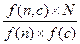|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Математические методы в лингвистикеСтр 1 из 9Следующая ⇒
Математические методы в лингвистике Введение Применение математических методов грамматические и семантические признаки текста звуко-буквенные ассоциации модели стихотворного ритма и рифмы тематическая структура ХТ динамика индивидуального стиля структура литературной ситуации … … В. Г. Адмони, В. С. Баевский, М. Л. Гаспаров, А. П. Журавлев, Ю. Н. Караулов, А. Н. Колмогоров, А. Я. Шайкевич, J. F. Burrows, T. N. Corns, D. L. Hoover и многие др. Направления и темы курса Основы математического анализа в лингвистике. Статистическая лексикография. Статистика и корпусная лингвистика. Математические методы в стилистике и лингвистике текста. Стилометрия. Статистика и фоносемантика. Статистические меры при оценке степени близости слов. Измерение семантических расстояний. Критерии социолингвистического и ассоциативного эксперимента. Вопросы кодификации нормы и количественные исследования речевой вариативности. математические методы в общем языкознании: классификация языков, глоттохронология, исследование циклических процессов в языке и т. д.
Специфика гуманитарных исследований Неточность, расплывчатость понятий и определений. Многозначность терминологии. Преобладание качественных характеристик их основных объектов. Ограниченность возможностей проведения активного эксперимента. Большой объем исходной информации.
Именно второй пункт, преобладание качественных (а не количественных) характеристик объектов, осложняет построение формализованных теорий в гуманитарных сферах. Острота четвертого пункта в отношении текстового анализа постепенно снимается с развитием компьютерных систем и корпусных проектов.
Лингвистика Гуманитарная сфера? 1. Особенности лингвистических объектов 2. Общие интересы наук: лингвистика биология, физика лингвистика социология, психология лингвистика « математика, информатика … … …
? лингвистика литературоведение
Свойства лингвистических объектов измеримость системность вероятностный характер процессов Случайным (стохастическим) называется процесс, мгновенные значения которого являются случайными величинами. Детерминированные процессы: уникальный и предопределённый результат для заданных входных данных. Компьютерный алгоритм, химическая реакция.
Подвижность языковой системы, существование «исключений». Вообще, все процессы, имеющие развитие во времени, с точки зрения теории вероятностей, можно называть стохастическими.
Асимметричность языкового знака Соотношение формы и содержания: полисемия синонимия
Языковые vs. математические знаки Естественные vs. искусственные языки
Генеральная проблема формализованного разрешения неоднозначностей (снятия омонимии) Еще раз о формализации Ю. Н. Марчук: любые данные о языке можно представить в лексикографической форме и — далее — перевести в алгоритмизованную, машинную форму. [? ] По сути это постулат компьютерной лингвистики.
Еще раз о формализации Особенности применения формальных методов на графико-фонетическом, словообразовательном, лексическом, синтаксическом, композиционно-текстовом уровнях. Формальные показатели грамматических значений. Идиоматичность семантики и затруднительность ее формализации и моделирования. О разной степени формализации языка Чем больше степень формализованности метода, тем лучше он будет работать при статистическом измерении. Сравним: Буквы и буквосочетания Грамматические признаки слов, синтаксические конструкции Лексемы (служебные слова/местоимения/знаменат. лексика Элементы композиции Слово как центральная единица языка, лексическая статистика Статусы слова: лексема – лемма словоформа – текстоформа (самое частное понятие; термин часто употребляется в корпусной лингвистике). Самое формальное определение т.: «набор знаков от от пробела до пробела» *слово-ономатема – слово-синтагма в классической лексикологии
Новый частотный словарь русской лексики Под ред. С. А. Шарова и О. Н. Ляшевской http: //dict.ruslang.ru/freq.php Основан на данных Национального корпуса русского языка Содержит информацию о частоте лексем и словоформ разных частей речи + Встречаемость слов в текстах разных функц. стилей Данные о частотности частеречных классов Частотность букв русского алфавита Частотность двубуквенных сочетаний Частотность имен собственных и аббревиатур
Лингвистическая теория текста Текст – самый сложный лингвистический объект. Устная речь и художественные тексты как самые сложные тексты. Стремление к системному описанию формальных и смысловых характеристик (художественного) текста: см. работы Л. Г. Бабенко, Н. С. Болотновой, В. Г. Гака, И. Р. Гальперина, Ю. В. Казарина, В. А. Лукина, Л. А. Новикова, В. А. Пищальниковой, И. Я. Чернухиной и др.
