
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Таким образом, получено уравнение регрессии
ŷ = – 0, 974 + 0, 01924х. Коэффициент регрессии a1=0, 01924 показывает, что увеличение среднесписочной численности на одного человека приводит к увеличению объема товарооборота в среднем на 19, 24 млн. руб. Это своего рода эмпирический норматив приростной эффективности использования работников данной группы магазинов. Если увеличение численности на одного работника приводит к меньшему росту объема товарооборота, то прием его на работу необоснован.
ryx = 0, 01924√ 544, 5/0, 2075= 0, 9856, что свидетельствует о наличии тесной линейной связи между численностью работников и розничным товарооборотом. В столбцах 8 и 10 табл.1 вычислены выровненные значения эмпирической функции регрессии и квадраты их отклонений от наблюденных значений. В соответствии с (8) получаем оценку дисперсии случайной составляющей
В соответствии с (9) значение коэффициента детерминации R2= 1 – Š 2/S2 = 1 – 0, 0479/1, 66=0, 971 показывает, что 97, 1% общей вариабельности розничного товарооборота объясняется изменениями числа работников, в то время как на все остальные факторы приходится лишь 2, 9% вариабельности. Найденные отклонения фактических значений от выровненных (столбец 9) позволяют провести сравнительный анализ работы различных магазинов. Прежде всего, необходимо обратить внимание на магазины с отрицательным отклонением (3, 4, 6). Особенно велико отклонение у 4-го магазина. Необходимо внимательно обследовать эти магазины и установить причины отклонений. Это может быть расположение магазина в стороне от основных потоков покупателей, плохое обслуживание, неудовлетворительный кадровый состав и т.п. Здесь, по-видимому, имеются резервы в организации труда работников. Напротив, в магазинах 1, 2, 5, 7 и 8 работники используются эффективнее статистического «норматива», но может оказаться, что эти магазины объективно находятся в лучших условиях. Обозначим Sx=å i(xi – Значимость оцененного коэффициента регрессии a1 может быть проверена с помощью анализа его отношения к своему стандартному отклонению
Эта величина имеет распределение Стьюдента с (n – 2) степенями свободы и называется t-статистика. (см. приложение 1). Можно использовать следующее грубое правило для оценки значимости коэффициента линейной регрессии: - если t< 1, то он не может быть признан значимым, поскольку доверительная вероятность здесь составляет менее 0, 7; - если 1< t< 2, то сделанная оценка может рассматриваться как более или менее значимая, доверительная вероятность здесь примерно от 0, 7 до 0, 95; - значение 2< t< 3, свидетельствует о весьма значимой связи (доверительная вероятность от 0, 95 до 0, 99); - t> 3 есть практически стопроцентное свидетельство ее наличия. Сформулированными правилами можно надежно пользоваться при n³ 10.
Для оценки тесноты любой корреляционной связи вводится корреляционное отношение Y к Х как отношение межгруппового среднего квадратического отклонения к общему среднему квадратическому отклонению признака Y:
Чем ближе корреляционное отношение к 1, тем теснее связь между признаками, однако, оно не задает вида этой связи и не позволяет судить о степени близости наблюдений к какой-либо кривой. Пример 2. Пусть имеется распределение 50 га пахотной земли по количеству внесенных удобрений х (ц на 1 га) и по урожайности у (ц с 1 га), приведенное в табл. 2. В этой таблице, например, число 4, стоящее на пересечении 1-й строки и 1-го столбца, показывает, что на 4 га из 50 было внесено по 10 ц удобрений и при этом получена урожайность по 15 ц с га. Найти уравнение прямой линии регрессии Y на Х, коэффициент корреляции и корреляционное отношение по данным корреляционной табл. 2. Таблица 2
Вычислим сначала все средние и дисперсии:
Тогда коэффициент корреляции из (2) ryx =(354 – 20.4× 17.4)/(6.62× 4.27)= – 0.034, коэффициент регрессии из (7) ryx = –0.034× 4.27/6.62= –0.022, уравнение прямой регрессии имеет вид
и корреляционное отношение из (11) hyx=2.73/4.27=0.64. Из вычисленных показателей можно сделать следующий вывод: Линейной связи между признаками нет, но какая-то связь есть, причем весьма существенная. Диаграмма рассеяния и прямая линия регрессии построены на рис.1. (В кружках проставлены nyx).
Рис.1. Диаграмма рассеяния (пример 2). Множественная регрессия. Значения экономических переменных определяются обычно влиянием не одного, а нескольких объясняющих факторов. Задача оценки статистической взаимосвязи переменных у и х =(х1, х2, …, хm) формулируется аналогично случаю парной регрессии. Ищется функция у=f(a, х )+e, где a– вектор параметров, e– случайная ошибка. В простейшем случае анализируется линейная зависимость у от х. Уравнение множественной линейной регрессии имеет вид у=a0+a1х1 +a2х2 +…+amхm+e. (12) Если имеется n наблюдений факторов х и переменной у, то отклонение зависимой переменной у в j-м наблюдении от линии регрессии ej= уj – a0 – a1хj1 – a2хj2 – … – amхjm (j=1, 2, …, n). Построение функции (12) проводится в два этапа. На первом этапе необходимо произвести отбор факторов. Сначала вычисляются коэффициенты корреляции rik по формуле (2) между выборочными значениями факторов Хi={xji} и Хk={xjk}. Если |rik|> 0.8 (наблюдается сильная линейная связь между факторами Хi и Хk), то один из них отбрасывается (в принципе, любой, но рекомендуется отбрасывать тот, информацию по которому труднее собрать или она менее достоверна). Затем