
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
ЧИСЛЕННЫЕ МЕТОДЫ МОДЕЛИРОВАНИЯСтр 1 из 31Следующая ⇒
СОДЕРЖАНИЕ
Предисловие. 6 7 ЧИСЛЕННЫЕ МЕТОДЫ МОДЕЛИРОВАНИЯ.. 7 7.1 Элементы теории погрешности. 8 7.2 Приближение данных функциями. 11 7.2.1 Интерполирование. 12 7.2.2 Сплайн-функции. 23 7.2.3 Аппроксимация данных методом наименьших квадратов 28 7.3 Численное дифференцирование. 36 7.4 Численное интегрирование. 38 7.4.1 Интерполяционные квадратурные формулы.. 39 7.4.2 Квадратурные формулы наивысшей алгебраической степени точности. Квадратурные формулы Гаусса. 45 7.5 Решение нелинейных уравнений и систем.. 48 7.5.1 Решение нелинейных уравнений. 49 7.5.2 Метод Лобачевского при решении алгебраических уравнений 58 7.5.3 Решение систем нелинейных уравнений. 63 7.6 Решение задач матричной алгебры.. 64 7.6.1 Некоторые понятия матричной алгебры.. 65 7.6.2 Обусловленность систем и матриц. 69 7.6.3 Метод Гаусса. 73 7.6.4 Итерационные методы решения систем линейных алгебраических уравнений. 75 7.6.5 Метод Данилевского при решении полной проблемы собственных значений. Построение канонической формы Фробениуса 80 7.7 Решение обыкновенных дифференциальных уравнений и систем 84 7.7.1 Методы Эйлера и Рунге-Кутта при решении задачи Коши для дифференциального уравнения первого порядка. 85 7.7.2 Правило Рунге. 87 7.7.3 Методы Эйлера и Рунге-Кутта при решении задачи Коши для систем дифференциальных уравнений. 89 7.7.4 Решение задачи Коши для систем линейных дифференциальных уравнений. 90 7.7.5 Методы Адамса при решении задачи Коши для обыкновенных дифференциальных уравнений. 91 7.7.6 Метод сеток решения линейных краевых задач. 93 7.7.7 Метод коллокации решения краевых задач. 96 8 Моделирование систем управления.. 99 8.1 Описание систем в пространстве состояний. 99 8.2 Аналитическое конструирование оптимальных регуляторов 103 8.2.1 Оптимальное управление при минимизации классического квадратичного функционала. 105 8.2.2 Оптимальное управление при минимизации функционала обобщенной работы.. 107 8.2.3 Оптимальное управление при минимизации локального квадратичного критерия. 111 8.2.4 Синтез следящей системы управления. 112 8.3 Моделирование систем оптимального управления. 114 8.3.1 Основные понятия цифровых систем управления. 114 8.3.2 Моделирование поведения управляемого объекта. 116 8.3.3 Синтез оптимального управления. 119 8.4 Моделирование систем управления при случайных внешних воздействиях. 124 8.4.1 Моделирование поведения объекта при наличии внешних возмущений. 124 8.4.2 Описание математической модели измерительного комплекса 126 8.4.3 Оценивание состояния модели объекта. 127 8.4.4 Синтез управляющих воздействий по оценкам состояния 131 8.5 Синтез адаптивной следящей системы.. 134 8.5.1 Основные понятия адаптивных систем управления. 135 8.5.2 Одновременное оценивание состояния и параметров модели объекта 136 8.6 Учет ограничений и запаздываний по управлению.. 140 8.7 Общая схема синтеза адаптивных систем управления. 141 9 Примеры построения математических моделей 144 9.1 Построение математических моделей прямолинейного и вращательного движения. 144 9.1.1 Математическая модель прямолинейного движения. 144 9.1.2 Математическая модель вращательного движения. 146 9.2 Макроэкономическая модель динамики фондов производственного накопления и потребления. 147 9.3 Построение математических моделей производства, хранения и сбыта товара повседневного спроса. 148 10 Программные средства моделирования.. 153 10.1 Языки программирования. 154 10.1.1 Язык Fortran. 154 10.1.2 Язык С.. 154 10.1.3 Язык С++. 155 10.1.4 Языки Pascal и Object Pascal 158 10.2 Системы разработки программного обеспечения. 158 10.2.1 Microsoft Visual C++ и MFC.. 158 10.2.2 Borland Delphi 159 10.2.3 Borland C++Builder 159 10.3 Специализированные математические пакеты.. 160 10.3.1 Система Maple. 161 10.3.2 Система Mathematica. 161 10.3.3 Система MatLAB.. 163 10.3.4 Система MathCAD.. 164 10.3.5 Система STATISTICA.. 166 10.3.6 Система EXCEL. 166 Литература.. 168
Предисловие
При компьютерном моделировании возникает необходимость в численном решении достаточно большого количества разнообразных задач. В связи с этим рассматриваются основные подходы к методам решения таких задач, как приближение данных, численное дифференцирование и интегрирование, решение нелинейных уравнений и систем, решение задач матричной алгебры, решение задачи Коши и краевой для обыкновенных дифференциальных уравнений. Приводятся условия сходимости итерационных алгоритмов, обсуждаются способы реализации и обращается внимание на погрешность результата. Подробно рассматривается моделирование систем управления в пространстве состояний методами аналитического конструирования оптимальных регуляторов. При этом рассматривается формирование следящей системы адаптивного управления с неполным измерением при построении оценок состояния и параметров модели объекта дискретными фильтрами Калмана. Построение такой системы управления осуществляется путем постепенного усложнения с помощью добавления новых алгоритмов и изменения существующих. Так как одной из первых и основных задач при формировании систем управления является построение математической модели управляемого объекта, то рассматриваются примеры построения математических моделей, описывающих прямолинейное и вращательное движение, изменение фондов производственного накопления и потребления, математических моделей процессов производства, сбыта и хранения продукции. В последней главе приводятся характеристики и возможности программных средств, используемых для моделирования систем, как инструментальных, так и специализированных математических пакетов. Эта глава написана в соавторстве с Борисовым Сергеем Ивановичем, программистом ЛИСМО ТУСУР, ассистентом кафедры КСУП ТУСУР.
Элементы теории погрешности
Результаты вычислений особенно достаточно большого объема, что характерно для моделирования реальных процессов, всегда являются неточными. Это вызвано накоплением различного рода погрешностей, влияние которых необходимо учитывать. Основными источниками погрешностей являются: 1) исходные данные, которые для вычислений часто берутся из эксперимента, а каждый эксперимент дает результат с ограниченной точностью; 2) использование иррациональных величин, которые в ЭВМ представляются приближенно; 3) применение итерационных методов решения задач, которые дают только приближенные результаты; 4) необходимость округления результатов при умножении и делении. Общепринятой является следующая классификация погрешностей: 1) неустранимая погрешность, которая возникает за счет неточности исходных данных; 5) погрешность метода, возникающая в результате решения задачи; 6) погрешность округления, которая всегда присутствует в вычислениях. В вычислительной математике большинство задач может быть записано в виде: где где При этом полная погрешность решения задачи может быть записана в виде: Первая скобка в (7.1.4) характеризует погрешность метода, а вторая – погрешность, возникающую за счет неточности исходных данных и округления, которая называется вычислительной погрешностью. И полная погрешность результатов вычислений складывается из вычислительной погрешности и погрешности метода. Обозначим точные значения некоторых величин через Абсолютной погрешностью величины Предельной абсолютной погрешностью Относительной погрешностью величины Предельной относительной погрешностью Рассмотрим зависимость абсолютной и относительной погрешностей функции от соответствующих погрешностей ее аргументов. При этом функцию можно рассматривать как модель вычислительного процесса. Пусть 1) функция 2) величины 3) погрешности аргументов настолько меньше значений соответствующих аргументов, что в сумме ими можно пренебречь. По определению имеем: где и Относительные погрешности функции будут определяться следующим образом:
Примеры. 1. Пусть 2. Пусть Так как погрешности суммируются, то может случиться так, что через достаточно большое число операций погрешности станут столь большими, что полностью исказят результаты вычислений. В связи с этим необходимо всегда учитывать влияние погрешностей, возникающих при моделировании. Интерполирование
Пусть задана таблица значений неизвестной функции В математике под интерполированием понимается задача нахождения неизвестного значения какой-либо величины по нескольким известным ее значениям и, может быть, по нескольким значениям других величин, с нею связанных (например, ее производных). Без дополнительных предположений о функции Предположим, что рассматривается множество Относительно функций 1) функции известны при всяких 2) с увеличением 3) при всяком 4) для всякой функции
(это условие обеспечивает возможность равномерного на 5) параметры Если
где Система (7.2.4) имеет единственное решение тогда и только тогда, когда ее определитель Последовательности функций Часто в качестве функций Система (7.2.4) в этом случае имеет вид: а ее определитель является определителем Вандермонда
который отличен от нуля для любых несовпадающих узлов
Таким образом, если удачно расположить узлы на Решим систему (7.2.7) по правилу Крамера. Тогда где Найденные таким образом параметры где
Таким образом,
Константу
Тогда и Таким образом получим функцию, которая называется интерполяционным многочленом Лагранжа и обозначается
Обозначим через
Тогда многочлен Лагранжа запишется в виде: Интерполяция многочленом Лагранжа имеет существенный недостаток: если выяснится, что полученная точность интерполирования недостаточна и для улучшения точности потребуется увеличить число узлов, то все вычисления придется проделать заново. От этого недостатка избавлен другой интерполяционный многочлен – многочлен Ньютона. Введем следующие обозначения: разностными отношениями первого порядка назовем величины
разностными отношениями второго порядка -
и т.д., и разностными отношениями Разностные отношения являются симметрическими функциями своих аргументов и
Для построения многочлена Ньютона запишем многочлен Лагранжа
Разность
Константу
Тогда Подставляя полученное выражение в (7.2.12) для
Несмотря на более сложное строение, формула Ньютона удобнее для вычислений, чем формула Лагранжа, так как позволяет не фиксировать заранее число узлов, а подключать новые узлы до тех пор, пока не будет достигнута требуемая точность вычислений. Величина остатка или погрешности интерполирования зависит от свойств функции где
то Для того, чтобы погрешность в (7.2.16) была наименьшей, необходимо выбрать узлы интерполирования таким образом, чтобы значение Многочлены Чебышева обладают следующими свойствами: 1) они являются алгебраическими многочленами соответствующей степени, так как 2) коэффициент при старшей степени 3) области определения и изменения многочленов Чебышева равны 4) многочлены 5) многочлены 6) они являются четными или нечетными в зависимости от
7) многочлены Чебышева ортогональны с весом
8) графическое представление многочленов Чебышева совпадает с проекциями синусов, нанесенных на цилиндр; 9) многочлены Чебышева являются наименее отклоняющимися от нуля, так как
при этом справедливо утверждение, что какой бы другой многочлен
Таким образом, для того чтобы значение Тогда для оценки погрешности будет верно неравенство: Если интерполирование производится на интервале можно перевести в интервал Достаточно часто при интерполировании приходится иметь дело с равноотстоящими узлами. Тогда полагают: В этом случае интерполяционные формулы можно значительно упростить, если ввести понятие конечных разностей. Конечной разностью
где
Так как узлы, лежащие вблизи точки интерполирования
Формула Ньютона для интерполирования вперед Пусть точка при этом, если это возможно, за
Если ввести новую переменную
и учитывая, что
получим
Эта формула называется формулой Ньютона для интерполирования вперед.
