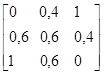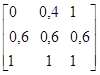|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Методы вывода и поиска решений в продукционных системах.Стр 1 из 7Следующая ⇒
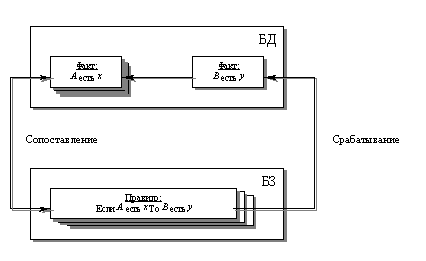
Методы вывода и поиска решений в продукционных системах. Методы вывода на основе прямой и обратной цепочек. При продукционном представлении область знаний представляется множеством продукционных правил если - тогда, а данные представляются множеством фактов о текущей ситуации. Механизм вывода сопоставляет каждое правило, хранящееся в БЗ с фактами, содержащимися в БД. Когда часть правила если (условие) подходит факту, правило срабатывает и его часть тогда (действие) исполняется. Срабатывающее правило может изменить множество фактов путем добавления нового факта, как показано на рис.6.1. Буквы в БД и БЗ используются для представления ситуаций и понятий.
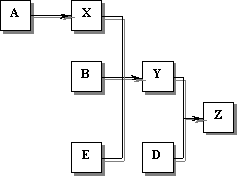
Рис.6.1. Цикл механизма вывода через процедуру «сопоставление – срабатывание» Сопоставление частей если правил с фактами создает цепочку вывода. Цепочка вывода показывает как ЭС применяет правила для получения заключения. Для иллюстрации метода вывода на основе цепочки, рассмотрим простой пример. Допустим, БД первоначально включает факты А, В, С, D и Е, а БЗ содержит только три правила: Правило 1. Y& D → Z Правило 2. X& B& E→ Y Правило 3. A→ X Цепочка вывода на рис. 6.2. показывает, как ЭС применяет правила для вывода факта Z.
Рис.6.2. Пример цепочки вывода. Сначала срабатывает Правило 3 для вывода нового факта Х изданного факта A. Тогда Правило 2 выполняется для вывода факта Y из первоначально фактов В и Е, а также уже известного факта Х. И наконец, Правило 1 применяет первоначально известный факт D и только что полученный факт Y для прихода и заключению Z. ЭС может отразить свою цепочку вывода для объяснения, как было достигнуто отдельное решение; это является основной частью ее объяснительных способностей. Механизм вывода должен решать, когда правила должны сработать. Существует два принципиальных способа, которыми правила могут быть выполнены. Один называется прямая цепочка (условно-выводимая), а другая обратная цепочка (целе-выводимая) [133]. Рассмотренный пример использует прямую цепочку вывода. Продукционные системы, в которых сначала анализируется антецедентная часть (условия), имеют так называемую условно-выводимую архитектуру. Примером экспертной системы такой архитектуры является META-DENDRAL. Альтернативным типом архитектуры, которая достаточно часто используется в экспертных системах, являются целе-выводимые (действие-выводимые или консеквент-выводимые) продукционные системы. Например, правило вида А& В& С→ D может быть интерпретировано, как «Логическая конъюнкция А, В и С влечет D» или «Чтобы доказать D, необходимо установить А, В, С». В последнем случае цель должна быть достигнута дедуктивным выводом. Для этого исследуются консеквенты правил для нахождения такого правила, которое позволило бы достичь цели. Когда такое правило найдено, проверяются на истинность все его условия. Если условия истинны, продукция активируется. В противном случае продолжается поиск подходящей продукции. Рассмотрим упрощенный пример продукционной системы с консеквент-выводимой архитектурой. Буквами здесь обозначены элементы БД и они считаются истинными, если содержатся в ней. БД: АF Правило 1: A& B& C→ D Правило 2: D& F→ G Правило 3: A& J→ G Правило 4: В→ С Правило 5: F→ B Правило 6: L→ J Правило 7: G→ H Предположим, цель состоит в том, чтобы вывести истинность Н. В первую очередь проверяется, находится ли Н в БД? Так как в данном случае это не так, то система пытается вывести истинность Н, используя правила, имеющие Н в правой части. Таким является правило 7. Теперь система пытается вывести истинность G, так как истинность последнего влечет за собой истинность Н. Снова проверяется БД: в БД нет G, следовательно, организуется полек правила, содержащего G в правой части. Таких правил несколько (два или три). В качестве стратегии «разрешения конфликта» будем считать, что правила упорядочены по приоритету, причем правилу с наименьшим номером соответствует больший приоритет. В данном случае выбирается правило 2, поэтому целью теперь становится вывести истинность D и F. Для этого достаточно показать, что А - истинно (так как находится в БД), В - истинно (согласно правилу 5), С - истинно (согласно правилу 4). Так как истинность D и F доказана, то из правила 2 следует истинность G, а из истинности G - следует истинность Н (правило 7). Таким образом цель достигнута. Элементы, истинность которых доказана, добавляются в БД. В данном случае это - элементы Н, G, D, С. В. Примерами целе-выводимой архитектуры является MYCIN.
