
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Доверительные интервалы для коэффициентов: реальные статистические данные
Практическому построению доверительных интервалов для коэффициентов aj нормальной модели линейной множественной регрессии у=a0+a1х1 +a2х2 +…+amхm+e. где e нормально распределенная случайная величина с параметрами
неизвестного значения s 2. Единственный выход из этого положения – заменить неизвестное значение s2 какой-нибудь подходящей его оценкой (estimate), которую можно было бы вычислить на основании имеющихся статистических данных. Такого рода оценки принято называть статистиками (statistics). В данной ситуации такой подходящей оценкой для неизвестного значения
Поскольку сумма Математическое ожидание этой случайной величины равно
т. е. Замечание. В частном случае (при отсутствии факторов) модель наблюдений принимает вид
(случайная выборка из распределения N (a0, s2)). Несмещенной оценкой для
Оценкой наименьших квадратов для параметра a0
Таким образом, выборочная дисперсия При выполнении стандартных предположений отношение
имеет стандартное распределение, называемое распределением хи-квадрат с (n-m-1) степенями свободы. Такое же распределение имеет сумма квадратов Для обозначения распределения хи-квадрат с K степенями свободы используют символ c2(K). Итак, мы не знаем истинного значения
Соответственно, вместо отношения
приходится использовать отношение
Однако последнее отношение как случайная величина уже не имеет стандартного нормального распределения, поскольку в знаменателе теперь стоит не постоянная, а случайная величина. Тем не менее, распределение последнего отношения также относят к стандартным, и оно известно под названием t-распределения Стьюдента с (n-m-1) степенями свободы. Для распределения Стьюдента с K степенями свободы принято обозначение t (K). Квантиль уровня р такого распределения будем обозначать символом tp (K). График функции плотности распределения Стьюдента симметричен относительно нуля и похож на график функции плотности нормального распределения. Например, при K=10 он имеет следующий вид (левый график).
Для сравнения, справа приведен график функции стандартного нормального распределения. Отличие графиков столь невелико, что визуально они почти неразличимы. Квантили этих двух распределений различаются более ощутимо:
Распределение Стьюдента имеет более тяжелые хвосты. Из приведенных значений квантилей следует, например, что случайная величина, имеющая стандартное нормальное распределение, может превысить значение 1.645 лишь с вероятностью 0.05. В то же самое время, с такой же вероятностью 0.05 случайная величина, имеющая распределение Стьюдента с 10 степенями свободы, принимает значения, большие, чем 1.812. Впрочем, для значений Итак,
Поэтому для этой случайной величины выполняется соотношение
так что с вероятностью, равной
т. е.
Иными словами, с вероятностью, равной 1-g, случайный интервал
накрывает истинное значение коэффициента α j, т. е. является 95%- доверительным интервалом для α j в случае, когда не известно истинное значение s2дисперсии случайных ошибок Замечание. Выбор конкретного значения Попытка повысить уровень доверия Так, для
где Соответственно, выбирая уровень доверия Теперь мы в состоянии перейти к построению интервальных оценок параметров моделей линейной регрессии для различного рода социально-экономических факторов на основании соответствующих статистических данных. Пример. Пусть при построении модели зависимости уровня безработицы среди белого населения США от уровня безработицы среди цветного населения в виде
получены следующие значения: Š =0.161231; Получаем:
т. е.
Для
т. е.
В связи с этим примером, отметим два обстоятельства. (а) Доверительный интервал для коэффициента (б) Каждый из двух построенных интервалов имеет уровень доверия Справиться с первым затруднением в данном примере можно, понизив уровень доверия до Что касается второго затруднения, то наиболее простой путь взятия под контроль вероятности одновременного накрытия доверительными интервалами для
Следовательно, если построить доверительный интервал для Это означает, что в нашем примере мы можем гарантировать, что вероятность одновременного накрытия истинных значений
значение
так что каждый из исходных интервалов увеличится в
Популярное:
|
Последнее изменение этой страницы: 2016-05-30; Просмотров: 1045; Нарушение авторского права страницы
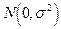 , препятствует вхождение в выражения для дисперсий
, препятствует вхождение в выражения для дисперсий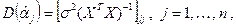
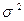 является статистика
является статистика (см. (9)).
(см. (9)).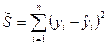 является квадратичной функцией от случайных величин e=(
является квадратичной функцией от случайных величин e=( 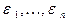 ), то она является случайной величиной, а следовательно, случайной величиной является и статистика `S2.
), то она является случайной величиной, а следовательно, случайной величиной является и статистика `S2.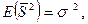
 – несмещенная оценка для
– несмещенная оценка для 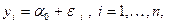

