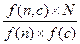|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Статистические методы в лексикографии
Статистическая параметризация в словарном деле Повторяемость элементов Структурность Объемность описываемого материала Отражение языковых соотношений в статистической картине Частотные словари Признаки, применимость, проблемы, обзор источников Частотный словарь: основные признаки Список слов с указанием частоты встречаемости. Область параметризации. Общеязыковой – функционально-стилистический – авторский – текстовый: словари языка, подъязыка, идиостиля автора, текста, разговорной речи. Достоверность обеспечивается большим корпусом текстов. Сортировка по убыванию частоты, алфавиту, типичности (слова, частотные для большинства текстов). Частотный словарь: применимость преподавание языка создание новых словарей компьютерная лингвистика исследования в области лингвистической типологии лингвистический «мониторинг», исследование языковых подсистем и идиостилей определение границ активного словарного состава частотный словарь и «образ мира»
Частотные показатели Относительная частота (ipm) Ранг (порядковый номер). Вопрос нумерации рангов (Засорина: всем словам, имеюшим одинаковую частоту, присвоен один ранг. Выравнивание показателей за счет анализа встречаемости слов в разных сегментах корпуса (коэффициент Жуйана, D). Влияние дискурса. Лексический материал Формализация понятий слова и границ слова. Текстоформы, словоформы, леммы. Конкордансы, их получение и использование в филологическом анализе. Частотность слов в Интернете. Вопрос об измерении частот в обиходно-разговорной речи.
Частотные зоны словаря Служебные и др. стоп-слова Частотная знаменательная лексика Зона редких слов. Еще раз о законе Ципфа: зависимость частоты от ранга Закон Ципфа первая тысяча самых частотных слов покрывает от 70 до 90 процентов любого текста (точный процент зависит от выбранного языка и жанра). чем дальше от начала списка, тем менее предсказуема частота конкретного слова и тем больше она зависит от структуры корпуса.
Частотный словарь, построенный на базе BNC
Частотный словарь, построенный на базе Брауновского корпуса: возможность сравнения корпусов исходя из частотных показателей most common words in English Частотные словари русского языка История и современные возможности Частотные словари РЯ Г. Йоссельсон (1953, Детройт) Э. А. Штейнфельдт (1963, Таллин) Л. Н. Засорина (1977, Москва) Л. Лённгрен (1993, Уппсала)
Основаны на небольших коллекциях (Засорина – на 1 млн слов, т. е. фактически ipm). Ранее считалось, что для достоверности описания 1600 – 1700 самых частотных слов достаточно корпуса в 400 000 слов. Отражают русский язык советского периода (Г. Йоссельсон – досоветского). Возможность ручного снятия омонимии на базе небольшого корпуса. Л. Н. Засорина (1977) Разброс частот в разных словарях (пример Ш – Л), ipm
Новый частотный словарь русской лексики С. Шарова – О. Ляшевской Коллекция НКРЯ 92 млн текстоформ
Статистика по НКРЯ Количество вхождений Количество предложений Количество текстов Статитистические данные по С.Шарову Средняя длина слова 5.28 символа. Средняя длина предложения 10.38 слов. 1000 наиболее частотных лемм покрывает 64.0708% текста. 2000 наиболее частотных лемм покрывают 71.9521% текста. 3000 наиболее частотных лемм покрывают 76.5104% текста. 5000 наиболее частотных лемм покрывают 82.0604% текста.
Проблемы частотных словарей вопрос воспроизводимости показателей (при сравнении разных корпусов), несоразмерность частот отдельных слов (частота слова в одном тексте может повлиять на его позицию в частотном списке), определение позиции менее частотных слов, трудность ранжирования
Проблемы частотных словарей Частотный список, построенный на основе корпуса, отражает специфику текстов, зависит от дискурса! Вопрос качества грамматической разметки. Вопрос размера корпуса: Количество токенов Знаки пунктуации «Орфографические» слова Цифры, сокращения, дефисные написания Проблемы лемматизации Лексические омонимы Формы мн. ч. существительных Видовые пары глагола Возвратные и прямые Степени сравнения Варианты написания, в т.ч. прописная/строчная Грамматические аномалии … …
Лексическая статистика и авторская лексикография Вопрос отражения подъязыка в словаре Авторские словари Стилистические словари
Макроструктура современных корпусов: вопрос корректного моделирования языка. Словари языка писателя Стилевые и частотные словари А. С. Пушкина, Л. Андреева, А. Блока, И. Гончарова, А. Грибоедова, А. Дельвига, Ф. Достоевского, А. Чехова, В. Шукшина, поэзии 1-й пол. ХХ в. … ! Проблема отражения специфики идиостиля.
