: E14 и A16: E19). 7) Установить флажок Значения левого столбца и нажать кнопку OK (Рис. 8.8). Таблица 8.4 Получение таблицы, содержащей консолидированные данные
Рис. 8.8. Диалоговое окно, открывающееся при выборе пункта меню Данные/Консолидация Еще один эффективный способ обобщения табличных данных - построение сводных таблиц. Одна из особенностей этого способа состоит в том, что он применим только к однородным табличным данным. Так, таблица 8.4 уже сложна для мастера сводных таблиц – мешают подзаголовки с названиями филиалов. Поэтому преобразуем ее в таблицу 8.5.
Таблица 8.5 Исходные данные для построения сводной таблицы
Теперь для построения сводной таблицы необходимо выполнить следующую последовательность действий: 1) вызвать мастер сводных таблиц с помощью пункта меню Данные/Сводная таблица, указать источник данных (в списке или базе данных), нажать кнопку Далее; 2) указать диапазон, в котором находятся исходные данные (в нашем примере A3: F15); если ячейки выделены заранее, то программа определит диапазон по выделению; нажать кнопку Далее; 3) создать макет сводной таблицы, используя известные поля; в нашем примере надо переместить мышью кнопку поля Филиал в область Страница (Рис. 8.9), кнопку поля Наименование – в область Строка, а кнопки I, II, III, IV – в область Данные; нажать кнопку Далее; 4) указать ячейку, которая будет соответствовать левому верхнему углу таблицы, нажать кнопку Готово.
Рис. 8.9. Создание макета сводной таблицы
Сводная таблица, созданная для нашего примера (Таблица 8.6), в первой строке содержит поле со списком. Если список раскрыть, то из него можно выбрать конкретный филиал или все (филиалы) – в зависимости от выбора изменяется содержимое столбца Всего. Таблица 8.6 Пример сводной таблицы
На этом завершим рассмотрение табличного процессора Excel. Как и при описании текстового процессора Word (см. раздел 7), мы не ставили перед собой задачу проиллюстрировать абсолютно все возможности данного приложения. Для более полного знакомства с Excel мы рекомендуем проделать лабораторные и контрольные работы, приведенные в [ 6 ], а также познакомиться с расширенными возможностями Excel [1, 2]. Кроме консолидации данных и построения сводных таблиц, Excel предоставляет и другие возможности, позволяющие работать с электронными таблицами как с базой данных. При желании эти возможности можно изучить самостоятельно, пользуясь литературой [1, 2] и встроенной справкой. Но еще лучше воспользоваться более мощными средствами, имеющимися в системах управления базами данных (СУБД), которым посвящен следующий раздел.
Контрольные вопросы к разделу 8: назначение Excel; основные понятия: электронная таблица, ячейка таблицы, адрес ячейки, ссылка, блок ячеек, текущая (активная) ячейка, рабочая книга; как скопировать, переместить или переименовать лист рабочей книги; как изменять высоту строк, ширину столбцов, как удалять и вставлять строки и столбцы; как выделить ячейку, строку, столбец, блок ячеек; установка формата выделенных ячеек – вкладки Число, Выравнивание, Шрифт, Граница, Вид; копирование формата ячеек; кнопки панели инструментов Форматирование, их применение; выполнение расчетов по формулам: ввод формулы, операторы и функции, используемые в Excel, применение относительной и абсолютной адресации; автозаполнение; построение диаграмм: ряды и категории данных, этапы построения диаграммы, форматирование элементов диаграммы; сортировка, консолидация данных, сводные таблицы.
