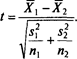|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Сравнение двух групп: критерий Стьюдента
Основные вопросы, рассматриваемые на лекции: 1 Принцип метода (критерий Стьюдента) 2 Обобщение критерия Стьюдента для различных выборок. 3 Примеры. 1. Принцип метода (критерий Стьюдента). Дисперсионный анализ позволяет проверить значимость различий нескольких групп. Нередко нужно сравнить только две группы. В этом случае можно применить критерий Стьюдента, который является частным случаем дисперсионного анализа. Вспомним, что точность выборочной оценки среднего характеризуется стандартной ошибкой среднего
где п — объем выборки, а σ — стандартное отклонение совокупности, из которой извлечена выборка. С увеличением объема выборки стандартная ошибка среднего уменьшается, следовательно уменьшается и неопределенность в оценке выборочных средних. Поэтому уменьшается и неопределенность в оценке их разности. Чтобы формализовать приведенные рассуждения, рассмотрим отношение:
Для двух случайных выборок, извлеченных из одной нормально распределенной совокупности, это отношение, как правило, будет близко к нулю. Чем меньше (по абсолютной величине) t, тем больше вероятность нулевой гипотезы. Чем больше t, тем больше оснований отвергнуть нулевую гипотезу и считать, что различия статистически значимы. Для нахождения величины t нужно знать разность выборочных средних и ее ошибку. Вычислить разность выборочных средних нетрудно – просто вычтем из одного среднего другое. Сложнее найти ошибку разности. Для этого обратимся к более общей задаче нахождения стандартного отклонения разности двух чисел, случайным образом извлеченных из одной совокупности. Можно доказать, что дисперсия разности (суммы) двух случайно извлеченных значений равна сумме дисперсий совокупностей, из которых они извлечены. В частности, если извлекать значения из одной совокупности, то дисперсия их разности будет равна удвоенной дисперсии этой совокупности. Говоря формально, если значение Х извлечено из совокупности, имеющей дисперсию
Почему дисперсия разностей больше дисперсии совокупности, легко понять: в половине случаев члены пары лежат по разные стороны от среднего, поэтому их разность еще больше отклоняется от среднего, чем они сами. Чтобы оценить дисперсию разности членов двух совокупностей по выборочным данным, нужно в приведенной выше формуле заменить дисперсии их выборочными оценками:
Этой формулой можно воспользоваться и для оценки стандартной ошибки разности выборочных средних. В самом деле, стандартная ошибка выборочного среднего — это стандартное отклонение совокупности средних значений всех выборок объемом n. Поэтому
Тем самым, искомая стандартная ошибка разности средних
Теперь мы можем вычислить отношение t (критическое значение t). Напомним, что мы рассматриваем отношение
Воспользовавшись результатом предыдущего раздела, имеем
Если ошибку среднего выразить через выборочное стандартное отклонение, получим другую запись этой формулы:
где п — объем выборки. Если обе выборки извлечены из одной совокупности, то выборочные дисперсии
Значение t, полученное на основе объединенной оценки:
Если объем выборок одинаков, оба способа вычисления t дадут одинаковый результат. Однако если объем выборок разный, то это не так. Теперь посмотрим, какие значения t мы будем получать, извлекая случайные пары выборок из одной и той же нормально распределенной совокупности. Так как выборочные средние обычно близки к среднему по совокупности, значение t будет близко к нулю. Однако иногда мы все же будем получать большие по абсолютной величине значения t. Чтобы понять, какую величину t следует считать достаточно «большой», чтобы отвергнуть нулевую гипотезу, проведем мысленный эксперимент. На рис. 1А приведено распределение значений t, вычисленных по 200 парам выборок. По нему уже можно судить о распределении t. Оно симметрично относительно нуля, поскольку любую из пары выборок можно счесть «первой». Как мы и предполагали, чаще всего значения t близки к нулю; значения, меньшие -2 и большие +2, встречаются редко. На рис. 1Б видно, что в 10 случаях из 200 (в 5% всех случаев) t меньше -2, 1 или больше +2, 1. Иначе говоря, если обе выборки извлечены из одной совокупности, вероятность того, что значение t лежит вне интервала от -2, 1 до +2, 1, составляет 5%. Продолжая извлекать пары выборок, мы увидим, что распределение принимает форму гладкой кривой, показанной на рис. 1В. Теперь 5% крайних значений соответствуют закрашенным областям графика левее -2, 1 и, правее +2, 1. Итак, мы нашли, что если две выборки извлечены из одной и той же совокупности, то вероятность получить значение t, большее +2, 1 или меньшее -2, 1, составляет всего 5%. Следовательно, если значение t находится вне интервала от -2, 1 до +2, 1, нулевую гипотезу следует отклонить, а наблюдаемые различия признать статистически значимыми.