Формула Ньютона для интерполирования назад Пусть точка
Введем новую переменную
Интерполяционные формулы Гаусса Если точка интерполирования
Тогда, после введения новой переменной
Если точка
и, после введения переменной
Если функция Пусть значения
то абсолютная погрешность разностей первого порядка равна
то максимальный порядок разностей, которые ведут себя правильно, равен Сплайн-функции
Пусть на отрезке Сплайном называется составная функция
Рассмотрим частный случай, когда функции
где Максимальная по всем частичным отрезкам степень многочлена называется степенью сплайна, а разность между степенью сплайна и порядком наивысшей непрерывной на Среди существующих сплайнов наиболее широкое распространение получили сплайны следующих типов: линейные, параболические, кубические, В-сплайны. Рассмотрим алгоритмы построения коэффициентов трех первых из перечисленных сплайнов.
Линейный сплайн Сплайн Параметры сплайна Обозначим
и для определения коэффициентов линейного сплайна (7.2.29) получим уравнения:
Параболический сплайн Сплайн Для определения коэффициентов сплайна дополнительно к условиям (7.2.30), (7.2.31) потребуем непрерывности первой производной сплайна на интервале Обозначив получим:
Тогда коэффициенты Если теперь записать выражения для где Таким образом, уравнения (7.2.37), (7.2.40) и (7.2.41) образуют систему из или Если подставить в (7.2.44) выражение для
где
Тогда и Таким образом, параметры параболического сплайна вычисляются в следующем порядке: сначала в обратном порядке вычисляются коэффициенты
Кубический сплайн Сплайн
Для определения параметров сплайна потребуем дополнительно к (7.2.30), (7.2.31), (7.2.35) выполнения условия непрерывности второй производной: Первая и вторая производные отдельных многочленов сплайна соответственно равны: Тогда, обозначив
Последние два уравнения получены из (7.2.35) и (7.2.48). Уравнения (7.2.51)–(7.2.54) составляют систему из Тогда из (7.2.55) следует а из (7.2.56) получим: Из уравнения (7.2.54) выразим и, подставляя его в (7.2.52), с учетом (7.2.51), получим Если выражения для где Уравнения (7.2.61) образуют систему из и вектором свободных членов Решение таких систем осуществляется методом прогонки, согласно которому решение представляют в виде: где При этом, учитывая (7.2.57), полагают Таким образом, порядок вычисления коэффициентов кубического сплайна следующий: сначала определяют коэффициенты Полиномиальные сплайны имеют ряд существенных недостатков: 1) при увеличении степени составных многочленов вычисление их коэффициентов значительно усложняется из-за увеличения числа уравнений (условий непрерывности функций и их производных); 2) требуется достаточно большой объем памяти для хранения информации о сплайне (точек разбиения От этих недостатков в значительной мере избавлен другой вид сплайнов, который основан на базисных функциях и называется В-сплайном. Численное дифференцирование
К численному дифференцированию приходится прибегать в том случае, когда функция В тех случаях, когда численное дифференцирование неприменимо, вместо функции Пусть требуется найти производную функции Функцию и, дифференцируя это тождество Так как за приближенное значение Если табличные значения являются равноотстоящими, то есть где Для вычисления второй производной в случае, если точка Аналогично можно получить выражения для вычисления производных и более высоких порядков. Кроме того, можно использовать и другие подходы для вычисления значений производных функций, заданных таблично, например, метод неопределенных коэффициентов. Заметим, что замена производных разностными отношениями типа (7.3.4) и (7.3.5) часто используется при моделировании задач математической физики.
Численное интегрирование
Будем рассматривать задачу вычисления интеграла при помощи некоторого числа значений интегрируемой функции. Достоинство этого метода состоит в его простоте и универсальности. Пусть по где Правила вычисления интегралов в большинстве своем являются специализированными, предназначенными для численного интегрирования функций, имеющих те же особенности, что и весовая функция Метод Гаусса
Достаточно часто для решения систем с действительными элементами используется метод Гаусса (метод исключения неизвестных). Этот метод осуществляет приведение исходной системы к эквивалентной системе с правой треугольной матрицей (схема единственного деления) или с диагональной матрицей (схема оптимального исключения). При этом не требуется заранее определять, имеет или нет решение данная система. Рассмотрим схему единственного деления. Систему Будем считать выбор порядка преобразования, в котором исключаются неизвестные, произвольным. Выберем какое-либо уравнение и неизвестное в этом уравнении. Единственное условие, которое должно быть выполнено при этом выборе, состоит в том, что коэффициент при выбранном неизвестном должен быть отличным от нуля. Переставляя, если необходимо, уравнения и меняя местами неизвестные, можно считать, что выбрано первое уравнение, неизвестное где
Исключим где К полученной системе применим такое же преобразование, т.е. выберем уравнение и неизвестное с коэффициентом, отличным от нуля, приведем этот коэффициент к единице, исключим неизвестное из прочих уравнений и так до тех пор, пока такие преобразования возможны. В результате придем к одной из двух ситуаций. 1. После Решение полученной системы осуществляется снизу вверх следующим образом: 2. После шага преобразований Тогда, если среди элементов Приведение системы к виду (7.6.31) называется прямым ходом метода Гаусса, а нахождение ее решения (7.5.32) – обратным. Заметим, что на каждом шаге прямого хода метода Гаусса выбирается уравнение и неизвестное, подлежащие исключению из прочих уравнений. Это равносильно выбору коэффициента для очередного шага преобразований. Этот коэффициент называется ведущим и он должен быть отличным от нуля. Во избежание большой потери точности рекомендуется осуществлять такую перестановку уравнений, чтобы ведущий коэффициент являлся либо максимальным по модулю коэффициентом во всей системе, либо максимальным по модулю коэффициентом в выбранном уравнении. Такая процедура называется методом Гаусса с выбором главного элемента. Метод Гаусса применим к вычислению определителей и обратных матриц. Так, значение определителя а вычисление обратной матрицы осуществляется одновременным решением где
Правило Рунге
Функция где Если главный член погрешности можно записать в виде Рассмотренные методы имеют порядок погрешности на шаге, равный Оценка погрешности методов Эйлера и Рунге-Кутта затруднительна. Грубую оценку погрешности можно получить, используя правило Рунге. Пусть
Тогда справедливы следующие равенства:
Приравнивая правые части этих равенств, получим:
и Таким образом, грубую оценку погрешности на интервале · для метода Эйлера · для метода Рунге-Кутта Кроме того, для контроля правильности выбора шага
Основные понятия цифровых систем управления
Включение ЭВМ в контур управления неизбежно создает особые условия его реализации, основными из которых являются: дискретность формируемого управления по времени и запаздывание подачи управляющего воздействия на приводы рулевых органов по отношению к моменту выдачи измерительной системой всей необходимой информации. Такие системы управления оперируют только с цифровой информацией и называются цифровыми системами управления. Цифровую систему управления непрерывным объектом с замкнутой обратной связью схематично можно изобразить следующим образом (рис. 8.3.1):
Рис. 8.3.1 Работа системы управления синхронизируется в ЭВМ таймером реального времени, который определяет момент поступления информации об объекте и момент воздействия управляющего сигнала на объект. При этом состояние объекта измеряется только в дискретные моменты времени. На входе в систему управления непрерывный вектор состояния Момент времени, в который происходит преобразование непрерывной информации в дискретную, называется моментом квантования управляющего воздействия и обозначается Квантование – неизбежный процесс в цифровых системах управления, обусловленный дискретной природой самих ЭВМ. Будем полагать, что для управления исходным непрерывным объектом используется цифровая система, формирующая кусочно-постоянный вектор управления
Основные понятия адаптивных систем управления
Наиболее существенными являются следующие признаки деления принципов адаптации: 1. По уровню априорной неопределенности: а) параметрическая адаптация, при которой априорная неопределенность заключается в недостаточном знании параметров (коэффициентов) управляемого объекта; б) непараметрическая адаптация, при которой априорная неопределенность не связана непосредственно с какими-либо параметрами. В обоих случаях неопределенность уменьшается на основе последовательных наблюдений входных и выходных данных в процессе управления. 2. По организации процесса адаптации: а) поисковые, для которых характерны процессы итеративного движения к достижению требуемого качества управления; б) беспоисковые, основанные на использовании некоторых необходимых (достаточных) условий требуемого качества управления. У систем поисковой адаптации формируются специальными устройствами детерминированные или случайные пробные сигналы или создаются условия для возбуждения в объекте незатухающих колебаний, используемые как поисковые. Наличие пробных движений является основным недостатком поисковой адаптации, так как они не всегда допустимы по условиям функционирования объекта. 3. По целям организации адаптации: а) системы со специальными свойствами, в результате функционирования которых управляемый процесс приобретает некоторые обязательные свойства, в число которых могут быть включены устойчивость, чувствительность к каким-либо возмущениям или ошибкам априорной информации, заданное расположение корней характеристического уравнения и т.д.; б) оптимальные системы, обеспечивающие минимизацию некоторых функционалов, отражающих качество управляемого движения. Наиболее перспективными для создания цифровых систем управления являются оптимальные беспоисковые системы с параметрической адаптацией, в которых на основе полученной в процессе функционирования объекта информации о самом объекте и возмущающих воздействиях осуществляется автоматическая настройка параметров модели объекта. При этом используется «принцип разделения», согласно которому формирование адаптивного управления состоит из трех этапов: выбор алгоритма управления в предположении, что параметры модели объекта известны точно (оптимальное управление); оценивание неизвестных параметров (идентификация) и состояния (фильтрация) модели объекта; формирование адаптивного управления посредством замены точных значений параметров и состояния на их оценки.
