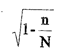|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Вычисление основных статистических показателей
Основные вопросы, рассматриваемые на лекции: 1. Назначение и разновидности основных математико-статистических показателей. 2. Виды ошибок исследований. 1. Назначение и разновидности основных математико-статистических показателей. Главная задача математической статистики заключается в сведении большого объема исходных количественных данных к нескольким математико-статистическим показателям. К ним относятся, прежде всего, простейшие показатели, характеризующие средний уровень и колеблемость (варьирование) исходных данных. Средний уровень описывается с помощью моды, медианы и средней арифметической, а колеблемость - размахом, средним абсолютным и средним квадратическим отклонениями, коэффициентом вариации. Мода - это наиболее часто встречаемое числовое значение признака из всех значений элементов изучаемой статистической совокупности. Положительная особенность моды заключается в том, что ее числовое значение не зависит от крайних значений. Медиана - срединное (центральное) значение признака в ранжированном ряду данных, расположенных в порядке возрастания признака. Проще - это середина ранжированного ряда. Однако в математико-статистических исследованиях наиболее часто и результативно используется показатель среднего уровня, названный средним арифметическим. Он служит для краткой, обобщенной характеристики статистической совокупности по какому-либо признаку. Географу часто приходится вычислять и использовать среднюю температуру воздуха. В статистическом показателе отбрасывается случайное и вскрывается наиболее типичное, существенное, характерное для всей статистической совокупности в целом. Особая ценность средней арифметической заключается в том, что она лежит в основе вычисления показателей колеблемости признаков, корреляционных зависимостей и других математико-статистических характеристик. Средняя арифметическая (
где хi — отдельные наблюдения; n - число наблюдений. Проверка правильности вычисления средней арифметической производится путем вычисления центральных отклонений (хi - Вычислим сумму центральных отклонений в нашем примере (см. табл. 1).
Таблица 1 – Вычисление средней арифметической
Формулу (1) применяют при сравнительно малом числе наблюдений. При большом числе n, когда происходит группировка данных, средний уровень проще вычислять по формуле взвешенной средней арифметической (2), где весами служат частоты.
где х, — центральные значения интервалов, m — частоты. Вычислим по этой формуле среднюю длину оврагов, сгруппированных в 5 интервалов: 10-20 м, 20-30 м, 30-40 м, 40-50 м и 50-60 м (см. лекцию 2, табл. 2). Середины (центры) этих интервалов будут соответственно равны 15, 25, 35, 45 и 55 м. Против каждого центра интервала проставим частоту. Затем найдем произведенние х-т (табл. 2).
Таблица 2 – Вычисление взвешенной средней арифметической
Вычисляем по формуле (2) среднюю арифметическую:
Роль средних исключительно велика. Они позволяют: 1) оценить значение отдельной величины путем сравнения ее со средней; 2) определить наличие связи между явлениями посредством анализа средних двух или нескольких признаков по одним и тем же территориям или временным промежуткам; 3) определить общую тенденцию развития явления. Приведем примеры на каждый из отмеченных направлений использования средних. 1. Скорости роста четырех оврагов в местах выпаса овец составляют 5, б, 8 и 9 м/год. Насколько овцы могут способствовать увеличению овражной эрозии, можно судить по тому, что средняя скорость роста оврагов в изучаемом районе только 2 м/год. 2. Рассматривая средние значения процента гумуса в почве (х) и урожайности зерновых (у) по отдельным районам изучаемой территории (табл. 3), можно обнаружить следующую закономерность: чем больше процент гумуса, тем больше урожайность. Таким образом, между взятыми признаками установлено наличие прямой зависимости. При рассмотрении всех наблюдений такую связь можно было бы и не заметить, так как во многих случаях при большом проценте гумуса могла быть малая урожайность и наоборот. Причина таких «аномалий» та, что на урожайность кроме природных свойств почв влияет множество других факторов, которые нивелируются в средних. Таблица 3 –– Зависимость урожайности зерновых от процента гумуса в почве
