|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Раздел 4. ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ В РАЗЛИЧНЫХ ОБЛАСТЯХ ДЕЯТЕЛЬНОСТИСтр 1 из 8Следующая ⇒
Раздел 4. ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ В РАЗЛИЧНЫХ ОБЛАСТЯХ ДЕЯТЕЛЬНОСТИ
Информационные технологии в системах организационного управления
4.1.1 ЭВМ при выборе решений в области технологии, организации, планирования и управления производством
Применение компьютерных информационных технологий позволяет в ряде случаев при сравнительно небольших затратах получать ценные управленческие решения. Составление экономико-математических моделей и проведение расчетов с помощью компьютера позволяют быстро и относительно недорого проводить разработку и сравнение многочисленных вариантов планов и управленческих решений. Многовариантность выбора - одно из ценнейших качеств рассматриваемых методов. Однако в настоящее время практическоеприменение экономико-математических методов в управление и планировании производственной деятельностью, несмотря на оснащение управленческих служб средствами вычислительной техники, далеко не соответствует имеющемуся в этой области научному запасу. Трудности практического внедрения экономико-математических методов связаны со многими объективными и субъективными причинами, но прежде всего обусловлены сложностью экономических процессов и явлений, невозможностью расчленения больших систем на обозримые части с целью их автономного рассмотрения, а также необходимостью учитывать наряду с технологическими аспектами и поведение людей. Поэтому практически приемлемым путем является включение компьютерных решений конкретных типовых задач в процесс принятия управленческих решений руководителем. При этом необходимо сочетать опыт и трудноформализуемые знания руководителя, хорошо знающего производственную и хозяйственную стороны управленческой деятельности, с производительностью и многовариантностью компьютерно-математических методов. В настоящее время имеются отработанные методы решения ряда типовых задач по организации и планированию производства, для которых могут быть применены компьютерные технологии. Все эти задачи могут быть классифицированы следующим образом. 1) Задачи в области организации производства. К ним относятся, например, задачи организации проектирования, ремонта машин, транспорта и складского хозяйства, задачи управления качеством, расчета потребности в ресурсах (трудовых, материальных, технических) с распределением во времени на основе календарного плана производства и т.п. 2) Задачи планирования производства. К ним относятся, например, задачи планирования производства товарной продукции, технического развития и повышения эффективности производства, труда и заработной платы, механизации и материально-технического обеспечения производства, задачи анализа производственно-хозяйственной деятельности и т. п. Такие отработанные решения определенных типовых задач базируются на методах имитационного моделирования, линейного программирования, вероятностного моделирования и других методах. Возможность практического решения указанных задач в настоящее.время расширяется в связи с компьютеризацией всех звеньев управленческого аппарата, созданием локальных и объединенных вычислительных сетей, организацией локальных и централизованных информационных баз данных и обеспечением к ним оперативного доступа. Автоматизированные системы научных исследований Автоматизированные системы научных исследований (АСНИ) представляют собой программно-аппаратные комплексы, обрабатывающие данные, поступающие от различного рода экспериментальных установок и измерительных приборов, и на основе их анализа облегчающие обнаружение новых эффектов и закономерностей (рис. 1). Блок связи с измерительной аппаратурой преобразует к нужному виду информацию, поступающую от измерительной аппаратуры. В базе данных хранится информация, поступившая из блока связи с измерительной аппаратурой, а также заранее введенная с целью обеспечения работоспособности системы. Расчетный блок, выполняя программы из пакета прикладных программ, производит все математические расчеты, в которых может возникнуть потребность в ходе научных исследований. Расчеты могут выполняться как по требованию исследователя, так и блока имитационного моделирования. При этом на основе математических моделей воспроизводится процесс, происходящий во внешней среде. Экспертная система моделирует рассуждения специалистов данной предметной области. С ее помощью исследователь может классифицировать наблюдаемые явления, диагностировать течение следуемых процессов.
Рис. 4.1 - Типовая структура АСНИ
АСНИ получили широкое распространение в молекулярной химии, минералогии, биохимии, физике элементарных частиц и многих других науках.