Примеры построения математических моделей
К объектам управления, поведение которых описывается обыкновенными дифференциальными уравнениями, относятся все механические, электромеханические объекты, а также многие технологические процессы, подчиняющиеся законам механики и электричества. Кроме того, такими уравнениями можно описать и многие макро- и микроэкономические процессы. При проектировании систем управления одной из основных задач, которую необходимо решить первой, - это построение математических моделей, описывающих управляемый объект или процесс. Качество функционирования системы управления будет существенно зависеть от того, насколько адекватной является построенная модель. Языки программирования Язык Fortran
Язык Fortran (от англ. Formula Translation) – один из первых языков программирования, появившийся еще в 50-х годах. В то время было разработано множество библиотек, в том числе математических, ориентированных на этот язык. Несмотря на то, что язык оказался не слишком удобным в использовании, он довольно прочно занял свою нишу для разработки математических программ, в первую очередь для моделирования. С тех пор язык претерпел несколько редакций (последняя – в 95-м году) и существует большое множество различных версий компилятора этого языка. Среди современных реализаций для персональных компьютеров следует отметить Microsoft Visual Fortran. Как следует из названия языка, основное его предназначение – перевод формул. И с этой работой он справляется достаточно успешно. К недостаткам этого языка следует отнести слабые возможности по описанию абстрактных типов данных, неудобную организацию циклов и других языковых конструкций. Язык С
Язык С, появившийся в первой половине 70-х годов прошлого столетья в лаборатории Bell Labs компании AT&T [Керниган&Ритчи], является в настоящее время де-факто стандартом для разработки программ системного назначения малого и среднего размеров. В настоящее время реализация этого языка есть практически для всех вычислительных систем от микроконтроллеров до сверхбольших вычислительных машин. Понятие «среднего размера» весьма относительно и, как правило, соответствует проектам от 10 до 100 тысяч строк исходного текста. Под «системными» понимаются программы, предназначенные, в основном, для нужд операционной системы (в том числе и сама операционная система является системной программой). Однако этот язык вполне подходит и для разработки прикладных программ, в том числе связанных с математическими вычислениями. Изюминка языка C - в его относительной близости к вычислительной системе, что позволяет разрабатывать высокоэффективный код (с минимальными накладными расходами, а соответственно, максимальный по скорости выполнения и минимальный по расходу памяти). Язык C обладает набором из 50 операций (как целочисленных, так и вещественных), распределённых по 15 уровням приоритетов. Среди математических операций языка собраны все операции, которые можут выполнить центральный процессор и математический сопроцессор. Часть операций применима как к целым типам данных, так и к вещественным. Язык не обладает встроенным понятием модуля, но, как правило, среда разработки (или по-другому – окружение языка) позволяет ввести это понятие искусственно и использовать как большое количество стандартных библиотек, так и свои собственные разработанные библиотеки. Более того, язык не обладает собственными средствами ввода/вывода, все эти средства реализуются внешними библиотеками, что позволяет разрабатывать более гибкий исходный код программ, применимый для различного операционного окружения языка и исполняемой программы. Недостатки языка являются обратной стороной его достоинств. К ним можно отнести отсутствие встроенных типов данных высокой степени абстракции (например, «строка», часто применимого для организации диалога с пользователем), отсутствие средств диагностики (контроль выхода за пределы массива, переполнения стека и числа и т.д.). Такой контроль можно обеспечить лишь, связавшись на низком уровне с операционной системой, при условии, что операционная система поддерживает такой контроль. Таким образом язык С хорошо подходит для разработки низкоуровневых системных библиотек и для математического моделирования. 10.1.3 Язык С++
Язык C++, разработанный в первой половине 80-х годов, как объектно-ориентированное (ОО) развитие языка C, Бьярном Страуструпом, занимает несколько иную нишу. В отличие от языка C, программы, скомпилированные с языка C++, обладают, как правило, немного худшей производительностью и большим объёмом исполняемого кода. Основная ниша данного языка – разработка больших (обычно прикладных) программных систем сравнительно большой группой разработчиков, распределённой в пространстве и/или времени. Основное преимущество данного языка – языковая поддержка 3-х базисных конструкций ОО программирования: инкапсуляция, полиморфизм и наследование. Под инкапсуляцией понимается разделение реализации объекта (модуля) и его интерфейса. Как правило, скрываются данные, а в интерфейсе остаются только методы их обработки. Поэтому инкапсуляцию иногда трактуют как объединение данных и методов их обработки в единой языковой конструкции. При решении задач моделирования это позволяет создавать типы данных высокой степени абстракции. Такие, например, как вектора, матрицы, генераторы, фильтры и так далее. Фактически, любое понятие предметной области (ПО) можно рассматривать как объект с точки зрения ОО программирования и строить соответствующую ему модель с детерминированным набором свойств и поведением. В языке C++ для поддержки инкапсуляции вводят понятия «объект» и «класс», который представляет собой обобщенное описание объекта. Язык C++ позволяет, используя еще одну языковую конструкцию – наследование, создавать обобщенные (базовые) классы, описывая в них общую составляющую всех дочерних классов. Это позволяет упростить процесс доработки программ, который теперь можно сводить не к переделке всего разработанного ранее класса. Для изменения набора свойств и/или расширения функциональности можно описать новый класс, наследованный от созданного ранее. Еще одной принципиальной с точки зрения ОО программирования возможностью языка является полиморфизм. Это понятие определяется как возможность указания разной семантической нагрузки для конструкций с одинаковым синтаксисом. Например, пусть есть классы «вектор» и «матрица». Оба этих класса имеют метод «абсолютное значение», который имеет схожий синтаксис (на входе объект, на выходе вещественное число), но внутренняя реализация этих методов принципиально различна. Тем не менее, вполне вероятно, что некоторая функция может работать с любым типом данных, если тот обладает методом вычисления абсолютного значения. Можно разработать такой метод для всех типов данных, с которыми будет работать Ваша программа, но при этом возникнет большая степень дублированности кода. С другой стороны, можно разработать некоторый базовый класс, в котором перечислены все основные свойства и методы большой группы классов. При этом часть методов могут быть описаны, как виртуальные, что позволяет давать этим методам разную реализацию в дочерних классах. Еще одной возможностью языка C++ является возможность описания шаблонов функций и классов (так называемое параметризованное описание). Параметром такого описания является, как правило, тип (или набор типов), с которым работает данная функция или класс. Это позволяет создавать более высокоэффективные (по сравнению с наследованием) программы. Кроме того, язык C++, один из немногих, позволяет перегружать смысл своих операций для абстрактных типов данных. Таким образом, можно получить набор типов (классов), максимально приближенный к аналогичным объектам в математике, например, класс матрица или вектор. Совместное использование всех языковых конструкций позволило создать весьма эффективную, но в то же самое время очень гибкую стандартную библиотеку шаблонов (standard template library – STL), включающую все основные способы хранения данных и базовые алгоритмы обработки этих данных. Существует построенная на этой библиотеке, например, библиотека MTL (matrix template library – библиотека шаблонов матрицы), которая позволяет достаточно эффективно обрабатывать матрицы произвольной размерности с произвольным типом хранимых данных. К сожалению, богатая история развития языка C++ привела к появлению огромного количества разночтений и, фактически, различных диалектов этого языка. Усилия консорциума разработчиков привели к тому, что в 1998 г. был утвержден стандарт этого языка. Однако далеко не все существующие компиляторы языка С++ совместимы с этим стандартом. Borland Delphi
В основе этой системы программирования лежит сильно модифицированный фирмой Borland язык Object Pascal. Язык изменен настолько сильно, что правильнее его называть языком Delphi. Первая версия этой среды разработки была ориентирована на ОС Windows 3.x и в то время стала прорывом в области разработок программ с интерфейсом пользователя. Основная ниша этой среды разработки – разработка клиентских программ для баз данных. Для этого в системе разработки программ предусмотрены богатые возможности по разработке интерфейса и несколько различных вариантов доступа к базам данных. 10.2.3 Borland C++Builder
Эта система разработки распространена значительно меньше предыдущей. Однако она имеет ряд принципиальных преимуществ, которые позволяют о ней говорить как о реально используемой платформе. В частности, компилятор C++, на базе которого построена эта система, очень близок к стандарту языка (вообще говоря, начиная с 5-й версии, Borland C++Builder получил сертификат соответствия стандарту, хотя на самом деле небольшие отличия есть). Все специализированные средства языка (которых нет в стандарте) являются расширениями и не противоречат стандарту. В основу положена та же библиотека, которая лежит в основе системы Delphi. И соответственно, эта система обладает всеми теми же возможностями, добавляя возможности, присущие стандарту языка C++. К недостаткам следует отнести сравнительно большой объем исполняемого кода и несколько худшие (по сравнению с Visual C++) скоростные показатели для программ графического интерфейса. Система Maple
Системы компьютерной математики класса Maple были созданы корпорацией Waterloo Maple, как система компьютерной алгебры с расширенными возможностями в области символьных вычислений. Система содержит средства для выполнения быстрых численных расчетов, лежащих в основе математического моделирования различных явлений окружающего мира, систем и устройств различного назначения. Все это сочетается с новейшими и весьма эффективными средствами визуализации вычислений. Maple - типичная интегрированная система. Она объединяет в себе мощный язык программирования (он же язык для интерактивного общения с системой), редактор для подготовки и редактирования документов и программ, многооконный пользовательский интерфейс с возможностью работы в диалоговом режиме, справочную систему с тысячью примеров, ядро алгоритмов и правил преобразования математических выражений, численный и символьный процессоры, систему диагностики, библиотеки встроенных и дополнительных функций, пакеты функций сторонних производителей и поддержку некоторых других языков программирования и программ. Ко всем этим средствам имеется полный доступ прямо из окна системы. Она реализована на больших ЭВМ, ПК класса IBM PC, Macintosh и др. Ядро системы Maple используется целым рядом систем компьютерной математики, например, таких, как MatLAB и MathCAD. Система Mathematica