Опять о «гуманитарности» Даже упомянутые структурные модели не являются настолько строгими, чтобы их можно было бы превратить в компьютерные алгоритмы. Моделирование макрокатегорий — таких, как образы автора и персонажей, художественное пространство и время и др., —предполагает человеческое прочтение. Специфика восприятия литературного произведения, помимо интерпретации смысла слов, предполагает не что иное, как переживание текста читателем.
Формализация при АОТ Практика автоматической обработки текста — в том числе информационный поиск, автоматическое аннотирование, машинный перевод и т.п. — выдвигает особые требования к «интегральному» описанию текста, которое должно быть абсолютно лишено неформализованных блоков информации, интуитивно понятных только человеку.
Аксиоматические положения математические методы, позволяют свести до минимума субъективизм исследователя, количественно оценить результат и проверить степень его достоверности. Чем больше по объему материал, тем объективнее результаты исследования. (вопрос повторяемости единиц). Необходимо учитывать степень формализации лингвистического материала. Количественное исследование становится по-настоящему объективным, если оно имеет сравнительный характер. Корректность выборки зависит от набора причин (пространство, время, человек etc.). There are three kinds of lies: lies, damned lies, and statistics Объективность vs. корректность модели Мат. методы (в том числе математическая статистика) – это лишь инструмент для работы. Представления и гипотезы о причинной связи должны быть привнесены из некоторой другой теории, которая позволяет содержательно объяснить изучаемое явление.
Иными словами, даже верные статистические показатели могут создать картину, которая противоречит языковой (тем более – литературно-художественной) действительности.
Cтатистические инструменты в применении к лингвистическим объектам Статистика (от латинского status) Отрасль знаний, изучающая количественную сторону массовых явлений в числовой форме. Выявляет скрытые закономерности и изучает их с помощью обобщенных показателей.
Статистика и лингвистика: эффективность взаимодействия Гармоничное сочетание качественных (традиционных и во многом – интуитивных) и количественных методов. Понимание типов лингвистических задач, решаемых статистическими методами, и возможной исчислимости яз. единиц и их признаков. Знание лингвистом необходимого набора статистических инструментов. Текст, словарь, корпус Основными объектами применения статистики в языкознании обычно является речь (текст), словарные и грамматические данные. Текст → язык. Количественное описание функционирования различных языковых единиц (фонем, букв, морфем, слов) в тексте: частота употребления единиц, их распределение в текстах разного жанра, сочетаемость и т. п. Накопление количественной информации о классах единиц, о конструкциях (напр., данные о средней длине слова или предложения, о частоте употребления каких-либо грам. форм в тех или иных синтаксических функциях и т. п.). Такая информация углубляет описание единиц языка. Сегодня объектом применения статистики все чаще становятся лингвистические корпуса. Выборочный метод Пример с орфоэпическим опросом: обеспé чение или обеспечé ние?
Случайная величина в этом случае может принимать только одно значение из двух (если только информант не колеблется). Тогда возможные степени градации: не знаю скорее, 1-е скорее, 2-е Требования к выборке по выборке (т. е. по части множества) мы должны сформировать некое представление о всей генеральной совокупности. Чтобы оно не было ошибочным, к выборке предъявляются критерии репрезентативности однородности Формулы: обозначения частот Выборочные частоты: x1, x2, x3, x4… xn Любая выборочная частота: xi Средняя частота: x. Средние значения Выборочное среднее – среднее арифметическое для элементов выборки. Мода – значение, которое встречается наиболее часто. Распределение может иметь несколько мод. Медиана – значение, которое делит ранжированную выборку на две равные части (или среднее по порядку, рангу значение). Медиана часто согласуется с интуитивным пониманием «среднего». Средние значения Выборочное среднее = 157: 22 = 7, 1363636 Мода = 8 (встречается 9 раз). Если в выборке более чем одна мода, она называется мультимодальной. Медиана = 7 (средняя частота 11-го и 12-го элементов из 22)
В данном случае ср. знач. близки, но они могут существенно расходиться. Вопрос построения модели! В крупном тексте: «Тихий Дон»: для знаменательных лемм (22409) Выборочное среднее = 11, 6. Мода = 1 (встречается 7480 раз). Обычный показатель для практически любого протяженного текста. Медиана = 3 (частота элемента ранга 11205 из 22409).