Рис. 1. А. Из некоторой совокупности извлекли 200 пар случайных выборок по 10 членов в каждой, для каждой пары рассчитали значение t и нанесли его на график. Большая часть значений сгруппирована вокруг нуля, однако некоторые значения по абсолютной величине превышают 1, 5 и даже 2. Б. Число значений, по абсолютной величине превышающих 2, 1, составляет 5%. В. Продолжая извлекать пары выборок, в конце концов мы получим гладкую кривую. 5% наибольших (по абсолютной величине) значений образуют две заштрихованные области (сумма заштрихованных площадей как раз и составляет 5% всей площади под кривой). Следовательно, «большие» значения t начинаются там, где начинается заштрихованная область, то есть с t = ±2, 1. Вероятность получить столь высокое значение t, извлекая случайные выборки из одной совокупности, не превышает 5%. Г. Описанный способ выбора критического значения t предопределяет возможность ошибки: в 5% случаев мы будем находить различия там, где их нет. Чтобы снизить вероятность ошибочного заключения, мы можем выбрать более высокое критическое значение. Например, чтобы площадь заштрихованной области составляла 1% от общей площади под кривой, критическое значение должно составлять 2, 878. Обратите внимание, что таким образом мы выявляем отличия экспериментальной группы от контрольной как в меньшую, так и в большую сторону — именно поэтому мы отвергаем нулевую гипотезу как при t < -2, 1, так и при t > +2, 1. Этот вариант критерия Стьюдента называется двусторонним; именно его обычно и используют. Существует и односторонний вариант критерия Стьюдента. Используется он гораздо реже, и в дальнейшем, говоря о критерии Стьюдента, мы будем иметь в виду двусторонний вариант. Если значение t меньше -2, 1 или больше +2, 1, то при уровне значимости 0, 05 мы сочтем различия статистически значимыми. Это означает, что если бы наши группы представляли собой две случайные выборки из одной и той же совокупности, то вероятность получить наблюдаемые различия (или более сильные) равна 0, 05. Следовательно, ошибочный вывод о существовании различий мы будем делать в 5% случаев. Чтобы застраховаться от подобных ошибок, можно принять уровень значимости не 0, 05, а, скажем, 0, 01. Однако, во-первых, ошибочные выводы о существовании различий все же не исключены, просто их вероятность снизилась до 1%, и, во-вторых, вероятность не найти различий там, где они есть, теперь повысилась. Критические значения t (подобно критическим значениям F, они сведены в таблицу) зависят не только от уровня значимости, но и от числа степеней свободы v. Если объем обеих выборок — n, то число степеней свободы для критерия Стьюдента равно 2 (n - 1). Чем больше объем выборок, тем меньше критическое значение t. Это и понятно – чем больше выборка, тем менее выборочные оценки зависят от случайных отклонений и тем точнее представляют исходную совокупность
2. Обобщение критерия Стьюдента для различных выборок. Критерий Стьюдента легко обобщается на случай, когда выборки содержат неодинаковое число членов. Напомним, что по определению
где
где s1 и s2 – стандартные отклонения выборок. Перепишем определение t, используя выборочные стандартные отклонения:
Объединенная оценка дисперсии для выборок объема n1 и n2 равна
Тогда
Это определение t для выборок произвольного объема. Число степеней свободы ν =n1+n2–2. Заметим, что если объемы выборок равны, то есть n1 = n2 = n, то мы получим ранее использовавшуюся формулу для t. 3. Примеры. При испытании двух типов фильтров для очистки воздуха в объемах пх = пy = 50 штук получено среднее значение чистоты воздуха х = 92%, у = 96%. Проверить, является ли расхождение значений х и у случайными, если известны D(x)= 0, 09%; D(у) = 0, 04%. Решение. Выдвигаем гипотезу Hо: М(х) = М(у). Определяем статистику При уровне значимости α = 0, 05, находим:
По таблице находим критическое значение tкр = 1, 96. Сравниваем t = 8 > tкр = 1, 96. Следовательно, гипотеза H0 отвергается, так как имеются качественные различия между двумя типами фильтров.