Система Mathematica разработана фирмой Wolfram Research. Основная идея разработчиков – объединить все известные понятия и методы математики в единую универсальную систему, способную функционировать на любой вычислительной платформе. Эта система дает возможность решать большое количество достаточно сложных задач, не вдаваясь в тонкости программирования, что привело к её широкому использованию в таких науках, как физика, биология, экономика и т.д. Система Mathematica состоит из двух частей – ядра, которое, собственно, и проводит вычисления, выполняя заданные команды, и интерфейсного процессора, фактически задающего внешнее оформление и характер взаимодействия с пользователем и программой. Пользователь записывает все выкладки в основном рабочем документе программы – notebook («записная книжка»). Внешний вид рабочего документа на экране монитора в большей или меньшей степени зависит от типа платформы (Windows, Macintosh, Unix) и определяется интерфейсным процессором, своим для каждой платформы. Notebook - полностью интерактивный документ, содержащий текст, таблицы, графики, вычисления и другие элементы. Документы могут быть представлены на экране с различным полиграфическим исполнением, могут включать в себя всевозможные математические или специальные символы. Однако внутреннее представление документов, с которыми работает ядро программы, всегда – не форматируемый текст в виде печатаемых (printable) 7-битовых ASCII-символов. Это позволяет легко переписывать документы с одной платформы на другую. Язык программирования Mathematica рассматривается как единый универсальный язык программирования и математики. Он является беспрецедентно гибким и интуитивным языком, содержит уникальную комбинацию математических и вычислительных обозначений. Основная унифицирующая идея языка - рассматривать любой объект как символьное выражение (это касается не только привычных структур данных, но и графиков, звуков и даже ячеек, и даже самого документа). Это делает легким добавление к системе Mathematica новых конструкций языка и изменения интерфейса программы. Язык включает в себя представление широко известных развитых методов программирования компьютерной науки и добавляет множество новых. На языке программирования можно всегда написать программу в наиболее естественном виде, так как Mathematica включает в себя множество парадигм программирования: процедурное программирование; основанное на операциях со списками (list-based); основанное на операциях со строками (string-based); функциональное; объектно-ориентированное; программирование, задающее правила преобразования выражений («правила переписывания термов»). В виде встроенных функций реализовано большое множество высокоинтеллектуальных математических операций. В состав Mathematica входят стандартные дополнения, включающие в себя подпрограммы (пакеты), которые значительно расширяют функциональные возможности системы в таких областях, как алгебра, аналитические и численные расчеты, графика, дискретная математика, геометрия, теория чисел, статистика и др. Система MatLAB
Лидером в области численных и матричных расчетов, а также реализации техники имитационного и ситуационного моделирования является система MatLAB с ее многочисленными пакетами расширения. Однако в области аналитических вычислений она сильно уступает таким системам, как Maple и Mathematica. Система MatLAB (сокращенно от MATrix LABoratory - Матричная лаборатория) разработана фирмой Math Works. Это интерактивная система, ориентированная в первую очередь на обработку массивов данных, базируется на матричных математических операциях. Даже одиночное число MatLAB рассматривает как матрицу, что позволило существенно повысить скорость выполнения вычислений. С точки зрения пользователя MatLAB представляет собой богатейшую библиотеку функций. Для облегчения поиска библиотека функций разбита на разделы. Те из функций, которые носят более общий характер и используются наиболее часто, входят в состав ядра MatLAB. Те функции, которые являются специфическими для конкретной области, включены в состав соответствующих специализированных разделов. Эти разделы называются MatLAB Toolboxes (Инструменты). Каждый из них имеет свое собственное название, отражающее его предназначение. Полная комплектация системы MatLAB содержит более 30 инструментальных приложений. В их число входят как достаточно стандартные для математических пакетов средства, так и нетрадиционные: средства цифровой обработки изображений, поиска решений на основе нечеткой логики, аппарат построения и анализа нейронных сетей, средства финансового анализа и др. Кроме того, имеются средства взаимодействия с офисными продуктами фирмы Microsoft - MS Word и MS Excel. К несомненным достоинствам системы MatLAB следует отнести тот факт, что она базируется на современных математических подходах, имеющих непосредственный выход в практику проектирования технических систем, например таких, как теория робастности и др. Особое место среди инструментальных приложений занимает система визуального моделирования SIMULINK. В определенном смысле SIMULINK можно рассматривать как самостоятельный продукт фирмы Math Works, однако он работает только при наличии ядра MatLAB и использует многие функции, входящие в его состав. MatLAB является платформно-независимой системой, так как может работать под управлением нескольких операционных систем: Windows, UNIX, MacOS. При этом технология моделирования с помощью SIMULINK остается неизменной. Система MathCAD
Система MathCAD разработана фирмой MathSoft. Она существенно отличается от аналогичных прикладных систем, таких, как MatLAB, Mathematica, Maple, тем, что является единственной прикладной системой, в которой описания математических задач и их решений задаются с помощью обычных в математике символов, формул и операторов, а документ MathCAD выглядит как страницы учебника или научной статьи. MathCAD - это популярная система компьютерной математики, предназначенная для решения математических задач в самых разных областях науки, техники и образования. Ранние версии MathCAD вообще не имели средств обычного программирования, а имели лишь средства визуально-ориентированного программирования в виде шаблонов математических операций, из которых составлялись математические выражения. Возможность задания программных модулей появилась, начиная с версии MathCAD PLUS 6.0. Программные модули, в сущности, являются функциями, но описанными с применением программных средств. Последние версии MathCAD допускают применение внешних расширений: электронных книг, пакетов расширений и библиотек. Внешние библиотеки чаще всего являются справочниками. Пакеты расширений и сопровождающие их электронные книги имеют различное назначение и ориентированы, как правило, на выполнение узкоспециальных вычислений. Пакеты расширений предоставляют следующие возможности: осуществлять вейвлет преобразования, анализ временных рядов, финансовые расчеты, обработку сигналов и изображений, расчеты по прикладной статистике, механике, дифференциальным уравнениям и т.д. Существенными дополнениями к системе являются пакеты расширения графических возможностей, численных методов. В MathCAD возможна интеграция с текстовым процессором Word, электронными таблицами Excel, графической системой Axum, пакетом научной и инженерной графики Visio, с пакетом SmartSketch LE, который позволяет включать в состав документов MathCAD довольно сложные конструкторские чертежи, с пакетом VisSim - моделирующей программой, в которой объекты задаются блоками, между которыми указываются дополнительные связи. Привычный вид математических формул, встроенный язык программирования, широкие возможности в отображении графической информации, представление текстовых комментариев с использованием любых символов, доступных в Windows, возможность проводить расчеты любой сложности и готовить документы высокого качества - все это характеризует систему MathCAD.
Система STATISTICA
Программная система STATISTICA разработана фирмой Copyright StatSoft. Это современный пакет для статистического анализа данных, в котором реализованы все новейшие компьютерные и математические методы анализа данных. Это - описательные статистики; анализ многомерных таблиц; многомерная и нелинейная регрессии; подгонка распределений; дискриминантный, кластерный, факторный, дисперсионный и ковариационный анализы; структурные модели; прогнозирование временных рядов; непараметрическая статистика; анализы надежности предпочтений, Монте-Карло, выживаемости и т.д. Система STATISTICA подходит для применения в любой области: маркетинге, финансах, страховании, бизнесе, промышленности, медицине и т.д. Система EXCEL
Табличный процессор EXCEL входит в самый популярный пакет автоматизации офисной деятельности Microsoft Office. EXCEL - одна из самых мощных и гибких систем обработки электронных таблиц. Эта система может работать не только с двумерными, но и с трехмерными таблицами, представленными листами с двумерными таблицами. EXCEL широко используется для подготовки прекрасно иллюстрированных финансово-экономических и других документов. Этот процессор содержит сотни математических и экономических функций, что позволяет решать множество задач в области естественных и технических наук. Возможности системы EXCEL можно использовать для анализа внешних данных, представленных в Microsoft FохPro, Access, Paradox, dBASE, SQL Server, а также базы данных сторонних производителей, поддерживающих технологию OLE (Object Linking and Embedding - связывания и внедрения объектов). В системе EXCEL можно создавать макросы и приложения с помощью Visual Basic for Applications (VBA). Visual Basic for Applications - это среда разработки приложений на базе программ, входящих в пакет Microsoft Office. Одно из главных достоинств языка Visual Basic for Applications заключается в том, что созданные средствами EXCEL VBA-макросы можно без труда использовать в других программах фирмы Microsoft.
Литература
1. Андреев Ю.Н. Управление конечномерными линейными объектами. - М.: Наука, 1976. - 424 с. 2. Брайсон А., Хо Ю-Ши. Прикладная теория оптимального управления. - М.: Мир, 1972. - 544 с. 3. Браммер К., Зиффлинг Г. Фильтр Калмана-Бьюси. - М.: Наука, 1982. - 200 с. 4. Буков В.Н. Адаптивные прогнозирующие системы управления полетом. - М.: Наука, 1987. - 232 с. 5. Горский А.А., Колпакова И.Г., Локшин Б.Я. Динамическая модель процесса производства, хранения и сбыта товара повседневного спроса Изв. РАН Теория и системы управления. - 1998. - №1. - С. 144–148. 6. Дорф Р., Бишоп Р. Современные системы управления. - М.: Лаборатория базовых знаний, 2002. - 832 с. 7. Красовский А.А., Буков В.Н., Шендрик В.С. Универсальные алгоритмы оптимального управления непрерывными процессами. - М.: Наука, 1977. - 272 с. 8. Крылов В.И., Бобков В.В., Монастырный П.И. Вычислительные методы. Том I. - М.: Наука, 1976. - 304 с. 9. Крылов В.И., Бобков В.В., Монастырный П.И. Вычислительные методы. Том II. - М.: Наука, 1976.- 400с. 10. Летов А.М. Аналитическое конструирование регуляторов. - Автоматика и телемеханика. - 1960. - №1. - С. 436–441; 1960. - №5. - С.561–568; 1960. - №6. - С. 661–665; 1960 - №4. - С. 425–435; 1962. - №11. - С. 1405–1413. 11. Медич Дж. Статистически оптимальные линейные оценки и управление. - М.: Энергия, 1973. - 440 с. 12. Мудров А.Е. Численные методы для ПЭВМ на языках Бейсик, Фортран и Паскаль. - Томск: МП «РАСКО», 1991. - 272 с. 13. Острем К., Виттенмарк Б. Системы управления с ЭВМ. - М.: Мир, 1987. - 480 с. 14. Решетникова Г.Н. Синтез и моделирование дискретных адаптивных систем (гос. Регистр. №50880000594) Алгоритмы и программы: Информационный бюллетень. - 1989. - №1. - С. 10. 15. Решетникова Г.Н., Смагин В.И.. Адаптивное управление по локальным и квазилокальным критериям: Учебное пособие по курсу «Адаптивные системы». - Томск: ТГУ,1993. - 27 с. 16. Смагин В.И., Параев Ю.И. Синтез следящих систем управления по квадратичным критериям. - Томск: Изд-во Том. ун-та, 1996. - 171 с. 17. Советов Б.Я., Яковлев С.А. Моделирование систем: Учебник для вузов. - 3-е изд., перераб. и доп. - М.: Высш. шк., 2001. - 343 с. 18. Справочник по теории автоматического управления Под ред. А.А.Красовского. - М.: Наука, 1987. - 712 с. СОДЕРЖАНИЕ
Предисловие. 6 7 ЧИСЛЕННЫЕ МЕТОДЫ МОДЕЛИРОВАНИЯ.. 7 7.1 Элементы теории погрешности. 8 7.2 Приближение данных функциями. 11 7.2.1 Интерполирование. 12 7.2.2 Сплайн-функции. 23 7.2.3 Аппроксимация данных методом наименьших квадратов 28 7.3 Численное дифференцирование. 36 7.4 Численное интегрирование. 38 7.4.1 Интерполяционные квадратурные формулы.. 39 7.4.2 Квадратурные формулы наивысшей алгебраической степени точности. Квадратурные формулы Гаусса. 45 7.5 Решение нелинейных уравнений и систем.. 48 7.5.1 Решение нелинейных уравнений. 49 7.5.2 Метод Лобачевского при решении алгебраических уравнений 58 7.5.3 Решение систем нелинейных уравнений. 63 7.6 Решение задач матричной алгебры.. 64 7.6.1 Некоторые понятия матричной алгебры.. 65 7.6.2 Обусловленность систем и матриц. 69 7.6.3 Метод Гаусса. 73 7.6.4 Итерационные методы решения систем линейных алгебраических уравнений. 75 7.6.5 Метод Данилевского при решении полной проблемы собственных значений. Построение канонической формы Фробениуса 80 7.7 Решение обыкновенных дифференциальных уравнений и систем 84 7.7.1 Методы Эйлера и Рунге-Кутта при решении задачи Коши для дифференциального уравнения первого порядка. 85 7.7.2 Правило Рунге. 87 7.7.3 Методы Эйлера и Рунге-Кутта при решении задачи Коши для систем дифференциальных уравнений. 89 7.7.4 Решение задачи Коши для систем линейных дифференциальных уравнений. 90 7.7.5 Методы Адамса при решении задачи Коши для обыкновенных дифференциальных уравнений. 91 7.7.6 Метод сеток решения линейных краевых задач. 93 7.7.7 Метод коллокации решения краевых задач. 96 8 Моделирование систем управления.. 99 8.1 Описание систем в пространстве состояний. 99 8.2 Аналитическое конструирование оптимальных регуляторов 103 8.2.1 Оптимальное управление при минимизации классического квадратичного функционала. 105 8.2.2 Оптимальное управление при минимизации функционала обобщенной работы.. 107 8.2.3 Оптимальное управление при минимизации локального квадратичного критерия. 111 8.2.4 Синтез следящей системы управления. 112 8.3 Моделирование систем оптимального управления. 114 8.3.1 Основные понятия цифровых систем управления. 114 8.3.2 Моделирование поведения управляемого объекта. 116 8.3.3 Синтез оптимального управления. 119 8.4 Моделирование систем управления при случайных внешних воздействиях. 124 8.4.1 Моделирование поведения объекта при наличии внешних возмущений. 124 8.4.2 Описание математической модели измерительного комплекса 126 8.4.3 Оценивание состояния модели объекта. 127 8.4.4 Синтез управляющих воздействий по оценкам состояния 131 8.5 Синтез адаптивной следящей системы.. 134 8.5.1 Основные понятия адаптивных систем управления. 135 8.5.2 Одновременное оценивание состояния и параметров модели объекта 136 8.6 Учет ограничений и запаздываний по управлению.. 140 8.7 Общая схема синтеза адаптивных систем управления. 141 9 Примеры построения математических моделей 144 9.1 Построение математических моделей прямолинейного и вращательного движения. 144 9.1.1 Математическая модель прямолинейного движения. 144 9.1.2 Математическая модель вращательного движения. 146 9.2 Макроэкономическая модель динамики фондов производственного накопления и потребления. 147 9.3 Построение математических моделей производства, хранения и сбыта товара повседневного спроса. 148 10 Программные средства моделирования.. 153 10.1 Языки программирования. 154 10.1.1 Язык Fortran. 154 10.1.2 Язык С.. 154 10.1.3 Язык С++. 155 10.1.4 Языки Pascal и Object Pascal 158 10.2 Системы разработки программного обеспечения. 158 10.2.1 Microsoft Visual C++ и MFC.. 158 10.2.2 Borland Delphi 159 10.2.3 Borland C++Builder 159 10.3 Специализированные математические пакеты.. 160 10.3.1 Система Maple. 161 10.3.2 Система Mathematica. 161 10.3.3 Система MatLAB.. 163 10.3.4 Система MathCAD.. 164 10.3.5 Система STATISTICA.. 166 10.3.6 Система EXCEL. 166 Литература.. 168
