
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Модели знаний на основе продукций
В модели знаний на основе продукций знания представлены совокупностью правил в формате " ЕСЛИ - ТО". Рассмотрим, например, правила порождения родительного падежа слов, задаваемые таблицей 1.1. Для того, чтобы получить родительный падеж слова " Знахарь" отыскиваем первую подходящую строку, начиная с верхней, в левом колонке табл.1.1. Строка будет подходящей, если указываемое в ней окончание совпадает с окончанием слова (в данном случае выбирается строка 5). Нетрудно, однако видеть, что строка 6 также подходит для нашей цели, хотя выдаваемый ею результат (правая колонка табл. 1.1.) не верен. Прежде чем мы рассмотрим более подробно это свойство системы продукций, выясним их природу. Рассматривая структуру продукции, нетрудно видеть, что ее условная часть (" ЕСЛИ..." ) определяет ситуацию, в которой продукция применима. В примере со словом " знахарь" ситуация определяется его окончанием, т.е. либо окончанием " арь", либо ''-ь". Таблица 1.1.
Если ситуация удовлетворяет продукции, то в результате ее применения может быть получен новый объект (состояние) согласно части " ТО... " в структуре продукции. Так, применение продукции с номером 5 в табл.1.1. к слову " знахарь" порождает слово " знахаря", а применение продукции номер 6 дает слово " знахари". Таким образом, одним из основных вопросов в реализации продукционных систем является стратегия выбора альтернативных правил. В общем случае эта проблема нетривиальна. Условная часть продукции может иметь различные формы, такие например, как в следующих примерах: ² ЕСЛИ (идет - дождь) ²; ² ЕСЛИ ( a > b2 - b ) ²; ² ЕСЛИ ( P C Q ) ². В структуре продукции дополнительно могут указываться метка и строка, содержащая объяснение применения продукции. Метка может быть простым идентификатором (или номером) или некоторым пояснительным текстом, например, " определение окраски инфекции по Граму" Строка-объяснение показывает, почему используется продукция. Следующий пример демонстрирует полную продукцию: МЕТКА: R26 Использование зонтика УСЛОВИЕ: ЕСЛИ (идет дождь) ДЕЙСТВИЕ: ТО (возьмите зонтик) ОБЪЯСНЕНИЕ: (зонтик предохраняет от дождя) Как правило, задача, формулируемая для продукционной системы, имеет одну из следующих структур < S0, Sf -? > (1.5) < S0 -?, Sf> (1.6) < S0, Sf, A -? > (1.7) < S0, Sf -?, A -? > (1.8) где: S0 - начальная ситуация, Sf - конечная (желаемая, требуемая ситуация), А - алгоритм (последовательность выполняемых продукций), переводящий систему из состояния S0 в состояние Sf Задача (1.5) связана с определением ситуации (состояния) Sf, удовлетворяющей некоторому критерию, которая может быть получена из заданной начальной ситуации. Задача (1.6) является обратной по отношению к предыдущей. Задача (1.7) заключается в отыскании алгоритма преобразования начальной ситуации в конечную. Задача (1.8) представляет обобщение задач (1.5) и (1.7). Продукции удачно моделируют человеческий способ рассуждений при решении проблем. Поэтому продукции широко используются во многих действующих ЭС. Система MYCIN, фрагмент которой приведен во введении, а также ее более поздняя редакция EMYCIN являются примерами продукционных систем. Продукционные системы впервые изобретены Постом в 1941г. Продукция в системе Поста имеет следующую схему
где t1, t2, ..., tn называются посылками, а t заключением продукции. Применение схемы (1.9) основывается на подстановке цепочек знаков вместо всех переменных, причем вместо вхождений одной и той же переменной подставляется одна и та же цепочка. В качестве других классических продукционных систем отметим нормальные алгоритмы Маркова и машину Тьюринга. Развитием модели на основе правил является модель " доски объявлений". Эта модель реализована в системе распознавания разговорной речи HEARSAY - 2. Основной принцип организации модели доски объявлений заключается в разбиении продукций по уровням иерархии. При этом заключения продукций на нижних уровнях используются как входные условия для продукций более высокого уровня. На нижнем уровне модели доски объявлений представлены факты, на верхнем - результирующее заключение. Иерархическое разбиение множества продукций позволяет более эффективно организовать их выполнение, существенно сократив затраты на перебор множества продукций при проверке условий их срабатывания, что определяет дополнительный интерес к продукционным системам. В рамках этой модели продукция определяется четверкой: P = < L, C, N, A >, где L – метка; С – условие применимости; N – ядро продукции, описываемое формулой (1.9); А – постдействие. Фреймовая модель знаний Фреймовая модель знаний предложена Марвином Минским. Минский также ввел терминологию и язык фреймов. Эта терминология включает такие понятия как " фреймы", " слоты", " терминалы", " значения по умолчанию". Фрейм определяется как структура следующего вида: {< имя-фрейма> < имя слота1 > < значение слота> 1, ..., < имя слотаn > < значение слота> n } Так, определим фрейм для объекта " книга": {< КНИГА> < АВТОР> < ДюмаА.