ВОПРОСЫ И ЗАДАНИЯ
1 В каких случаях применяется критерий Стьюдента. 2 Как соотносится дисперсия разности (суммы) двух случайно извлеченных значений с дисперсиями совокупностей, из которых они извлечены.
Лекция № 7 Применение ГИС-технологий
Основные вопросы, рассматриваемые на лекции: 1. Основные выполняемые ГИС функции. 2. Типы применений ГИС. 3. Модели данных и их разновидности. 1. Основные выполняемые ГИС функции. ГИС представляет собой средство, инструмент для представления, моделирования реального мира с помощью данных о том или ином месте в пространстве. Геоинформационные технологии – это технологии организации, манипулирования, анализа и представления пространственных данных. Любая ГИС так или иначе должна быть способна выполнять несколько групп функций. Рассмотрим их в самом первом приближении. 1. Система должна обеспечивать средства для формирования цифрового представления пространственных объектов и явлений, иначе говоря, должны обеспечиваться функции сбора, кодирования и ввода информации. 2. Для поддержания массива данных в актуальном состоянии должны обеспечиваться средства редактирования, обновления, эффективного хранения данных, а также реорганизации данных и преобразования их в разные формы, средства для контроля правильности и качества данных. 3. Требуется обеспечивать средства для получения информации, как в ее первичном виде, так и обобщенной в различных смыслах (генерализованной, суммарной, усредненной), а также средства для анализа, моделирования ситуаций и процессов и интегрирования разнородной информации. 4. Система должна обеспечивать выполнение сложных запросов на получение информации. Выполнение таких сложных запросов само по себе также является методом анализа. 5. Наконец, система должна обладать способностью представлять результаты работы в виде человекочитаемых наглядных документов - таблиц, карт, диаграмм и т.п.
