|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
ОБРАБОТКА РЕЗУЛЬТАТОВ ЭКСПЕРИМЕНТАЛЬНОГО ИССЛЕДОВАНИЯ
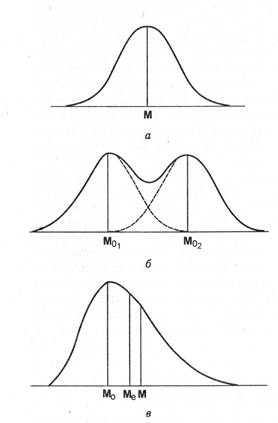
Итак, результаты экспериментальных исследований могут быть описаны с помощью определенных статистических показателей. Какие именно показатели могут быть применены в каждом отдельном случае, зависит от типа использованных измерительных шкал. Прежде чем будут описаны конкретные способы вычислений некоторых статистических показателей, необходимо определить значение ряда используемых при этом понятий. В первую очередь надо пояснить понятие распределения результатов. Можно себе представить, что большому числу испытуемых было предложено решить некоторое число, например 20, задач. Результаты оценивались в категориях «решил /не решил» задачи. Если задачи окажутся трудными для испытуемых, то лишь немногие из них правильно решат все 20 задач, притом что некоторые не решат ни одной задачи. Кроме того, можно ожидать, что большинство испытуемых какое-то количество задач решат правильно и какое-то количество - ошибочно. Первый шаг обработки первичных результатов состоит в подсчете того, сколько испытуемых правильно решили 1 задачу, сколько испытуемых - 2 задачи и т. д. И наконец, сколько лиц правильно решили все 20 задач. Величина, характеризующая количество людей, правильно решивших то или иное число задач, называется частотой (f). Совокупность полученных частот образует распределение первичных результатов, в нашем случае - распределение числа лиц правильно решивших то или иное количество задач. При графическом представлении результатов (рис. 1.1.1) и при достаточно большом количестве измерений, т.е. большой выборке (см. ниже), кривая распределения чаще всего имеет характерный колоколо-образный вид, Такое распределение первичных результатов получило название нормального, или Гауссова, распределения. Нормальное распределение от других возможных распределений отличается рядом простых свойств. Прежде всего оно однозначно определяется всего лишь двумя параметрами, а именно: средней арифметической величиной (М) и среднеквадратичным отклонением (s) или дисперсией (D). Мода (Мо) и медиана (Me) этого распределения совпадают со значением средней арифметической величины. Кроме того, форма нормального распределения симметрична относительно центра, т. е. местоположения М, Мо и Me.
Рис. 1.1.1. Виды распределения первичных результатов: а - нормальное распределение, б - бимодальное распределение, в - асимметричное распределение. М - средняя арифметическая величина: Мо1 и Мо2 - моды двух максимальных классов частот; Me - медиана: прерывистыми линиями показано, что бимодальное распределение может быть получено путем сдвига двух нормальных распределении друг относительно друга.
Иногда нормальное распределение подвергают операции нормирования, полагая среднеарифметическую величину равной нулю, а среднеквадратичное отклонение равным +1. Наряду с нормальным распределением результатов эксперимента часто встречаются асимметричные распределения и бимодальные (см. также рис. 1.1.1). Другое понятие, требующее пояснения, - это понятие выборки. Под выборкой понимается все множество значений изучаемой переменной величины, зарегистрированное в эксперименте. Объем выборки измерений принято обозначать символом N. Поясним сказанное примером. Допустим, что измерение скорости простой сенсомоторной реакции было осуществлено у 10 человек и реакцию каждого из них учитывали только по одному разу. Тогда N=10. Но если раздражитель был предъявлен испытуемым многократно, то объем выборки будет больше: например, при 15 предъявлениях N =150. Обработка результатов любого исследования начинается с представления их в удобной для обозрения форме. Представление результатов распределения дискретных признаков. Для начала рассмотрим один из примеров исследования; допустим, что был проведен опрос 1000 подростков одного возраста (500 юношей и 500 девушек) с целью определения предпочитаемого жанра читаемой ими литературы. Для этого каждому опрашиваемому было предложено выбрать один-единственный жанр из предъявляемого списка десяти жанров. Результаты опроса можно подсчитать и затем табулировать, т. е. представить в виде таблицы (табл. 1.1.1). При этом частоту выбора каждого из жанров (f) можно указать как раздельно для юношей и девушек, так и суммарно для тех и других, т. е. для всей выборки испытуемых. В последней строке таблицы необходимо указать сумму частот, что позволяет контролировать правильность подсчета. Результаты данного исследования, т. е. частоту выбора, часто представляют в виде процентов. Но необходимо помнить, что перевод частот в проценты не может быть признан целесообразным, если объем выборки невелик. Кроме того, надо помнить, что не рекомендуется приводить в таблице только процентные величины, т. е. необходимо указывать также первичные данные (в данном случае частоту f), на основе которых были рассчитаны проценты или хотя бы суммарные величины изучаемого признака. Для нашего примера величины частот выбора, пересчитанные в проценты, отражены в табл. 1.1.2.
