
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Взвешивание вербальных (словесных) значений
Некоторые параметры («Год выпуска», «Мощность двигателя», «Разгон Некоторые параметры («Год выпуска», «Мощность двигателя», «Разгон до 100», «Число дверей», «Цена», «Потребление топлива на 100 км») вариантов имеют числовые значения, а некоторые – словесные, такие как «Тип привода», «Тип кузова», «Цвет», «Страна выпуска». Словесные значения называются качественными, как противоположность количественным (числовым) значениям. Наряду с термином «словесные» используется термины «вербальные» и «лингвистические». Эквивалентны по смыслу словосочетания «словесные значения», «вербальные значения» и «лингвистические метки». Что сравнивать словесные значения для них следует установить либо ранги, либо веса. Ранги используются в методе главного критерия, а в методе интегрального критерия вычисляются веса. При этом эти веса рассматриваются как числовые эквиваленты вербальных значений. Ранг – это аналог сортности товара или занятого места в соревновании. Высший ранг равен 1, далее идут ранги 2, 3, и так далее до числа сравниваемых слов Вес слова – это доля «значимости» или «важности» этого слова в совокупной «значимости» («важности») всех сопоставляемых слов. Поэтому вес представляет собой число из отрезка По сути дела, установление рангов или весов – это определение отношения предпочтения на совокупности слов, образующих множество значений вербального показателя. Отношение предпочтения представляет собой содержательную частную интерпретацию математического отношения порядка. При этом если равенство рангов или весов допускается, то имеет место отношение нестрогого порядка, в противном случае – отношение строгого порядка. И ранги, и веса устанавливаются с помощью таблицы парных сравнений. Различие состоит только в способе заполнения таблицы и способе вычисления исковых значений. Определение рангов рассмотрено в материалах по методу главного критерия. Здесь рассмотрим методику взвешивания словесных значений. Матрица парных сравнений 1) строки и столбцы матрицы маркируются вербальными значениями (словами) или их сокращениями; эти значения в последующем будем называть ещё и вариантами в соответствии с традиционной терминологией парных сравнений; 2) в диагональных ячейках располагаются единицы – признаки эквивалентности значений; 3) в каждой наддиагональной ячейке размещается
4) каждая поддиагональная ячейка заполняются величиной обратной значению ячейки, симметричной относительно диагонали, т. е. в ней помещается
5) для каждого столбца вычисляется сумма значений ячеек 6) формируется новая – нормированная матрица парных сравнений 7) Таким образом формируется вектор весов
Изложенные выше пункты методики в целом семантически не сложны. Возникает только один вопрос: каким образом следует выбирать число Ответ на этот вопрос содержится в методике Саати []. Для чисел множества 1 – вариант строки эквивалентен по значимости (важности) варианту столбца; 3 – значимость варианта строки несущественно (в три раза) превышает значимость варианта столбца; 5 – значимость варианта строки явно (в пять раз) превышает значимость варианта столбца; 7 – значимость варианта строки существенно (в семь раз) превышает значимость варианта столбца; 9 – значимость варианта строки значительно (в девять раз или более) превышает значимость варианта столбца; 2, 4, 6, 8 – промежуточные значения, используемые для более «тонкого» выражения мнения о превосходстве варианта строки над вариантом столбца. Для величин обратных числам множества 1/3, 1/5, 1/7, 1/9 – соответственно значимость варианта строки несущественно, явно, существенно, значительно ниже значимости варианта столбца; 1/2, 1/4, 1/6, 1/8 – промежуточные значения для выражения мнения о меньшей значимости варианта строки по сравнению с вариантом столбца. В процессе формирования матрицы a) аналитик выбирает качественное (словесное) выражение степени доминирования сопоставляемых вариантов; b) число, ассоциированное с выбранным словесным выражением степени доминирования, выбирается автоматически программной системой либо проставляется в таблицу вручную, если решение осуществляется в табличном процессоре без использования программирования. Можно использовать и такой подход. Определяются три уровня доминирования одного сравниваемого варианта над другим: 1) незначительный; 2) существенный; 3) очень существенный. За указанными уровнями закрепляются соответствующие тройки целых чисел: (1, 2, 3); (4, 5, 6.); (7, 8, 9). Процесс выбора числа, выражающего степень доминирования одного варианта над другим, разделяется на три шага: a) выбирается качественное (словесное) выражение степени доминирования: 1) незначительный; 2) существенный; 3) очень существенный; b) выбирается уточнение выбранной степени: 1) Left; 2) Centre; 3) Right; c) число, ассоциированное с выбранным словесным выражением степени доминирования, выбирается автоматически программной системой либо проставляется в таблицу вручную, если решение осуществляется в табличном процессоре без использования программирования. При этом, если вариант строки доминирует вариант столбца, то в соответствующий элемент матрицы Отметим следующее: если множество сопоставляемых слов невелико (2 – 4), то для выражения отношения предпочтительностей двух вербальных значений можно использовать не только целые числа, но и дроби, такие как 1, 5; 1, 5; 1, 75; 2, 25 и т. д. Конечно же, взвешивать нужно только те словесные значения, которые представлены в таблице допустимых вариантов. Взвешивать все значения, содержащиеся в таблице исходных вариантов, смысла нет. Наглядными примерами расчёта весов вербальных значений являются расчёты, выполненные в рамках рассматриваемого примера, и представленные в таблицах 3 – 9. Таблица 3 содержит матрицу
Нетрудно заметить, что процессы ранжирования и взвешивания взаимосвязаны. Наиболее очевидно то, что по весам «автоматически» определяются ранги, – путём упорядочения вариантов по убыванию их весов. Эти ранги указаны в примере таблицы 4. Менее очевиден следующий факт: через ранги можно вычислить веса. Для этого можно использовать формулу:
Заметим, что в случае различия значений всех рангов справедливо равенство Вычислим по указанной формуле веса цветов, используя их ранги, представленные в таблице 4, т.е. сделаем шаг в обратную сторону. Получим следующий вектор весов:
Как видим, векторы Совместно эти веса показаны на рисунке.