Пример регрессионной зависимости Закон Ципфа закономерность распределения частоты слов естественного языка: если все слова языка (или просто достаточно длинного текста) упорядочить по убыванию частоты их использования, то частота n-го слова в таком списке окажется приблизительно обратно пропорциональной его порядковому номеру n (рангу этого слова). Закон носит имя своего первооткрывателя — американского лингвиста Джорджа Ципфа (George Kingsley Zipf) из Гарвардского университета.
Закон Ципфа: зависимость частоты от ранга
Обратно-пропорциональная зависимость между рангом слова (r) и его частотой (f), k – константа, зависящая от корпуса (абсолютное число употреблений самого частотного слова), α – степенной параметр, зависящий от грамматического строя языка.
Частоты по НЧС РЯ Чистый Ipm и формула регрессии
Величины, на которых построен график По НКРЯ видно, что перед нами: Эмпирическая зависимость, а не строгое соответствие. Связана с особенностями конкретного языка. Связана со структурой конкретного корпуса данных.
Закон Ципфа первая тысяча самых частотных слов покрывает от 70 до 90 процентов любого текста (точный процент зависит от выбранного языка и жанра). чем дальше от начала списка, тем менее предсказуема частота конкретного слова и тем больше она зависит от структуры корпуса. [Шаров, Ляшевская]: слова неумолимо и подвох входят в число 20 000 самых частотных слов, а слова изворотливый и раскуривать – за пределами 30 000. Литературоцентричность корпуса. Специфика моделирования языка.
Закон Ципфа: дискуссия и опровержение Американский биолог Ли Вэньтянь попытался опровергнуть закон Ципфа, строго доказав, что случайная последовательность символов подчиняется закону Ципфа. Автор делает гипотетический вывод, что закон Ципфа, по-видимому, является чисто статистическим феноменом, не имеющим отношения к чисто языковым параметрам. Вероятность случайного появления какого-либо слова длиной n в цепочке случайных символов уменьшается с ростом n в той же пропорции, в какой растет при этом номер этого слова в частотном списке. Потому произведение номера слова на его частоту есть константа.
Статистика и проблемная область Корреляционный и регрессионный анализ нельзя использовать для определения наличия связи между переменными, поскольку наличие такой связи и есть предпосылка для применения анализа. Статистическая корреляция наиболее интересна тогда, когда она указывает на существование закономерной связи между изучаемыми явлениями. Возвращаемся к проблеме, заявленной ранее Случайны или существенны отклонения выборочных частот от средней? Подчиняются ли общему статистическому закону колебания лексических частот, наблюдаемые на материале корпуса, или метрические отклонения в поэтических текстах? Два направления ответов: методы статистики методы проблемной области (филологии)
Частотные словари Признаки, применимость, проблемы, обзор источников Частотный словарь: основные признаки Список слов с указанием частоты встречаемости. Область параметризации. Общеязыковой – функционально-стилистический – авторский – текстовый: словари языка, подъязыка, идиостиля автора, текста, разговорной речи. Достоверность обеспечивается большим корпусом текстов. Сортировка по убыванию частоты, алфавиту, типичности (слова, частотные для большинства текстов). Частотный словарь: применимость преподавание языка создание новых словарей компьютерная лингвистика исследования в области лингвистической типологии лингвистический «мониторинг», исследование языковых подсистем и идиостилей определение границ активного словарного состава частотный словарь и «образ мира»
Частотные показатели Относительная частота (ipm) Ранг (порядковый номер). Вопрос нумерации рангов (Засорина: всем словам, имеюшим одинаковую частоту, присвоен один ранг. Выравнивание показателей за счет анализа встречаемости слов в разных сегментах корпуса (коэффициент Жуйана, D). Влияние дискурса. Лексический материал Формализация понятий слова и границ слова. Текстоформы, словоформы, леммы. Конкордансы, их получение и использование в филологическом анализе. Частотность слов в Интернете. Вопрос об измерении частот в обиходно-разговорной речи.
Частотные зоны словаря Служебные и др. стоп-слова Частотная знаменательная лексика Зона редких слов. Еще раз о законе Ципфа: зависимость частоты от ранга Закон Ципфа первая тысяча самых частотных слов покрывает от 70 до 90 процентов любого текста (точный процент зависит от выбранного языка и жанра). чем дальше от начала списка, тем менее предсказуема частота конкретного слова и тем больше она зависит от структуры корпуса.