Раздел 5 ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ В РАСПРЕДЕЛЕННЫХ СИСТЕМАХ
Технологии распределенных вычислений (РВ)
Современное производство требует высоких скоростей обработки информации, удобных форм ее хранения и передачи. Необходимо также иметь динамичные способы обращения к информации, способы поиска данных в заданные временные интервалы, чтобы реализовывать сложную математическую и логическую обработку данных. Управление крупными предприятиями, управление экономикой на уровне страны требуют участия в этом процессе достаточно крупных коллективов. Такие коллективы могут располагаться в различных районах города, в различных регионах страны и даже в различных странах. Для решения задач управления, обеспечивающих реализацию экономической стратегии, становятся важными и актуальными скорость и удобство обмена информацией, а также возможность тесного взаимодействия всех участвующих в процессе выработки управленческих решений. В эпоху централизованного использования ЭВМ с пакетной обработкой информации пользователи вычислительной техники предпочитали приобретать компьютеры, на которых можно было бы решать почти все классы их задач. Однако сложность решаемых задач обратно пропорциональна их количеству, и это приводило к неэффективному использованию вычислительной мощности ЭВМ при значительных материальных затратах. Нельзя не учитывать и тот факт, что доступ к ресурсам компьютеров был затруднен из-за существующей политики централизации вычислительных средств в одном месте. Принцип централизованной обработки данных (рис. 5.1) не отвечал высоким требованиям к надежности процесса обработки, затруднял развитие систем и не мог обеспечить необходимые временные параметры при диалоговой обработке данных в многопользовательском режиме. Кратковременный выход из строя центральной ЭВМ приводил к роковым последствиям для системы в целом.
Рис. 5.1 - Система централизованной обработки данных
Появление персональных компьютеров потребовало нового подхода к организации систем обработки данных, к созданию новых информационных технологий. Возникло логически обоснованное требование перехода от использования отдельных ЭВМ в системах централизованной обработки данных к распределенной обработке данных (рис. 5.2).
Рис. 5.2 - Система распределенной обработки данных
Распределенная обработка данных - обработка данных, выполняемая на независимых, но связанных между собой компьютерах, представляющих распределенную систему. В основе распределенных вычислений лежат две основные идеи: § много организационно и физически распределенных пользователей, одновременно работающих с общими данными - общей базой данных (пользователи с разными именами, которые могут располагаться на различных вычислительных установках, с различными полномочиями и задачами); § логически и физически распределенные данные, составляющие и образующие тем не менее, общую базу данных (отдельные таблицы, записи и даже поля могут располагаться на различных вычислительных установках или входить в различные локальные базы данных). Дня реализации распределенной обработки данных были созданы многомашинные ассоциации, структура которых разрабатывается по одному из следующих направлений: § многомашинные вычислительные комплексы (МВК); § компьютерные (вычислительные) сети. Многомашинный вычислительный комплекс - группа установленных рядом вычислительных машин, объединенных с помощью специальных средств сопряжения и выполняющих совместно единый информационно-вычислительный процесс. Под процессом понимается некоторая последовательность действий для решения задачи, определяемая программой. Многомашинные вычислительные комплексы могут быть: § локальными, при условии установки компьютеров в одном помещении, не требующих для взаимосвязи специального оборудования и каналов связи; § дистанционными, если некоторые компьютеры комплекса установлены на значительном расстоянии от центральной ЭВМ и для передачи данных используются телефонные каналы связи. Пример 1. Три ЭВМ объединены в комплекс для распределения заданий, поступающих на обработку. Одна из них выполняет диспетчерскую функцию и распределяет задания в зависимости от занятости одной из двух других обрабатывающих ЭВМ. Это локальный многомашинный комплекс. Пример 2. ЭВМ, осуществляющая сбор данных по некоторому региону, выполняет их предварительную обработку и передает для дальнейшего использования на центральную ЭВМ по телефонному каналу связи. Это дистанционный многомашинный комплекс. Компьютерная (вычислительная) сеть - вычислительная система, включающая в себя несколько компьютеров, терминалов и других аппаратных средств, соединенных между собой линиями связи, обеспечивающими передачу данных Терминал - устройство, предназначенное для взаимодействия пользователя с вычислительной системой или сетью ЭВМ. Состоит из устройства ввода (чаще всего это клавиатура) и одного или нескольких устройств вывода (дисплей, принтер и т.д.).