Таблица 1.1.1 Частота выбора (f) подростками разных жанров литературных произведений
Таблица 1.1.2 Частота выбора (f), выраженная в процентах
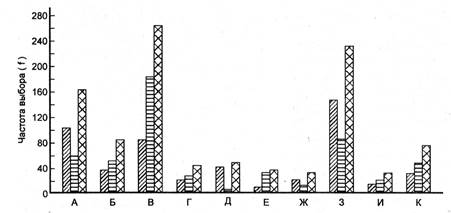
Рис. 1.1.2. Столбиковая диаграмма первичных результатов исследования выборки испытуемых (см. табл. 1.1.1). А-К - разные жанры предпочитаемой литературы; состав выборки: 1 - юноши, 2 - девушки, 3 - общее число испытуемых.
Наряду с табулированием часто используется прием графического изображения первичных результатов. При наличии результатов измерения, имеющих вид дискретного распределения (например, результаты опроса или тестирования с помощью ряда личностных методик), наиболее подходящим способом их графического отображения является столбиковая диаграмма (рис. 1.1.2). По оси абсцисс такого графика располагают дискретные значения независимой переменной (в нашем примере это предпочитаемые жанры литературного произведения, обозначаемые буквами алфавита), а по оси ординат - частоту случаев (у нас - частота выбора f) или процент случаев. Столбиковые диаграммы можно использовать для отображения исключительно величин шкал наименований. Представление результатов распределения непрерывных признаков. Для порядковых и интервальных величин, а также для величин шкалы отношений, т. е. величин непрерывных, принцип табулирования остается таким же, как при составлении таблиц для номинативных дискретных величин. Но при графическом отображении и в случае группировки первичных результатов в классы или разряды обнаруживаются существенные различия. Для начала в качестве примера приведем результаты исследования, иллюстрирующие характер непрерывности изучаемой переменной. В опыте, в котором участвовали 96 испытуемых, определялся цвет последовательного - как говорят физиологи - образа восприятия насыщенного красного цвета. С этой целью каждый испытуемый в течение одной минуты рассматривал окрашенный в красный цвет образец, а затем переносил взгляд на белый экран. Рядом с ним находится цветовой круг, на котором испытуемый должен выбрать тот цвет, который соответствует цвету возникшего у него последовательного образа. При этом испытуемый не называет цвет, а лишь его номер в цветовом круге. Цветовой круг нормирован таким образом, что соседние цвета в нем отличаются друг от друга на одинаково замечаемую величину. Следовательно, цветовой круг можно расценивать как интервальную шкалу. Наряду с этим цветовой круг характеризуется и еще одним свойством. В частности, можно себе представить, что между двумя соседними цветами, например между зеленовато-голубым и голубовато-зеленым, имеется еще множество не замечаемых человеческим глазом цветовых переходов. В этом именно смысле цветовой круг представляет собой пример непрерывной переменной. Фактически же всегда испытуемые выделяют конечное число цветовых оттенков и поэтому свой выбор останавливают на конкретном номере (или названии) цвета. В рассматриваемом эксперименте испытуемые определяли свой последовательный образ в диапазоне от № 16 - зеленовато-голубой цвет до № 23 - желтовато-зеленый. Полученные результаты возможно табулировать, что и было сделано в табл. 1.1.3. Как видно, в построении табл. 1.1.1 и 1.1.3 нет принципиального различия. Но различие характера первичных данных, отображенных в обеих таблицах, все же есть, и оно обнаруживается при их графическом изображении (см. рис. 1.1.2 и 1.1.3). В самом деле, рис. 1.1.3 представляет собой уже не столбиковую, а ступенчатую диаграмму, называемую гистограммой. Следует обратить внимание на то, что все участки (столбики) ступенчатой диаграммы расположены вплотную друг к другу (числовые значения переменной Х на оси абсцисс гистограммы пишут напротив центральной оси каждого участка).
Таблица 1.1.3 Популярное:
|
Последнее изменение этой страницы: 2017-03-08; Просмотров: 683; Нарушение авторского права страницы