Частотный словарь, построенный на базе BNC
Частотный словарь, построенный на базе Брауновского корпуса: возможность сравнения корпусов исходя из частотных показателей most common words in English Статистические методы MI (mutual informarion), «коэффициент взаимной информации». t-score, анализ частоты совместной встречаемости слова и его коллоката. Log-likelihood (логарифмическая функция правдоподобия) отношение функций правдоподобия, соответствующих двум гипотезам – о случайной и неслучайной природе двусловия. Критерий χ ² (Хи-квадрат), или Критерий Пирсона, употребляемый для проверки гипотезы распределения вероятностей. … … …
Статистические меры. Мера MI сравнивает зависимые контекстно-связанные частоты с независимыми, как если бы слова появлялись в тексте совершенно случайно:
MI=log2, где
MI — объем информации < …> f(n, c) — частота встречаемости ключевого слова n в паре с коллокатом c; f(n), f(c) — абсолютные частоты ключевого слова n и слова c в корпусе; N — общее число словоформ в корпусе. Если значение MI (n, c) больше 1, тогда данное сочетание слов считается статистически значимым. Вопрос о пороговом значении. Статистические меры. Мера t-score учитывает частоту совместной встречаемости слова и коллоката:
t-score =, где
f(n, c) — частота встречаемости ключевого слова n в паре с коллокатом c; f(n), f(c) — абсолютные частоты ключевого слова n и слова c в корпусе; N — общее число словоформ в корпусе.
Выделение коллокаций с очень частотными словами (например, служебными). Слова с наибольшим значением t-score оказываются самыми частотными языковыми неоднословными целостностями. Идея стоп-листа. Статистические меры коллокации, выделяемые с помощью меры MI, чаще всего являются сложными номинациями (терминами, наименованиями объектов, ключевых для определения предметной области) критерий t-score направлен, прежде всего, на выделение «устойчивых конструкций», клише и «общеязыковых устойчивых сочетаний» (производных служебных слов, дискурсивных слов)
Статистика по слову война [Хохлова 2008] По словарю коллокаций Е. Г. Борисовой
MI-коллокации по [Ягунова, Пивоварова 2010] для новостных текстов – 5 КУРМАНБЕК БАКИЕВ, 6 АЛИШЕР УСМАНОВ, 7 БЕНЕДИКТ XVI, 8 УСЕЙН БОЛТ, 12 СЕРДЕЧНЫЙ ПРИСТУП, 13 ОСАМА БИН, 16 СТИХИЙНЫЙ БЕДСТВИЕ, 21 ЛАМПА НАКАЛИВАНИЕ, 22 РАДОВАН КАРАДЖИЧ, 23 ПОЛЕЗНЫЙ ИСКОПАЕМОЕ, 24 ДЖОННИ ДЕПП, 25 ФИДЕЛЬ КАСТРО, ДОЛИНА СВАТ, 30 САДДАМ ХУСЕЙН, 33 СИМФОНИЧЕСКИЙ ОРКЕСТР, 35 КРОВНЫЙ МЕСТЬ, 37 РАФАЭЛЬ НАДАЛЬ, 38 РИММА САЛОНЕН, 40 КРУГЛЫЙ СТОЛ, 41 ГАРРИ ПОТТЕР, 42 РОБЕРТО МИЧЕЛЕТТИ, 43 ЗАРАБОТНЫЙ ПЛАТА, 44 БОСНИЙСКИЙ СЕРБ, 45 ЧЕН ИР; Материал – портал www.lenta.ru с апреля по декабрь 2009; общий объем проанализированных текстов: более 66000000 «токенов» (словоупотребленией и знаков препинания) [Ягунова, Пивоварова 2010] Биграммы с наиболее высокими значениями меры t-score Статистика и идиостилистика Объем произведения, грамматические параметры, «словарный запас». Применение количественных методов грамматические и семантические признаки текста звуко-буквенные ассоциации модели стихотворного ритма и рифмы тематическая структура ХТ динамика индивидуального стиля структура литературной ситуации В. Г. Адмони, В. С. Баевский, М. Л. Гаспаров, А. П. Журавлев, Ю. Н. Караулов, А. Н. Колмогоров, А. Я. Шайкевич, J. F. Burrows, T. N. Corns, D. L. Hoover и др.
