|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Восьмеричная система счисленияСтр 1 из 7Следующая ⇒
Двоичная система счисления В этой системе всего две цифры — 0 и 1. Особую роль здесь играет число 2 и его степени: 2, 4, 8 и т. д. Крайняя правая цифра числа показывает число единиц, следующая цифра — число двоек, следующая — число четверок и т. д. Двоичная система счисления позволяет закодировать любое натуральное число — представить его в виде последовательности нулей и единиц. Восьмеричная система счисления В этой системе счисления 8 цифр: 0, 1, 2, 3, 4, 5, 6, 7. Цифра 1, указанная в самом младшем разряде, означает — как и в десятичном числе — просто единицу. Та же цифра 1 в следующем разряде означает 8, в следующем 64 и т. д. Число 100 (восьмеричное) есть не что иное, как 64 (десятичное). Чтобы перевести в двоичную систему, например, число 611 (восьмеричное), надо заменить каждую цифру эквивалентной ей двоичной триадой (тройкой цифр). Шестнадцатеричная система счисления Запись числа в восьмеричной системе счисления достаточно компактна, но еще компактнее она получается в шестнадцатеричной системе. В качестве первых 10 из 16 шестнадцатеричных цифр взяты привычные цифры 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, а вот в качестве остальных 6 цифр используют первые буквы латинского алфавита: А, В, С, D, Е, F. Цифра 1, записанная в самом младшем разряде, означает просто единицу. Та же цифра 1 в следующем разряде — 16 (десятичное), в следующем — 256 (десятичное) и т. д. Цифра F, указанная в самом младшем разряде, означает 15 (десятичное). Перевод из шестнадцатеричной системы в двоичную и обратно производится аналогично тому, как это делается для восьмеричной системы 3) Способы хранения числовой информации в двоичной памяти ЭВМ. Для представления информации в памяти ЭВМ (как числовой, так и не числовой) используется двоичный способ кодирования. Для кодирования символов достаточно одного байта. - Двоично-десятичное кодирование В некоторых случаях при представлении чисел в памяти ЭВМ используется смешанная двоично-десятичная " система счисления" - Представление целых чисел в дополнительном коде Другой способ представления целых чисел — дополнительный код. Диапазон значений величин зависит от количества бит памяти, отведенных для их хранения. - Кодирование вещественных чисел Несколько иной способ применяется для представления в памяти персонального компьютера действительных чисел. 4) Способы хранения и представления графической информации в ЭВМ. - Побитовые изображения Обработка графической информации требует своего способа кодирования. Любое изображение представляется в виде огромного числа отдельных мельчайших точек. Обычная картинка на экране может содержать до миллиона таких точек. Простейшим изображением является черно-белое. В этом случае одна точка изображения может кодироваться одним битом, например 0 - черная точка, 1 - белая. Чтобы закодировать целый рисунок, его необходимо разбить на точки. Чем больше будет точек и чем меньше они будут, тем точнее будет передача рисунка. Когда рисунок разбит на точки, то начиная с левого верхнего угла и двигаясь по строкам слева направо, кодируется цвет каждой точки. Когда все точки рисунка закодированы, получается последовательность байтов. (например: 175, 176, 128, 65, 65, 80, 55, 80, 80, 214, 210, ...) 5) Способы хранения и вывода аудио информации в ЭВМ. 6) Способ хранения и представления текстовой информации с помощью ЭВМ. Текстовая информация состоит из символов: букв, цифр, знаков препинания, скобок и других. Мы уже говорили, что множество всех символов, с помощью которых записывается текст, называется алфавитом, а число символов в алфавите — его мощностью. Для представления текстовой информации в компьютере используется алфавит мощностью 256 символов. Мы знаем, что один символ такого алфавита несет 8 битов информации: 2 в 8 степени равно 256. 8 битов = 1 байт, следовательно: Один символ в компьютерном тексте занимает 1 байт памяти. Двоичный код каждого символа Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код — просто порядковый номер символа в двоичной системе счисления. Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки. Для разных типов ЭВМ используются различные таблицы кодировки, С распространением персональных компьютеров типа IBM PC международным стандартом стала таблица кодировки под названием ASCII (American Standart Code for Information Interchange — американский стандартный код для информационного обмена). Точнее говоря, стандартной в этой таблице является только первая половина, т. е. символы с номерами от нуля (двоичный код 00000000) до 127 (01111111). Сюда входят буквы латинского алфавита, цифры, знаки препинания, скобки и некоторые другие символы. Остальные 128 кодов, начиная с 10000000 и кончая 11111111, используются в разных вариантах. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита. Тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные нам буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в форме двоичного кода. Из памяти компьютера текст может быть выведен на экран или на печать в символьной форме. Но для долговременного хранения его следует записать на внешний носитель в виде файла 7) Области применения ЭВМ различных типов. Классификация типов ЭВМ по быстродействию и объему памяти. Первые компьютеры создавались исключительно для вычислений (что отражено в названиях «компьютер» и «ЭВМ»). Даже самые примитивные компьютеры в этой области во много раз превосходят людей (если не считать некоторых уникальных людей-счётчиков). Не случайно первым высокоуровневым языком программирования был Фортран, предназначенный исключительно для выполнения математических расчётов. Вторым крупным применением были базы данных. Прежде всего, они были нужны правительствам и банкам. Базы данных требуют уже более сложных компьютеров с развитыми системами ввода-вывода и хранения информации. Для этих целей был разработан язык Кобол. Позже появились СУБД со своими собственными языками программирования. Третьим применением было управление всевозможными устройствами. Здесь развитие шло от узкоспециализированных устройств (часто аналоговых) к постепенному внедрению стандартных компьютерных систем, на которых запускаются управляющие программы. Кроме того, всё бо́ льшая часть техники начинает включать в себя управляющий компьютер. Четвёртое. Компьютеры развились настолько, что стали главным информационным инструментом как в офисе, так и дома. Теперь почти любая работа с информацией зачастую осуществляется через компьютер — будь то набор текста или просмотр фильмов. Это относится и к хранению информации, и к её пересылке по каналам связи. Основное применение современных домашних компьютеров — навигация в Интернете и игры. Пятое. Современные суперкомпьютеры используются для компьютерного моделирования сложных физических, биологических, метеорологических и других процессов и решения прикладных задач. Например, для моделирования ядерных реакций или климатических изменений. Некоторые проекты проводятся при помощи распределённых вычислений, когда большое число относительно слабых компьютеров одновременно работает над небольшими частями общей задачи, формируя таким образом очень мощный компьютер. Наиболее сложным и слаборазвитым применением компьютеров является искусственный интеллект — применение компьютеров для решения таких задач, где нет чётко определённого более или менее простого алгоритма. Примеры таких задач — игры, машинный перевод текста, экспертные системы. 8) Организация вычислительного процесса на ЭВМ; Процесс обработки может быть разбит на ряд связанных между собой процедур (рис. 1) — организацию вычислительного процесса (ОВП), преобразование данных и отображение данных.
Содержание процедур процесса обработки данных представляет его концептуальный уровень; модели и методы, формализующие процедуры обработки данных в ЭВМ, логический уровень; средства аппаратной реализации процедур — физический уровень процесса. При пакетном режиме обработки задания (задачи), а точнее, программы с соответствующими исходными данными, накапливаются на дисковой памяти ЭВМ, образуя " 'пакет". Обработка заданий осуществляется в виде их непрерывного потока. Размещенные на диске задания образуют входную очередь, из которой они выбираются автоматически, последовательно или по установленным приоритетам. Входные очереди могут пополняться в произвольные моменты времени. Такой режим позволяет максимально загрузить ЭВМ, так как простои между заданиями отсутствуют, однако при получении решения возникают задержки из-за того, что задание некоторое время простаивает в очереди. Режим разделения времени реализуется путем выделения для выполнения заданий определенных интервалов времени, называемых квантами. Предназначенные для обработки в этом режиме задания находятся в оперативной памяти ЭВМ одновременно.. При большом числе одновременно поступающих на обработку заданий можно для более эффективного использования оперативной памяти временно перемещать во внешнюю память только что обрабатывавшееся задание до следующего его кванта. В режиме разделения времени возможна также реализация диалоговых операций, обеспечивающих непосредственный контакт человека с вычислительной системой. Режим реального времени