
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Характеристика основных понятий статистики
Статистика – это, прежде всего, способ мышления; для ее применения, кроме здравого смысла, нужно знать основы математики. Без статистики выводы в психологических исследованиях были бы чисто интуитивные и не могли бы быть основой для интерпретации полученных данных. Существует 3 главных раздела статистики: 1. Описательная – позволяет описывать, подводить итоги распределения, вычислять «среднее» для этого распределения, его размах и дисперсию. 2. Индуктивная – это проверка того, можно ли результаты, полученные на данной выборке, перенести на всю популяцию, из которой взята эта выборка. 3. Измерение корреляции – позволяет узнать насколько связаны между собой две переменные, чтобы можно было предсказать возможные значения одной из них, если мы знает другую. Существует две разновидности статистических методов или тестов, позволяющих вычислять степень корреляции. Первая разновидность – это наиболее широко применяемые параметрические методы, в которых используются такие параметры, как среднее значение или дисперсии данных. Вторая – непараметрические методы, используемые тогда, когда выборка испытуемых очень мала или когда обрабатываются качественные показатели или данные. Эти методы считаются простыми в расчетах и применении. Одна из задач статистики – это анализ данных, полученных на части популяции с целью сделать вывод на популяцию в целом. Популяция – это необязательно какая-либо группа людей или естественное сообщество; этот термин относится ко всем существам или предметам, образующим изучаемую совокупность (атомы, студенты). Выборка – это небольшое количество элементов, отобранных так, чтобы она была репрезентативной, т.е. отражала популяцию в целом. Данные в статистике – это основные элементы, подлежащие анализу; данными могут быть какие-то количественные результаты, свойства, присущие членам популяции, т.е. это, может быть любая информация, которую можно классифицировать для обработки (распределить по общему признаку на классы или группы). Построение распределения – это разделение первичных данных, полученных на выборке, на классы или категории с целью получить упорядоченную картину для анализа. Существует 3 типа данных: 1. Количественные данные, получаемые при измерениях (данные о температуре, о размере) их можно распределить по шкале с равными интервалами. 2. Порядковые данные, соответствующие местам этих элементов в последовательности, полученной при их расположении в возрастающем порядке (1, 7, 10, 11...). 3. Качественные данные – это свойства элементов выборки или популяции, их нельзя измерить; их единственной количественной оценкой служит частота встречаемости (число лиц с голубыми глазами, сильных и слабых, утомленных и отдохнувших). Из всех этих типов данных только количественные можно анализировать с помощью параметрических методов, но для этого необходимо 3 условия: данные должны быть количественными, их число должно быть достаточным, но самое главное – их распределение должно быть нормальным, т.е. для него должна быть характерна симметричная кривая распределения. Во всех остальных случаях используется непараметрические методы. Описательная статистика Задачи описательной статистики таковы: - классификация данных, построение распределения их частот; - выявление центральных тенденций этого распределения, т.е. моды, медианы, среднего арифметического; - оценка разброса данных относительно средних. Для классификации данных сначала их располагают в возрастающем порядке, затем разделяют их на классы по величине, интервалы между величинами определяются тем, что хочет выявить исследователь в данном распределении. Наиболее часто используются такие параметры для описания распределения: с одной стороны, это мода, медиана и среднее арифметическое (средняя); с другой стороны, показателями разброса являются дисперсия и стандартное отклонение. Мода соответствует значению, которое встречается чаще других или находится в середине класса, обладающего наибольшей частотой (Мо). Медиана (Ме) соответствует значению центрального данного, которое может быть получено после того, как все данные будут расположены в возрастающем порядке (проранжированы). Если число данных п будет четное, то Ме равна среднему арифметическому между значениями, находящимися в ряду данных на месте п/2 или п/2 + 1. Среднее арифметическое (средняя) М равна частному от деления суммы всех данных на их число. Распределение считается нормальным, если все показатели центральной тенденции совпадают (Мо, Ме, М), что свидетельствует о симметричности распределения, а кривая распределения имеет колоколообразный вид. Диапазон распределения (размах результатов) равен разности между наибольшим и наименьшим значениями результатов. Среднее отклонение - это более точный показатель разброса, чем диапазон распределения. Для расчета среднего отклонения вычисляют среднюю разность между всеми значениями данных и средней арифметической, т.е. среднее отклонение равно
Показателем разброса, вычисляемым из среднего отклонения является дисперсия (варианса), равная среднему квадрату разностей между значениями всех данных и средней.
Для популяции для выборки
Наиболее употребительным показателем разброса данных служит отклонение, равное квадратному корню из вариансы (дисперсии).
Таким образом, стандартное отклонение равно квадратному корню из суммы квадратов всех отклонений от средней. Важное свойство стандартного отклонения (квадратичное отклонение от нормы) – то, что, независимо от его абсолютной величины в нормальном распределении, оно всегда соответствует одинаковому % данных, располагающихся по обе стороны от средней: 68% результатов располагаются в пределах одного стандартного отклонения в обе стороны от средней.