В качестве исходного количественного материала географ нередко использует средние арифметические с тем, чтобы по ним вычислить новые средние. Так, количественные характеристики климата, урожайности и ряда других явлений, изображаемых часто на картах, осреднены за какой-то промежуток времени (обычно за несколько лет). На основании этих данных исследователь может вычислить средний показатель на определенную территорию, например, среднюю урожайность в Алтайском крае, в России и т.д. Таким образом, здесь имеет место двойное осреднение — во времени и в пространстве. Другой пример такого осреднения. На изучаемой территории имеется определенное число оврагов, скорость роста которых меняется из года в год. Чтобы правильно судить о скорости роста каждого оврага, лучше рассматривать среднюю скорость роста его за те годы, когда велись наблюдения. Интенсивность овражной эрозии на всей территории будет выражаться средней арифметической из вычисленных средних для каждого оврага. В процессе укрупнения территориальных единиц осреднение может применяться многократно. Например, вычисляют среднюю урожайность зерновых по хозяйствам, полученные данные служат для расчета урожайности по районам, далее по областям, республикам, и, наконец, по России. Положительную роль пространственного и временного осреднения в географических исследованиях не следует преувеличивать. Более того, нужно иметь в виду, что средние по слишком крупным территориальным единицам или большим временным промежуткам могут не только сгладить, но и исказить реальную картину размещения и функционирования изучаемых явлений. По средней арифметической можно судить лишь о массовом уровне признака. Вторая основная проблема математической статистики заключается в выяснении степени колеблемости отдельных значений вокруг средней величины. Недостаточность и «однобокость» показателей среднего уровня покажем на следующем примере. В одной статистической совокупности изучаемый признак принимает следующие значения: 1, 3, 5, 7, 9; в другой - 3, 4, 5, 6, 7. В обоих случаях средняя арифметическая равна 5, однако разброс значений величин не одинаков (в первой совокупности он больше - от 1 до 9, во второй меньше - от 3 до 7). Необходимо ввести особые показатели изменчивости признака внутри статистической совокупности. Простейшим показателем колеблемости являются лимиты, то есть максимальные и минимальные значения количественных признаков статистической совокупности. В географических описаниях это наиболее распространенный показатель колеблемости. Примеры таких описаний: «Суточные суммы солнечной радиации в июле в Акмолинской области составляют 550-600 кал/кв.см, что больше, чем на тех же широтах в Поволжье», «Общие запасы перегноя и азота в полуметровой толще соответственно колеблются от 350 до 400 и от 23 до 25 т на гектар». По лимитам можно судить не только об амплитуде колебания количественных показателей, но и о среднем уровне, который обязательно занимает промежуточное положение между максимумом и минимумом. Разность между максимальным и минимальным значениями признака называют размахом. Он часто приписывается к лимитам в скобках. Степень разнообразия признака более точно выражается рядом других показателей. Разберем некоторые из них. При проверке вычисления средней арифметической скорости роста оврагов, были найдены центральные отклонения (хi -
В математической статистике отдают предпочтение другому показателю степени колеблемости - среднему квадратическому отклонению, который вычисляется следующим образом. Каждое центральное отклонение возводится в квадрат. Затем находят среднюю арифметическую из этих квадратов и извлекают из нее квадратный корень. Формула среднего квадратического отклонения:
где d (сигма) - знак среднего квадратического отклонения. Схема вычисления дана в таблице 6. Более правильно в знаменателе подкоренного выражения ставить не n, a n - 1. Однако при достаточно большом числе наблюдений уменьшение знаменателя на 1 практически не скажется на значении 6. Таблица 6 – Схема, облегчающая вычисление среднего квадратического отклонения
Результаты вычислений могут быть записаны в следующем виде:
Средние квадратические отклонения обычно несколько больше средних абсолютных отклонений (примерно на 1/4). Вычисление взвешенного среднего квадратического отклонения при сгруппированных данных производится по формуле
Следовательно, длины 25 рассмотренных оврагов можно охарактеризовать двумя числами: 37 ± 10, 2 м. В теоретических формулах d часто выступает возведенной в квадрат. Эта величина называется дисперсией. Она также является мерой колеблемости признака. Средние квадратические отклонения климатических, почвенных, экономических показателей строго закономерны в пределах изучаемых территорий и отрезков времени. К сожалению, до сих пор при изучении колеблемости признаков географы весьма редко прибегают к вычислению d и даже q, а ограничиваются рассмотрением более простого, но менее корректного показателя колеблемости - размаха. Пример: основной показатель вертикального расчленения рельефа обычно представляет собой разность максимальной и минимальной высот. По матеатико-статистической терминологии это «размах» высот. Правильнее было бы вычислить d или хотя бы q. Среднее квадратическое отклонение является размерным показателем колеблемости признака. Оно выражается в тех же единицах, что и варианты признака. Поэтому сигма может служить непосредственным показателем колеблемости только тогда, когда сравниваются однородные количественные признаки. Пример сравнения колеблемости неоднородных признаков: имеются данные о значениях средних квадратических отклонений следующих показателей природных условий в одном и том же районе (табл. 8): Таблица 8 – Сравнение неоднородных признаков
По этим числам невозможно установить, какой из приведенных признаков варьирует больше, а какой меньше. Действительно, метры нельзя сравнить с процентами и градусами, так как единицы измерения оказываются разными. Поэтому для сравнения разнородных признаков введен особый показатель - коэффициент вариации (V), представляющий собой отношение d к
Зная средние арифметические и средние квадратические отклонения признаков, указанные в нашем примере, по формуле (6) можно вычислить коэффициенты вариации (см. табл. 9).
Таблица 9 – Схема вычисления коэффициента вариации
Оказалось, что на исследуемой территории наиболее изменчивым количественным признаком является длина оврагов (V1 = 50%), а наименее изменчивы углы наклона (V3 = 10%). Обратим внимание на то, что коэффициент вариации применим для сравнения колеблемостей только тех количественных показателей, которые не могут принимать отрицательных значений. Этому условию полностью отвечают признаки, рассмотренные в таблице 9. Действительно, длины оврагов, распаханность и углы наклонов площадей водосборов немыслимы со знаком минус. То же можно сказать и о вещественных разновидностях продукции промышленного и сельскохозяйственного производств, о вещественных природных ресурсах (биологических, водных, минеральных). Не удовлетворяют отмеченному условию высоты земной поверхности, температуры, предельно-допустимые нормы концентраций (ПДК). В зависимости от выбора точки отсчета этих показателей будут изменяться значения вычисленных средних арифметических и зависимых от них коэффициентов вариации. Например, коэффициент вариации абсолютных высот земной поверхности окажется гораздо меньше коэффициента вариации относительных высот, началом отсчета которых служат самые различные высотные уровни. Аналогично численные значения коэффициента вариации температур будут зависеть от выбора точки их отсчета (точки кипения, замерзания и др.). 2. Виды ошибок исследований. Полученные в результате измерений количественные показатели явлений имеют ошибки самого разнообразного характера. Можно выделить следующие группы ошибок: 1. Ошибки методические, вызванные применением неправильной методики исследований. 2. Ошибки точности (инструментальные, картографические, расчеты с недостаточной точностью). 