«Топ» лексической частотности по А. О. Гребенникову А. П. Чехов: говорить, сказать, один, мочь, знать, глаз, человек, рука, лицо, два, стать, глядеть, думать, большой, жизнь, идти, день, голова, сидеть, видеть, другой, жить, дом, казаться, раз, спать, дело, время, жена, люди, бог, взять… Л. Н. Андреев (рука, глаз, сказать, говорить, мочь, лицо, другой, знать, голова, отец, люди, человек, стать, жизнь, смотреть, видеть, слово, думать, нога, хотеть, голос, идти, день, казаться, раз, земля, женщина, дом, черный, два, ночь, стоять… Универсальное и индивидуальное в лексических частотах Постановка проблемы сопоставительного частотного анализа. Лексикографирование идиом и прочих неоднословных целостностей Понятие биграммы (n-граммы). Использование статистических мер. Статистика встречаемости Статистические методы MI (mutual informarion), «коэффициент взаимной информации». t-score, анализ частоты совместной встречаемости слова и его коллоката. Log-likelihood (логарифмическая функция правдоподобия) отношение функций правдоподобия, соответствующих двум гипотезам – о случайной и неслучайной природе двусловия. Критерий χ ² (Хи-квадрат), или Критерий Пирсона, употребляемый для проверки гипотезы распределения вероятностей. … … …
Статистические меры. Мера MI сравнивает зависимые контекстно-связанные частоты с независимыми, как если бы слова появлялись в тексте совершенно случайно:
MI=log2, где
MI — объем информации < …> f(n, c) — частота встречаемости ключевого слова n в паре с коллокатом c; f(n), f(c) — абсолютные частоты ключевого слова n и слова c в корпусе; N — общее число словоформ в корпусе. Если значение MI (n, c) больше 1, тогда данное сочетание слов считается статистически значимым. Вопрос о пороговом значении. Статистические меры. Мера t-score учитывает частоту совместной встречаемости слова и коллоката:
t-score =, где
f(n, c) — частота встречаемости ключевого слова n в паре с коллокатом c; f(n), f(c) — абсолютные частоты ключевого слова n и слова c в корпусе; N — общее число словоформ в корпусе.
Выделение коллокаций с очень частотными словами (например, служебными). Слова с наибольшим значением t-score оказываются самыми частотными языковыми неоднословными целостностями. Идея стоп-листа. Статистические меры коллокации, выделяемые с помощью меры MI, чаще всего являются сложными номинациями (терминами, наименованиями объектов, ключевых для определения предметной области) критерий t-score направлен, прежде всего, на выделение «устойчивых конструкций», клише и «общеязыковых устойчивых сочетаний» (производных служебных слов, дискурсивных слов)
Статистика по слову война [Хохлова 2008] По словарю коллокаций Е. Г. Борисовой
MI-коллокации по [Ягунова, Пивоварова 2010] для новостных текстов – 5 КУРМАНБЕК БАКИЕВ, 6 АЛИШЕР УСМАНОВ, 7 БЕНЕДИКТ XVI, 8 УСЕЙН БОЛТ, 12 СЕРДЕЧНЫЙ ПРИСТУП, 13 ОСАМА БИН, 16 СТИХИЙНЫЙ БЕДСТВИЕ, 21 ЛАМПА НАКАЛИВАНИЕ, 22 РАДОВАН КАРАДЖИЧ, 23 ПОЛЕЗНЫЙ ИСКОПАЕМОЕ, 24 ДЖОННИ ДЕПП, 25 ФИДЕЛЬ КАСТРО, ДОЛИНА СВАТ, 30 САДДАМ ХУСЕЙН, 33 СИМФОНИЧЕСКИЙ ОРКЕСТР, 35 КРОВНЫЙ МЕСТЬ, 37 РАФАЭЛЬ НАДАЛЬ, 38 РИММА САЛОНЕН, 40 КРУГЛЫЙ СТОЛ, 41 ГАРРИ ПОТТЕР, 42 РОБЕРТО МИЧЕЛЕТТИ, 43 ЗАРАБОТНЫЙ ПЛАТА, 44 БОСНИЙСКИЙ СЕРБ, 45 ЧЕН ИР; Материал – портал www.lenta.ru с апреля по декабрь 2009; общий объем проанализированных текстов: более 66000000 «токенов» (словоупотребленией и знаков препинания) [Ягунова, Пивоварова 2010] Биграммы с наиболее высокими значениями меры t-score |
Последнее изменение этой страницы: 2017-04-12; Просмотров: 121; Нарушение авторского права страницы