|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Архитектура многослойной сети прямого распространения. ⇐ ПредыдущаяСтр 7 из 7
Стандартная L-слойная сеть прямого распространения состоит из слоя входных узлов (будем придерживаться утверждения, что он не включается в сеть в качестве самостоятельного слоя), (L-1) скрытых слоев и выходного слоя, соединенных последовательно в прямом направлении и не содержащих связей между элементами внутри слоя и обратных связей между слоями. Многослойный перцептрон. Наиболее популярный класс многослойных сетей прямого распространения образуют многослойные перцептроны, в которых каждый вычислительный элемент использует пороговую или сигмоидальную функцию активации. Многослойный перцептрон может формировать сколь угодно сложные границы принятия решения и реализовывать произвольные булевы функции [37]. Разработка алгоритма обратного распространения для определения весов в многослойном перцептроне сделала эти сети наиболее популярными у исследователей и пользователей нейронных сетей. Геометрическая интерпретация [109] объясняет роль элементов скрытых слоев (используется пороговая активационная функция). RBF-сети. Сети, использующие радиальные базисные функции (RBF-сети), являются частным случаем двухслойной сети прямого распространения. Каждый элемент скрытого слоя использует в качестве активационной функции радиальную базисную функцию типа гауссовой. Радиальная базисная функция (функция ядра) центрируется в точке, которая определяется весовым вектором, связанным с нейроном. Как позиция, так и ширина функции ядра должны быть обучены по выборочным образцам. Обычно ядер гораздо меньше, чем обучающих примеров. Каждый выходной элемент вычисляет линейную комбинацию этих радиальных базисных функций. С точки зрения задачи аппроксимации скрытые элементы формируют совокупность функций, которые образуют базисную систему для представления входных примеров в построенном на ней пространстве. Существуют различные алгоритмы обучения RBF-сетей [96]. Основной алгоритм использует двушаговую стратегию обучения, или смешанное обучение. Он оценивает позицию и ширину ядра с использованием алгоритма кластеризации " без учителя", а затем алгоритм минимизации среднеквадратической ошибки " с учителем" для определения весов связей между скрытым и выходным слоями. Поскольку выходные элементы линейны, применяется неитерационный алгоритм. После получения этого начального приближения используется градиентный спуск для уточнения параметров сети. Этот смешанный алгоритм обучения RBF-сети сходится гораздо быстрее, чем алгоритм обратного распространения для обучения многослойных перцептронов. Однако RBF-сеть часто содержит слишком большое число скрытых элементов. Это влечет более медленное функционирование RBF-сети, чем многослойного перцептрона. Эффективность (ошибка в зависимости от размера сети) RBF-сети и многослойного перцептрона зависят от решаемой задачи. Существует множество спорных вопросов при проектировании сетей прямого распространения - например, сколько слоев необходимы для данной задачи, сколько следует выбрать элементов в каждом слое, как сеть будет реагировать на данные, не включенные в обучающую выборку (какова способность сети к обобщению), и какой размер обучающей выборки необходим для достижения " хорошей" способности сети к обобщению. Хотя многослойные сети прямого распространения широко применяются для классификации и аппроксимации функций [28], многие параметры еще должны быть определены путем проб и ошибок. Существующие теоретические результаты дают лишь слабые ориентиры для выбора этих параметров в практических приложениях. 2. Самоорганизующиеся карты Кохонена. Самоорганизующиеся карты Кохонена (SOM: Self – Organizing Map) [108] обладают благоприятным свойством сохранения топологии, которое воспроизводит важный аспект карт признаков в коре головного мозга высокоорганизованных животных. В отображении с сохранением топологии близкие входные примеры возбуждают близкие выходные элементы. На рис. 5.11 показана основная архитектура сети SOM Кохонена. По существу она представляет собой двумерный массив элементов, причем каждый элемент связан со всеми n входными узлами. Такая сеть является специальным случаем сети, обучающейся методом соревнования, в которой определяется пространственная окрестность для каждого выходного элемента. Локальная окрестность может быть квадратом, прямоугольником или окружностью. Начальный размер окрестности часто устанавливается в пределах от 1/2 до 2/3 размера сети и