1.1. Функции ввода данных. Вопросы ввода данных занимают одно из важнейших мест среди функций ГИС. Если же говорить о важности этих функций на данном конкретном этапе внедрения геоинформационных технологий, то это, может быть, и центральное место. Следует различать функции по первичному вводу информации в пространственную базу данных, так называемый массовый, или первичный ввод или первичная загрузка базы данных, и функции вторичного ввода, который производится уже в процессе эксплуатации системы. В некоторых случаях эти функции могут не различаться - возможны ситуации, когда заполненная однажды данными ГИС функционирует без изменения набора данных в ней. Первичный ввод часто выполняется сразу в больших объемах, нередко путем переноса данных из другой компьютерной системы (импорт данных) или путем оцифровки большого количества часто однотипных бумажных документов. Вторичный ввод данных может быть различным по характеру. Это может быть модификация, редактирование существующих данных - изменение значений атрибутов объектов, редактирование объектов с изменением их формы или/и положения. Это может быть дополнение существующих тематических слоев новыми объектами, как в пределах той территории, где уже имеются данные в базе, так и с наращиванием, расширением территории. Это может быть дополнение базы данных новыми тематическими слоями, ранее в ней отсутствовавшими, и объектами в них. В целом это могут быть более разнообразные процессы, чем при первичном вводе, использующие более разнообразные технологии и функции системы. 1.2. Функции вывода и представления данных.Функции вывода могут отличаться у систем, ориентированных на выполнение потока отдельных информационных запросов и систем, ориентированных на выполнение серьезных аналитических операций. Последние чаще выдают вещественные документы - твердые копии карт, таблиц, диаграмм, отчетов. Запросного типа системы выдают преимущественно карты, краткие таблицы и диаграммы только на экране. 1.3. Функции обработки и анализа информации, администрирования данных. Функции обработки и анализа информации – наверное, самые важные. Функции обработки могут быть связаны только с пространственной компонентой информации, только с описательной (атрибутивной) компонентой или с обеими. Разумеется, важна группа функций, обеспечивающих администрирование базы данных, контроль ее состояния, управление доступом.
2. Типы применений ГИС. По требованиям к наличию или относительной развитости тех или иных функций в программном обеспечении ГИС, можно выделить 12 основных направлений, типов применения ГИС. 1. Простое копирование бумажных карт в электронной форме с помощью сканера или дигитайзера ( automated mapping ). Основная цель - возможность просматривать карты на экране и получать копии карт на плоттере с легкостью внесения необходимых изменений в графический компонент. Это одна из самых простых и примитивных функций ГИС. Здесь не предусматривается ни активной работы с описательными характеристиками объектов, ни какие-либо аналитические функции. 2. Компьютерный подход к тематическому картографированию - множественность атрибутов, связанных с одними и теми же объектами дает возможность для одной и той же контуровки легко получать множество карт разного тематического содержания, с разными схемами классификации для одного и того же признака, с использованием разных картографических методов представления информации (карты плотностей точек, цветовые легенды, вписанные диаграммы, масштабируемые значки...). ( Thematic mapping ). Более развитые функции, в основном за счет управления визуализацией через значения атрибутов. В отличие от предыдущей группы хорошо обеспечивается визуализация площадных объектов. 3. Комплексирование информации методом наложения карт (оверлейные операции) ( Map overlay ). Наряду с примитивными операциями (как просто включение и отключение тематических слоев и просмотр различных их комбинаций на экране) используются полноценные операции, где в результате формируются новые слои, и в их формировании участвуют атрибуты объектов и при этом происходит перегруппировка или объединение атрибутов для вновь формирующихся объектов, обеспечивается далеко не всеми системами. Одна из очень серьезных и важных на практике аналитических функций ГИС - задачи районирования территории по комплексу признаков, выбора оптимального месторасположения нового объекта и др. 4. Анализ пространственных данных, включающий рассмотрение их описательных характеристик, таких, например, как средний размер населенных пунктов в пределах определенной территории или урожай зерновых в пределах определенной климатической зоны. 5. Различные виды статистики по атрибутам (непространственной) по пространственным объектам (+ картографическое представление результатов). 6. Пространственная статистика, включающая характеристики размещения объектов, но не включающая рассмотрение значений их атрибутов (например, характеристика степени равномерности (случайности) распределения объектов с помощью критерия хи-квадрат). 7. Пространственный анализ (использующий статистические методы или нет) формы объектов или других характеристик, требующих проведения пространственных измерений на самих объектах. 8. Пространственная статистика, включающая в рассмотрение как расположение, так и атрибутивные характеристики объектов (например, построение карт трендов, пространственная корреляция между удалением от дорожной сети и степенью нарушенности первичного биоценоза). 9. Пространственный анализ, использующий моделирование (" что если", моделирование процессов с построением их математических моделей...). 10. Интерактивный просмотр информации в пространственной базе данных с включением неформальных элементов анализа ее человеком (традиционный метод работы, где все решения и анализ - за человеком, а информационная система выполняет только техническую работу, обеспечивая удобство и наглядность работы с информацией за счет " количественного" фактора - увеличения скорости доступа к информации - обеспечивается качественный скачок. 11. Решение задачи методом организации запроса к пространственной базе данных - формулирование условий и ограничений для поиска объектов и визуализация найденных объектов. 12. Комбинирование логического и пространственного анализа - системы поддержки принятия решений и экспертные системы, учитывающие пространственную информацию.