Предисловие
При компьютерном моделировании возникает необходимость в численном решении достаточно большого количества разнообразных задач. В связи с этим рассматриваются основные подходы к методам решения таких задач, как приближение данных, численное дифференцирование и интегрирование, решение нелинейных уравнений и систем, решение задач матричной алгебры, решение задачи Коши и краевой для обыкновенных дифференциальных уравнений. Приводятся условия сходимости итерационных алгоритмов, обсуждаются способы реализации и обращается внимание на погрешность результата. Подробно рассматривается моделирование систем управления в пространстве состояний методами аналитического конструирования оптимальных регуляторов. При этом рассматривается формирование следящей системы адаптивного управления с неполным измерением при построении оценок состояния и параметров модели объекта дискретными фильтрами Калмана. Построение такой системы управления осуществляется путем постепенного усложнения с помощью добавления новых алгоритмов и изменения существующих. Так как одной из первых и основных задач при формировании систем управления является построение математической модели управляемого объекта, то рассматриваются примеры построения математических моделей, описывающих прямолинейное и вращательное движение, изменение фондов производственного накопления и потребления, математических моделей процессов производства, сбыта и хранения продукции. В последней главе приводятся характеристики и возможности программных средств, используемых для моделирования систем, как инструментальных, так и специализированных математических пакетов. Эта глава написана в соавторстве с Борисовым Сергеем Ивановичем, программистом ЛИСМО ТУСУР, ассистентом кафедры КСУП ТУСУР.
ЧИСЛЕННЫЕ МЕТОДЫ МОДЕЛИРОВАНИЯ
Настоящее время характеризуется резким расширением применения математики практически во всех сферах деятельности человека. Это во многом связано с созданием и быстрым развитием средств вычислительной техники. Расширение возможностей приложения математики обусловило математизацию различных разделов науки: химии, экономики, биологии, геологии, психологии, медицины, конкретных разделов техники и др. Процесс математизации состоит в построении математических моделей процессов и явлений и в разработке методов их исследования. В физике или механике, например, построение математических моделей для описания различных явлений природы и изучения этих моделей с целью объяснения старых или предсказания новых эффектов явлений являются традиционными. Современные успехи в решении таких важных для общества проблем, как атомные, космические, экономические, вряд ли были бы возможны без применения вычислительной техники и численных методов. Быстрое проникновение математики во многие области знания, в частности, объясняется тем, что математические модели и методы их исследования применимы сразу ко многим явлениям, сходным по своей формальной структуре. Часто математическая модель, описывающая какое-либо явление, появляется при изучении других явлений или при абстрактных математических построениях задолго до конкретного рассмотрения данного явления. Математические модели реальных объектов и процессов являются, как правило, достаточно сложными. Поэтому моделирование необходимо осуществлять с помощью вычислительной техники с использованием вычислительных алгоритмов. К вычислительным алгоритмам, которые используются для моделирования, предъявляются следующие основные требования: 1) реализуемость - возможность решения задачи за допустимое время; 2) экономичность – получение решения за минимальное время среди эквивалентных по точности алгоритмов; 3) отсутствие аварийных остановов ЭВМ в процессе вычислений; 4) сходимость итерационных алгоритмов, применяемых для решения конкретных задач; 5) вычислительная устойчивость – отсутствие накопления суммарной погрешности за счет влияния погрешности округления. Для решения практически каждой задачи существует несколько численных методов. Выбор метода определяется конкретной задачей и условиями ее реализации. В настоящем учебном пособии будут рассмотрены лишь некоторые численные методы, позволяющие осуществлять моделирование с помощью вычислительной техники. |
Последнее изменение этой страницы: 2019-04-10; Просмотров: 388; Нарушение авторского права страницы
 (7.1.1)
(7.1.1) и
и 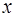 принадлежат заданным пространствам
принадлежат заданным пространствам 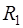 и
и 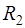 ,
,  – некоторая заданная функция. Задача состоит либо в отыскании
– некоторая заданная функция. Задача состоит либо в отыскании  , либо в отыскании
, либо в отыскании  и функции
и функции  некоторыми другими пространствами
некоторыми другими пространствами  ,
, 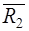 и функцией
и функцией  , при этом замена должна быть сделана таким образом, чтобы решение новой задачи
, при этом замена должна быть сделана таким образом, чтобы решение новой задачи (7.1.2)
(7.1.2) ,
,  , было в каком то смысле близким к точному решению исходной задачи и его можно было бы практически отыскать. За счет погрешности исходных данных и округления фактически была решена задача
, было в каком то смысле близким к точному решению исходной задачи и его можно было бы практически отыскать. За счет погрешности исходных данных и округления фактически была решена задача . (7.1.3)
. (7.1.3) (7.1.4)
(7.1.4)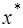 ,
,  ,
, 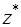 , …, а соответствующие им приближенные значения через
, …, а соответствующие им приближенные значения через  ,
,  , … .
, … . . (7.1.5)
. (7.1.5)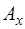 величины
величины 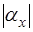 , которая может быть найдена, исходя из способа получения числа
, которая может быть найдена, исходя из способа получения числа  . (7.1.6)
. (7.1.6) величины
величины 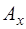 к абсолютному значению величины
к абсолютному значению величины  . (7.1.7)
. (7.1.7) - заданная функция
- заданная функция 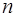 аргументов
аргументов  , по значениям которых требуется определить
, по значениям которых требуется определить  непрерывно дифференцируема в области определения своих аргументов;
непрерывно дифференцируема в области определения своих аргументов; и
и 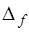 необходимо определить с небольшой точностью;
необходимо определить с небольшой точностью; (7.1.8)
(7.1.8) - некоторая точка отрезка, соединяющего
- некоторая точка отрезка, соединяющего 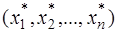 и
и  , а
, а  - частная производная функции
- частная производная функции  по
по  в точке
в точке 
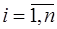 . Последнее равенство в (7.1.8) получено согласно формуле конечных приращений. Учитывая предположение относительно малости погрешностей аргументов, заменим
. Последнее равенство в (7.1.8) получено согласно формуле конечных приращений. Учитывая предположение относительно малости погрешностей аргументов, заменим 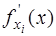 и получим:
и получим: (7.1.9)
(7.1.9) . (7.1.10)
. (7.1.10) , (7.1.11)
, (7.1.11) . (7.1.12)
. (7.1.12) . Тогда
. Тогда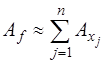 ,
,  .
. . Тогда
. Тогда ,
,  .
.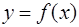 в точках
в точках 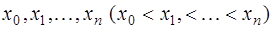 , и необходимо определить значение этой функции в некоторой точке
, и необходимо определить значение этой функции в некоторой точке 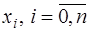 . Это типичная постановка задач интерполяции (если
. Это типичная постановка задач интерполяции (если 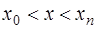 ) или экстраполяции (если
) или экстраполяции (если 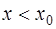 или
или 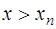 ). Точки
). Точки 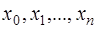 называются узлами интерполирования.
называются узлами интерполирования.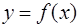 эта задача является неопределенной и за
эта задача является неопределенной и за 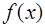 можно принять любое число, если только
можно принять любое число, если только 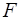 функций
функций 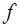 , обладающих некоторыми свойствами. Рассмотрим семейство функций
, обладающих некоторыми свойствами. Рассмотрим семейство функций 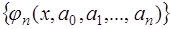 , определенных на интервале
, определенных на интервале 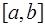 , содержащем все узлы интерполирования, и зависящих от параметров
, содержащем все узлы интерполирования, и зависящих от параметров 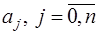 . Будем полагать, что
. Будем полагать, что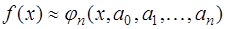 . (7.2.1)
. (7.2.1)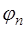 известны следующие предположения:
известны следующие предположения: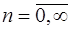 и определены на отрезке
и определены на отрезке 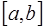 для любых значений параметров
для любых значений параметров 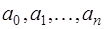 ;
;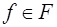 и любого числа
и любого числа 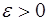 существует такое
существует такое 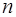 и такие значения параметров
и такие значения параметров 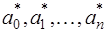 , что при всех
, что при всех 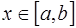 выполняется неравенство:
выполняется неравенство: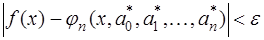
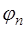 называется полным для множества
называется полным для множества 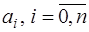 выбираются из условия совпадения функций
выбираются из условия совпадения функций 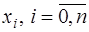 . Это приводит к системе уравнений:
. Это приводит к системе уравнений: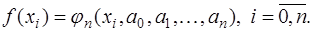 (7.2.2)
(7.2.2)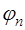 - нелинейная функция относительно
- нелинейная функция относительно 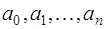 , то система (7.2.2) будет нелинейной и ее решение может быть только приближенным. Поэтому чаще всего задают функцию
, то система (7.2.2) будет нелинейной и ее решение может быть только приближенным. Поэтому чаще всего задают функцию 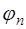 линейной относительно параметров
линейной относительно параметров 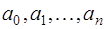 , то есть в виде:
, то есть в виде: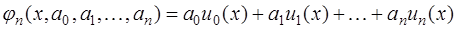 , (7.2.3)
, (7.2.3)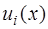 ,
, 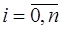 - линейно независимые координатные функции, определенные на
- линейно независимые координатные функции, определенные на  . При этом система (7.2.2) примет вид:
. При этом система (7.2.2) примет вид: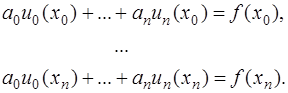 (7.2.4)
(7.2.4)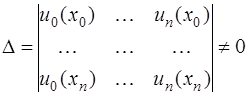 . (7.2.5)
. (7.2.5)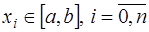 , называются последовательностями Чебышева.