9. Системы управления базами данных. СУБД Access
9.1. Основные понятия База данных – это совокупность структурированных данных, относящихся к некоторой предметной области. Предметная область – это область конкретной практической деятельности. В зависимости от круга рассматриваемых во взаимосвязи объектов и, соответственно, круга решаемых задач предметная область может быть узкой или очень широкой. Она может охватывать объекты и задачи производственной технологии в отдельном цехе или отделе, некоторые сферы деятельности предприятия, например, экономику и финансы, а, возможно, и все предприятие. В крупных организациях обычно выделяют ряд предметных областей в рамках основных служб, в каждой из которых создаются свои базы данных для решения своих задач. Но обобщенные в той или иной мере данные поступают в интегрированную базу предприятия, концентрирующую информацию, требуемую для контроля служб и отделов, для подготовки общей отчетности организации и для управления ею. В этой небольшой книге мы, конечно, не будем рассматривать крупное предприятие, а ограничимся компактными примерами, поясняющими роль баз данных. Структурирование – это введение соглашений о способах представления данных. Это понятие близко к понятиям модель данных и формализация данных. В разделе 3 мы уже рассматривали понятие модели объекта – это формализованное описание существенных свойств объекта ограниченным набором параметров. Структуры данных - тоже объекты. Так, в реляционных базах данных, рассматриваемых далее, используются три структуры данных: таблица, запись, поле. И каждая из этих структур имеет свои свойства, описываемые параметрами. Таблица имеет имя и состоит из записей. Запись имеет номер в таблице и состоит из полей. У каждого поля есть имя, тип (текстовый, числовой и т.п.), длина в байтах. Поясним эти структуры на примере построения информационной модели конкретной предметной области. Пусть нас интересует проблема учета всех затрат предприятия, например, строящего фабрику. Затраты должны учитываться по объектам, по видам работ и по организациям-подрядчикам. В соответствии с нашими интересами построим таблицы:
Объекты [Код об, Объект], Работы [Код раб, Работа], Организации [Код орг, Организация, Индекс, Город, Адрес, Телефон, Факс, Эл почта] и собственно таблицу для учета затрат Затраты [Код затр, Затрата, Код об, Код раб, Код орг, Дата, Стоимость]. Каждая из этих таблиц имеет имя, выделенное полужирным курсивом, и состоит из записей - строк, состав которых (перечень полей) указан в квадратных скобках. Имена полей – это имена столбцов таблицы. Курсивом выделены имена ключевых полей. Значение ключевого поля (ключа) однозначно определяет запись в таблице. По возрастанию значений ключа СУБД сортирует записи в таблицах. Ключевые поля служат также для связывания таблиц. Например, таблица Затраты может содержать множество записей, в которых указан код одной и той же организации-подрядчика. Предположим, одна и та же организация проектировала и строила мост, подъездную дорогу, трансформаторную подстанцию и, возможно, другие объекты. При обработке записей таблицы Затраты может потребоваться факс этой организации – его легко найти в таблице Организации, которая должна содержать единственную запись с требуемым нам кодом организации в поле Код орг. Связь между этими таблицами называется связью «один ко многим» (1 ® ¥ ): ссылка на одну запись в таблице Организации содержится во многих записях таблицы Затраты. Если бы мы ввели еще одну таблицу – Банковские реквизиты, в которой для каждой организации-подрядчика указали бы ее код, название банка, номера счетов и другие данные, используемые при оформлении платежей, то связь между этой таблицей и таблицей Организации была бы связью «один к одному» (1 ® 1), т.к. в этих таблицах есть только по одной записи с одним и тем же значением ключевого поля Код орг. В некоторых ситуациях ключ может состоять из двух-трех полей и тогда он называется составным. Например, подразделение может идентифицироваться номером цеха и номером бригады в данном цехе, точка геофизических измерений может идентифицироваться номером профиля и номером точки на этом профиле и т.п. Для ключевого поля СУБД строит индекс – вспомогательную таблицу, содержащую для каждого значения ключа адрес записи в основной таблице. Поэтому, если требуется запись с определенным значением ключа, то она легко находится по индексу. Если же в таблицу вставляется новая запись, то сортировке подвергается только индекс, но не записи таблицы. Итак, в нашем примере база данных охватывает несколько взаимосвязанных таблиц «объекты-свойства». Такие базы данных называются реляционными. Это понятие (relation – отношение) было введено известным американским специалистом в области систем управления базами данных И.Ф.Коддом. В 1994 г. отмечалась 25 годовщина с того момента, как И.Ф.Кодд (тогда научный сотрудник корпорации IBM) предложил реляционную модель. Тем не менее первая коммерческая реляционная СУБД, названная Oracle [14], появилась только в 1979 г. Она была разработана небольшой компанией Silicon Valley. Сегодня это Oracle Corporation – крупнейший в мире поставщик реляционных СУБД и сопутствующих программных продуктов. Первой СУБД клиент/сервер стал выпущенный в 1985 г. Oracle 5. В настоящее время широкое распространение получили более поздние реляционные СУБД, созданные корпорациями Oracle, Sybase, Microsoft и некоторыми другими. Современные ведущие реляционные СУБД сочетают реляционную модель данных с технологией клиент/сервер и с объектно-ориентированным подходом к созданию программных средств. На ЭВМ третьего поколения имели место многочисленные попытки применения иерархических и сетевых СУБД. Они оказались слишком сложными для восприятия пользователями и, кроме того, в них были ограничены или полностью отсутствовали возможности динамического изменения структуры баз данных. Последнее ограничение в некоторой степени присуще и реляционным СУБД, но все-таки с помощью языка SQL (см. подраздел 9.4) и другими методами здесь не так уж трудно изменить состав записей в таблице или создать новую таблицу и связать ее с имеющимися в рамках действующей СУБД. Важнейшим достоинством концепции баз данных (в отличие, например, от обработки данных в автономных файлах) является введение набора стандартных структур, в которые, как в контейнеры, вкладываются данные. Планируя работу с данными в конкретной предметной области, после уяснения основных задач решают вопросы организации данных: как сгруппировать данные в таблицы, какие поля и каких типов, предусмотреть в каждой таблице, как связать таблицы друг с другом и т.п. Решение этого комплекса вопросов называют построением информационно-логической (инфологической) модели, которая отражает предметную область в виде совокупности информационных объектов и их структурных связей. Только после решения вопросов организации данных приступают к разработке приложений – многофункциональных программ, осуществляющих преобразования данных путем их извлечения из одних таблиц, проведения расчетов и размещения результатов в других таблицах базы данных. Такой подход, во-первых, гарантирует, что каждый новый фрагмент данных, полученный предприятием, окажется «на своем месте» - в конкретной таблице конкретной базы данных, а, во-вторых, отпадает необходимость в разработке огромного числа процедур обработки данных. Последнее объясняется тем, что типовые операции над содержимым структур данных (таблиц, записей, полей) уже запрограммированы и входят в состав СУБД – ведь системы управления базами данных как раз и предназначены для создания баз данных и последующего манипулирования этими данными. СУБД, работающую со структурами данных, можно сравнить с техническими средствами на современном транспорте – они работают с контейнерами, не зависимо от того, что в этих контейнерах перевозится в конкретном случае.