3. Модели данных и их разновидности. Очень многое определяется разумной организацией данных в пространственной информационной системе. Модель данных - это концептуальный уровень организации данных, логический уровень. Если говорить о компьютерных моделях данных, то это всегда цифровое представление данных. Не только числовые характеристики, но и информация положения, и пространственная геометрическая (положения и формы), и пространственная топологическая (взаиморасположение и связи объектов), и описательная словесная (неколичественная) информация всегда в компьютерных моделях данных присутствуют в числовой форме. Выбор того или иного способа организации данных в ГИС определяет очень многое, почти все. Определяет гораздо больше, чем выбор того или иного конкретного программного пакета. Выбор модели данных напрямую определяет многие функциональные возможности создаваемой ГИС, так как некоторые функции по работе с пространственной информацией просто невозможно реализовать для определенных типов организации данных, или эти функции будут обеспечиваться только путем чрезмерно сложных манипуляций. Способ организации данных в ГИС, то есть выбранная модель данных, напрямую определяет также и применимость тех или иных технологий ввода данных. От выбора модели данных в не меньшей степени зависит также достижимая пространственная точность представления геометрической информации, возможность накопления в пространственной базе качественного, кондиционного и внутренне непротиворечивого материала. Возможности по организации тех или иных процедур контроля качества и непротиворечивости пространственных данных существенно зависят от выбранной модели данных. Возможность организовать работу с большими объемами данных или с точными данными по большим территориям также связана не только с особенностями и ограничениями конкретного программного пакета, но в еще большей мере - с типом и особенностями выбранной модели данных. Такие важные для практики аспекты, как удобство редактирования и обновления данных, возможность организации многопользовательской работы с пространственной базой данных в режиме редактирования - тоже связаны в первую очередь с моделью организации данных, и уже во вторую - с выбором конкретного программного обеспечения. Ошибки в решении этого вопроса могут проявиться решающим образом в самой возможности выполнения ГИС требуемых функций, в возможности расширения списка этих функций в будущем, в успешности или неуспешности проекта с экономической точки зрения и, что очень важно - могут определить ценность накапливаемых пространственных баз данных в долговременной перспективе. Будут ли Ваши данные совместимы с другими, будут ли они нужны другим, наконец, не придется ли Вам на каком-то этапе эксплуатации и развития системы бросить все и переходить на принципиально другую систему, поддерживающую другую модель данных, и придется ли Вам при этом отвергнуть весь уже накопленный материал и вводить его заново, или нет - это во многом зависит от правильного ответа на вопрос о выборе способа организации пространственных данных, модели данных. Как известно, обмен данными между двумя разными ГИС и даже полная смена программного пакета - обычно не очень большая проблема, если используемые в них модели данных близки. Индивидуальные объекты могут иметь различную размерность в геометрическом смысле - быть точечными (нулевая длина и ширина, размерность 0), линейными (нулевая ширина при ненулевой длине, размерность 1) и площадными (ненулевая длина и ширина, размерность 2). Следует отделять от понятия размерность объекта понятие размерности пространства его описания. Линейное пространство (размерности 1) - это, например, система координат вдоль линии, такая как километровые столбы вдоль шоссе; двумерное плоское пространство (размерности 2) - это, например, карта с системой картографических координат; трехмерное пространство (размерности 3) - это наше обычное " реальное" пространство. Такого типа пространство удобно для описания пространственных данных об объектах местности вместе с рельефом местности, на которой они находятся, для работы с перспективным изображением местности, для создания, как сейчас принято говорить, " виртуальных" отображений действительного или смоделированного ландшафта - высокореалистичного и динамичного его отображения. Легко заметить, что