Распределенные базы данных
Системы распределенных вычислений появляются, прежде всего, по той причине, что в крупных автоматизированных информационных системах, построенных на основе корпоративных сетей, не всегда удается организовать централизованное размещение всех баз данных и СУБД на одном узле сети. Поэтому системы распределенных вычислений тесно связаны с системами управления распределенными базами данных. Распределенная база данных - это совокупность логически взаимосвязанных баз данных, распределенных в компьютерной сети. Система управления распределенной базой данных - это программная система, которая обеспечивает управление распределенной базой данных и прозрачность ее распределенности для пользователей. Распределенная база данных может объединять базы данных, поддерживающие любые модели (иерархические, сетевые, реляционные и объектно-ориентированные базы данных) в рамках единой глобальной схемы. Подобная конфигурация должна обеспечивать для всех приложений прозрачный доступ к любым данным независимо от их местоположения и формата. Основные принципы создания и функционирования распределенных баз данных: § прозрачность расположения данных для пользователя (иначе говоря, для пользователя распределенная база данных должна представляться и выглядеть точно так же, как и нераспределенная); § изолированность пользователей друг от друга (пользователь должен " не чувствовать", " не видеть" работу других пользователей в тот момент, когда он изменяет, обновляет, удаляет данные); § синхронизация и согласованность (непротиворечивость) состояния данных в любой момент времени. Из основных вытекает ряд дополнительных принципов: § локальная автономия (ни одна вычислительная установка для своего успешного функционирования не должна зависеть от любой другой установки); § отсутствие центральной установки (следствие предыдущею пункта); § независимость от местоположения (пользователю все равно, где физически находятся данные, он работает так, как будто они находятся на его локальной установке); § непрерывность функционирования (отсутствие плановых отключений системы в целом, например для подключения новой установки или обновления версии СУБД); § независимость от фрагментации данных (как от горизонтальной фрагментации, когда различные группы записей одной таблицы размещены на различных установках или в различных локальных базах, так и от вертикальной фрагментации, когда различные поля-столбцы одной таблицы размещены на разных установках); § независимость от реплицирования (дублирования) данных (когда какая-либо таблица базы данных (или ее часть) физически может быть представлена несколькими копиями, расположенными на различных установках); § распределенная обработка запросов (оптимизация запросов должна носить распределенный характер - сначала глобальная оптимизация, а далее локальная оптимизация на каждой из задействованных установок); § распределенное управление транзакциями (в распределенной системе отдельная транзакция может требовать выполнения действий на разных установках, транзакция считается завершенной, если она успешно завершена на всех вовлеченных установках); § независимость от аппаратуры (желательно, чтобы система могла функционировать на установках, включающих компьютеры разных типов); § независимость от типа операционной системы (система должна функционировать вне зависимости от возможного различия ОС на различных вычислительных установках); § независимость от коммуникационной сети (возможность функционирования в разных коммуникационных средах); § независимость от СУБД (на разных установках могут функционировать СУБД различного типа, на практике ограничиваемые кругом СУБД, поддерживающих SQL). В обиходе СУБД, на основе которых создаются распределенные информационные системы, также характеризуют термином " распределенные СУБД", и, соответственно, используют термин " распределенные базы данных". Практическая реализация распределенных вычислений осуществляется через отступление от некоторых рассмотренных выше принципов создания и функционирования распределенных систем. В зависимости от того, какой принцип приносится в " жертву" (отсутствие центральной установки, непрерывность функционирования, согласованного состояния данных и др.) выделились несколько самостоятельных направлений в технологиях распределенных систем - технологии " Клиент-сервер", технологии реплицирования, технологии объектного связывания. Реальные распределенные информационные системы, как правило, построены на основе сочетания всех трех технологий, но в методическом плане их целесообразно рассмотреть отдельно.