, называются последовательностями Чебышева. используются алгебраические многочлены:
используются алгебраические многочлены: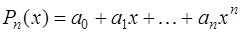 . (7.2.6)
. (7.2.6)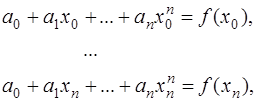 (7.2.7)
(7.2.7)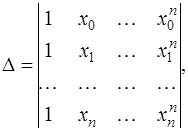
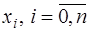 . Таким образом, система (7.2.7) имеет единственное решение и интерполирование функции
. Таким образом, система (7.2.7) имеет единственное решение и интерполирование функции 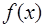 по ее значениям в узлах
по ее значениям в узлах 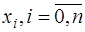 с помощью многочлена
с помощью многочлена 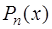 всегда возможно и единственно. Кроме того, согласно теореме Вейерштрасса, если отрезок
всегда возможно и единственно. Кроме того, согласно теореме Вейерштрасса, если отрезок 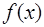 непрерывна на нем вместе с производными первых
непрерывна на нем вместе с производными первых 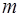 порядков, то для всякого
порядков, то для всякого 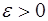 существует алгебраический многочлен
существует алгебраический многочлен 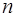 , для которого при любых
, для которого при любых 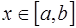 выполняются неравенства
выполняются неравенства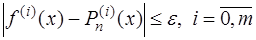 .
.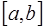 , то можно получить достаточно хорошие результаты при вычислении значений функции
, то можно получить достаточно хорошие результаты при вычислении значений функции 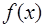 и ее производных в любой точке отрезка
и ее производных в любой точке отрезка 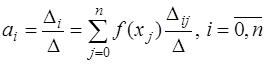 , (7.2.8)
, (7.2.8)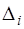 - определитель, полученный из
- определитель, полученный из 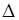 заменой
заменой 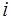 -го столбца столбцом свободных членов,
-го столбца столбцом свободных членов, 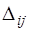 - алгебраическое дополнение для
- алгебраическое дополнение для 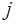 -го элемента в
-го элемента в 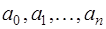 подставим в (7.2.6), приведем подобные относительно
подставим в (7.2.6), приведем подобные относительно 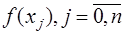 и получим:
и получим: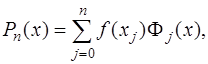 (7.2.9)
(7.2.9)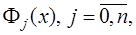 - алгебраические многочлены
- алгебраические многочлены 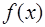 и
и 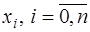 , получим:
, получим: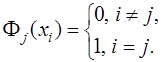
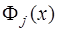 есть многочлен
есть многочлен 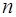 точках
точках 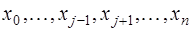 , и, следовательно, представимый в виде:
, и, следовательно, представимый в виде: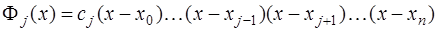 .
.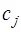 определим из условия
определим из условия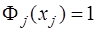 .
.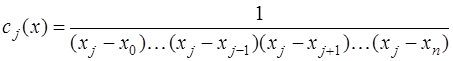
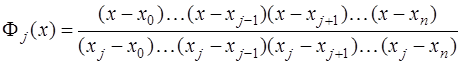 .
.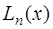 :
: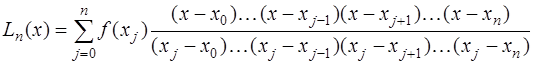 . (7.2.10)
. (7.2.10)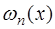 многочлен
многочлен 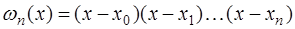 .
.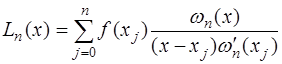 . (7.2.11)
. (7.2.11)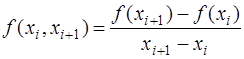 ,
,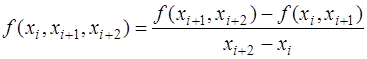
 -го порядка -
-го порядка -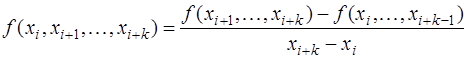 .
.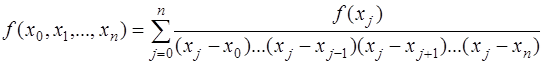 .
.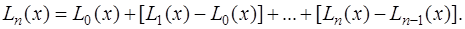 (7.2.12)
(7.2.12)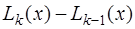 есть многочлен
есть многочлен 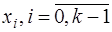 , и, следовательно, представимый в виде:
, и, следовательно, представимый в виде: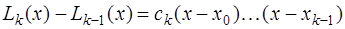 .
.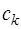 определим, полагая
определим, полагая 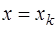 , и учитывая, что
, и учитывая, что 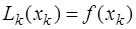 , то есть
, то есть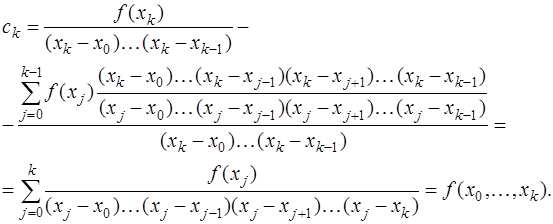
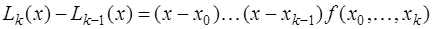 .
.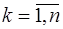 , получим интерполяционный многочлен Ньютона:
, получим интерполяционный многочлен Ньютона: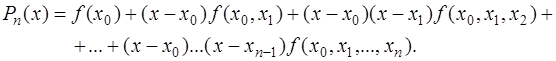 (7.2.13)
(7.2.13)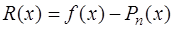 (7.2.14)
(7.2.14)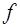 , выбора узлов
, выбора узлов 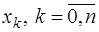 и от положения точки
и от положения точки 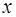 на
на 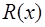 имеет вид:
имеет вид: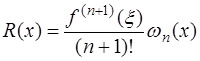 , (7.2.15)
, (7.2.15)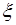 - некоторая точка отрезка
- некоторая точка отрезка 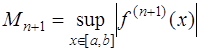 ,
,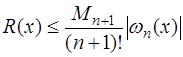 . (7.2.16)
. (7.2.16)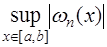 было минимальным. Для этого можно воспользоваться многочленами Чебышева:
было минимальным. Для этого можно воспользоваться многочленами Чебышева: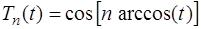 . (7.2.17)
. (7.2.17)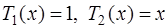 , а для построения многочленов более высокой степени можно воспользоваться рекуррентной формулой:
, а для построения многочленов более высокой степени можно воспользоваться рекуррентной формулой: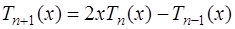 ; (7.2.18)
; (7.2.18)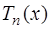 равен
равен 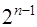 ;
;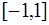 ;
;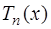 имеют
имеют 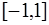 , которые располагаются в точках
, которые располагаются в точках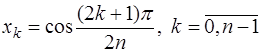 ; (7.2.19)
; (7.2.19)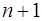 экстремум, равный
экстремум, равный 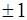 , на
, на 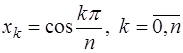 ; (7.2.20)
; (7.2.20)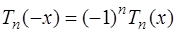 ;
;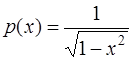 на
на 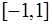 , так как
, так как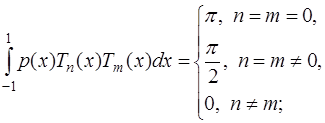
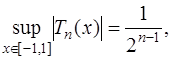
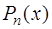 степени
степени 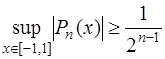 .
.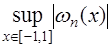 было наименьшим, необходимо в качестве
было наименьшим, необходимо в качестве 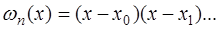
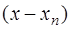 взять приведенный многочлен Чебышева
взять приведенный многочлен Чебышева 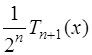 , то есть в качестве узлов интерполирования взять корни многочлена Чебышева:
, то есть в качестве узлов интерполирования взять корни многочлена Чебышева: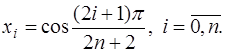 (7.2.21)
(7.2.21)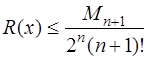 . (7.2.22)
. (7.2.22) , то значения
, то значения 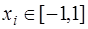 с помощью линейного преобразования
с помощью линейного преобразования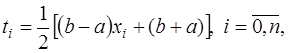 (7.2.23)
(7.2.23)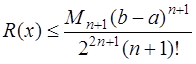 . (7.2.24)
. (7.2.24)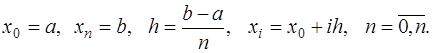
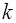 -го порядка называется величина
-го порядка называется величина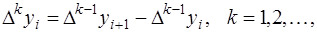
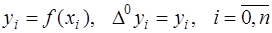 .