вычисляются коэффициенты корреляции riу по формуле (2) между выборочными значениями фактора Хi={xji} и Y={yj}. Если |riy|< 0.2 (практически отсутствует линейная связь между фактором Хi и анализируемым показателем Y), то и этот фактор отбрасывается. На втором этапе для оставшихся факторов применяется метод наименьших квадратов. Метод наименьших квадратов предполагает поиск коэффициентов ai таких, что Q=å ej2®min. Для отыскания минимума берутся частные производные Q по искомым параметрам (мы использовали этот метод в случае однофакторной регрессии для нахождения a0 и a1) и приравниваются к нулю. После выполнения элементарных преобразований получают так называемую систему нормальных уравнений, из которой и находятся искомые параметры. Система нормальных уравнений для многофакторной регрессии имеет вид:
a0 …………………………………………….. a0 Для решения системы (13) можно использовать любой метод решения системы линейных уравнений (Гаусса, Крамера и пр.). Оцененное уравнение описывает как общий тренд (тенденцию) изменения зависимой переменной у, так и отклонения от этого тренда. Проблема здесь состоит не только в том, чтобы объяснить возможно большую долю колебаний переменной у, но и отделить влияние каждого из факторов.
Коэффициенты множественной линейной регрессии ai имеют большой экономический смысл. Они показывают, на сколько изменится анализируемый показатель Y при изменении фактора Хi на единицу. Пример 3. Рассмотрим аналитические модели спроса, используя ниже приведенные в табл.3 конкретные статистические данные обследования семей, сведенные в девять групп (с примерно одинаковым объемом потребления). Таблица 3.
Рассмотрим сначала однофакторную линейную модель зависимости расходов на питание (у) от величины душевого дохода (х1) ŷ =а0 + а1х1, параметры которой а0 и а1 находятся по формулам (6), используя данные табл.3 и
Rŷ х1 =√ 1 – 63846/454070 =0, 927. Полученное значение свидетельствует, что связь между расходами на питание и душевым доходом очень тесная. Величина R2ŷ х1 показывает долю изменения результативного признака под воздействием факторного признака. В нашем примере R2ŷ х1 =0, 859; это означает, что фактором душевого дохода можно объяснить почти 86% изменения расходов на питание. Рассмотрим теперь двухфакторную линейную модель зависимости расходов на питание (у) от величины душевого дохода (х1) и размера семьи (х2) ŷ =а0 + а1х1+ а2х2 . Параметры модели а0, а1и а2 находятся посредством решения следующей системы нормальных уравнений:
6080, 5а0 + 63989644, 1а1 + 21649, 1 а2 = 10894351 3, 1а0 + 21649, 1а1 + 10, 2а2 = 4488, которую решаем, например, методом Гаусса. Делим второе и третье уравнения на коэффициент при а0.
а0 + 10523, 75а1 + 3, 56 а2 = 1791, 69 а0 + 6983, 58а1 + 3, 29а2 = 1447, 74. От второго и третьего уравнения отнимаем первое
4443, 25а1 + 0, 46 а2 = 477, 79 903, 08а1 + 0, 19а2 = 133, 84. Делим второе и третье уравнения на коэффициент при а1.
а1 + 0, 0001035 а2 = 0, 1075316 а1 + 0, 0002104а2 = 0, 1482039. От третьего уравнения отнимаем второе
а1 + 0, 0001035 а2 = 0, 1075316 0, 0001069а2 = 0, 0406723. Из третьего уравнения находим а2 =380.47; подставляя его во второе уравнение получаем а1 = 0, 06815; подставляя найденные а1и а2 в первое уравнение, получаем а0 = –279.94; следовательно ŷ = –279.94 + 0.06815х1+ 380.47х2 . Для определения тесноты связи предварительно вычисляются теоретические значения ŷ , затем уклонения ej и их квадраты (колонки 5, 6, 7 табл.3). Получим Sŷ 2 =(∑ (у – ŷ )2)/n =2198, 2. Используя ранее вычисленное Sу2=454070, получим R2 =1 – Sŷ 2/ Sу2 =0, 995. R2 показывает долю вариации результативного признака под воздействием изучаемых факторных признаков. У нас R2=0, 995; это означает, что совместное влияние душевого дохода и размера семей объясняет почти 99, 5% изменения расходов на питание. Влияние отдельных факторов в многофакторных моделях может быть охарактеризовано с помощью частных коэффициентов эластичности, которые в случае линейной двухфакторной модели рассчитываются по формулам
Частные коэффициенты эластичности показывают, на сколько процентов изменится результативный признак, если изменить один из факторных признаков на один процент не меняя значения остальных. В рассматриваемом выше примере 3 Эŷ х1(х2)=0, 06815·6080, 5/1313, 9=0, 315; Эŷ х2(х1)=380.47·3, 1/1313, 9=0, 898. Это означает, что при увеличении душевого дохода на один процент и неизменном размере семьи расходы на питание увеличатся на 0, 315 процента, а увеличение на один процент (условно) размера семьи при неизменном душевом доходе приведет к росту расходов на питание на 0, 898 процента. Пример 4. Как размер платы за квартиру зависит от площади квартиры и от количества человек, прописанных в данной квартире. Данные приведены в табл. 4. Таблица 4
Построим линейную аддитивную модель в виде ŷ =а0+а1x1+а2x2. Необходимые данные для расчета модели сведем в табл. 5. Таблица 5
Для решения линейной двухфакторной модели строим следующую систему уравнений:
Нам нужно решить систему из трех линейных уравнений с тремя неизвестными и найти значения коэффициентов модели а0, а1 и а2.
а0+43, 04 a1+2, 5 a2 = 254, 86 43, 04 а0+2274, 58 a1+116, 46 a2 = 13031, 89 2, 5 а0+116, 46 a1+7, 1 a2 = 712. Для того чтобы решить данную систему уравнений методом Крамера, найдем сначала значение определителя основной матрицы. Этот определитель определяется равенством