Выводы на фреймах и в семантических сетях. Вывод на фреймах. Структура данных фрейма. Прежде, чем обсуждать вывод во фреймовой системе, рассмотрим подробнее структуру данных фрейма. Фреймовая система – это иерархическая структура, узлами, которой являются фреймы с определенной структурой данных. 1. Имя фрейма. Это идентификатор, присваиваемый фрейму. Фрейм должен иметь имя, единственное в данной фреймовой системе (уникальное имя). Каждый фрейм состоит из произвольного числа слотов, причем несколько из них обычно определяются самой системой для выполнения специфических функций, а остальные определяются пользоватлем. В их число входят слот, показывающий фрейм – родитель данного фрейма; слот указателей дочерних фреймов, который является списком указателей этих фреймов; слот для ввода имени пользователя, даты определения, даты изменения, такста комментария и другие слоты. Каждый слот, в свою очередь, также представлен определенной структурой данных. 2. Имя слота. Это идентификатор, присваиваемый слоту; слот должен иметь уникальное имя во фрейме, к которому он принадлежит. Обычно имя слота не имеет никакой смысловой нагрузки и является лишь идентификатором данного слота, но в некоторых случаях оно может иметь специфический смысл. К таким именам относятся: отношение; указатель прямого дочернего фрейма; дата определения фрейма; дата модификации фрейма и т.п. 3. Указатели наследования. Эти указатели касаются только фреймовых систем иерархического типа, основанных на отношениях иерархического типа, основанных на отношениях «абстрактное - конкретное». Они показывают, какую информацию об атрибутах слотов во фрейме верхнего уровня наследуют слоты с такими же именами во фрейме нижнего уровня. 4. Указатель типа данных (атрибутов слотов). Указывается, что слот имеет численное значение численное значение, либо служит указателем другого фрейма (т.е. показывает имя фрейма). К типам данных относятся указатель, целый, действительный, булевый, присоединенная процедура, текст, список, таблица, выражение и др. 5. Значение слота. Здесь вводится значение слота. Значение слота должно совпадать с указанным типом данных этого слота, кроме того, должно выполняться условие наследоваия. 6. Процедура – демон. Существуют следующие типы процедур – демонов: если-необходимо, если-изменено, если-добавлено, если-удалено. Демоном указывается процедура, автоматически запускаемая при выполнении некоторого условия. Т.е. когда изменяет свое значение атрибут в условной части если утверждения о состоянии демона. Процедуры – демоны активизируются при каждой попытке добавления или удаления данных из слота (по умолчанию). Демоны запускаются при обращении к соответствующему слоту. Например, демон если-необходимо запускается, если в момент обращения к слоту его значение не было установлено; если-добавлено запускается при подстановке в слот значения; если-удалено запускается при стирании значения слота. Кроме того, демон является разновидностью присоединенной процедуры. 7. Присоединенная процедура (процедура – слуга). В качестве значения слота можно использовать программу процедурного типа, называемую служебной (в языке LISP) и методом (в языке Smalltalk). В данном случае присоединенная процедура запускается по сообщению, переданному из другого фрейма, или при выполнении условий, определенных пользователем при создании фрейма. Когда мы говорим, что в моделях представления знаний фреймами объединяются процедурные и декларативные знания, то считаем и присоединенные процедуры процедурными значениями. Кроме того, в языке представления знаний фреймами отсутствует специальный механизм управления выводом, поэтому пользователь должен реализовать данный механизм с помощью присоединенной процедуры. Вывод во фреймовой системе. В рамках фреймового подхода предполагается, что знания в системе представляются в виде отдельных кластеров знаний, или подструктур, содержащих сведения о стереотипах (т.