используется при обработке данных в информационных технологиях, предназначенных для управления физическими процессами. В таких системах информационная технология должна обладать высокой скоростью реакции, чтобы успеть за короткий промежуток времени (лучше бы мгновенно! ) обработать поступившие данные и использовать полученные результаты для управления процессом. Поскольку в технологической системе управления потоки данных имеют случайный характер, вычислительная система всегда должна быть готова получать входные сигналы и обрабатывать их. Повторить поступившие данные невозможно, поэтому потеря их недопустима. В ЭВМ используют также режимы, называемые однопрограммными и мультипрограммными. В режиме разделения времени используется вариант мультипрограммного режима. Задания в виде программ и данных подвергаются процессу обработки, поступая из системы ввода, системы хранения, по каналам вычислительной сети. В этих условиях остро ставится вопрос планирования и выполнения заданий в вычислительной системе. Операционная система (ОС) - комплекс программ, которые обеспечивают управление аппаратурой ЭВМ, планирование эффективного использования её ресурсов и решение задач по заданиям пользователей. Назначение операционной системы. Основная цель ОС, обеспечивающей работу ЭВМ в любом из описанных режимов, - динамическое распределение ресурсов и управление ими в соответствии с требованиями вычислительных процессов (задач). Ресурсом является всякий объект, который может распределяться операционной системой между вычислительными процессами в ЭВМ. Различают аппаратные и программные ресурсы ЭВМ. К аппаратным ресурсам относятся микропроцессор (процессорное время), оперативная память и периферийные устройства; к программным ресурсам – доступные пользователю программные средства для управления вычислительными процессами и данными. Важнейшими программными ресурсами являются программы, входящие в систему программирования; средства программного управления периферийными устройствами и файлами; библиотеки системных и прикладных программ; средства, обеспечивающие контроль и взаимодействие вычислительных процессов (задач). Операционная система распределяет ресурсы в соответствии с запросами пользователей и возможностями ЭВМ и с учетом взаимодействия вычислительных процессов. Функции ОС также реализуются рядом вычислительных процессов, которые сами потребляют ресурсы (память, процессорное время и др.) Вычислительные процессы, относящиеся к ОС, управляют вычислительными процессами, созданными по запросу пользователей. Считается, что ресурс работает в режиме разделения, если каждый из вычислительных процессов занимает его в течение некоторого интервала времени. Например, два процесса могут разделять процессорное время поровну, если каждому процессу дается возможность использовать процессор в течение одной секунды из каждых двух секунд. Аналогично происходит разделение всех аппаратурных ресурсов, но интервалы использования ресурсов процессами могут быть неодинаковыми. Например, процесс может получить в своё распоряжение часть оперативной памяти на весь период своего существования, но микропроцессор может быть доступен процессу только в течение одной секунды из каждых четырёх. Операционная система является посредником между ЭВМ и её пользователем. Она делает работу с ЭВМ более простой, освобождая пользователя от обязанностей распределять ресурсы и управлять ими. Операционная система осуществляет анализ запросов пользователя и обеспечивает их выполнение. Запрос отражает необходимые ресурсы и требуемые действия ЭВМ и представляется последовательностью команд на особом языке директив операционной системы. Такая последовательность команд называется заданием. Функции Командный интерпретатор исполняет команды своего языка, заданные в командной строке или поступающие из стандартного ввода или указанного файла. В качестве команд интерпретируются вызовы системных или прикладных утилит, а также управляющие конструкции. Кроме того, оболочка отвечает за раскрытие шаблонов имен файлов и за перенаправление и связывание ввода-вывода утилит. В совокупности с набором утилит, оболочка представляет собой операционную среду, язык программирования и средство решения как системных, так и некоторых прикладных задач, в особенности, автоматизации часто выполняемых последовательностей команд. Драйвер ( driver ) представляет собой специализированныйпрограммный модуль, управляющий внешним устройством. Драйверы обеспечиваютединый интерфейс к различным устройствам, тем самым ``отвязывая''пользовательские программы и ядро ОС от особенностей аппаратуры. Слово driver происходит от глагола to drive ( вести )и переводится с английского языка как извозчик или шофер: тот, ктоведет транспортное средство. Нужно отметить, что большинство ``настоящих'' ОС запрещают пользовательскимпрограммам непосредственный доступ к аппаратуре. Это делается для повышениянадежности и обеспечения безопасности в многопользовательских системах.