Лингвистическая теория текста Существующие структурные модели, как правило, не являются настолько строгими, чтобы их можно было бы превратить в компьютерные алгоритмы. Моделирование макрокатегорий — таких, как образы автора и персонажей, художественное пространство и время и др., — предполагает человеческое прочтение. Специфика восприятия литературного произведения, помимо интерпретации смысла слов, предполагает не что иное, как переживание текста читателем. Проблема квантификации «эстетического объекта».
Художественный текст и статистика ! Однако и художественный текст характеризуется измеряемостью. Он состоит из языковых единиц, имеющих количественные и качественные признаки. Последние формализуются значительно сложнее, если вообще формализуются.
Как с помощью статистических данных отразить в исследовании текста, языка писателя, особенности литературного направления, периода именно то индивидуальное, что характеризует язык произведений? Как с помощью статистических данных доказать или опровергнуть авторство анонимного или псевдонимного текста?
Сопоставление По результатам анализа можно выделить сферы, в большей и в меньшей степени характерные для авторов
Примеры социолингвистических выкладок Гендерные исследования на материале корпуса Гендерная характеристика длины высказывания [Даниэль, Зеленков, 2012] Источник данных – устный подраздел в НКРЯ (10 млн текстоформ). 3 группы документов: публичная речь, непубличная речь, речь кино. Метаразметка по признакам пола и возраста. Средняя длина высказывания как социолингвистический показатель. Понятие «реплики» как набора высказываний до смены говорящего или до конца документа. Стереотип женской речи: «болтливость». Полученные данные Средняя длина реплики Мужчины: 26, 34 слова Женщины: 15, 41 слова Средняя длина реплики в публичной речи Мужчины: 30, 36 Женщины: 20, 65 Средняя длина реплики в частной речи Мужчины: 10, 77 Женщины: 10, 29 Полученные данные Средняя длина реплик в зависимости от пола адресата
В частном разговоре женщина больше говорит с женщиной, а мужчина – с мужчиной. В публичной речи пол адресата значительно увеличивает продолжительность реплики у обоих полов.
Гендерные характеристики ряда семантических классов слов [Мухин, 2014] Источник данных – основной подраздел в НКРЯ
На текущий момент в основной части корпуса Мужских текстов: 32 806 документов, 15 071 686 предложений, 180 140 656 слов (180 млн). Женских текстов: 10 511 документов, 2 566 969 предложений, 28 914 624 слова (29 млн). Доля текстов с обозначенным полом автора: 86, 2 % 13, 8 % Предыстория и уточнение терминов Проблема междометий Кто чаще ахает – женщины или мужчины? J Если судить по зоне снятой грамматической омонимии, мужчины употребляют междометия в два раза чаще, чем женщины (1604 ↔ 891 на миллион слов, ipm ). Определимся с понятиями: гендер – статистические различия в приоритетах употребления слов мужчинами и женщинами, объясняемые социальными стереотипами; антигендер – отсутствие таких различий; трансгендер – выбор приоритетов употребления слов, стереотипно свойственных противоположному полу.
Гендерно маркированные группы слов и социальное ожидание (гипотеза): Чувства, эмоции Цвета, цветовая картина мира Деньги Спорт Алкоголь, табак Неприличные слова Секс, сексуальность
Учитывается фактор омонимии при подборе материала
Чувства, эмоции любовь любить любимый ненависть ненавидеть радоваться радость радостный грустить грусть грустный счастье счастливый несчастье несчастливый горе горевать
Цвета, цветовая картина мира
Цвета: значимые гендерные различия Деньги Спорт Алкоголь, табак Неприличные слова Мат (три корня) Секс, сексуальность Статистика употребления слов с корнем секс-, ipm: Основные итоги положит. чувства, эмоции цвета: частные различия деньги (кроме рубля) алкоголь (водка), курение мат
отрицат. чувства, эмоции цветовая картина мира деньги (рубль)
междометия спорт, кроме хоккея коньяк, пиво, сигареты грубое просторечие секс, сексуальность (? ) Статистические методы при изучении языковой нормы: Норма и нормативность Норма и система языка Признаки нормативности Устойчивость, консерватизм Распространённость языкового явления (узуальность) — количественный фактор. Норма и узус (? ). то́ карей или токаре́ й, То́ карей или Токаре́ й? Вся речевая деятельность вся литература Все нехудожественные тексты Театральная речь Речь филологов (? ) Соответствие системе языка. Дружить Долбить Сверлить Бурить Крепить Включить Звонить Орфографические вопросы Бренд – брэнд Блогер – блоггер Прайм-тайм – праймтайм Экскурс в историю вопроса. Источники данных Интернет Узус и словари Специфика опросов Диалектные различия Влияние звучащих СМИ Корпус как источник данных Среди современных примеров найдите те, в которых слова эк и эко употреблены не по нормам XIX в. 1) …Я снова остановилась. Эк меня заносит! Надо поспокойнее. [Дарья Донцова (2004)]. 