× (5012, 44–5686, 45)=2586, 586 – 621, 07 – 1685, 025=280, 49. Получили, что ∆ =280, 49≠ 0, значит, система уравнений имеет единственное решение, которое находится по формулам Крамера
∆ а0 ∆ а1 ∆ а2
∆ ∆ ∆
- 43, 04× (92526, 42–82919, 52) + 2, 5× (1517693, 9–1619500, 96) = 659218, 33 – – 413480, 98–254515, 25= –8777, 9.
× (30644, 48–32579, 72)=9606, 9–3677, 63–4838, 1=1091, 2.
– 43, 04 × (30644, 48 – 32579, 73) + 254, 86 × (5012, 44 –5686, 45) = =101807, 05+83293, 16–171778, 19=13322, 02. Теперь мы можем найти значения коэффициентов модели а0, а1 и а2. а0 = –8777, 9/280, 49= –31, 3; а1 = 1091, 2/280, 49= 3, 89; а2 = 13322, 02/280, 49= 47, 5, следовательно, линейная аддитивная модель имеет следующий вид: ŷ = –31, 3+3, 89 x1+47, 5 x2. Коэффициент регрессии модели а1 =3, 89 показывает, что каждый метр площади квартиры повышает квартплату на 3, 89 руб., а коэффициент а2=47, 5 показывает, что каждый прописанный человек повышает квартплату на 47, 5 руб. Найдем теоретические значения ŷ и их отклонения от априорных (данные приведены в табл.6). Таблица 6.
Совокупный коэффициент детерминации R2 = 1 – 906, 4/12488, 18= 0, 927. Значение данного коэффициента близко к 1, что очень хорошо. 2.5. Формирование регрессионных моделей на компьютере с помощьюППП Excel Однофакторная регрессия. С татистическая функция ЛИНЕЙН определяет параметры линейной регрессии у=ах+b. Порядок вычисления следующий: 1) введите исходные данные или откройте существующий файл, содержащий анализируемые данные; 2) выделите область пустых ячеек 5´ 2 (5 строк, 2 столбца) длявывода результатов регрессионной статистики или область 1´ 2 – для получения только оценок коэффициентов регрессии; 3) активизируйте Мастер функций любым из способов: а) в главном меню выберите Вставка/Функция; б) на панели инструментов Стандартная щелкните по кнопке Вставка функции; 4) в окне Категория выберите Статистические, в окне Функция – ЛИНЕЙН. Щелкните по кнопке ОК; 5) заполните аргументы функции: Известные_значения_у – диапазон, содержащий данные результативного признака; Известные_значения_х – диапазон, содержащий данные факторов независимого признака; Константа - логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член равен 0; Статистика – логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводятся только оценки параметров уравнения. Щелкните по кнопке ОК; 6) в левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите клавишу < F2>, а затем – на комбинацию клавиш < CTRL> +< SHIFT> +< ENTER>. Регрессионная статистика представляется в выделенной области в следующем порядке:
Многофакторная регрессия. Построение линейной многофакторной модели производится с помощью инструментов пакета анализа данных Корреляция и Регрессия. Корреляция используется для расчета матрицы парных коэффициентов корреляции. С помощью Регрессии, помимо результатов регрессионной статистики, дисперсионного анализа и доверительных интервалов, можно получить остатки и графики подбора линии регрессии, остатков и нормальной вероятности. Порядок действий следующий: 1) проверьте доступ к пакету анализа. В главном меню последовательно выберите Сервис/Надстройки. Установите флажок Пакет анализа; 2) введите исходные данные или откройте существующий файл, содержащий анализируемые данные; 3) в главном меню выберите пункты Сервис/Анализ данных / Корреляция; 4) заполните диалоговое окно входных данных и параметров вывода: Входной интервал – диапазон, содержащий анализируемые данные (все столбцы или строки); Группирование – по столбцам или по строкам; Метки – флажок, который указывает, содержит ли первая строка названия столбцов или нет; Выходной интервал – достаточно указать левую верхнюю ячейку диапазона; 5) результаты вычислений – матрица парных коэффициентов корреляции, анализ которых позволяет выполнить первый этап процесса моделирования, описанный в 2.4; 6) в главном меню выберите пункты Сервис/Анализ данных / Регрессия; 7) заполните диалоговое окно входных данных и параметров вывода как в пункте 4, только интервал для результативного признака Y и для факторов Х надо задавать отдельно (причем входной интервал Х должен включать все столбцы, содержащие значения факторных признаков); 8) в результате получаем регрессионную статистику, таблицу дисперсионного анализа и таблицу коэффициентов модели, в которой первая строка (Y-пересечение) соответствует коэффициенту а0, а следующие строки описывают коэффициенты регрессии аi. Популярное:
|
Последнее изменение этой страницы: 2016-03-25; Просмотров: 705; Нарушение авторского права страницы
 Выборочный коэффициент корреляции можно определить, используя равенство (7).
Выборочный коэффициент корреляции можно определить, используя равенство (7). =0, 0479/6=0, 008.
=0, 0479/6=0, 008. )2, тогда дисперсия параметра a1 вычисляется по формуле D(a1)=σ 2/ Sx.
)2, тогда дисперсия параметра a1 вычисляется по формуле D(a1)=σ 2/ Sx. t=a1 /Ö D(a1). (10)
t=a1 /Ö D(a1). (10) При большом размере выборки повторяющиеся пары наблюдений группируются в виде корреляционной таблицы. Если nyx–количество наблюдений одинаковых пар (х, у), то для вычисления коэффициента корреляции в формуле (2) необходимо брать ху=å nyxxiyi/n.
При большом размере выборки повторяющиеся пары наблюдений группируются в виде корреляционной таблицы. Если nyx–количество наблюдений одинаковых пар (х, у), то для вычисления коэффициента корреляции в формуле (2) необходимо брать ху=å nyxxiyi/n. hyx=sYx/sy. (11)
hyx=sYx/sy. (11)