7 11 16 20 25 - С помощью этих показателей можно осуществить оценку различий между двумя распределениями, позволяющую проверить, насколько эти различия могут быть экстраполированы (перенесены) на всю популяцию, из которой взяты эти две выборки. Для этого применяют метод индуктивной статистики. Экстраполяция – распространение полученных из наблюдения выводов одной части явления на другую его часть или на целое явление. Индуктивная статистика Задача индуктивной статистики – оценить значимость тех различий, которые могут быть между двумя распределениями. Чтобы определить достоверность различий, следует выдвинуть гипотезу, которая потом проверяется статистическими методами (в статистике это перенос прошлой тенденции на будущий период). Нулевая гипотеза (Н0) – это предположение, по которому различие между двумя распределениями недостовено. Альтернативная гипотеза утверждает о выборках противоположное, т.е. достоверность различий между распределениями. Если данных достаточно, если эти данные количественные, если они подчиняются нормальному распределению, то для проверки гипотез используют параметрические критерии. Если же данных мало, если они порядковые или качественные, то для проверки гипотез используют непараметрические критерии. Из параметрических критериев наиболее эффективен t-критерий Стьюдента (t- тест Стьюдента). Этот критерий позволяет сравнить среднее и стандартное отклонение для 2-х распределений. Если эти показатели принадлежат независимым выборкам то используют формулу: t= М1 – среднее 1-й выборки М2 – среднее 2-й выборки N1 – число данных в 1-м распределении N2 - число данных во 2-м распределении S1 – стандартное отклонение по 1-ой выборке. S2 - стандартное отклонение по 2-ой выборке.
Для зависимых выборок используют формулу:
t= Независимые выборки – это выборки, взятые из двух разных групп испытуемых (т.е. из контрольной и экспериментальной). Зависимые выборки (сопряженные) – отражают результаты одной и той же группы испытуемых до и после воздействия на них (при «входе» в формирующий эксперимент и на «выходе» из формирующего эксперимента). Существует уровень достоверности, равный: р р Чтобы выяснить уровень достоверности, следует смотреть таблицу значений t-критерия: если полученное нами значение t меньше того, которое соответствует уровню достоверности по таблице, то разница между двумя выборками недостоверна, и они могут принадлежать к одной популяции, но чаще t-критерий применяют при проверке гипотезы о достоверности разницы средней между результатами экспериментальной и контрольной групп после воздействия. Если сравниваются не два, а несколько распределений, то пользуются таким параметрическим методом, как дисперсионный анализ. Из непараметрических методов наиболее популярный – следующий: критерий хи-квадрат ( К другим непараметрическим методам относится критерий рангов и t-критерий Вилкоксона. Какой бы критерий не использовался, его значение следует сравнить по таблице для уровня значимости 0, 05 с учетом числа степеней свободы (число данных). Если вычисленный результат будет выше указанной цифры, то Н0 гипотеза может быть отвернута и можно утверждать, что разница между распределениями достоверна. Корреляционный анализ Задача корреляционного анализа – установить возможную связь между двумя показателями, полученными на одной и той же выборке или на 2-х разных выборках. При этом устанавливается, приводит ли увеличение какого-либо показателя к увеличению или уменьшению другого показателя. Коэффициент корреляции колеблется в пределах от +1 (это полная положительная корреляция) до -1 (в случае полной отрицательной корреляции). Если этот коэффициент равен 0, то считается, что никакой корреляции между двумя рядами данных нет. Корреляция – связь между двумя или несколькими элементами выборок или между двумя выборками. Параметрическим показателем является коэффициент корреляции Пирсона (r). Для вычисления коэффициента корреляции по Пирсону сравнивают среднее и стандартное отклонение результатов двух измерений по формуле: r=
Из непараметрических показателей используют коэффициент корреляции рангов Спирмена. С его помощью выявляют связь между рангами, соответствующих величин в 2-х рядах измерений. Коэффициент корреляции может быть значимым для анализа. Это можно проверить по таблице пороговых значений р для уровня значимости р=0, 05. Популярное:
|
Последнее изменение этой страницы: 2017-03-08; Просмотров: 602; Нарушение авторского права страницы
 , где
, где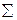 - сумма,
- сумма,  - абсолютное значение отдельного отклонения,
- абсолютное значение отдельного отклонения,  - число данных.
- число данных.
 =
= 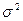 (S2)
(S2)





 +
+  , где
, где
 0, 05
0, 05 0, 01
0, 01 ), проверяющий являются ли две переменные независимыми друг от друга.
), проверяющий являются ли две переменные независимыми друг от друга.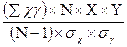 , где
, где - сумма произведений данных каждой пары
- сумма произведений данных каждой пары - средняя для данных X
- средняя для данных X - средняя для данных У
- средняя для данных У - стандартное отклонение для распределения х
- стандартное отклонение для распределения х - стандартное отклонение для распределения у
- стандартное отклонение для распределения у