> < НАЗВАНИЕ> < Граф Мосте Кристо> < ЖАНР> < Роман> } Мы видим, что слоты соответствуют атрибутам (характеристикам, свойствам) объекта. Если значения слотов не определены, то фрейм называется фреймом-прототипом. Заменяя неизвестное значение звездочкой (" *" ) будем иметь следующий фрейм-прототип: {< КНИГА> < АВТОР> < *> < НАЗВАНИЕ> < *> < ЖАНР> < *> } Напротив, фрейм, в котором все слоты заполнены, называется конкретным фреймом. Отметим, что имена слотов часто называют ролями. Основной процедурой над фреймами является поиск по образцу. Образец, или прототип, это - фрейм, в котором заполнены не все структурные единицы, а только те, по которым среди фреймов, хранящихся в памяти ЭВМ, отыскиваются нужные фреймы. Другими процедурами, характерными для фреймовых языков, являются наполнение слотов данными, введение в систему новых фреймов-прототипов, а также изменения некоторого множества фреймов, сцепленных по слотам (т.е. имеющих одинаковые значения для общих слотов). Фрейм может быть декларативного, процедурного и процедурно-декларативного типа. В фреймах процедурного типа процедуры привязываются к слоту путем указания последовательности выполняемых операций. Различают два вида процедур: процедуры-" демоны" и процедуры-" слуги". Процедура-демон запускается автоматически, когда фрейм удовлетворяет некоторому образцу, по которому осуществляется поиск в базе знаний. Процедура-слуга запускается по внешнему запросу, а также используется для задания по умолчанию значений слотам, если они не определены. Таблица 1.2.
Структура фрейма, содержащего процедуры, приведены в табл.1.2. Внутренняя процедура используется для изменения содержимого данного фрейма, в то время как внешняя - для изменения содержимого других фреймов. Процедура выполняет изменения в той части фрейма, которая называется терминальной (образована множеством терминалов - ячеек для хранения и записи информации). Примеры систем, работающих с фреймами, это KRL, FRL, GUS, OWL [20, 21] и др.
Развитием концепции фреймовых моделей являются сценарии и ленемы. Понятие сценария введено Р. Шенком и Р. Абельсоном. Сценарий - это фреймоподобная структура, в которой определены такие специальные слоты как сценарий, цель, сцена, роль. Следующий пример сценария взят из: < сценарий: ресторан роли: посетитель, официант, кассир цель: принятие пищи, чтобы насытиться и получить удовольствие сцена 1: вход в ресторан войти в ресторан осмотреть места выбрать свободное место пройти к свободному столику сесть сцена 2: заказ взять меню прочитать меню решить, что заказать заказ меню официанту сцена 3: прием пищи получение пищи съедение пищи сцена 4: уход просьба рассчитать получение чека движение к кассиру передача денег кассиру выход из ресторана > Сценарии отражают каузальные ( причинно - следственные ) цепочки предметной области, т.е. имеют более развитую семантику в сравнении с " классическими" фреймами. Таким образом, сценария рассматриваются как средство представления проблемно-зависимых каузальных знаний. Отметим, что фреймовые модели знаний эффективны для структурного описания сложных баз знаний, однако для них нет специфического формализованного аппарата, в связи с чем фреймы часто используют как базу данных системы продукций. Семантические сети
Введен также специальный тип вершин: вершины связи. Вершина связи не соответствует ни объектам, ни отношениям и используется для указания связи. Основными отношениями в семантической сети являются отношения принадлежности к классу, свойства, специфические для данного понятия и примеры данного понятия (рис. 1.2). Отношение принадлежности элемента к некоторому классу либо части к целому в англоязычной литературе определяется соответственно как " IS А", либо как " РАRТ ОF", например, фразе " лев есть хищник" соответствует семантический фрагмент, изображенный на рис. 1.3.