 где n – объем выборки (сумма всех частот); nx – частота значения х признака Х; ny – частота значения у признака Y; y – общая средняя признака Y; yx – условная средняя признака Y.
где n – объем выборки (сумма всех частот); nx – частота значения х признака Х; ny – частота значения у признака Y; y – общая средняя признака Y; yx – условная средняя признака Y. ух
ух
 у=(38× 15+12× 25)/50=17.4,
у=(38× 15+12× 25)/50=17.4,  х=(10× 10+28× 20+12× 30)/50=20.4,
х=(10× 10+28× 20+12× 30)/50=20.4, 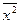 =(10× 100+28× 400+12× 900)/50=460,
=(10× 100+28× 400+12× 900)/50=460,  ху=(4× 10× 15+28× 20× 15+6× 30× 15+6× 10× 25+6× 30× 25)/50=354,
ху=(4× 10× 15+28× 20× 15+6× 30× 15+6× 10× 25+6× 30× 25)/50=354, 

 sх = Ö
sх = Ö  sy =Ö (38× (15 – 17.4)2 +12× (25 – 17.4)2)/50=4.27,
sy =Ö (38× (15 – 17.4)2 +12× (25 – 17.4)2)/50=4.27, 

 sYx =Ö (10× (21 – 17.4)2+28× (15 – 17.4)2+12× (20 – 17.4)2)/50=Ö 7.44=2.73.
sYx =Ö (10× (21 – 17.4)2+28× (15 – 17.4)2+12× (20 – 17.4)2)/50=Ö 7.44=2.73.
 ух – 17.4= –0.022(х – 20.4) или ух = –0.022х + 17.85
ух – 17.4= –0.022(х – 20.4) или ух = –0.022х + 17.85