Рисунок – Веса цветов по разным методам вычисления на числовой оси Ромбиками на числовой оси представлены веса, найденные по методу Саати, а квадратиками – путём вычисления через ранги вариантов. Как видно из рисунка, веса, вычисленные через ранги, расположены на числовой оси более примитивно: эквидистантно (равномерно). Веса по Саати существенно не равномерны, они более эластичны, поэтому можно предположить, что они более точно выражают мнение аналитика. Таблица 9 иллюстрирует особый частный случай, – когда множество сопоставляемых вербальных значений равно двум. В этом случае не целесообразно строить отдельную матрицу парных сравнений: единицу между двумя значениями легко поделить сразу, без указания того, во сколько раз одно из значений является предпочтительнее другого. После того, как все вербальные значения отображены в числа, и тем самым упорядочены, можно приступить к построению таблицы множества Парето. Популярное:
|
Последнее изменение этой страницы: 2017-03-11; Просмотров: 631; Нарушение авторского права страницы
 . Чем выше ранг, т.е. чем меньше его числовое значение, тем предпочтительнее («лучше», «качественнее») вербальное значение с этим рангом. Процедура установления рангов называется ранжированием, или упорядочиванием. Ранжирование можно рассматривать как отображение множества слов во множество натуральных (целых положительных) чисел.
. Чем выше ранг, т.е. чем меньше его числовое значение, тем предпочтительнее («лучше», «качественнее») вербальное значение с этим рангом. Процедура установления рангов называется ранжированием, или упорядочиванием. Ранжирование можно рассматривать как отображение множества слов во множество натуральных (целых положительных) чисел. . Взвешивание можно рассматривать как отображение множества слов во множество дробных чисел из указанного отрезка.
. Взвешивание можно рассматривать как отображение множества слов во множество дробных чисел из указанного отрезка. , где
, где  – целое число из множества
– целое число из множества  , – если, по мнению аналитика, слово, маркирующее
, – если, по мнению аналитика, слово, маркирующее 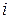 -ю строку, предпочтительнее слова, маркирующего
-ю строку, предпочтительнее слова, маркирующего 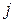 -й столбец; в противном случае, – если слово, маркирующее строку, уступает по качеству слову, маркирующему столбец, – ячейка заполняется
-й столбец; в противном случае, – если слово, маркирующее строку, уступает по качеству слову, маркирующему столбец, – ячейка заполняется 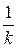 – величиной обратной
– величиной обратной  , т. е. наддиагональный элемент
, т. е. наддиагональный элемент  матрицы
матрицы  заполняется так:
заполняется так: 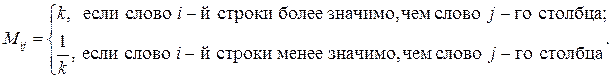
 ,
,  ,
,  ;
;  ,
, 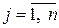 – номер столбца.
– номер столбца. , которая получается в результате деления каждого элемента матрицы
, которая получается в результате деления каждого элемента матрицы  ;
;  – вес
– вес  , т. е.
, т. е.  ,
,  . Его элементы обладают замечательным свойством: их сумма равна единице, т.е.
. Его элементы обладают замечательным свойством: их сумма равна единице, т.е. .
. ?
?  .
. .
.  .
. .
.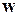 и
и  различаются весьма существенно. В процентах это различие таково:
различаются весьма существенно. В процентах это различие таково:  .
.