Рис. 1.3 Рис. 1.4
Рис. 1.5 Свойства передаются через связки " IS" и " HAS" (" есть" и " имеет" ), например, высказывание " лев имеет гриву" интерпретирует фрагмент сети, показанный на рис.1.4, а фраза " грива густая" (a mane is thick) передается фрагментом на рис. 1.5. Если обозначить фрагменты, показанные на рис.1.3 - 1.5 через Фi, то в общем случае семантическая сеть образуется как соединение (°) этих фрагментов, т.е. как Ф1 ° Ф2 °...° Фn, причем порядок индексации фрагментов не имеет значения (операция соединения коммутативна). Важный момент в организации модели базы знаний на основе семантической сети заключается в представлении событий и действий. Концептуализация действий строится из следующих элементов:
Для описания семантики действий используются следующие основные группы обозначений и концептуальных схем: Обозначения: РР - класс физических объектов; О - физические объекты; АСТ - действия; РА - свойства объектов; LОС - местоположение; Т - времена; АА - атрибуты (характеристики) действий; РА - атрибуты (характеристики) объектов; R. - реципиенты; I - инструменты, посредством которых выполняется действие; D - направление действия; Концептуальные схемы: Û - используется для обозначения концепта действия (1) PP Û ACT - некоторые объекты могут производить действия (2) PP Û PA - объекты обладают свойства (3)
(4) - АКТы имеют направление
(5) - АКТы имеют реципиентов
(7) PP Û PP - один PP эквивалентен другому или является
(8) - концепт действия характеризуется местоположением
(11) - концепт действия характеризуется изменением состояния
(12) (13) Следующие примеры демонстрируют использование введенных понятий. Пример 1. Джон съел лягушку.
Джон Û съесть
Y - некоторое неизвестное местоположение. Пример 2. Билл обидел Джона.
Пример 3. Джон дал Мэри книгу.
Для задания событий используются временные отношения, такие как " раньше", " позже", " в данный момент", " одновременно", " не позднее" и т.д. Кроме рассмотренных понятий, на семантической сети могут быть определены также сетевые продукции, которые позволяют: - добавлять или удалять фрагменты сетей - добавлять или удалять связи и вершины - проверить, что некоторый фрагмент содержится в сети - строить примеры отношений - находить фрагменты, общие для двух и более сетей и др. Особенностью и в то же время недостатком семантической сети является ее представление в виде такой целостной структуры, которая не позволяет разделить базу знаний и механизм выводов. Это означает, что процесс вывода, как правило, связан с изменением структуры сети путем применения сетевых продукций.
