
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Введение в корреляционно-регрессионный анализ.
Соотношения между экономическими переменными. Одна из наиболее общих задач в экономических исследованиях состоит в оценивании степени зависимости изучаемой величины Y от одной или нескольких случайных (или неслучайных) величин X, называемых факторами. Зависимость может быть функциональной, статистической, либо отсутствовать вовсе. Строгая функциональная зависимость между экономическими показателями (наличие всегда выполняющегося равенства Y=f(X)) реализуется редко, так как они подвержены влиянию случайных факторов. При статистической зависимости изменение одной из величин влечет изменение распределения другой (в частности, среднего значения; в этом случае статистическую зависимость называют корреляционной). Причем, всегда есть несколько величин, которые определяют главные тенденции изменения рассматриваемой величины, и в экономической теории и практике ограничиваются тем или иным кругом таких величин (объясняющих переменных). Однако всегда существует и воздействие большого числа других, менее важных или трудно идентифицируемых факторов, приводящее к отклонению значений объясняемой (зависимой) переменной от конкретной формулы ее связи с объясняющими переменными, сколь бы точной эта формула ни была. Нахождение, оценка и анализ таких связей, идентификация объясняющих переменных, построение формул зависимости и оценка их параметров и составляют предмет корреляционно-регрессионного анализа, при этом корреляционный анализ занимается исследованием взаимозависимости случайных величин, тогда как регрессионный анализ на базе выборочных данных исследует зависимость случайной величины от ряда неслучайных и случайных величин. Примерами корреляционно, но не функционально, связанных величин являются объемы производства и себестоимость продукции, объемы продаж и прибыль, урожай зерна и количество внесенных удобрений. Действительно, в последнем примере с одинаковых по площади участков земли при равных количествах внесенных удобрений снимают различный урожай, т.е. отсутствует функциональная связь. Это объясняется влиянием случайных факторов (осадки, температура, качество семян и др.). Вместе с тем, как показывает опыт, средний урожай меняется с изменением количества удобрений, т.е. прослеживается корреляционная зависимость. Рассмотрим сначала однофакторную регрессионную модель. В этом случае имеется n пар наблюдений (xi, yi), i=1, 2, …, n, над некоторыми случайными величинами Х={xi} и Y={yi}. Эти наблюдения можно представить точками на плоскости с координатами (xi, yi), получая так называемую диаграмму рассеяния. Задача построения регрессионной модели заключается в том, что необходимо подобрать некоторую кривую (график соответствующей функции) таким образом, чтобы она располагалась как можно “ближе” к этим точкам. Такого рода кривую называют эмпирической или аппроксимирующей кривой. Весьма часто тип эмпирической кривой определяется экспериментальными или теоретическими соображениями (исходя из законов экономической теории), в противном случае выбор кривой осуществить довольно трудно. Иногда точки на диаграмме рассеяния располагаются таким образом, что не наблюдается никакого их группирования, и, соответственно, нет никаких оснований предполагать наличие в наблюдениях какой-либо взаимозависимости. Таким образом, результатом исследования статистической взаимозависимости на основе выборочных данных является построение уравнений регрессии вида y=f(x). Линейная связь, корреляция. В самом простом случае предполагается, что f задает уравнение прямой f(x)=a0+a1х. Модель в этом случае имеет вид уi=a0+a1хi+ei (i=1, 2, …, n). (1) Здесь ei являются вертикальными уклонениями точек (xi, yi) от аппроксимирующей прямой. Вопрос о нахождении формулы зависимости можно ставить после положительного ответа на вопрос о существования такой зависимости, но эти два вопроса можно решать и одновременно. Для ответа на поставленные вопросы существуют специальные методы и, соответственно, показатели, значения которых определенным образом свидетельствуют о наличии или отсутствии линейной связи между переменными. Такими показателями являются коэффициент корреляции величин Х и Y, а также коэффициенты линейной регрессии a0 и a1, их стандартные ошибки и t-статистики, по значениям которых проверяется гипотеза об отсутствии связи величин Х и Y. Угловой коэффициент a1 прямой линии регрессии Y на X называют коэффициентом регрессии Y на X и обозначают ryx. Выражение sх2 = Выборочный коэффициент корреляции определяется равенством
где sy есть выборочное среднее квадратическое отклонение Y. (Верхняя черта, как это принято в теории вероятностей и математической статистике, означает среднее значение выборочной совокупности, в данном случае Коэффициент корреляции измеряет силу (тесноту) линейной связи между Y и X. Он является безразмерной величиной, не зависит от выбора единиц измерения обеих переменных. Для него всегда выполняется 0 £ |ryx| £ 1, и чем ближе его значение к ±1, тем сильнее линейная связь. Коэффициент корреляции будет положительным, если зависимость переменных Х и Y прямо пропорциональная, и отрицательным, – если обратно пропорциональная. При близости к нулю коэффициента корреляции, например, величин уровней инфляции и безработицы (что имело место фактически в экономике США в 1970-х – 1980-х годах) нужно не говорить сразу о независимости этих показателей, а попытаться построить более сложную (не линейную) модель их связи.
Популярное: |
Последнее изменение этой страницы: 2016-03-25; Просмотров: 660; Нарушение авторского права страницы
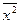 –(
–(  )2 есть выборочная дисперсия Х (или квадрат выборочного среднего квадратического отклонения).
)2 есть выборочная дисперсия Х (или квадрат выборочного среднего квадратического отклонения).
 ryx =(ху – х× у )/(sхsy), (2)
ryx =(ху – х× у )/(sхsy), (2)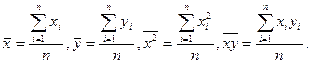 ).
).