 является
является  , так что
, так что
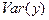 переменной
переменной  , получаемая делением
, получаемая делением 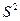 именно на
именно на  (а не на
(а не на  ), является несмещенной оценкой для
), является несмещенной оценкой для 
 случайных величин, независимых в совокупности и имеющих одинаковое стандартное нормальное распределение. При
случайных величин, независимых в совокупности и имеющих одинаковое стандартное нормальное распределение. При  график функции плотности этого распределения имеет вид
график функции плотности этого распределения имеет вид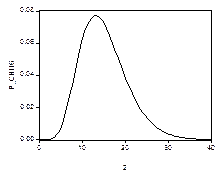
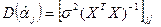 на его несмещенную оценку
на его несмещенную оценку


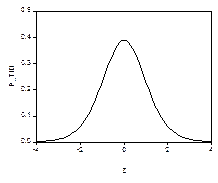


 квантили распределения Стьюдента
квантили распределения Стьюдента 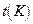 практически совпадают с соответствующими квантилями cтандартного нормального распределения
практически совпадают с соответствующими квантилями cтандартного нормального распределения 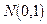 .
. ~
~  .
.
 , выполняется двойное неравенство
, выполняется двойное неравенство
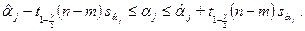
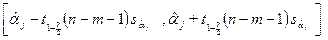
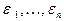 . В среднем, длина такого интервала больше, чем длина доверительного интервала с тем же уровнем доверия, построенного при известном значении
. В среднем, длина такого интервала больше, чем длина доверительного интервала с тем же уровнем доверия, построенного при известном значении 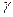 определяет компромисс между желанием получить более короткий доверительный интервал и желанием обеспечить более высокий уровень доверия.
определяет компромисс между желанием получить более короткий доверительный интервал и желанием обеспечить более высокий уровень доверия. с более высоким значением
с более высоким значением 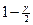 , т. е. к большему значению
, т. е. к большему значению  можно приближенно считать, что
можно приближенно считать, что ,
,  – квантиль уровня
– квантиль уровня  стандартного нормального распределения.
стандартного нормального распределения.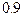 ,
, 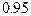 или
или 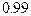 , мы получаем для
, мы получаем для  . Это означает, что переход от уровня доверия
. Это означает, что переход от уровня доверия 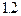 раза, а дополнительное повышение уровня доверия до
раза, а дополнительное повышение уровня доверия до  раза.
раза.

 .
. =
= 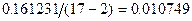 . Для построения
. Для построения  — доверительного интервала для
— доверительного интервала для 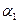 остается найти квантиль уровня
остается найти квантиль уровня  распределения Стьюдента с
распределения Стьюдента с 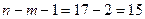 степенями свободы. Используя, например, приложение 1, находим:
степенями свободы. Используя, например, приложение 1, находим: 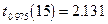 . Соответственно, получаем
. Соответственно, получаем 

 имеем
имеем  ,
,  ;
; 
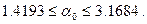
 . В этом случае в выражении для доверительного интервала квантиль
. В этом случае в выражении для доверительного интервала квантиль  , так что левая граница доверительного интервала для
, так что левая граница доверительного интервала для  . Однако это достигается ценой того, что новый доверительный интервал будет накрывать истинное значение параметра
. Однако это достигается ценой того, что новый доверительный интервал будет накрывать истинное значение параметра  оба интервала накрывают
оба интервала накрывают 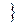 =
=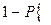 хотя бы один из них не накрывает соответствующее
хотя бы один из них не накрывает соответствующее 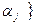 =
= доверительный интервал для
доверительный интервал для  =
=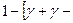
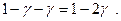
 , то тогда правая часть полученной цепочки соотношений будет равна
, то тогда правая часть полученной цепочки соотношений будет равна 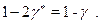
 . Но тогда при построении этих интервалов придется использовать вместо значения
. Но тогда при построении этих интервалов придется использовать вместо значения
 ,
,  раза. Это, конечно, приводит к еще более неопределенным выводам относительно истинных значений параметров
раза. Это, конечно, приводит к еще более неопределенным выводам относительно истинных значений параметров