е. о некоторых общих характеристиках данного класса объектов или ситуаций. Согласно данному предположению понимание ситуации для системы означает поиск в перечне накопленных структур такой, которая наилучшим способом описывала бы рассматриваемую ситуацию. При этом слоты заполняются некоторой информацией и заполненный фрейм проверяется на адекватность данной ситуации. В случае несовпадения ищется новый фрейм и процесс продолжается. Таким образом, можно выделить три основных процесса, происходящих во фреймовых системах: 1. Создание экземпляра фрейма. Для создания экземпляра фрейма необходимо найти подходящий фрейм и заполнить его слоты информацией, описывающей специфику рассматриваемой ситуации. Для того чтобы заполнить слоты используется специальная информация о том, как найти потенциальные «заполнители» слотов. Эта информация часто хранится в процедурной форме. 2. Активация фреймов. В том случае, когда фрейм считается подходящим для описания данной ситуации, осуществляется его активация глобальным процессом. Если обнаруживается слишком много отличий содержимого фреймов от специфических особенностей рассматриваемой ситуации или они носят достаточно серьезный характер, организуется поиск другого, более подходящего фрейма. При этом «отвергнутый» фрейм может содержать указания на то, какие именно фреймы следует исследовать вместо данного (например, более общие или наоборот, более специализированные). Часть данных, используемых для заполнения слотов «отвергнутого» фрейма, может быть использована при рассмотрении новых кандидатов. 3. Организация вывода, заключающаяся в последовательном поиске « активации в сети фреймов до нахождения наиболее соответствующего и построения на его основе экземпляра фрейма. В [52] Т. Виноград предложил объединить во фреймах преимущества декларативного и процедурного представления. Суть его предложения состоит в том, что знания, касающиеся функций непосредственного представления их с помощью фреймов, должны храниться в декларативной форме, а знания об использовании фреймов — в процедурной. В частности, процедуры могут хранить знания, позволяющие давать ответ на следующие вопросы: 1. Когда активировать фрейм? Подобно «демонам» фреймы могут активировать сами себя в случае, если распознана соответствующая ситуация. 2. В каком случае считать, что данный фрейм неадекватен ситуации и что в этом случае делать? Фрейм мог бы, например, автоматически передать управление другому фрейму или деактивировать себя. 3. Когда осуществлять заполнение слотов — в момент вызова или позднее, по мере необходимости? Реализация этих функций может быть возложена на присоединенные процедуры. Процедуры могут также реализовывать эвристики, направленные на поиск необходимой для заполнения слотов информации. Неопределенность. Одной из общих характеристик к информации, доступной ЛПР, является ее несовершенство. Информация может быть неполной, противоречивой, неопределенной, ненадежной, нечеткой, носить случайный характер или может характеризоваться различными комбинациями этих описаний. Другими словами, информация часто является не вполне подходящей для решения задачи. Однако эксперт справляется с этими недостатками и обычно может делать верные суждения и принимать правильные решения. Интеллектуальная СПР также должна быть в состоянии справляться с неопределенностью и приходить к обоснованным выводам. В основном определяют четыре источника неопределенных знаний в интеллектуальных СПР: неизвестные данные, неточный язык, неявное смысловое содержание и трудности, связанные с сочетанием взглядов различных экспертов. Хотя неопределенность широко распространена в реальном мире, ее обработка в практических системах ИИ является весьма ограниченной. Неопределенность является серьезной проблемой. Попытки избежать ее учета и реализации возможностей работы с ней не может быть лучшей стратегией при разработке интеллектуальных СПР. Поэтому необходимо улучшать методы работы с неопределенностью. Интеллектуальные СПР и ЭС должны быть в состоянии управлять неопределенностью, т.к. любая предметная область реального мира содержит неточные знания и нужно справляться с неполными, противоречивыми или даже отсутствующими данными. Были разработаны различные методы для работы с неопределенностью в интеллектуальных и экспертных системах. Мы рассмотрим наиболее известные подходы к управлению неопределенностью: Байесовское вероятностное рассуждение и его расширения, Теорию уверенности, нечеткую логику.