В таких системах драйверы являются для прикладных программ единственнымспособом доступа к внешнему миру. Еще одна важная функция драйвера - это разделение доступа к устройству в средах с вытесняющей многозадачностью. Допускать одновременный неконтролируемый доступ к устройству для нескольких параллельно исполняющихся процессов просто нельзя, потому что для большинствавнешних устройств даже простейшие операции ввода/вывода не являютсяатомарными. Фа́ йловая систе́ ма (англ. file system) — порядок, определяющий способ организации, хранения и именования данных на носителях информации в компьютерах, а также в другом электронном оборудовании: цифровых фотоаппаратах, мобильных телефонах и т. п. Файловая система определяет формат содержимого и способ физического хранения информации, которую принято группировать в виде файлов. Конкретная файловая система определяет размер имени файла (папки), максимальный возможный размер файла и раздела, набор атрибутов файла. Некоторые файловые системы предоставляют сервисные возможности, например, разграничение доступа или шифрование файлов. Файловая система связывает носитель информации с одной стороны и API для доступа к файлам — с другой. Когда прикладная программа обращается к файлу, она не имеет никакого представления о том, каким образом расположена информация в конкретном файле, так же, как и на каком физическом типе носителя (CD, жёстком диске, магнитной ленте, блоке флеш-памяти или другом) он записан. Всё, что знает программа — это имя файла, его размер и атрибуты. Эти данные она получает от драйвера файловой системы. Именно файловая система устанавливает, где и как будет записан файл на физическом носителе (например, жёстком диске). С точки зрения операционной системы (ОС), весь диск представляет собой набор кластеров (как правило, размером 512 байт и больше)[1]. Драйверы файловой системы организуют кластеры в файлы и каталоги (реально являющиеся файлами, содержащими список файлов в этом каталоге). Эти же драйверы отслеживают, какие из кластеров в настоящее время используются, какие свободны, какие помечены как неисправные. Однако файловая система не обязательно напрямую связана с физическим носителем информации. Существуют виртуальные файловые системы, а также сетевые файловые системы, которые являются лишь способом доступа к файлам, находящимся на удалённом компьютере. 16) - Файловая система хранения данных, каталоги и файлы, организация доступа к файлам. Практически всегда файлы на дисках объединяются в каталоги. В простейшем случае все файлы на данном диске хранятся в одном каталоге. Такая одноуровневая схема использовалась в CP/M и в первой версии MS-DOS 1.0. Иерархическая файловая система со вложенными друг в друга каталогами впервые появилась в Multics, затем в UNIX. Wiki.txtTornado.jpgNotepad.exe(Одноуровневая файловая система)Каталоги на разных дисках могут образовывать несколько отдельных деревьев, как в DOS/Windows, или же объединяться в одно дерево, общее для всех дисков, как в UNIX-подобных системах. В UNIX существует только один корневой каталог, а все остальные файлы и каталоги вложены в него. Чтобы получить доступ к файлам и каталогам на каком-нибудь диске, необходимо смонтировать этот диск командой mount. Например, чтобы открыть файлы на CD, нужно, говоря простым языком, сказать операционной системе: «возьми файловую систему на этом компакт-диске и покажи её в каталоге /mnt/cdrom». Все файлы и каталоги, находящиеся на CD, появятся в этом каталоге /mnt/cdrom, который называется точкой монтирования (англ. mount point).[2] В большинстве UNIX-подобных систем съёмные диски (дискеты и CD), флеш-накопители и другие внешние устройства хранения данных монтируют в каталог /mnt, /mount или /media. Unix и UNIX-подобные операционные системы также позволяет автоматически монтировать диски при загрузке операционной системы. Кроме того, следует отметить, что вышеописанная система позволяет монтировать не только файловые системы физических устройств, но и отдельные каталоги (параметр --bind) или, например, образ ISO (опция loop). Такие надстройки, как FUSE, позволяют также монтировать, например, целый каталог на FTP и ещё очень большое количество различных ресурсов. Ещё более сложная структура применяется в NTFS и HFS. В этих файловых системах каждый файл представляет собой набор атрибутов. Атрибутами считаются не только традиционные только для чтения, системный, но и имя файла, размер и даже содержимое. Таким образом, для NTFS и HFS то, что хранится в файле, — это всего лишь один из его атрибутов. Если следовать этой логике, один файл может содержать несколько вариантов содержимого. Таким образом, в одном файле можно хранить несколько версий одного документа, а также дополнительные данные (значок файла, связанная с файлом программа). Такая организация типична для HFS на Macintosh. Задачи файловой системы Основные функции любой файловой системы нацелены на решение следующих задач:
В многопользовательских системах появляется ещё одна задача: защита файлов одного пользователя от несанкционированного доступа другого пользователя, а также обеспечение совместной работы с файлами, к примеру, при открытии файла одним из пользователей, для других этот же файл временно будет доступен в режиме «только чтение». 17) - Этапы разработки программ для ЭВМ. Данные и алгоритмы, как модельное отражение реальных объектов. Языки программирования. В процессе создания любой программы можно выделить несколько этапов. 1. Постановка задачи — выполняется специалистом в предметной области на естественном языке (русском, английском и т. д.). Необходимо определить цель задачи, ее содержание и общий подход к решению. Возможно, что задача решается точно (аналитически), и без компьютера можно обойтись. Уже на этапе постановки надо учитывать эффективность алгоритма решения задачи на ЭВМ, ограничения, накладываемые аппаратным и программным обеспечением (АО и ПО). 2. Анализ задачи и моделирование — определяются исходные данные и результат, выявляются ограничения на их значения, выполняется формализованное описание задачи и построение (выбор) математической модели, пригодной для решения на компьютере. 3. Разработка или выбор алгоритма решения задачи — выполняется на основе ее математического описания. Многие задачи можно решить различными способами. Программист должен выбрать оптимальное решение. Неточности в постановке, анализе задачи или разработке алгоритма могут привести к скрытой ошибке — программист получит неверный результат, считая его правильным. 4. Проектирование общей структуры программы — формируется модель решения с последующей детализацией и разбивкой на подпрограммы, определяется " архитектура" программы, способ хранения информации (набор переменных, массивов и т. п.). 5. Кодирование — запись алгоритма на языке программирования. Современные системы программирования позволяют ускорить процесс разработки программы, автоматически создавая часть ее текста, однако творческая работа по-прежнему лежит на программисте. Для успешной реализации целей проекта программисту необходимо использовать методы структурного программирования. 6. Отладка и тестирование программы. Под отладкой понимается устранение ошибок в программе. Тестирование позволяет вести их поиск и, в конечном счете, убедиться в том, что полностью отлаженная программа дает правильный результат. Для этого разрабатывается система тестов — специально подобранных контрольных примеров с такими наборами параметров, для которых решение задачи известно. Тестирование должно охватывать все возможные ветвления в программе, т. е. проверять все ее инструкции, и включать такие исходные данные, для которых решение невозможно. Проверка особых, исключительных ситуаций, необходима для анализа корректности. Например, программа должна отказать клиенту банка в просьбе выдать сумму, отсутствующую на его счете. В ответственных проектах большое внимание уделяется так называемой " защите от дурака" подразумевающей устойчивость программы к неумелому обращению пользователя. Использование специальных программ — отладчиков, которые позволяют выполнять программу по отдельным шагам, просматривая при этом значения переменных, значительно упрощает этот этап. 7. Анализ результатов — если программа выполняет моделирование какого-либо известного процесса, следует сопоставить результаты вычислений с результатами наблюдений. В случае существенного расхождения необходимо изменить модель. 8. Публикация результатов работы, передача заказчику для эксплуатации. 