5.3 Технологии и модели " Клиент-сервер"
Системы на основе технологий " Клиент-сервер" исторически выросли из первых централизованных многопользовательских автоматизированных информационных систем, интенсивно развивавшихся в 70-х годах (системы mainframe), и получили, вероятно, наиболее широкое распространение в сфере информационного обеспечения крупных предприятий и корпораций. В технологиях " Клиент-сервер" отступают от одного из главных принципов создания и функционирования распределенных систем - отсутствия центральной установки. Поэтому можно выделить две основные идеи, лежащие в основе клиент-серверных технологий: § общие для всех пользователей данные на одном или нескольких серверах; § много пользователей (клиентов), на различных вычислительных установках, совместно (параллельно и одновременно) обрабатывающих общие данные. Иначе говоря, системы, основанные на технологиях " Клиент-сервер", распределены только в отношении пользователей, поэтому часто их не относят к " настоящим" распределенным системам, а считают отдельным классом многопользовательских систем. Важное значение в технологиях " Клиент-сервер" имеют понятия сервера и клиента. Под сервером в широком смысле понимается любая система, процесс, компьютер, владеющие каким-либо вычислительным ресурсом (памятью, временем, производительностью процессора и т. д.). Клиентом называется также любая система, процесс, компьютер, пользователь, запрашивающие у сервера какой-либо ресурс, пользующиеся каким-либо ресурсом или обслуживаемые сервером иным способом. В своем развитии системы " Клиент-сервер" прошли несколько этапов, в ходе которых сформировались различные модели систем " Клиент-сервер". Их реализация и, следовательно, правильное понимание основаны на разделении структуры СУБД на три компонента: § компонент представления, реализующий функции ввода и отображения данных, называемый иногда еще просто как интерфейс пользователя; § прикладной компонент, включающий набор запросов, событий, правил, процедур и других вычислительных функций, реализующий предназначение автоматизированной информационной системы в конкретной предметной области; § компонент доступа к данным, реализующий функции хранения-извлечения, физического обновления и изменения данных. Исходя из особенностей реализации и распределения в системе этих трех компонентов различают четыре модели технологий " Клиент-сервер": § модель файлового сервера (File Server - FS); § модель удаленного доступа к данным (Remote Data Access - RDA); § модель сервера базы данных (DataBase Server - DBS); § модель сервера приложений (Application Server - AS).
Модель файлового сервера
Модель файлового сервера является наиболее простой и характеризует не столько способ образования информационной системы, сколько общий способ взаимодействия компьютеров в локальной сети. Один из компьютеров сети выделяется и определяется файловым сервером, т. е. общим хранилищем любых данных. Суть FS- модели иллюстрируется схемой, приведенной на рис. 5.3.
Рис 5.3 - Модель файлового сервера
В FS-модели все основные компоненты размещаются на клиентской установке. При обращении к данным ядро СУБД, в свою очередь, обращается с запросами на ввод-вывод данных за сервисом к файловой системе. С помощью функций операционной системы в оперативную память клиентской установки полностью или частично на время сеанса работы копируется файл базы данных. Таким образом, сервер в данном случае выполняет чисто пассивную функцию. Достоинством данной модели являются ее простота, отсутствие высоких требований к производительности сервера (главное, требуемый объем дискового пространства). Следует также отметить, что программные компоненты СУБД в данном случае не распределены, т.е. никакая часть СУБД на сервере не инсталлируется и не размещается. Недостатки данной модели - высокий сетевой трафик, достигающий пиковых значений особенно в момент массового вхождения в систему пользователей, например в начале рабочего дня. Однако более существенным недостатком, с точки зрения работы с общей базой данных, является отсутствие специальных механизмов безопасности файла (файлов) базы данных со стороны СУБД. Иначе говоря, разделение данных между пользователями (параллельная работа с одним файлом данных) осуществляется только средствами файловой системы ОС для одновременной работы нескольких прикладных программ с одним файлом. Несмотря на очевидные недостатки, модель файлового сервера является естественным средством расширения возможностей персональных (настольных) СУБД в направлении поддержки многопользовательского режима и, очевидно, в этом плане еще будет сохранять свое значение.