Вероятностный вывод. Вероятностный подход. Случайная (или вероятностная) неопределенность может быть связана со случайностью событий, например, экономических ситуаций, состояний объекта, случайным характером отказов оборудования и другими факторами. При проектировании интеллектуальных СПР и организации работы с БЗ уровень достоверности и надежность многих знаний, фактов, событий и данных бывает различным. Для формализации рассуждений в условиях стохастической неопределенности используется теория вероятностей и статические решения. При реализации рассуждений с учетом неопределенности для вычисления вероятности некоторой гипотезы для варианта решения возможно применение байесовского подхода. Рассмотрим основные положения байесовского метода и правило Байеса. Пусть А есть событие в реальной действительности, а В – другое событие. Предположим, что события А и В не являются взаимно исключающими, но происходят условно при проявлении другого. Вероятность того, что событие А произойдет, если произойдет событие В, называется условной вероятностью. Условная вероятность математически обозначается как Р(А|B), в которой вертикальная черта изображает «имело место», а полное выражение вероятности интерпретируется как «Условная вероятность того, что произойдет событие А при условии, что имело место событие В». p(А|B)= Количество возможных совместный проявлений А и В, или вероятность того, что А и В произойдут совместно, называется совместной вероятностью А и В. Математически это представляется Р(АÇ В). Количество способов возможного проявления В является вероятностью В, Р(В), и тогда
Так же, условная вероятность того, что произойдет событие В при условии, что имело место событие А определяется
Отсюда, p(ВÇ А) =p(В|А)´ p(А) (6.4) Совместная вероятность является коммутативной, таким образом p(АÇ В)= p(ВÇ А) Следовательно p(АÇ В) =p(В|А)´ Р(А) (6.5) Подстановка (6.5) в (6.2) приводит к следующему уравнению:
где p(А|В) – условная вероятность того, что произойдет событие А при условии, что имело место событие В; p(В|А) – условная вероятность того, что произойдет событие В при условии, что имело место событие А; p(А) - вероятность того, что произойдет событие А; p(В) - вероятность того, что произойдет событие В. Уравнение (6.6) известно как правило (или формула) Байеса, которое названо именем Томаса Байеса, британского математика XVIII века, который предложил это правило. Понятие условной вероятности предлагается, когда считается, что событие А было зависимым от события В. Этот принцип может быть расширен на случай, когда событие А зависит от некоторого числа несовместимых событий В1, В2, …, Вn. Следующее множество уравнений может быть выведено из (6.2): p(АÇ В1) =p(А|В1)´ p(В1) p(АÇ В2) =p(А|В2)´ p(В2) ... p(АÇ Вn) =p(А|Вn)´ p(Вn) Или после объединения.
Если (6.7) просуммировано по всему полному перечню событий Bi, мы получаем
Это приводит к следующему уравнению условной вероятности, т.е. Р(А) выражается с помощью формулы полной вероятности:
Если проявление события А зависит только от двух взаимно исключающих событий, например В и НЕ В, тогда (6.9) будет выглядеть так: p(А)=p(А|B)´ p(B)+p(A\Ø B)´ p(Ø B) (6.10) Где Ø - логическое НЕ. Также
p(В)=p(В|А)´ p(А)+p(В\Ø А)´ p(Ø А) (6.11) Подставим теперь (6.11) в формулу Байеса (6.6), что приводит к
Уравнение (6.12) обеспечивает основу использования теории вероятности для управления неопределенностью в интеллектуальных системах. Байесовский вывод. Используя уравнение (6.12) мы можем теперь от теории вероятностей обратить наше внимание вновь к интеллектуальным системам [115]. Допустим все правила в БЗ представлены в следующей форме: Если Н истинно Тогда С истинно {с вероятностью р}. Это правило подразумевает, что если событие Н происходит, тогда вероятность, что событие С произойдет р. Что будет, если событие С произошло, но мы не знаем, произошло ли событие Н? Рассмотрим возможность вычисления вероятности того, что событие Н также произошло. Уравнение (6.12) позволяет нам это сделать. Мы просто используем Н и С вместо А и В. В интеллектуальных системах Н обычно обозначает гипотезы, а С – свидетельства в поддержку этих гипотез. Таким образом, уравнение (6.12), выраженное в терминах гипотез и свидетельств, выглядит так