размерность пространства описания связана определенным образом с размерностью объекта, а именно: максимальная размерность объекта равна размерности пространства описания. На линии можно расположить точечные и линейные объекты, на карте - точечные, линейные и площадные, в трехмерном пространстве - точечные, линейные, площадные и объемные. Объекты могут относиться к разным категориям и находиться между собой в сложных соотношениях, например, образовывать иерархические структуры соподчиненности. К примеру, линейные объекты могут быть реками (элемент гидрографии), железными дорогами, автомобильными дорогами, центральными линиями улиц (элементы транспортной сети), линиями газопроводов, линиями нефтепроводов (элементы трубопроводной сети). Автомобильные дороги, например, могут быть далее подразделены на множество различных классов по разным их признакам и сочетаниям признаков (значение, ширина, число полос движения, тип дорожного покрытия, его состояние, время постройки, время и содержание последнего ремонта или инспекции, принадлежность к той или иной организации обслуживания, интенсивность движения - может быть, разная в разное время суток, день недели, сезон - дальше можно продолжать очень долго). И из этих признаков можно построить не единственную систему классификации дорог - в зависимости от того, какие признаки считать более существенными, а какие -относительно менее существенными, им подчиненными. Ясно, что такие смысловые подразделения и группировки объектов в разные категории не могут быть абсолютными на все случаи жизни - выбор той или иной из них зависит от стоящих перед нами задач. С индивидуальным объектом, если мы хотим трактовать его как индивидуальный, должен быть связан его уникальный идентификатор - например, какой-то номер, формально присваиваемый ему программой в процессе ввода или имеющий содержательный смысл и вне пространственной базы данных, например, его номер по какому-то перечню или кадастру. Это может быть, в принципе, и какое-то уникальное нечисловое имя - например, уникальное название, неповторяющееся более нигде в пределах области изучения. (Или только той ее части, в пределах которой требуется сохранять уникальность идентификаторов. В последнем случае мы имеем как бы двухуровневое деление, и имя (код) этой части может рассматриваться как составная часть идентификатора (префикс идентификатора) объекта.) В общем, идентификатор необходим, в противном случае объект не является уникальным и его нельзя трактовать как в полной мере индивидуальный, самостоятельный. Тем не менее, естественно, что информация о положении (а также форме, размерах) объекта крайне важна в ГИС. Обычно такую информацию, как бы она ни была выражена - числовыми координатами, или как-то еще, называют информацией положения (локатором) и отделяют ее от информации идентификации (идентификатора). Вся остальная информация об объекте может рассматриваться как его атрибуты - набор характеристик. Атрибуты можно подразделить на пространственные и непространственные. Пространственные - это, например, периметр и площадь площадного объекта, длина линейного. Непространственные атрибуты могут быть самыми различными - числовыми, текстовыми значениями каких-то величин, описывающих объект. Пространственные атрибуты часто являются функциями параметров положения - например, периметр площадного объекта может рассчитываться из координат слагающих его контур точек. Можно говорить об объектах элементарных (обычно это точка, линия и полигон) и об объектах неэлементарных (группировках), представляющих объединения (постоянные или временные группировки) элементарных объектов. Если такая группа в свою очередь имеет уникальный идентификатор, то она тоже может рассматриваться как индивидуальный объект. Такая группировка может быть организована на базе как однотипных, так и разнотипных объектов. В последнем случае назовем такие объекты (группировки) комплексными объектами. Более того, в нее могут входить также и объекты неэлементарные, которые уже, в свою очередь, являются группировками. Чуть подробнее коснемся атрибутов объектов. Для них важнейшей характеристикой является тип использованной шкалы измерений. Общепринято деление шкал (и, соответственно, данных в этих шкалах) на " качественные" и " количественные". К " качественным" относят шкалы номинальную (наименований) и