9.2. Нормализация отношений (таблиц) и обеспечение целостности данных в реляционной базе данных В терминологии реляционных баз данных таблицы называют отношениями – ведь, включая в записи таблицы определенные поля, мы устанавливаем отношения между информационными объектами. Поскольку одни и те же данные можно по-разному сгруппировать в таблицы, то требуются некоторые правила, оптимизирующие группировку полей - свойств объектов. Такие правила были сформулированы применительно к реляционным базам данных. Это правила нормализации отношений. Нормализация отношений – формальный аппарат ограничений на формирование отношений (таблиц), который позволяет устранить дублирование, обеспечивает непротиворечивость хранимых данных, уменьшает трудозатраты на их ввод и корректировку. И.Ф.Коддом выделены три нормальные формы отношений и предложены методы преобразования отношений к третьей, самой совершенной нормальной форме. Отношение считается нормализованным, или приведенным к первой нормальной форме, если все его атрибуты (свойства объектов, описываемые в полях записей) простые, т.е. далее неделимы. Отношение Организации (см. подраздел 9.1) можно считать приведенным к первой нормальной форме. Единственный его атрибут, который теоретически еще можно разделить на части, - это Адрес. Но практически этот атрибут уже не делим, так как улица и дом, где расположена каждая организация, нам не могут потребоваться в отдельности. А такие атрибуты, как Город, уже отделены от адреса. Так что, если нам потребуется какая-нибудь сводка по организациям-подрядчикам, расположенным в определенном городе, то мы легко сможем отобрать соответствующие записи. Отношение находится во второй нормальной форме, если оно приведено к первой нормальной форме, и его каждый неключевой атрибут функционально зависит от ключа. Функциональная зависимость от ключа означает, что в экземпляре информационного объекта (в записи таблицы) конкретному значению ключа соответствует определенное значение описательного атрибута. Так, в таблице Затраты нашего примера коду (например, номеру) каждой затраты соответствует ее название, код объекта, в который вложены средства, коды вида работ и организации-подрядчика, дата и сумма платежа. Перечисленные атрибуты функционально зависят от ключа Код затр. Если бы ключ был составным, то для приведения отношения ко второй нормальной форме потребовалась бы функционально полная зависимость атрибутов от ключа. Она заключается в том, что каждый неключевой атрибут функционально зависит от ключа, но не находится в функциональной зависимости ни от какой части составного ключа. Понятие третьей нормальной формы основывается на понятии нетранзитивной зависимости [4]. Транзитивная зависимость наблюдается, если один из атрибутов зависит от ключа, а другой – от этого атрибута. Например, если в таблицу Затраты включить не только код организации, но и город, в котором она расположена, то получится, что атрибут Код орг функционально зависит от ключа Код затр, а атрибут Город зависит, в свою очередь, от атрибута Код орг и, следовательно, транзитивно зависит от ключа. Отношение находится в третьей нормальной форме, если оно находится во второй нормальной форме, и каждый неключевой атрибут нетранзитивно зависит от первичного ключа. Если бы мы включили в записи таблицы Затраты не только код организации-подрядчика, но и ее атрибуты (название, адрес и др.), то отношение уже не находилось бы в третьей нормальной форме, а это резко осложнило бы работу с базой данных. Во-первых, во все записи таблицы Затраты, где в качестве подрядчика выступает эта организация, пришлось бы вводить не только ее код, но и длинные названия, дублируя их многократно. Во-вторых, в случае изменения адреса, факса или другой характеристики организации пришлось бы вносить коррективы не в единственную запись таблицы Организации, а во множество записей таблицы Затраты. Приведенный пример показывает, что казалось-бы теоретическое понятие нормализации отношений играет важную практическую роль, позволяя устранить дублирование данных, облегчить их ввод и корректировку в базе данных. Другое важное понятие – обеспечение целостности данных в базе данных. Этот термин подразумевает, что в СУБД должны иметься средства, не позволяющие нарушать корректность и полноту хранимой информации. Например, СУБД обычно содержат средства поддержания ссылочной целостности. Так, если мы попытаемся в запись таблицы Затраты ввести код объекта 777, а в таблице Объекты еще нет объекта с кодом 777, то СУБД должна воспрепятствовать нашему намерению, если, конечно, мы выбрали соответствующий режим ее работы. Кроме того, когда мы вводим новую запись, СУБД проверяет уникальность ее ключа, обеспечивая целостность таблицы. Наконец, СУБД проверяет целостность домена. Домен – это множество допустимых значений столбца. Так в столбец Код орг могут входить только целые числа. Если при вводе записи введем в поле Код орг хотя бы одну букву или действительное число, запись не будет включена в таблицу. Дальнейшее изложение ориентировано на изучение возможностей СУБД Access, но прежде приведем схему [4] обобщенной технологии работы с СУБД (Рис. 9.1).