3. Ошибки репрезентативности, имеющие место при выборочном исследовании, когда используется только определенная часть генеральной совокупности. Избежать этих ошибок нельзя, однако их размеры можно свести к минимуму правильной организацией выборочного наблюдения. Кроме того, разработаны методы, дающие возможность по выборочным данным определять значения ошибок репрезентативности (см. ниже). Следует заметить, что расчет последних возможен только для выборочных показателей. Если же исследуется вся генеральная совокупность (например, все хозяйства или все населенные пункты на данной территории), то определять эти ошибки не имеет смысла - они фактически отсутствуют. Ошибка репрезентативности средней арифметической зависит от колеблемости признака в генеральной совокупности и от численности выборки. Предположим, что колеблемость признака в генеральной совокупности равна нулю (например, когда урожайность зерновых в различных местах изучаемой территории одинакова). В таком случае одно наблюдение дает точную, безошибочную характеристику генеральной совокупности. Чем больше колеблемость признака, тем больше вероятность попасть в такую выборку, средняя которой будет сильно отличаться от средней генеральной совокупности. Легко можно понять и зависимость ошибки выборочного х от объема выборки. Чем больше число наблюдений, тем большая часть генеральной совокупности исследуется, и, следовательно, тем с меньшей ошибкой может быть дано заключение о средней для всей генеральной совокупности. При увеличении объема выборки ошибка средней уменьшается, и, когда число наблюдений достигнет численности генеральной совокупности, ошибка выборочной средней станет равной нулю. Если выборочная совокупность составляет не менее 30-50% от генеральной совокупности, то применяется следующая формула расчета ошибки выборочной средней арифметической (
где d - среднее квадратическое отклонение выборки; n - объем выборки; N - объем генеральной совокупности. При бесконечно большой генеральной совокупности, то есть при N = Приведем примеры. 1. Исследовалась урожайность зерновых на территории, где расположено 800 хозяйств. Решено отобрать из них 400. Оказалось, что среднее квадратическое отклонение урожайности d = 2 ц/га, а средняя урожайность Выборка составляет 50% генеральной совокупности, следовательно, используем формулу (7).
Окончательный результат расчета записывается следующим образом:
Это значит, что действительный размер средней урожайности в изучаемом районе в большинстве случаев (в 68 случаях из 100) не будет отличаться от вычисленной свыше 0, 07 ц/га в ту и другую сторону. Предельные же отклонения выборочной средней практически не превысят 2-3, то есть действительное значение средней урожайности может находиться в пределах 7, 99-8, 41 ц/га.
Когда численность выборки приближается к численности всей генеральной совокупности (n —> N), ошибка средней близка к нулю. ности (не менее 30-50%). Когда же объем выборки не более 5-10%, множитель
2. Из 800 хозяйств решили взять только 25. Предположим, что q и х получились такие же, как и в первом примере. Выборка составляет примерно 30% генеральной совокупности, поэтому воспользуемся формулой (8)
При достаточно большом объеме выборки ошибка репрезентативности среднего квадратического отклонения определяется по формуле
где d - среднее квадратическое отклонение выборки, n - число наблюдений. Из формулы (9) видно, что ошибка среднего квадратического отклонения так же, как и ошибка средней арифметической, зависит oт значения сигмы и от числа наблюдений. Точность определения среднего квадратического отклонения будет тем больше, чем меньше его численное значение и больше объем выборки. Покажем вычисление ошибки выборочного среднего квадратического отклонения по данным примера, когда d=2ц/гa и n=200;
При малом объеме выборки по сравнению с объемом генеральной совокупности ошибка среднего квадратического отклонения меньше ошибки средней арифметической примерно на ч/2 = 1, 4
ВОПРОСЫ И ЗАДАНИЯ 1. Каковы назначение и разновидности основных математико-статистических показателей? 2. Напишите формулу средней арифметической. 3. Напишите формулу взвешенной средней арифметической. 4. Что такое лимиты и размах? 5. Приведите формулы среднего абсолютного и среднего квадратического отклонений. 6. Как выглядит формула среднего квадратического отклонения при сгруппированных данных? 7. Объясните, что такое коэффициент вариации и условия его применения? 8. Как вычисляются ошибки средней арифметической? 9. Как вычислить ошибки среднего квадратического отклонения?
Лекция № 6 Популярное:
|
Последнее изменение этой страницы: 2016-03-25; Просмотров: 1759; Нарушение авторского права страницы
 ) вычисляется по формуле
) вычисляется по формуле









 ):
): 
 , формула упрощается (8).
, формула упрощается (8).