.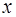 , оказывают большее влияние, чем узлы, лежащие дальше, то целесообразно при построении интерполяционной формулы привлекать сначала ближний узел, а затем остальные в порядке их удаленности от точки
, оказывают большее влияние, чем узлы, лежащие дальше, то целесообразно при построении интерполяционной формулы привлекать сначала ближний узел, а затем остальные в порядке их удаленности от точки 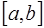 или слева от него. Для построения интерполяционной формулы Ньютона за
или слева от него. Для построения интерполяционной формулы Ньютона за 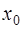 принимается ближайший к
принимается ближайший к 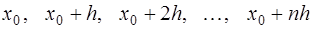 ,
,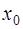 выбирается лежащий слева от точки
выбирается лежащий слева от точки 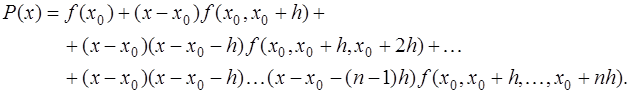
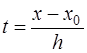 , то
, то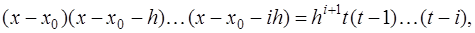
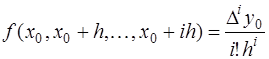 ,
,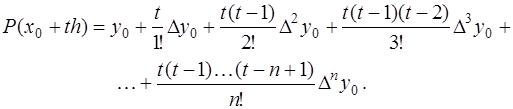 (7.2.25)
(7.2.25)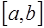 или справа от него. За первый узел для построения интерполяционной формулы примем ближайший к
или справа от него. За первый узел для построения интерполяционной формулы примем ближайший к 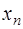 , при этом, если возможно, следует избегать ситуации экстраполирования. Далее узлы для построения интерполяционной формулы следует привлекать в следующем порядке:
, при этом, если возможно, следует избегать ситуации экстраполирования. Далее узлы для построения интерполяционной формулы следует привлекать в следующем порядке: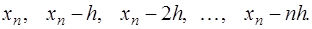
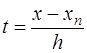 . Тогда, преобразовывая аналогично предыдущему, получим формулу Ньютона для интерполирования назад:
. Тогда, преобразовывая аналогично предыдущему, получим формулу Ньютона для интерполирования назад: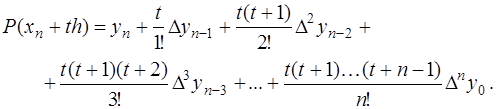 (7.2.26)
(7.2.26)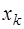 , причем правее его, то есть
, причем правее его, то есть 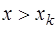 , то узлы привлекаются в следующем порядке:
, то узлы привлекаются в следующем порядке: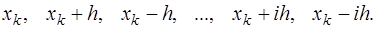
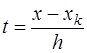 и соответствующих преобразований, получается формула Гаусса для интерполирования вперед, которая имеет вид:
и соответствующих преобразований, получается формула Гаусса для интерполирования вперед, которая имеет вид: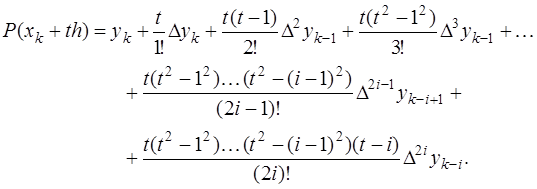 (7.2.27)
(7.2.27)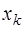 , причем
, причем 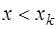 , то для построения интерполяционной формулы узлы привлекаются в следующем порядке:
, то для построения интерполяционной формулы узлы привлекаются в следующем порядке: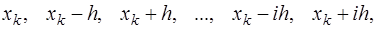
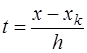 и соответствующих преобразований, получим формулу Гаусса для интерполирования назад:
и соответствующих преобразований, получим формулу Гаусса для интерполирования назад: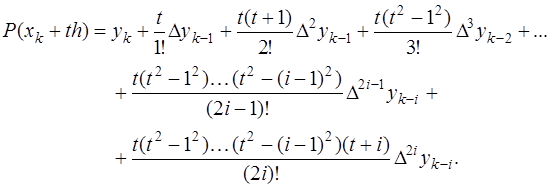 (7.2.28)
(7.2.28)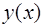 достаточно гладкая, то разности
достаточно гладкая, то разности 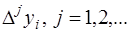 убывают с ростом
убывают с ростом 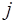 и для некоторого
и для некоторого 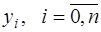 вычислены с абсолютной погрешностью
вычислены с абсолютной погрешностью 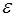 . Так как конечные разности определяются по формуле:
. Так как конечные разности определяются по формуле: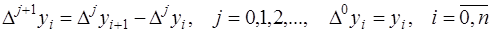 ,
,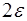 , второго порядка –
, второго порядка – 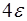 ,…,
,…, 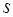 -го порядка –
-го порядка – 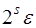 . Тогда, если
. Тогда, если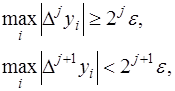
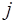 . Разности
. Разности 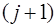 -го порядка уже меньше погрешности, поэтому их использование приведет к искажению результата и при построении интерполяционной формулы они отбрасываются.
-го порядка уже меньше погрешности, поэтому их использование приведет к искажению результата и при построении интерполяционной формулы они отбрасываются.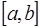 задано разбиение
задано разбиение 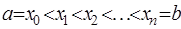 , в узлах которого известны значения достаточно гладкой функции
, в узлах которого известны значения достаточно гладкой функции 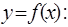
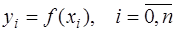 . Узлы разбиения делят отрезок
. Узлы разбиения делят отрезок 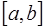 на
на 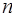 отрезков
отрезков 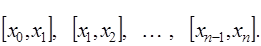
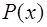 , которая вместе с производными нескольких порядков непрерывна на всем отрезке
, которая вместе с производными нескольких порядков непрерывна на всем отрезке 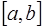 , а на каждом частичном отрезке
, а на каждом частичном отрезке 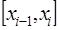 в отдельности является составляющей функцией:
в отдельности является составляющей функцией: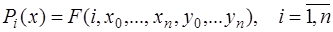 .
.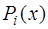 являются алгебраическими многочленами вида:
являются алгебраическими многочленами вида: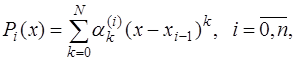
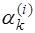 – коэффициенты, определяемые для каждого частичного отрезка.
– коэффициенты, определяемые для каждого частичного отрезка.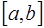 производной – дефектом сплайна.
производной – дефектом сплайна. состоит из линейных многочленов вида:
состоит из линейных многочленов вида: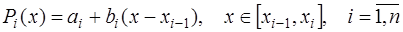 . (7.2.29)
. (7.2.29)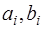 ,
,  определим из условия непрерывности
определим из условия непрерывности 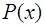 на
на 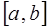 и требования совпадения значений сплайна с функцией
и требования совпадения значений сплайна с функцией 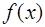 в узловых точках:
в узловых точках: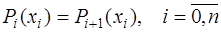 , (7.2.30)
, (7.2.30)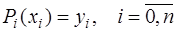 . (7.2.31)
. (7.2.31)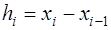 . Тогда для каждого из многочленов можно записать
. Тогда для каждого из многочленов можно записать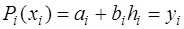 ,
, 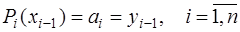 ,
, 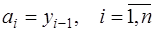 , (7.2.32)
, (7.2.32)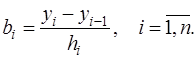 (7.2.33)
(7.2.33)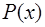 состоит из парабол, то есть
состоит из парабол, то есть 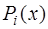 имеют вид:
имеют вид: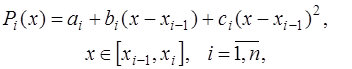 (7.2.34)
(7.2.34)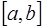 , то есть:
, то есть: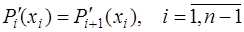 . (7.2.35)
. (7.2.35)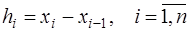 , и, учитывая, что
, и, учитывая, что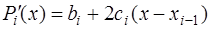 , (7.2.36)
, (7.2.36)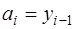 , (7.2.37)
, (7.2.37)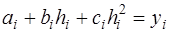 , (7.2.38)
, (7.2.38)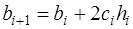 . (7.2.39)
. (7.2.39)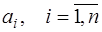 определяются согласно (7.2.37), а (7.2.38) можно записать в виде:
определяются согласно (7.2.37), а (7.2.38) можно записать в виде: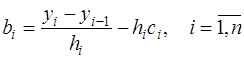 . (7.2.40)
. (7.2.40)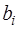 и
и 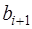 в виде (7.2.40) и подставить их в (7.2.39), то получим
в виде (7.2.40) и подставить их в (7.2.39), то получим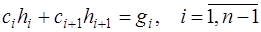 , (7.2.41)
, (7.2.41)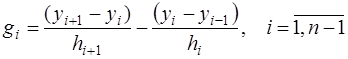 . (7.2.42)
. (7.2.42)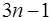 уравнений для определения
уравнений для определения 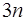 коэффициентов сплайна. Недостающее уравнение получается из дополнительного условия, которое накладывается на значение производной сплайна на конце интервала
коэффициентов сплайна. Недостающее уравнение получается из дополнительного условия, которое накладывается на значение производной сплайна на конце интервала 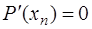 (7.2.43)
(7.2.43)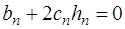 . (7.2.44)
. (7.2.44)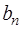 из (7.2.40), то формулу (7.2.44) можно переписать в виде:
из (7.2.40), то формулу (7.2.44) можно переписать в виде: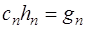 ,
,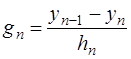 .
.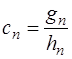 (7.2.45)
(7.2.45)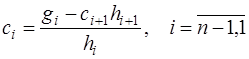 . (7.2.46)
. (7.2.46)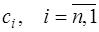 по (7.2.45), (7.2.46), затем
по (7.2.45), (7.2.46), затем 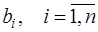 по (7.2.39) и
по (7.2.39) и 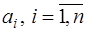 , по (7.2.37).
, по (7.2.37).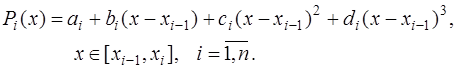 (7.2.47)
(7.2.47)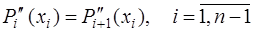 . (7.2.48)
. (7.2.48)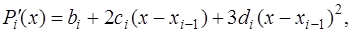 (7.2.49)
(7.2.49)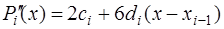 . (7.2.50)
. (7.2.50)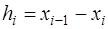 , получим:
, получим: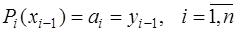 , (7.2.51)
, (7.2.51)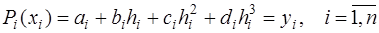 , (7.2.52)
, (7.2.52)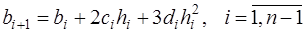 , (7.2.53)
, (7.2.53)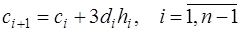 . (7.2.54)
. (7.2.54)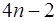 уравнений для определения
уравнений для определения 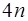 параметров сплайна. Для получения двух недостающих уравнений потребуем выполнения дополнительных условий на концах интервала
параметров сплайна. Для получения двух недостающих уравнений потребуем выполнения дополнительных условий на концах интервала 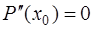 , (7.2.55)
, (7.2.55)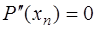 . (7.2.56)
. (7.2.56)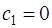 , (7.2.57)
, (7.2.57)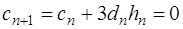 . (7.2.58)
. (7.2.58)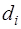
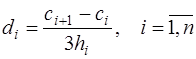 , (7.2.59)
, (7.2.59)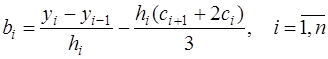 . (7.2.60)
. (7.2.60)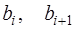 и
и 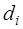 подставить в (7.2.53), то получим:
подставить в (7.2.53), то получим: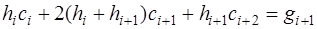 , (7.2.61)
, (7.2.61)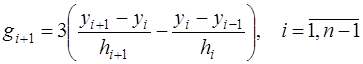 . (7.2.62)
. (7.2.62)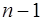 уравнения относительно неизвестных
уравнения относительно неизвестных 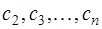 . Эта система является системой с трехдиагональной матрицей вида:
. Эта система является системой с трехдиагональной матрицей вида: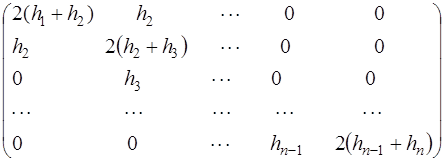 (7.2.63)
(7.2.63)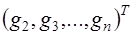 , где Т - символ транспонирования.
, где Т - символ транспонирования.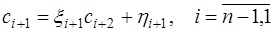 , (7.2.64)
, (7.2.64)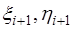 – неизвестные коэффициенты. Чтобы получить выражения для этих коэффициентов, запишем формулы для определения
– неизвестные коэффициенты. Чтобы получить выражения для этих коэффициентов, запишем формулы для определения 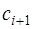 и
и 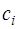 согласно (7.2.64) и, подставив их в (7.2.61), сравним полученное выражение с (7.2.64). При сравнении получим, что выражения для определения неизвестных коэффициентов
согласно (7.2.64) и, подставив их в (7.2.61), сравним полученное выражение с (7.2.64). При сравнении получим, что выражения для определения неизвестных коэффициентов 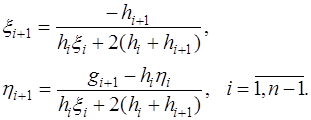 (7.2.65)
(7.2.65)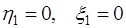 .