Машина вывода Понятие формальной системы Прежде чем мы сформулируем понятие машины вывода, нам необходимо дать определение формальной (аксиоматической) системы и правил вывода. Под формальной системой понимается четверка: М = < Т, Р, А, П>, (1.10) где Т - множество базовых элементов; Р - множество правил построения правильных (сложных) объектов из базовых элементов; А - множество изначально заданных объектов формальной системы (множество аксиом ); П - множество правил построения новых объектов из других правильных объектов системы. Для того, чтобы выяснить смысл этих формализмов, рассмотрим введенную ранее логическую модель как пример аксиоматической системы. В качестве множества базовых элементов Т здесь используются элементы языка логики предикатов: переменные, константы, функциональные и предикатные символы и вспомогательные знаки. В качестве множества правил Р построения правильных (сложных) объектов логики предикатов выступают правила построения формул логики предикатов. Например, следующая формула является правильно построенной ( " x( $ y( $ z( P(x, y) ® в то время как объект ниже (x ® P(x, y)) Ú ( $ z ( не является правильно построенной формулой. Множество аксиом - это множество формул, истинность которых постулируется без доказательства. Постулаты логики предикатов имеют вид схем аксиом. Схема аксиомы - это математическое выражение, которое дает конкретную аксиому каждый раз при подстановке вместо какой-то буквы одной и той же формулы. Схемы аксиом логики предикатов таковы: 1. A ® (B ® A) 2. (A ® B) ® ((A ® (B ® C)) ® (A ® C)) 3. A ® (B ® A & B) 4. a) A & B ® A b) A & B ® B 5. a) A ® A Ú B b) B ® A Ú B 6. (A ® C) ® ((B ® C) ® (A Ú B ® C)) 7. (A ® B) ® ((A ® 8. 9. " x A(x) ® A(t) 10. A(t) ® xA(x) Постулаты арифметики: 1. A(o) & x (A(x) ® A(x’)) ® A(x) (аксиома индукции) 2. a¢ = b¢ ® a = b 3. a = b ® (a = c ® b = c) 4. A + 0 = a 5. a ° 0 = 0 6. 7. a = b ® a¢ = b¢ 8. а + b = (а + b)¢ 9. a b¢ = a b + a Здесь A, B, C - формулы; х - переменная; t - терм; a, b, c - целые числа; операция (’) (штрих) соответствует добавлению к числу единицы: а’ = а + 1. Рассмотрим, например, схему аксиом (7). Заменим формулу А ® В на
Далее по правилам де Моргана:
Нетрудно видеть, что схема аксиом (7) является тождественно истинной, если истинна формула A Мы, однако, не в состоянии доказать последнюю формулу, т.е. считаем ее истинной по определению. Воспользуемся примером, иллюстрирующим это положение. Рассмотрим высказывание " последовательность 0123456789 встречается в разложении числа p". Обозначим это высказывание через А. Тогда обратное высказывание Будем записывать десятичное разложение числа p, а под ним десятичную дробь r = 0, 333.... При записи каждой очередной цифры в разложении p добавляем " 3" в r. Если окажется, что высказывание А истинно, то стираем записанное представление для r и полагаем
где k - число троек, полученных в представлении к данному моменту. Допустим, что справедлива формула В Спросим себя, рационально ли r или нет? Если r не рационально (верно
где х, у - целые, т.е. было бы рационально. Однако, если справедливо Действительно, если r рационально либо мы построили бесконечную последовательность 0, 333... (что невозможно), либо доказали формулу А. Приведенный пример характеризует так называемое интуиционистское направление в математике. Так интуиционисты отрицают правило tertium non datyr (третьего не дано). Ими также подвергается критике само понятие отрицания: ложность любой формулы j трактуется ими так, что допущение j ведет к противоречию. Еще один философский пример того же рода демонстрирует так называемый парадокс лжеца: " если некто говорит, что он лжет, то говорит ли он на самом деле правду или лжет? " Обозначим высказывание " Я лгу " через А. Если А истинно, то " некто в действительности лжет", т.е. должно быть Вернемся, однако, к истине (1.10). Нам осталось определить правила вывода П. Каждое правило вывода имеет структуру вида:
означающую, что если выведены формулы j1, j2, ..., jn, называемые посылками, то выводима также формула e называемая заключением. Под выводимостью формулы e из формул j1, j2, ..., jn, понимается такое отношение между этими формулами, что всякий раз, когда истинна каждая из формул j1, j2, ..., jn, истинна также формула e. По определению, аксиома a имеет структуру
т.е. невыводима из других формул (множество посылок пусто). Отметим следующие основные свойства для отношения выводимости. 1. Рефлективность:
2. Транзитивность:
(если j выводима из e и из j выводима g, то из e выводима формула g). 3. Монотонность:
(если из e выводима формула j, то присоединение к e формулы g не отменяет выводимость j). Отметим, что свойство монотонности в общем случае не имеет места в некоторых неклассических логиках, рассматриваемых в главе 3. 4. Теорема дедукции: Если из e и g выводима формула j, то из e выводима формула g ® j (® - импликация). Верна также обратная теорема: Теорема дедукции имеет весьма важное значение в логике. Действительно, чтобы доказать выводимость заменим формулу e эквивалентной формулой e Ú , где - символ пустой формулы (лжи). Используя эквивалентную замену e Ú «
 « «  . (1.21) . (1.21)
 следует показать, что следует показать, что  , т.е., что из j и , т.е., что из j и  следует противоречие -. следует противоречие -.