ординальную (порядковую, ранговую). К " количественным" относят интервальную (интервалов) и рациональную (отношений) шкалы. Отметим, что это деление не имеет ничего общего с формой записи или кодированием значений - и данные в номинальной шкале могут быть представлены (и всегда в конечном счете представляются в компьютере) числом. Но это число как бы и не численное значение, это просто код класса, число здесь выступает просто как заменитель названия. В случае номинальной и порядковой шкал для этого числа не имеют смысла некоторые арифметические операции (для порядковой шкалы - имеется только операция упорядочения и сравнения " больше-меньше-равно", а для номинальной -только сравнение " равно-не равно" ). Кроме этого, атрибуты могут быть первичными (измеренными, введенными) и вторичными, расчетными, полученными расчетом из значений других атрибутов. Частный случай таких вторичных рассчитываемых - это атрибуты (обычно пространственные), которые рассчитываются исходя из позиционных параметров объектов (например, периметр). В современных ГИС возможно иногда связывание с объектом некоторого действия, например, запуск какой-то программы при активизации объекта указанием на него. Возможно также при активизации объекта (например, площадного объекта " Московская область" на карте России) перейти к другой карте - более подробной карте Московской области с районным делением или к карте Москвы - столице области. Таким образом другую карту, организованную в рамках той же (например, векторно-топологической) или другой (например, растровой) модели данных или какой-то индивидуальный объект в них можно тоже рассматривать в качестве атрибута первого объекта. При этом возможна организация связи между ними различным образом, в том числе с установлением иерархических связей соподчиненности между как индивидуальными объектами, так и их множествами (картами, тематическими слоями). Все это позволяет создавать конкретные структуры баз данных очень сложные и изощренные. Некоторое свойство, непрерывно распределенное в пространстве, например, на земной поверхности, удобно в математическом смысле рассматривать в качестве поля. (Вообще говоря, разного вида - скалярного, векторного, тензорного, трехмерного или двумерного, определенного только на поверхности земли или с ней не связанного, а только проектируемого на нее или пересекаемого ею). Типичные формы представления подобных непрерывных свойств таковы: Нерегулярная сеть точек - произвольно расположенные точечные объекты, в качестве атрибутов имеющие значение поля в данной точке. С помощью такого способа представления, если не иметь очень густо расположенных по сравнению с пространственной изменчивостью поля точек, трудно гарантировать его адекватное представление. Сеть может быть слишком редкая, или точки, выбранные случайно, не попадают на характерные представительные места/значения, или, наоборот, точки выбраны неслучайно и тоже не являются представительными (например, все значения кислотности почвы измерялись только там, где можно было легко передвигаться по местности, то есть на голых водоразделах, а не в заболоченных речных долинах). Способ представления изолиниями - наиболее распространен в традиционной картографии. Обычно нет никакой информации о поведении поля между изолиниями, и вторая проблема состоит в том, что по одним и тем же исходным данным (обычно это точки нерегулярной сети) интерполяция и последующее проведение изолиний может быть сделана не единственным способом. Способ представления очень привычный, но не самый удобный для анализа. Наиболее удобен для многих случаев вариант, когда поля задаются регулярно расположенными в пространстве точками достаточной густоты (регулярная модель" ), особенно когда это точки не интерполированные из нерегулярных, а измерения, проведенные по регулярной сети. Из них легко перейти к любой другой форме представления. Несколько особняком стоит модель данных TIN (Triangulated Irregular Network), специально предназначенная для представления поверхностей значений, полей (например и в первую очередь - поверхности рельефа местности). Это также нерегулярная сеть точек, но точек связанных, соединенных особым образом выбранной сетью прямых отрезков, при этом эти отрезки (называемые часто ребрами - edges) образуют множество треугольников, как бы грани (фасеты). Наличие таких связок