p(Н) – априорная (безусловная) вероятность того, что гипотеза Н является истинной; p(С|Н) – вероятность того, что гипотеза Н является истинной, будет результатом свидетельства С; p(Ø Н) - априорная (безусловная) вероятность того, что гипотеза Н является ложной; p(С|Ø Н) – вероятность нахождения свидетельства С даже когда гипотеза Н ложна. Уравнение (6.13) предполагает, что вероятность гипотезы Н, p(Н) должна быть определена перед тем, как проверены какие-либо свидетельства. В интеллектуальных СПР вероятности требуются для решения задачи, которые ставят эксперты. Эксперт определяет априорные вероятности для возможной гипотезы p(Н) и p(Ø Н), а также условные вероятности для наблюдаемого свидетельства С, если гипотеза Н истинна, p(С|Н), и если гипотеза Н ложна, p(С|Ø Н). Пользователи обеспечивают информацию о наблюдаемом свидетельстве и интеллектуальная система вычисляет p(С|Н) для гипотезы Н в свете представленного пользователем свидетельства С. Вероятность p(С|Н) называется апостериорной вероятностью гипотезы Н при наблюдаемом свидетельстве С. Рассмотрим ситуации, когда эксперт, основываясь на простом свидетельстве С, не может выбрать простую гипотезу, но скорее обеспечивает многочисленные гипотезы Н1, Н2, …, Нт. Или когда имеются многочисленные свидетельства С1, С2, …, Сn и эксперт также выдает множество гипотез. Мы можем обобщить уравнение (6.13) принимая во внимание и многочисленные гипотезы Н1, Н2, …, Нт и многочисленные свидетельства С1, С2, …, Сn. Но гипотезы, так же как и свидетельства должны быть взаимно исключающими. Для простого свидетельства С и многочисленных гипотез Н1, Н2, …, Нт следует:
Для многочисленных свидетельств С1, С2, …, Сn и многочисленных гипотез Н1, Н2, …, Нт следует:
Применение уравнения (6.15) требует получения условных вероятностей всех возможных комбинаций свидетельств для всех гипотез. Это требование ложится огромным грузом на эксперта и делает его задачу практически невыполнимой. Поэтому в интеллектуальных СПР и ЭС, тонкости совместного влияния многочисленных свидетельств должны не учитываться, а допускаться условная независимость между различными свидетельствами. Следовательно, вместо неосуществимого уравнения (6.15) мы получаем
Для того, чтобы прояснить, каким образом интеллектуальная система вычисляет все апостериорные вероятности и в итоге ранжирует потенциально истинную гипотезу, рассмотрим простой пример. Предположим, что эксперт, имея три условно независимых свидетельства С1, С2 и С3, создает три взаимно исключающие гипотезы Н1, Н2 и Н3 и обеспечивает априорные вероятности для этих гипотез – p(Н1), p(Н2) и p(Н3) соответственно. Эксперт также определяет условные вероятности каждого отмеченного свидетельства для всех возможных гипотез. В Таблице 6.1. показаны априорные и условные вероятности, обеспеченные экспертом. Таблица 6.1. Априорные и условные вероятности.
Допустим, что мы сначала наблюдаем свидетельство С3. Интеллектуальная система вычисляет апостериорные вероятности для всех гипотез по уравнению (6.14):
Таким образом
Как можно видеть, после того, как наблюдается свидетельства С3, доверие гипотезе Н2 и становится равным доверию гипотезе Н1. Доверие гипотезе Н3 также возрастает и даже приблизительно достигает доверию гипотезам Н1 и Н2. Предположим теперь, что мы наблюдаем свидетельство С1. Апостериорные вероятности рассчитываются по уравнению (6.16):
Таким образом
Гипотеза Н2 теперь рассматривается как наиболее вероятная, т.к. доверие гипотезе резко уменьшается. После наблюдения свидетельства С2 интеллектуальная СПР также вычисляет последние апостериорные вероятности для всех гипотез:
Таким образом