. ,
,  , для чего необходимо, осуществляя прямой ход метода прогонки по формулам (7.2.65), найти значения
, для чего необходимо, осуществляя прямой ход метода прогонки по формулам (7.2.65), найти значения 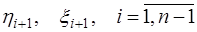 , при
, при 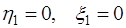 , а затем, обратным ходом, считая
, а затем, обратным ходом, считая 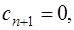 по формуле (7.2.64), вычислить
по формуле (7.2.64), вычислить 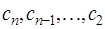 . При этом, согласно (7.2.57),
. При этом, согласно (7.2.57), 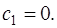 Остальные коэффициенты сплайна определяются по следующим формулам:
Остальные коэффициенты сплайна определяются по следующим формулам: 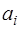 – (7.2.51),
– (7.2.51), 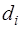 – (7.2.59),
– (7.2.59), 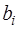 – (7.2.60),
– (7.2.60), 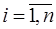 .
.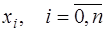 и значений коэффициентов сплайнов).
и значений коэффициентов сплайнов).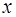 и
и  имеет очень сложное аналитическое выражение. В первом случае методы дифференциального исчисления просто неприменимы, а во втором случае их использование вызывает значительные трудности.
имеет очень сложное аналитическое выражение. В первом случае методы дифференциального исчисления просто неприменимы, а во втором случае их использование вызывает значительные трудности. рассматривают интерполяционный многочлен
рассматривают интерполяционный многочлен  и считают производную от
и считают производную от 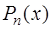 . Естественно, что при этом производная от
. Естественно, что при этом производная от 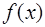 в некоторой точке
в некоторой точке  , если таблица значений функции
, если таблица значений функции  . В этом случае наиболее удобным является использование в качестве
. В этом случае наиболее удобным является использование в качестве  , то для вычисления значения первой производной функции
, то для вычисления значения первой производной функции  (7.3.1)
(7.3.1) можно записать в виде:
можно записать в виде: (7.3.2)
(7.3.2) раз (в предположении, что
раз (в предположении, что  имеют производные
имеют производные  . (7.3.3)
. (7.3.3) принимается
принимается  , то погрешность дифференцирования есть
, то погрешность дифференцирования есть  . При замене
. При замене  интерполяционным многочленом предполагается, что остаточный член
интерполяционным многочленом предполагается, что остаточный член  мал, но из этого вовсе не следует, что мало
мал, но из этого вовсе не следует, что мало  , так как производные от малой функции могут быть весьма велики. На самом деле практика показывает, что при таком способе вычисления производных
, так как производные от малой функции могут быть весьма велики. На самом деле практика показывает, что при таком способе вычисления производных 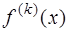 получается сравнительно большая погрешность, особенно при вычислении производных высших порядков.
получается сравнительно большая погрешность, особенно при вычислении производных высших порядков. , то для вычисления значения первой производной в точке
, то для вычисления значения первой производной в точке 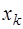 , получаются следующие выражения:
, получаются следующие выражения: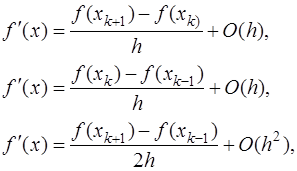 (7.3.4)
(7.3.4) используются для обозначения выражений, имеющих порядок малости, превышающий величины
используются для обозначения выражений, имеющих порядок малости, превышающий величины  и
и  соответственно. Несмотря на то, что с помощью последнего выражения в (7.3.4) получается более точный результат, использовать это выражение для вычисления первой производной нужно с большой осторожностью, так как достаточно часто это приводит к потере устойчивости решения.
соответственно. Несмотря на то, что с помощью последнего выражения в (7.3.4) получается более точный результат, использовать это выражение для вычисления первой производной нужно с большой осторожностью, так как достаточно часто это приводит к потере устойчивости решения. , используется следующее выражение:
, используется следующее выражение: . (7.3.5)
. (7.3.5) есть любой конечный или бесконечный отрезок числовой оси и требуется найти приближенное значение интеграла
есть любой конечный или бесконечный отрезок числовой оси и требуется найти приближенное значение интеграла (7.4.1)
(7.4.1) значениям функции
значениям функции  в точках
в точках  . Многие правила численного интегрирования основаны на замене интегрируемой функции
. Многие правила численного интегрирования основаны на замене интегрируемой функции 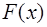 на всем отрезке
на всем отрезке  или на его частях на более простую функцию, близкую к
или на его частях на более простую функцию, близкую к  , легко интегрируемую точно и принимающую в точках
, легко интегрируемую точно и принимающую в точках  . В качестве такой функции достаточно часто используют алгебраический многочлен или рациональную функцию. В том случае, если интегрируемая функция
. В качестве такой функции достаточно часто используют алгебраический многочлен или рациональную функцию. В том случае, если интегрируемая функция  имеет особенности, то это затруднит такое приближение или сделает его вообще невозможным. В этом случае заранее освобождаются от этих особенностей путем их выделения. Для этого функцию
имеет особенности, то это затруднит такое приближение или сделает его вообще невозможным. В этом случае заранее освобождаются от этих особенностей путем их выделения. Для этого функцию  , (7.4.2)
, (7.4.2) имеет те же особенности, что и
имеет те же особенности, что и  является достаточно гладкой функцией. Тогда задача заключается в вычислении интеграла вида:
является достаточно гладкой функцией. Тогда задача заключается в вычислении интеграла вида: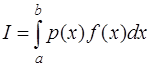 . (7.4.3)
. (7.4.3) . Поэтому при вычислении интеграла (7.4.3) функция
. Поэтому при вычислении интеграла (7.4.3) функция  считается фиксированной функцией, а
считается фиксированной функцией, а 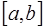 .
. представим в виде:
представим в виде: (7.6.28)
(7.6.28) , и при этом
, и при этом  . Разделив выбранное уравнение на
. Разделив выбранное уравнение на  , приведем его к виду:
, приведем его к виду: , (7.6.29)
, (7.6.29)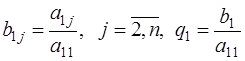 .
. и вычтем из второго, третьего и т.д. последнего уравнения системы. Преобразованные уравнения будут иметь вид:
и вычтем из второго, третьего и т.д. последнего уравнения системы. Преобразованные уравнения будут иметь вид: (7.6.30)
(7.6.30) .
.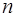 шагов преобразований получим систему вида:
шагов преобразований получим систему вида: (7.6.31)
(7.6.31) (7.6.32)
(7.6.32) система приняла вид:
система приняла вид: (7.6.33)
(7.6.33) есть отличные от нуля, то система (7.6.28) не имеет решения, если все
есть отличные от нуля, то система (7.6.28) не имеет решения, если все  ,
,  , то система имеет бесчисленное множество решений (неизвестные
, то система имеет бесчисленное множество решений (неизвестные  могут принимать любые значения, а
могут принимать любые значения, а 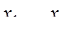 выражаются через них).
выражаются через них). матрицы
матрицы  равно произведению ведущих коэффициентов:
равно произведению ведущих коэффициентов: (7.6.34)
(7.6.34)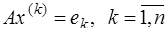 , (7.6.35)
, (7.6.35) – единичный вектор (вектор, у которого все элементы, кроме
– единичный вектор (вектор, у которого все элементы, кроме  -го, равны нулю, а
-го, равны нулю, а  –
– 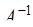 . Невозможность вычисления обратной матрицы проявляется в невозможности решения какой-либо системы из (7.5.35).
. Невозможность вычисления обратной матрицы проявляется в невозможности решения какой-либо системы из (7.5.35).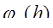 в (7.7.5) имеет следующий смысл: это разность между точным и приближенным приращениями решения дифференциального уравнения в точке
в (7.7.5) имеет следующий смысл: это разность между точным и приближенным приращениями решения дифференциального уравнения в точке  . Тогда, учитывая (7.7.6) и (7.7.7), можно записать уравнение погрешности функции решения в одной точке следующим образом:
. Тогда, учитывая (7.7.6) и (7.7.7), можно записать уравнение погрешности функции решения в одной точке следующим образом: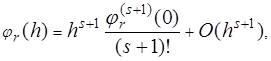 (7.7.13)
(7.7.13)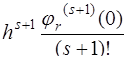 – главный член погрешности. Число шагов, которые необходимо сделать до произвольной точки
– главный член погрешности. Число шагов, которые необходимо сделать до произвольной точки 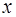 , обратно пропорционально шагу
, обратно пропорционально шагу 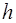 , т.е.
, т.е. 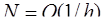 и погрешность в произвольной точке
и погрешность в произвольной точке 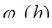 на число шагов
на число шагов 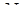 , т.е.
, т.е.  .
.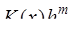 , то говорят, что порядок погрешности метода равен
, то говорят, что порядок погрешности метода равен 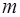 . На практике в качестве погрешности приближенного решения берут главный член погрешности:
. На практике в качестве погрешности приближенного решения берут главный член погрешности: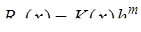 . (7.7.14)
. (7.7.14) , а порядок погрешности метода –
, а порядок погрешности метода – 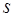 . Для метода Эйлера
. Для метода Эйлера  , а для метода Рунге-Кутта
, а для метода Рунге-Кутта  . Таким образом, при моделировании методом Эйлера результаты получаются с погрешностью порядка
. Таким образом, при моделировании методом Эйлера результаты получаются с погрешностью порядка 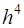 .
.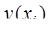 – точное решение в точке
– точное решение в точке 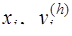 – приближенное решение в точке
– приближенное решение в точке 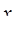 , найденное с шагом
, найденное с шагом 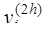 – приближенное значение в точке
– приближенное значение в точке 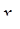 , найденное с шагом
, найденное с шагом 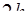 , и пусть погрешность приближенного решения определяется формулой:
, и пусть погрешность приближенного решения определяется формулой: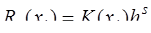 .
.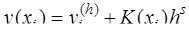 ,
,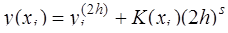 .
.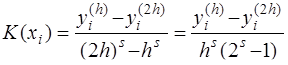
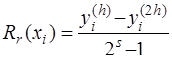 . (7.7.15)
. (7.7.15) можно получить с помощью двойного счета по формулам Эйлера и Рунге-Кутта и в качестве оценки погрешностей использовать величины:
можно получить с помощью двойного счета по формулам Эйлера и Рунге-Кутта и в качестве оценки погрешностей использовать величины: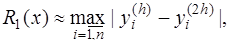 (7.7.16)
(7.7.16)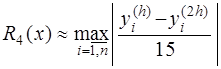 . (7.7.17)
. (7.7.17)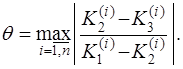 (7.7.18)
(7.7.18)
 преобразуется в цифровую форму аналого-цифровым преобразователем (АЦП), а на выходе цифровой вектор управляющих воздействий
преобразуется в цифровую форму аналого-цифровым преобразователем (АЦП), а на выходе цифровой вектор управляющих воздействий  преобразуется в непрерывный сигнал
преобразуется в непрерывный сигнал  цифро-аналоговым преобразователем (ЦАП).
цифро-аналоговым преобразователем (ЦАП). между двумя моментами квантования называется периодом квантования.
между двумя моментами квантования называется периодом квантования. . Если
. Если