В качестве основных правил вывода в логике предикатов используются правила modus ponens и generalization. Правило modus ponens:
утверждает, что если истинны формулы А и А ® В, то истинна формула B. Правило generalization:
Справедлива и обратное
при условии, что С не содержит переменной. х. Это последнее правило существенно важно при реализации наиболее широко применяемого резолютивного вывода, с содержанием которого мы познакомимся позднее. В частности, если С пустая формула, то имеет место Пример правила generalization:
Отметим, что правила вывода в логике предикатов не исчерпывают множества всех известных правил вывода. Однако, правила вывода имеют иное семантическое содержание. Об этом следующий параграф. Примеры стратегии вывода Рассмотрим формализм нормальных алгоритмов Маркова, в котором правила вывода реализуются на основе операторов подстановки. Пусть а и b - произвольные слова. Будем говорить, что слово а входит в слово b, если существуют такие слова с и d, что b = cad. Основным правилом вывода является подстановка. Оператор подстановки а ® b используется для замены левого вхождения слова а на слово b. Для того, чтобы применить оператор а ® b к слову e, необходимо, чтобы е содержало а. В последнем случае будем говорить, что выполнены условия применимости оператора а ® b. Из множества операторов, для которых выполнены условия применимости, всегда выбирается один оператор (например, первый по порядку). Отметим, что вывод считается детерминированным, если всякий раз условия применимости выполняются не более чем для одного правила вывода. Алгоритм завершает работу, если либо нет выполнимых операторов, либо выполняется специальный оператор конца (стоп-оператор). Пример. (1) a ® bc (2) c ® ebcc (3) c ® d (4) d ® e (5) b ® e (6) есс ® d. e - символ пробела. Рассмотрим, как преобразуется в этой системе слово cad:
Здесь внизу под стрелкой указан номер оператора. В системах нормальных алгоритмов Маркова выводимость трактуется в конструктивном смысле - как получение из исходного слова (образца) других слов. Это - так называемый вывод по образцу (нашедший применение, например, в системах, использующих фреймы и семантические сети). Каноническая продукционная система Поста также является системой вывода по образцу. Пусть x1, x2, ..., xn - попарно различные переменные, которые имеют области определения D1, D2, ..., Dm соответственно. Если переменная х связана некоторым значением Образец t это конструкция t где каждому xi, сопоставлен терм уi, являющийся либо самой переменной хi, (если она не связана), либо Например, t1 = Пусть даны два образца t1 и t2. Будем говорить, что из t1 и t2 выводится образец t3, и писать это: 1) t1 и t2 содержат общие переменные 2) пусть xi - одна (любая) из общих переменных, тогда xi и в t1, и в t2 либо связана одним и тем же значением, либо как минимум одна из них не связана вовсе. 3) t3 образуется путем включения (без дублирования) всех переменных из t1 и t2. При этом если общая переменная xi связана, скажем в t1, значением хi = а, а в t2 свободна ( не связана), то в t3 xi будет иметь значение а. В этом случае говорят, что переменные в t3 наследуют значения соответствующих переменных в t1, t2. Пример вывода по образцам t1, t2 образца t3. t1 = t2 = из t1, t2 выводим образец t3 t3 = Другой важной стратегией, используемой в машинах вывода, является Байесовская стратегия вывода, которая используется в системах, где детерминированность выводов является скорее исключением, чем правилом. Байесовская стратегия вывода оперирует вероятностными знаниями. Ее основная идея заключается в оценке апостериорной вероятности гипотезы при наличии фактов, подтверждающих или опровергающих гипотезу. Пусть Р(Н) = - априорная вероятность гипотезы Н при отсутствии каких- либо свидетельств; Р(Н: Е) = - апостериорная вероятность гипотезы Н при наличии свидетельства Е. Согласно теоремы Байеса:
и где Р(Н*) оценивает новую вероятность гипотезы Н с учетом свидетельства Е. Введем отношение правдоподобия ОП(Н: Е),
а также формулу для вычисления шансов O(H),
Из (1.28) нетрудно обратным преобразованием получить
Теперь формула Байеса (1.8) на языке шансов принимает следующий вид: O(H*) = O(H) OП(H: E), (1.30) где O(Н*) - новая оценка шансов для гипотезы Н с учетом свидетельства Е. Формула (1.30) при наличии многих свидетельств E1, E2, ..., En принимает вид:
Таким образом, на основании формул (1.30) и (1.31) имеется возможность просто пересчитывать апостериорные вероятности гипотез на основании получаемых свидетельств. Теорема Байеса является основой механизма вывода в экспертных системах PROSRECTOR и HULK. Рассмотрим пример использования стратегии Байеса. Пусть требуется провести дифференциальную диагностику между заболеваниями D1, D2, ..., Dn. Для простоты, пусть имеется три заболевания и четыре признака, по которым должен быть составлен диагноз. Заболевания: D1 - тетрадаФалло, D2 - дефект межпредсердечной перегородки, D3 - незараценный артериальный проток. Признаки: S1 - цианоз, S2 - усиление легочного рисунка, S3 - акцент II тона во втором межреберье слева, S4 - правограмма (ЭКГ). Допустим, известны следующие условные и безусловные вероятности (табл. 1.2), полученные на основе накопленной статистики о больных данными заболеваниями. Таблица 1.2
Пусть у пациента налицо все четыре признака: S1, S2, S3, S4. Каков диагноз заболевания? На основе теоремы Байеса можно оценить апостериорные вероятности заболеваний в предположении, что признаки S1, S2, S3, S4 независимые. Найдем
Из условия независимости признаков имеем: P(S1, S2, S3, S4|Di) = P(S1|Di) × P(S2|Di) × P(S3|Di) × P(S4|Di) (1.32)
Популярное:
|
Последнее изменение этой страницы: 2016-03-17; Просмотров: 1043; Нарушение авторского права страницы
 (1.9)
(1.9)  Семантическая сеть - это граф, вершины которого соответствуют объектам или понятиям, а дуги, связывающие вершины, определяют отношения между ними.
Семантическая сеть - это граф, вершины которого соответствуют объектам или понятиям, а дуги, связывающие вершины, определяют отношения между ними.


 - АКТы имеют объекты
- АКТы имеют объекты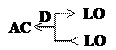

 (6) - АКТы могут изменять характеристики
(6) - АКТы могут изменять характеристики его частной характеристикой
его частной характеристикой (9) - один концепт действия является причиной другого
(9) - один концепт действия является причиной другого

 - действие ACT характеризуется инструментом I
- действие ACT характеризуется инструментом I - действие характеризуется объектом 0.
- действие характеризуется объектом 0.

 лягушка
лягушка 


 (z))))),
(z))))),  ) ®
) ®  A)
A)  ® A
® A 
 Ú В и подставим (7)
Ú В и подставим (7)
 =
=  получаем:
получаем: 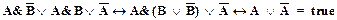
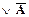 .
.
 , где В - это высказывание " число рационально", и
, где В - это высказывание " число рационально", и  ), то должно быть верно
), то должно быть верно 
 (1.13)
(1.13)  , (1.14)
, (1.14)  (1.15)
(1.15)  (1.16)
(1.16) 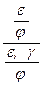 (1.17)
(1.17)  (1.18)
(1.18)  (1.19)
(1.19)  (1.22)
(1.22)  . (1.23)
. (1.23)  (1.24)
(1.24) 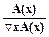 (1.25)
(1.25) 
 cad ® ebccad ® eccad ® dad ® ad ® bcd ® cd ® ebccd ® eccd ® dd ® d ® e
cad ® ebccad ® eccad ® dad ® ad ® bcd ® cd ® ebccd ® eccd ® dd ® d ® e  из Dj, , то будем вместо х, писать
из Dj, , то будем вместо х, писать 
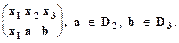
 , если выполнены следующие условия:
, если выполнены следующие условия: 

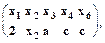
 (1.26)
(1.26) 
 (1.27)
(1.27) 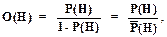 (1.28)
(1.28)  (1.29)
(1.29)  (1.31)
(1.31) 
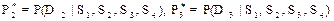
 (1.32)
(1.32) 