Хотя первоначальное ранжирование, предложенное экспертом было Н1, Н2 и Н3, только гипотезы Н1 и Н3 остались для рассмотрения после всех свидетельств (С1, С2 и С3), которые наблюдались. Гипотеза Н2 теперь может быть полностью исключена. Заметим, что гипотеза Н3 теперь рассматривается как более предпочтительная, чем гипотеза Н1. При применении методов на базе байесовской логики возникают трудности с получением большого числа данных, необходимых для определения условных вероятностей. На практике делается предположение о независимости наблюдений, что видимо влияет на строгость статической модели. Подобные допущения присутствуют в методе на базе байесовского подхода, предложенного в [85]. Дуда, Харт и Нильсон видоизменили формулы Байеса для выводов в инженерии знаний и предположили метод выводов, названный субъектным байесовским методом. Основные цели этого метода были успешно реализованы ими в экспертной системе PROSPECTOR [84]. Приближенные рассуждения. В классической теории исчисления высказываний выражение «Если А, Тогда В», где А и В – пропозициональные переменные (пропозициональная переменная – это переменная для предложений, которые рассматриваются лишь с точки зрения их истинности или ложности), записывается как А®В, где импликация (®) рассматривается как связка, смысл которой определяется таблицей истинности. Таким образом А®Вº Ø АÚ В (6.17) В том смысле, что А®В (А влечет В) и Ø АÚ В (не А или В) имеют идентичные таблицы истинности. Более важным в нашем случае является неопределенное высказывание «Если А, Тогда В», коротко А®В, в котором А (антецедент) и В (консеквент) – нечеткие множества, а не пропозициональные переменные («пропозиция» означает предложение, выражение, высказывание). Типичные примеры высказываний: Если «большой», Тогда «малый» Если «скользкий», Тогда «опасный; » Они являются сокращениями предложений: Если х-«большой», Тогда у-«малый»; Если дорога «скользкая», Тогда езда «опасна». В сущности предложения этого вида описывают отношения между двумя неопределенными переменными. Это означает что неопределенное высказывание следует скорее определить как нечеткое отношение в смысле (5.25), а не как связку в смысле (6.17). Здесь целесообразно определить сначала декартово произведение двух нечетких множеств. Пусть А-нечеткое подмножество области рассуждений U и пусть В- нечеткое подмножество другой области рассуждений V. Тогда декартово произведение А и В, обозначаемое А´ В, определяется следующим образом
где U´ V означает декартово произведение множеств U и V, т.е.
Заметим, что когда А и В – не нечеткие, (6.18) преобразовывается в обычное определение декартова произведения множеств. Иными словами, (6.18) означает, что А´ В нечеткое множество упорядоченных пар (u, v), Пример 6.1. Пусть U=1+2 (6.19) V=1+2+3 (6.20) A=1/1+0, 8/2 (6.21) B=0, 6/1+0, 9/2+1/3 (6.22) Тогда А´ В=0, 6/(1, 1)+0, 9/(1, 2)+1/(1, 3)+0, 6/(2, 1)+0, 8/(2, 2)+0, 8/(2, 3) (6.23) Отношение, определенное в (6.17) можно представить матрицей отношения
Смысл нечеткого высказывания вида «Если А, Тогда В» становится ясен, если рассматривать его как специальный случай условного высказывания «Если А, Тогда В, Иначе С», где А, В и С – нечеткие подмножества, возможно, различных областей U и V, соответственно. В терминах декартова произведения последнее предложение определяется так: Если А, Тогда В, Иначе С Где + означает объединение нечетких множеств А´ В и (Ø А´ С). Чтобы обобщить понятие материальной импликации на нечеткие множества, предположим, что U и V – два возможно различных универсальных множества, а А, В и С – нечеткие подмножества множеств U, V и V соответственно. Сначала определим смысл высказывания Если А, Тогда В, Иначе С, и затем определим Если А, Тогда В как частный случай высказывания Если А, Тогда В, Иначе С. Определение. Высказывание Если А, Тогда В, Иначе С есть бинарное нечеткое отношение в U´ V, определяемое следующим образом: Если А, Тогда В, Иначе С=А´ В+Ø А´ С (6.26) То есть, если А, В и С – унарные нечеткие отношения в U, V и V, тогда Если А, Тогда В, Иначе С – бинарное нечеткое отношение в U´ V, которое является объединением декартова произведения А и В (см.