9. Сопровождение программы — включает консультации представителей заказчика по работе с программой и обучение персонала. Недостатки и ошибки, замеченные в процессе эксплуатации, должны устраняться. Язык программирования - искусственный язык, являющийся промежуточным при переходе от естественного человеческого языка к машинным двоичным кодам. языки программирования бывают высокого и низкого уровней. языки программирования высокого уровня (как видно из схемы) являются более близкими к естественному человеческому языку по сравнению с языками программирования низкого уровня. создание текста программы на языке программирования выполняется человеком вручную, а перевод текста программы в машинные двоичные коды - трансляция (англ.translation - перевод) выполняется специальными программами- трансляторами. программирование на языках высокого уровня, очевидно, проще, чем на языках низкого уровня. оно не требует глубоких знаний устройства компьютера и поэтому вполне доступно людям, не являющимися специалистами в вычислительной технике. однако, программы, написанные на языках низкого уровня, как правило, отличаются более высокой скоростью работы, меньшим объемом и более полным использованием ресурсов вычислительной техники. к языкам высокого уровня относятся: фортран, бейсик, паскаль, си, алгол, алмир, ада, си++, delphi, java и сотни других. старейшим языком программирования высокого уровня является фортран (англ. formula translation, перевод формул). он был создан группой программистов американской фирмы ibm под руководством джона бекуса в 1957 году. несколько позже в европе был разработан язык алгол (англ.algorythmic language, алгоритмический язык). эти языки послужили основой для других новых языков программирования. так, язык бейсик (англ. basic, базовый, или beginner's all-purpose symbolic instruction code, многоцелевой язык символических команд для начинающих) был создан джоном кемени в сша в 1965 году. он представляет собой упрощенную версию фортрана, который оказался сложным для большинства пользователей из-за своей избыточности. Язык алгол послужил основой для не менее популярного языка паскаля, созданного в 1969 году швейцарским математиком никласом виртом. паскаль не сложнее бейсика, но в него изначально были заложены более широкие возможности. дальнейшее развитие язык паскаль получил в виде системы программирования delphi. на украине в 1965 году на базе алгола был создан язык алмир, отличавшийся использованием символики на основе русского, а не английского языка. этот язык считается первым в мире языком программирования на основе национального языка (native language). язык си, в котором использованы элементы паскаля, был создан в 1972 году в американской фирме bell laboratories под руководством дениса ритчи. название языка си связано с тем, что наиболее удачной оказалась его третья версия ( си- третья буква английского алфавита). си считается наиболее эффективным среди языков программирования высокого уровня. с одной стороны он не намного сложнее паскаляи или фортрана, но с другой обладает возможностями, присущими языкам программирования низкого уровня. поэтому си иногда называют языком программирования среднего уровня и используют как при написании прикладных программ, так и при разработке системных. дальнейшим развитием языка си стали языки си++ и java. к языкам низкого уровня отноятся ассемблер и автокод. ассемблер, как язык низкого уровня, фактически состоит из набора команд данной машины, записанных в виде сокращений на английском языке. автокод- вариант ассемблера на основе русского языка.
17) - Базовые и структурные типы данных, используемые для описания свойств объектов. Структура транслятора
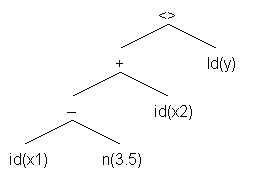
Транслятором называется программа, обрабатывающая текст на некотором входном языке. Наиболее распространёнными видами трансляторов для языков программирования являются компиляторы и интерпретаторы. Компиляторы переводят текст программы с языка высокого уровня на язык низкого уровня – машинный код. Интерпретаторы переводят текст программы с языка высокого уровня на язык команд некоторой абстрактной машины, программная реализация которой, как правило, входит в интерпретатор. Этот язык команд может быть довольно высокого уровня. На рис. 1 представлена общая схема компилятора. Он состоит из двух частей – анализирующей и генерирующей. Интерпретатор может содержать ещё интерпретирующую часть – абстрактную машину. Кроме того, если входом этой машины является непосредственно семантическая структура, построенная анализирующей частью, то он не нуждается в генераторе кода. Анализирующая часть синтаксически управляемого транслятора состоит из лексического, синтаксического и контекстного анализаторов. Лексический анализатор преобразует входной символьный поток в последовательность более крупных единиц – лексем. Например, текст из 14 символов (включая пробелы) " x1-3.5+x2 < > y" преобразуется в последовательность из 7 лексем [id(x1), `-, n(3.5), `+, id(x2), '< > ', id(y)]. Синтаксический анализатор входного языка проверяет синтаксическую правильность входной цепочки (уже разбитой на лексемы) и строит её семантическое дерево. Так, для предыдущей последовательности лексем может быть построено семантическое дерево