2) Парень вдруг расслабился и даже разулыбался. « Эко его кидает», — подумала Лизавета [Е. Козырева (2001)] 3) — Эк куда тебя понесло! При чем тут президент? Я с ним встречаться не собираюсь. [Семен Данилюк (2003)] 4) Эко хватил г-н Огарев! А на практике, после женитьбы, оказалось проще простого: не сошлись характерами и разошлись [Юрий Безелянский. В садах любви (1993)] 5) « Эк разрезвилась сестренка, —думал Павел, стараясь подняться до обычного своего покровительственного тона с младшими. [Ирина Ратушинская. Одесситы (1998)] 6) Не нравится мне этот конец дикостью своей, нелепостью и тем, что вроде бы и не вытекает из всего сказанного выше. Так сочини другой, эко дело! [Кураев Михаил (2000)] Корпус как источник данных Однако корпус, даже сбалансированный, не всегда может быть источником проверки нормативности: Объем О частоте слов в Интернете Google: «Таллинн»: 2, 04 млн 2, 04 млн – 1, 097665 млн (сумма употреблений конкретных словоформ = 942 335 (потерянный остаток) Глоттохронология, Глоттохронология Метод сравнительно-исторического языкознания для предположительного определения времени разделения родственных языков, основанный на гипотезе, что скорость изменения базового словаря языка остается примерно одинаковой. Гипотеза предложена американским лингвистомМоррисом Сводешом (Morris Swadesh). Оценка «лексического полураспада» языка, определение периода, за который два или более языка разошлись от общего праязыка, путем подсчёта количества заменённых слов в каждом языке. Затем вычисляется приблизительное время появления этих языков. Сгласно глоттохронологической гипотезе, в каждом языке особой стабильностью к изменениям во времени обладает некоторое количество одинаковых для всех языков понятий. Эти понятия относят к так называемой «ядерной», «базовой» лексике. Список Сводеша (Swadesh list) — инструмент для оценки степени родства между различными языками по признаку схожести наиболее устойчивого базового словаря. Стандартизированный перечень базовых лексем данного языка, приблизительно упорядоченный по убыванию их «базовости» или исторической устойчивости. Минимальный набор «стержневой» лексики содержится в 100-словном списке. Правила составления Интерпретация списков Прямые заимствования. Скорость изменения, в действительности, не постоянна, но зависит от периода времени, в течение которого слово существует в языке (то есть вероятность замены лексемы X лексемой Y возрастает прямо пропорционально прошедшему времени — так называемому «старению слов», эмпирически понимаемому как постепенное «разрушение» первоначального значения слов под весом приобретённых вторичных значений. Отдельные единицы в 100-словном списке имеют разный уровень стабильности (например, для слова «я» обычно вероятность замены намного ниже, чем для слова «жёлтый» и т. д.). Развитие глоттохронологии В связи с традиционными лингвистическими наблюдениями над языком и современными статистическими исследованиями словарей и корпусов можно сформулировать ряд положений (тенденций), связанных с циклическим характером языкового генезиса. Тенденция к разрастанию со временем смысловой области каждого значения и к появлению новых значений у знака как частный случай скачкообразного расширения смысловой области материнского значения и автономизации её частей. Абстрактивизация значений. Наложение друг на друга двух процессов – (1) постепенно замедляющегося и останавливающегося в определённый момент процесса появления новых значений и (2) начинающегося позже и тоже постепенно замедляющегося процесса выпадения ранее появившихся значений – приводит к формированию асимметричной кривой развития полисемии знака, с пиком развития полисемии, сдвинутым к началу жизненного цикла знака (см. далее). Обратнопропорциональная зависимость между частотой употребления знака и его длиной была замечена Джорджем Ципфом Эта зависимость позволяет носителям языка общаться относительно экономно, затрачивая на производство каждого из самых употребительных знаков относительно меньше усилий. Тенденция к росту, а потом падению активности свободных значений слов к порождению от них фразеологически связанных значений. С ростом степени абстрактности значений слов всё более значительного возраста, увеличивается широта контекстов употребления каждого из таких значений. В результате в