сокращается согласно определенному закону (например, по экспоненциально убывающей зависимости). Во время обучения модифицируются все веса, связанные с победителем и его соседними элементами. Самоорганизующиеся карты Кохонена могут быть использованы для проектирования многомерных данных, аппроксимации плотности и кластеризации. Эта сеть успешно применялась для распознавания речи, обработки изображений, в робототехнике и в задачах управления, анализе финансовых данных. Параметры сети включают в себя размерность массива нейронов, число нейронов в каждом измерении, форму окрестности, закон сжатия окрестности и скорость обучения. Модели теории адаптивного резонанса. Дилемма стабильности-пластичности является важной особенностью обучения методом соревнования. Как обучать новым явлениям (пластичность) и в то же время сохранить стабильность, чтобы существующие знания не были стерты или разрушены? Карпентер и Гроссберг, разработавшие модели теории адаптивного резонанса (ART1, ART2 и ARTMAP) [81], сделали попытку решить эту дилемму. Сеть имеет достаточное число выходных элементов, но они не используются до тех пор, пока не возникнет в этом необходимость. Будем говорить, что элемент распределен (не распределен), если он используется (не используется). Обучающий алгоритм корректирует имеющийся прототип категории, только если входной вектор в достаточной степени ему подобен. В этом случае они резонируют. Степень подобия контролируется параметром сходства k, 0< k< 1, который связан также с числом категорий. Когда входной вектор недостаточно подобен ни одному существующему прототипу сети, создается новая категория, и с ней связывается нераспределенный элемент со входным вектором в качестве начального значения прототипа. Если не находится нераспределенного элемента, то новый вектор не вызывает реакции сети. Модель ART1 может создать новые категории и отбросить входные примеры, когда сеть исчерпала свою емкость. Однако число обнаруженных сетью категорий чувствительно к параметру сходства. Сеть Хопфилда. Хопфилд использовал функцию энергии как инструмент для построения рекуррентных сетей и для понимания их динамики [101]. Формализация Хопфилда сделала ясным принцип хранения информации как динамически устойчивых аттракторов и популяризовала использование рекуррентных сетей для ассоциативной памяти и для решения комбинаторных задач оптимизации. Динамическое изменение состояний сети может быть выполнено по крайней мере двумя способами: синхронно и асинхронно. В первом случае все элементы модифицируются одновременно на каждом временном шаге, во втором - в каждый момент времени выбирается и подвергается обработке один элемент. Этот элемент может выбираться случайно. Главное свойство энергетической функции состоит в том, что в процессе эволюции состояний сети согласно уравнению она уменьшается и достигает локального минимума (аттрактора), в котором она сохраняет постоянную энергию. Ассоциативная память Если хранимые в сети образцы являются аттракторами, она может использоваться как ассоциативная память. Любой пример, находящийся в области притяжения хранимого образца, может быть использован как указатель для его восстановления. Ассоциативная память обычно работает в двух режимах: хранения и восстановления. В режиме хранения веса связей в сети определяются так, чтобы аттракторы запомнили набор p n-мерных образцов {x1, x2,..., xp}, которые должны быть сохранены. Во втором режиме входной пример используется как начальное состояние сети, и далее сеть эволюционирует согласно своей динамике. Выходной образец устанавливается, когда сеть достигает равновесия. Сколько примеров могут быть сохранены в сети с n бинарными элементами? Другими словами, какова емкость памяти сети? Она конечна, так как сеть с n бинарными элементами имеет максимально 2n различных состояний, и не все из них являются аттракторами. Более того, не все аттракторы могут хранить полезные образцы. Ложные аттракторы могут также хранить образцы, но они отличаются от примеров обучающей выборки. Минимизация энергии. Сеть Хопфилда эволюционирует в направлении уменьшения своей энергии. Это позволяет решать комбинаторные задачи оптимизации, если они могут быть сформулированы как задачи минимизации энергии. В частности, подобным способом может быть сформулирована задача коммивояжера. Некоторые другие обучающие алгоритмы из таблицы 6.3 описаны в следующих работах: Adaline и Madaline [109], линейный дискриминантный анализ [104], проекции Саммона [104], анализ главных компонентов [99].