Семантическая структура программы является наиболее важной компонентой процесса трансляции. Одна и та же семантическая структура может использоваться для генерации объектного машинного кода, а так же интерпретации программы на разных программно-аппаратных платформах. Семантическая структура содержит все объекты программы, их свойства и отношения, существенные с точки зрения компиляции и/или интерпретации. Семантическое дерево программы представляет лишь часть этой структуры. И компиляция, и интерпретация языка основаны на некотором определении его семантики - определении того, как каждая программа языка преобразует свои входные данные в выходные. Часто за определение семантики берут определение абстрактной машины, используемой в интерпретаторе. Однако, желательно иметь более общее (более абстрактное) определение семантики - тогда оно сможет быть основой для создания самых разных трансляторов, работающих в различных программно-аппаратных системах. Семантика обычно определяется на семантической структуре программ, от которой также требуется достаточная абстрактность. Современные методы построения трансляторов требуют применения изощрённых и эффективных методов, основанных на теории языков, грамматик и автоматов, в свою очередь базирующихся на более общих математических теориях - теории множеств, алгебре, математической логике и других. Очень большую роль играет здесь выбор формальных средств определения тех или иных аспектов языка. Если для лексики и синтаксиса общепринято использовать автоматные и контекстно-свободные грамматики, соответственно, то для остальных свойств этих грамматик недостаточно и предлагаются самые разнообразные и очень сложные формализмы. На практике же чаще обходятся неформальными описаниями, что низводит создание трансляторов с уровня науки и индустрии к уровню ремесла, причём весьма трудоемкого и плохо контролируемого. В данной книге для определения всех " постсинтаксических" аспектов языка используются предикативные грамматики. Благодаря своей твёрдой математической основе (математическая логика) и универсальности, эти грамматики позволяют дать достаточно абстрактные определения и строго обосновывать многие проектные решения, например, семантическую правильность трансляции. С другой стороны, благодаря реализации предикативных грамматик в системах логического программирования на базе языка Пролог, эти определения могут быть отлажены ещё на этапе проектирования транслятора или даже языка. Основное отличие данной книги от многих других, посвящённых этой теме, состоит в том, что в ней излагается не только теория формализмов, используемых для определения языков и трансляторов (грамматик, автоматов и т.п.), но и теория самих языков программирования, их семантики и трансляции. Несмотря на огромное разнообразие языковых конструкций и методов их реализации, есть некоторые общепризнанные концепции построения языков программирования и трансляторов, которые мы здесь попытались осветить. К таким концепциям относятся, например, концепции типа, блочной видимости, принципы адресации, реализации рекурсивных процедур и т.д. К счастью, есть довольно простой язык программирования - Паскаль, из которого нетрудно выделить небольшое подмножество, содержащее все затронутые понятия. Это позволило проиллюстрировать все рассмотренные методы трансляции в виде полной реализации этого языка и тем самым рассмотреть их не изолированно, а во взаимосвязи. Благодаря встроенности предикативных грамматик в Пролог-системы, студенты получают не только теоретические знания, но и могут проверить их на практике. Искусственные среды По большей части искусственные среды для передачи сигналов представлены проводами и кабелями:
Кабель USB Порты USB позволяют подавать питание на определенные устройства и одновременно осуществлять передачу данных. Внутри кабеля USB имеется четыре провода, два из которых предназначены для подачи питания, а другие два - для передачи данных. Во избежание путаницы стандарты USB предусматривают использование разъемов типа A и B и связь компьютеров с помощью кабелей USB обеспечивает сравнительно невысокую скорость передачи данных. Скорость передачи зависит также от качества кабеля, операционной системы, протоколов, сетевых устройств, центрального процессора и других электронных узлов. Волоконно-оптический кабель Популярное:
|
Последнее изменение этой страницы: 2016-05-30; Просмотров: 1430; Нарушение авторского права страницы