 25
25
 ух = -0.022х+17.85
ух = -0.022х+17.85

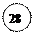

 15
15
 10 20 30
10 20 30 a0 + a1
a0 + a1  ,
,  + a2
+ a2  + … + am
+ … + am 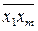 =
=  , (13)
, (13)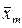 + a1
+ a1 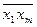 + a2
+ a2  + … + am
+ … + am  =
=  .
. Для анализа статистической значимости полученных коэффициентов множественной линейной регрессии оценивают дисперсию D(ai) и стандартные отклонения S(ai)=Ö D(ai) коэффициентов ai. Аналогично (10) величина t=ai/S(ai), называемая t–статистикой, имеет распределение Стьюдента с (n-m-1) степенями свободы. Если число степеней свободы достаточно велико (не менее 10), то при 5%-ном уровне значимости можно приближенно считать оценку незначимой, если t–статистика по модулю меньше 1, и весьма надежной, если модуль t–статистики больше 3.
Для анализа статистической значимости полученных коэффициентов множественной линейной регрессии оценивают дисперсию D(ai) и стандартные отклонения S(ai)=Ö D(ai) коэффициентов ai. Аналогично (10) величина t=ai/S(ai), называемая t–статистикой, имеет распределение Стьюдента с (n-m-1) степенями свободы. Если число степеней свободы достаточно велико (не менее 10), то при 5%-ном уровне значимости можно приближенно считать оценку незначимой, если t–статистика по модулю меньше 1, и весьма надежной, если модуль t–статистики больше 3. Затем вычисляются средняя квадратическая ошибка выборки (корень квадратный из дисперсии у)
Затем вычисляются средняя квадратическая ошибка выборки (корень квадратный из дисперсии у)
 Sу=√ (∑ (у – у)2)/n,
Sу=√ (∑ (у – у)2)/n,  В нашем примере Sу2=454070, Sŷ 2=63846, следовательно
В нашем примере Sу2=454070, Sŷ 2=63846, следовательно



 х1а0 +
х1а0 + 

 х2а0 + х1х2 а1 +
х2а0 + х1х2 а1 + 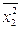 а2 = ух2,
а2 = ух2, 
 которая также формируется с применением метода наименьших квадратов (средние величины х1х2 ,
которая также формируется с применением метода наименьших квадратов (средние величины х1х2 ,  а0 + 6080, 5а1 + 3, 1а2 = 1313, 9
а0 + 6080, 5а1 + 3, 1а2 = 1313, 9 а0 + 6080, 5а1 + 3, 1а2 = 1313, 9
а0 + 6080, 5а1 + 3, 1а2 = 1313, 9 а0 + 6080, 5а1 + 3, 1а2 = 1313, 9
а0 + 6080, 5а1 + 3, 1а2 = 1313, 9

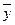 =254, 86
=254, 86
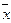 1=43, 04
1=43, 04

 1=13031, 9
1=13031, 9
 а0+
а0+  1a1+
1a1+ 

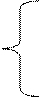 Подставляя в данную систему найденные числовые данные, получим систему
Подставляя в данную систему найденные числовые данные, получим систему