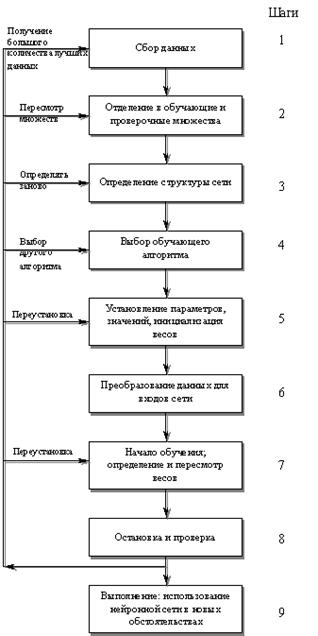
Процесс развития ИНС. Хотя процесс ИНС похож на методологии структурного проектирования традиционных компьютерных ИС, некоторые шаги присущи только приложениям нейронных сетей или имеют дополнительные факторы. В процессе, описанном ниже, мы допускаем, что предварительные шаги развития системы, такие как определение информационных потребностей и проведение анализа реализуемости проекта полностью закончены. Такие шаги являются общими для любой информационной системы. Как показано на рис. 6.8., процесс развития приложения ИНС имеет девять шагов. На шаге 1 собираются данные, которые должны использоваться для обучения и проверки сети. Важно принимать во внимание, чтобы поставленная задача была доступна для получения решения ИНС и чтобы для этого существовали и могли быть получены адекватные данные. На шаге 2 должны быть установлены обучающие данные и должен быть создан план для проверки выполнения сети. На шагах 3-4 выбираются архитектура сети и обучающий метод. Наличие специальных инструментальных средств развития ИНС может определить тип нейронной сети, которая должна быть построена. Важными соображениями являются специальное количество нейронов и число уровней. Существующие модели нейронных сетей имеют параметры, которые настраивают сеть на желаемый уровень исполнения. Частью процесса на шаге 5 является инициализация весов и параметров сети, которая также следует после получения отклика об исполнении. Часто первоначальные значения важны для определения эффективности и продолжительности обучения. Следующая процедура на шаге 6 преобразует используемые данные в тип и формат, требуемые нейронной сетью. Это может означать использование программ для предварительной обработки данных. Хранение и манипулирование данными должно быть организовано для удобного и эффективного переобучения нейронной сети, когда это необходимо. Также способ представления и организации используемых данных часто определяет эффективность и, возможно, точность результатов, получаемы ИНС. На шагах7-8 обучение и проверка проводятся как интервальный процесс представления входных и желаемых выходных данных в сеть. Нейронная сеть вычисляет фактические выходы и регулирует веса до тех пор, пока фактические выходы будут подходить желаемому состоянию. Желаемые выходы и их связи со входными данными получают из исторических данных (части данных, собранных на шаге 1). На шаге 9 процесса получают устойчивое множество весов. Теперь сеть может воспроизводить желаемые выходы изданных входов также как на обучаемом множестве. Нейронная сеть готова для использования как самостоятельная система или как часть другой программной системы.
Рис.6.8. Последовательность процесса развития и настройки искусственной нейронной сети. Развитие ИНС вызвало немало энтузиазма и критики. Некоторые сравнительные исследования оказались оптимистичными, другие - пессимистичными. Для многих задач, пока не создано доминирующих подходов. Выбор лучшей технологии должен диктоваться природой задачи. Нужно пытаться понять возможности, предпосылки и область применения различных подходов и максимально использовать их дополнительные преимущества для дальнейшего развития интеллектуальных систем. Подобные усилия могут привести к синергетическому подходу, который объединяет ИНС с другими технологиями для существенного прорыва в решении актуальных проблем. Как недавно заметил Минский, пришло время строить системы за рамками отдельных компонентов. Индивидуальные модули важны, но мы также нуждаемся в методологии интеграции. Ясно, что взаимодействие и совместные работы исследователей в области ИНС и других дисциплин позволят не только избежать повторений, но и (что более важно) стимулируют и придают новые качества развитию отдельных направлений.
Популярное:
|
Последнее изменение этой страницы: 2017-03-11; Просмотров: 1104; Нарушение авторского права страницы