9.3. Работа с СУБД Access Работу с СУБД Access рассмотрим на уже упоминавшемся примере учета затрат предприятия. Последовательность действий в основном будет соответствовать приведенной схеме (см. рис. 9.1). Сначала создадим пустую базу данных “Затраты”, а затем – пустые таблицы этой БД, т.е. структуру таблиц. Для этого откроем приложение Access, выберем пункт меню Файл/Создать, в открывшемся диалоговом окне подтвердим желание создать новую БД нажатием кнопки Ok. После этого откроется стандартное диалоговое окно Сохранить как (см. подраздел 2.3). В нем надо выбрать каталог для размещения новой базы данных и дать имя файлу, например, Затраты.mdb. Этот файл будет содержать описание структуры таблиц, сами таблицы, формы, запросы и отчеты, которые будут созданы в соответствии с нашей технологической схемой (см. рис. 9.1). На рис. 9.2 показано окно приложения Access. В этом окне после создания пустой базы данных “Затраты” появится окно базы данных с заголовком “Затраты: база данных”, только в этом окне еще не будет перечня таблиц и, конечно, в окне приложения Access еще не будут открыты окна таблиц для просмотра и корректировки наших четырех таблиц. На рисунке эти таблицы показаны заранее, чтобы читатель яснее представлял то, что еще предстоит создать.
Рис. 9.1. Схема обобщенной технологии работы с СУБД
Теперь, когда пустая база данных существует, создадим пустые таблицы, т.е. пока только определим их структуру – опишем каждое поле записи. Начинать надо со вспомогательных таблиц Объекты, Работы и Организации. Для создания таблицы Объекты в окне базы данных (Затраты: база данных)нажмем кнопку Таблицы (вверху), а затем кнопку Создать (справа). В открывшемся диалоговом окне выберем из списка Конструктор. После этого откроется диалоговое окно Объекты: таблица – на рис. 9.3 оно показано справа. В этом окне в графе Имя поля введем Код об, а в поле со списком (см. подраздел 2.2) Тип данных выберем Числовой. После этого в поле со списком Размер поля выберем Длинное целое. Затем, нажав на панели инструментов кнопку с изображением ключа, сделаем поле Код об ключевым. Теперь определим второе поле – поле Объект. В графу Имя поля введем его название, а в поле со списком Тип данных выберем Текстовый. Длина текстового поля по умолчанию равна 50 байтам, и это нас устраивает. После этого окно, в котором мы определяли поля таблицы Объекты, можно закрыть с помощью кнопки системного меню (в строке заголовка окна, справа). При закрытии этого окна появится диалоговое окно, в котором надо задать имя таблицы – “Объекты”. Теперь таблица создана, ее можно открыть с помощью кнопки Открыть в окне базы данных и ввести в нее записи (см. рис. 9.2). Для ввода данных надо “встать” в нужное поле с помощью щелчка мыши или с помощью клавиш перемещения курсора и вводить данные в это поле. После ввода значения нажимают клавишу < Enter> - этим завершается ввод данных в ячейку таблицы, и курсор перемещается в следующее поле записи или в первое поле очередной записи. Для перемещения курсора также можно пользоваться клавишами < Tab> и < Shift> +< Tab>. Кроме того, перемещаться по записям таблицы помогает навигатор – линейка с кнопками внизу каждой таб Рис. 9.2. Рабочее окно СУБД Access с открытыми таблицами БД «Затраты»
Популярное:
|
Последнее изменение этой страницы: 2017-03-03; Просмотров: 1570; Нарушение авторского права страницы




 Филиал
Филиал


 (Все)
(Все)