каких-то из этих контекстов слово в одном из таких значений начинает употребляться в особенности часто, что и ведёт в итоге к формированию новой устойчиво употребляемой и далее идиоматизирующейся комбинации слов, фразеологической единицы. Война: гражданская, мировая, отечественная, холодная, крымская, русско-японская, японская, империалистическая, новая, великая, последняя, ядерная, настоящая, партизанская, франко-прусская, священная, звездная (-ые), тридцатилетняя, большая, минувшая… … гибридная, латентная… Тенденция к деэтимологизации, семантическому и морфемному опрощению структуры слова. В ходе возможного дальнейшего роста употребительности производного слова носители языка могут утратить, забыть мотивацию морфемного состава слова (после десемантизации некоторых морфем и утраты независимого употребления служебными или предметными словами, генетически соответствующими некоторым морфемам). Т. е. может произойти деэтимологизация, семантическое опрощение, переосмысление некоторой группы морфем в пределах слова как одной морфемы, и, как следствие, опрощение его морфемной структуры. Примеры: находить, подушка, забыть, зонтик (голл. zondek)… Апробация модели Математические методы в лингвистике Введение Применение математических методов грамматические и семантические признаки текста звуко-буквенные ассоциации модели стихотворного ритма и рифмы тематическая структура ХТ динамика индивидуального стиля структура литературной ситуации … … В. Г. Адмони, В. С. Баевский, М. Л. Гаспаров, А. П. Журавлев, Ю. Н. Караулов, А. Н. Колмогоров, А. Я. Шайкевич, J. F. Burrows, T. N. Corns, D. L. Hoover и многие др. Направления и темы курса Основы математического анализа в лингвистике. Статистическая лексикография. Статистика и корпусная лингвистика. Математические методы в стилистике и лингвистике текста. Стилометрия. Статистика и фоносемантика. Статистические меры при оценке степени близости слов. Измерение семантических расстояний. Критерии социолингвистического и ассоциативного эксперимента. Вопросы кодификации нормы и количественные исследования речевой вариативности. математические методы в общем языкознании: классификация языков, глоттохронология, исследование циклических процессов в языке и т. д.
Специфика гуманитарных исследований Неточность, расплывчатость понятий и определений. Многозначность терминологии. Преобладание качественных характеристик их основных объектов. Ограниченность возможностей проведения активного эксперимента. Большой объем исходной информации.
Именно второй пункт, преобладание качественных (а не количественных) характеристик объектов, осложняет построение формализованных теорий в гуманитарных сферах. Острота четвертого пункта в отношении текстового анализа постепенно снимается с развитием компьютерных систем и корпусных проектов.
Лингвистика Гуманитарная сфера? 1. Особенности лингвистических объектов 2. Общие интересы наук: лингвистика биология, физика лингвистика социология, психология лингвистика « математика, информатика … … …
? лингвистика литературоведение
Свойства лингвистических объектов измеримость системность вероятностный характер процессов Случайным (стохастическим) называется процесс, мгновенные значения которого являются случайными величинами. Детерминированные процессы: уникальный и предопределённый результат для заданных входных данных. Компьютерный алгоритм, химическая реакция.
Подвижность языковой системы, существование «исключений». Вообще, все процессы, имеющие развитие во времени, с точки зрения теории вероятностей, можно называть стохастическими.
Асимметричность языкового знака Соотношение формы и содержания: полисемия синонимия
Языковые vs. математические знаки Естественные vs. искусственные языки
Генеральная проблема формализованного разрешения неоднозначностей (снятия омонимии) Еще раз о формализации Ю. Н. Марчук: любые данные о языке можно представить в лексикографической форме и — далее — перевести в алгоритмизованную, машинную форму. [? ] По сути это постулат компьютерной лингвистики.
Еще раз о формализации Особенности применения формальных методов на графико-фонетическом, словообразовательном, лексическом, синтаксическом, композиционно-текстовом уровнях. Формальные показатели грамматических значений. Идиоматичность семантики и затруднительность ее формализации и моделирования. О разной степени формализации языка |
Последнее изменение этой страницы: 2017-04-12; Просмотров: 176; Нарушение авторского права страницы
 Формула зависимости для закона Ципфа с учетом конкретного корпуса
Формула зависимости для закона Ципфа с учетом конкретного корпуса