(5.23)) и декартова произведения отрицания А и С. Далее высказывание Если А, Тогда В можно рассматривать как частный случай высказывания Если А, Тогда В, Иначе С при допущении, что С – полное множество V. Т.о. Если А, Тогда В В сущности это равнозначно интерпретации высказывания Если А, Тогда В высказыванием Если А, Тогда В, Иначе безразлично. Пример 6.2. Иллюстрация (6.26) и (6.27) Предположим, что U=V=1+2+3 А=малый=1/1+0, 4/2 В=большой=0, 4/2+1/3 С=не большой=1/1+0, 6/2 Тогда Если А, Тогда В, Иначе С=(1/1+0, 4/2)´ ( 0, 4/2+1/3)+(0, 6/2+1/3)´ (1/1+0, 6/2)=0, 4/(1, 2)+1/(1, 3)+0, 6/(2, 1)+0, 6/(2, 2)+0, 4/(2, 3)+1/(3, 1)+0, 6/(3, 2) Что можно представить в виде матрицы отношения Если А, Тогда В, Иначе С= Аналогично Если А, Тогда В=(1/1+0, 4/2)´ (0, 4/2+1/3)+(0, 6/2+1/3)´ (1/1+1/2+1/3) =0, 4/(1, 2)+1/(1, 3)+0, 6/(2, 1)+0, 6/(2, 2)+0, 6/(2, 3)+1/(3, 1)+1/(3, 2)+1/(3, 3) Или эквивалентно Если А, Тогда В= Вывод в нейронных сетях. Сеть Хопфилда. Хопфилд использовал функцию энергии как инструмент для построения рекуррентных сетей и для понимания их динамики [101]. Формализация Хопфилда сделала ясным принцип хранения информации как динамически устойчивых аттракторов и популяризовала использование рекуррентных сетей для ассоциативной памяти и для решения комбинаторных задач оптимизации. Динамическое изменение состояний сети может быть выполнено по крайней мере двумя способами: синхронно и асинхронно. В первом случае все элементы модифицируются одновременно на каждом временном шаге, во втором - в каждый момент времени выбирается и подвергается обработке один элемент. Этот элемент может выбираться случайно. Главное свойство энергетической функции состоит в том, что в процессе эволюции состояний сети согласно уравнению она уменьшается и достигает локального минимума (аттрактора), в котором она сохраняет постоянную энергию. Ассоциативная память Если хранимые в сети образцы являются аттракторами, она может использоваться как ассоциативная память. Любой пример, находящийся в области притяжения хранимого образца, может быть использован как указатель для его восстановления. Ассоциативная память обычно работает в двух режимах: хранения и восстановления. В режиме хранения веса связей в сети определяются так, чтобы аттракторы запомнили набор p n-мерных образцов {x1, x2,..., xp}, которые должны быть сохранены. Во втором режиме входной пример используется как начальное состояние сети, и далее сеть эволюционирует согласно своей динамике. Выходной образец устанавливается, когда сеть достигает равновесия. Сколько примеров могут быть сохранены в сети с n бинарными элементами? Другими словами, какова емкость памяти сети? Она конечна, так как сеть с n бинарными элементами имеет максимально 2n различных состояний, и не все из них являются аттракторами. Более того, не все аттракторы могут хранить полезные образцы. Ложные аттракторы могут также хранить образцы, но они отличаются от примеров обучающей выборки. Минимизация энергии. Сеть Хопфилда эволюционирует в направлении уменьшения своей энергии. Это позволяет решать комбинаторные задачи оптимизации, если они могут быть сформулированы как задачи минимизации энергии. В частности, подобным способом может быть сформулирована задача коммивояжера. Некоторые другие обучающие алгоритмы из таблицы 6.3 описаны в следующих работах: Adaline и Madaline [109], линейный дискриминантный анализ [104], проекции Саммона [104], анализ главных компонентов [99].
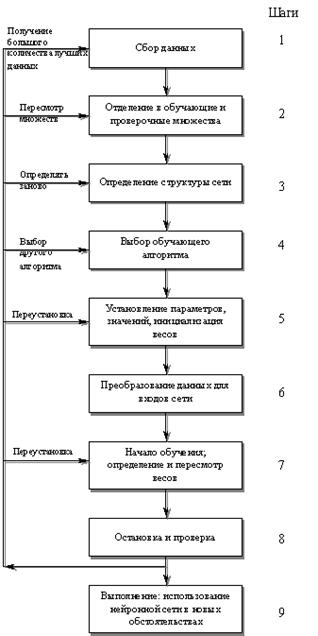