между точками дает некоторое представление (линейное приближение) о поведении поля (или форме поверхности) на данном участке в промежутке между точками. Поэтому модель данных типа TIN часто позволяет получать более качественное и более экономное представление поверхностей (полей). В особенности удачным оказывается применение этой модели данных для ситуации, когда изменчивость поля (например, рельефа местности) очень разная в разных частях территории, например, если район изучения захватывает и горный район, и плоскую предгорную равнину. К сожалению, многие типы аналитических задач трудно выполнимы на этом типе модели данных. Несколько схематизируя ситуацию, заметим, что в ГИС о модели данных можно говорить в нескольких смыслах. Во-первых, сами пространственные данные, а это в значительной части графическая, позиционная компонента, могут быть организованы различно по своему внутреннему устройству, в соответствии с разными моделями. Во-вторых, можно говорить и о разных моделях организации атрибутивных данных внутри себя, безотносительно к графической компоненте. Наконец, и это уже момент, специфичный именно для ГИС, можно говорить о разных моделях отношений между пространственной и атрибутивной информацией, или, упрощая, между графической и описательной. Такое раздельное рассмотрение названных аспектов полезно не всегда, иногда модель данных весьма тесно интегрирует пространственную и атрибутивную информацию. Выделим два общих принципа (подхода) к организации пространственных данных. Это различные принципы группировки объектов в логически связанные структуры более высокого порядка. (Они могут в той или иной мере сочетаться с разными только что описанными моделями взаимоотношений пространственных объектов и их атрибутов.) Один - это принцип послойной организации информации (его часто называют классическим), второй - опять же основан на объектно-ориентированном подходе. Надо сразу отметить, что объектно-ориентированный подход здесь понимается не обязательно в том смысле, что в объектно-ориентированном программировании и что между двумя упомянутыми принципами организации информации " антагонистического противоречия", конечно, нет. Послойный принцип организации информации заключается в том, что находится некоторое деление объектов на тематические слои; и объекты, отнесенные к одному слою, образуют некоторую логически (а часто и физически) отдельную единицу данных - например, они собираются в один файл или в одну директорию, они имеют единую и отдельную от других слоев систему идентификаторов, к ним можно обращаться как к некоторому множеству. Например, мы выносим в один слой все объекты гидрографии, или все шоссейные дороги, или все, относящееся к растительному покрову. Чаще всего при этом организуется также и деление одного тематического слоя по горизонтали - по аналогии с отдельными листами карт. Это делается в основном из удобства администрирования баз данных и чтобы избежать работы с чрезмерно большими файлами. Для случая векторно-топологических моделей данных (то есть тех, которые позволяют строить и хранить в самой модели данных топологические отношения между объектами) обычно существуют некот Популярное:
|
Последнее изменение этой страницы: 2016-03-25; Просмотров: 5284; Нарушение авторского права страницы
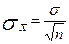 ,
, 
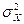 , а значение Y из совокупности, имеющей дисперсию
, а значение Y из совокупности, имеющей дисперсию  , то распределение всех возможных значений X-Y имеет дисперсию
, то распределение всех возможных значений X-Y имеет дисперсию .
.

 .
.
 .
.
 и
и  – это оценки одной и той же дисперсии σ 2. Поэтому их можно заменить на объединенную оценку дисперсии. Для выборок равного объема объединенная оценка дисперсии вычисляется как
– это оценки одной и той же дисперсии σ 2. Поэтому их можно заменить на объединенную оценку дисперсии. Для выборок равного объема объединенная оценка дисперсии вычисляется как .
. .
.
 ,
, 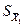 и
и  – стандартные ошибки средних для двух выборок. Если объем первой выборки равен и n1, а объем второй – n2, то
– стандартные ошибки средних для двух выборок. Если объем первой выборки равен и n1, а объем второй – n2, то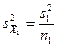 и
и 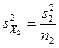 ,
,