Процесс развития ИНС. Хотя процесс ИНС похож на методологии структурного проектирования традиционных компьютерных ИС, некоторые шаги присущи только приложениям нейронных сетей или имеют дополнительные факторы. В процессе, описанном ниже, мы допускаем, что предварительные шаги развития системы, такие как определение информационных потребностей и проведение анализа реализуемости проекта полностью закончены. Такие шаги являются общими для любой информационной системы. Как показано на рис. 6.8., процесс развития приложения ИНС имеет девять шагов. На шаге 1 собираются данные, которые должны использоваться для обучения и проверки сети. Важно принимать во внимание, чтобы поставленная задача была доступна для получения решения ИНС и чтобы для этого существовали и могли быть получены адекватные данные. На шаге 2 должны быть установлены обучающие данные и должен быть создан план для проверки выполнения сети. На шагах 3-4 выбираются архитектура сети и обучающий метод. Наличие специальных инструментальных средств развития ИНС может определить тип нейронной сети, которая должна быть построена. Важными соображениями являются специальное количество нейронов и число уровней. Существующие модели нейронных сетей имеют параметры, которые настраивают сеть на желаемый уровень исполнения. Частью процесса на шаге 5 является инициализация весов и параметров сети, которая также следует после получения отклика об исполнении. Часто первоначальные значения важны для определения эффективности и продолжительности обучения. Следующая процедура на шаге 6 преобразует используемые данные в тип и формат, требуемые нейронной сетью. Это может означать использование программ для предварительной обработки данных. Хранение и манипулирование данными должно быть организовано для удобного и эффективного переобучения нейронной сети, когда это необходимо. Также способ представления и организации используемых данных часто определяет эффективность и, возможно, точность результатов, получаемы ИНС. На шагах7-8 обучение и проверка проводятся как интервальный процесс представления входных и желаемых выходных данных в сеть. Нейронная сеть вычисляет фактические выходы и регулирует веса до тех пор, пока фактические выходы будут подходить желаемому состоянию. Желаемые выходы и их связи со входными данными получают из исторических данных (части данных, собранных на шаге 1). На шаге 9 процесса получают устойчивое множество весов. Теперь сеть может воспроизводить желаемые выходы изданных входов также как на обучаемом множестве. Нейронная сеть готова для использования как самостоятельная система или как часть другой программной системы.
Рис.6.8. Последовательность процесса развития и настройки искусственной нейронной сети. Популярное:
|
Последнее изменение этой страницы: 2017-03-11; Просмотров: 2224; Нарушение авторского права страницы
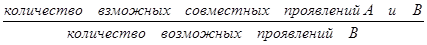 (6.1)
(6.1)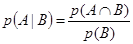 (6.2)
(6.2)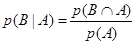 (6.3)
(6.3)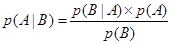 (6.6)
(6.6)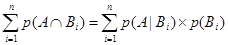 (6.7)
(6.7)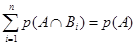 (6.8)
(6.8)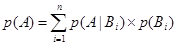 (6.9)
(6.9)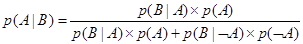 (6.12)
(6.12)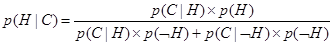 (6.13)
(6.13)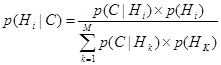 (6.14)
(6.14)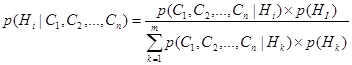 (6.15)
(6.15)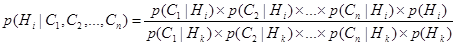 (6.16)
(6.16)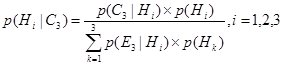
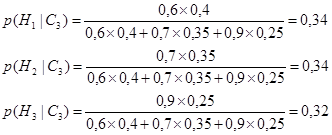
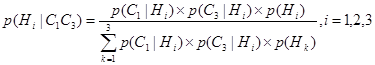
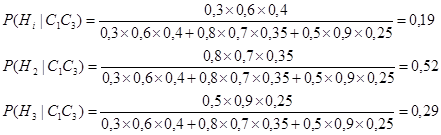
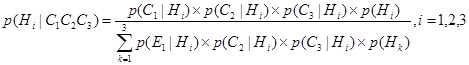
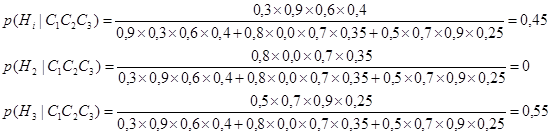
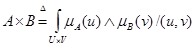 (6.18)
(6.18)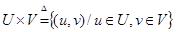
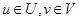 , со степенью принадлежности (u, v) к (А´ В), задаваемой формулой
, со степенью принадлежности (u, v) к (А´ В), задаваемой формулой 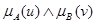 . В этом смысле А´ В есть нечеткое отношение U и V.
. В этом смысле А´ В есть нечеткое отношение U и V.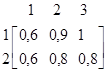
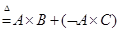 (6.25)
(6.25) Если А, Тогда В, Иначе V=А´ В+Ø А´ V (6.27)
Если А, Тогда В, Иначе V=А´ В+Ø А´ V (6.27)