Модель сервера базы данных
Развитием PDA-модели стала модель сервера базы данных. Ее сердцевиной является механизм хранимых процедур. В отличие от PDA-модели, определенные для конкретной предметной области информационной системы события, правила и процедуры, описанные средствами языка SQL, хранятся вместе с данными на сервере системы и на нем же выполняются. Иначе говоря, прикладной компонент полностью размещается и выполняется на сервере системы. Схематично DBS-модель приведена на рис. 2.5.
Рис. 5.5 Модель сервера базы данных (DBS-модель)
На клиентских установках в DBS-модели размещается только интерфейсный компонент (компонент представления), что существенно снижает требования к вычислительной установке клиента. Пользователь через интерфейс системы на клиентской установке направляет на сервер базы данных только лишь вызовы необходимых процедур, запросов и других функций по обработке данных. Все затратные операции по доступу и обработке данных выполняются на сервере и клиенту направляются лишь результаты обработки, а не наборы данных, как в RDA-модели. Этим обеспечивается существенное снижение трафика сети в DBS-модели по сравнению с RDA -моделью. Следует заметить, что на сервере системы выполняются процедуры прикладных задач одновременно всех пользователей системы. В результате резко возрастают требования к вычислительной установке сервера, причем как к объему дискового пространства и оперативной памяти, так и к быстродействию. Это основной недостаток DBS-модели. К достоинствам же DBS-модели, помимо разгрузки сети, относится и более активная роль сервера сети, размещение, хранение и выполнение на нем механизма событий, правил и процедур, возможность более адекватно и эффективно " настраивать" распределенную информационную систему на все нюансы предметной области. Также более надежно обеспечивается согласованность состояния и изменения данных и, вследствие этого, повышается надежность хранения и обработки данных, эффективно координируется коллективная работа пользователей с общими данными.
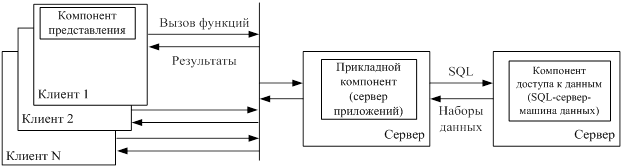
Модель сервера приложений
Чтобы разнести требования к вычислительным ресурсам сервера в отношении быстродействия и памяти по разным вычислительным установкам, используется модель сервера приложений. Суть AS-модели заключается в переносе прикладного компонента информационной системы на специализированный в отношении повышенных ресурсов по быстродействию дополнительный сервер системы. Схема AS-модели приведена на рис. 5.6
Рис. 5.6. Модель сервера приложений (AS-модель)
Как и в DBS-модели, на клиентских установках располагается только интерфейсная часть системы, т. е. компонент представления. Однако вызовы функций обработки данных направляются на сервер приложений, где эти функции совместно выполняются для всех пользователей системы. За выполнением низкоуровневых операций по доступу и изменению данных сервер приложений, как в RDA-модели, обращается к SQL-серверу, направляя ему вызовы SQL-процедур, и получая, соответственно, от него наборы данных. Как известно, последовательная совокупность операций над данными (SQL-инструкций), имеющая отдельное смысловое значение, называется транзакцией. В этом отношении сервер приложений управляет формированием транзакций, которые выполняет SQL-сервер. Поэтому программный компонент СУБД, инсталлируемый на сервере приложений, еще называют монитором обработки транзакций (Transaction Processing Monitors - TRM), или просто монитором транзакций. AS-модель, сохраняя сильные стороны DBS-модели, позволяет оптимально построить вычислительную схему информационной системы, однако, как и в случае RDA-модели, повышает трафик сети. В практических случаях используются смешанные модели, когда простейшие прикладные функции и обеспечение ограничений целостности данных поддерживаются хранимыми на сервере процедурами (DBS-модель), а более сложные функции предметной области (так называемые правила бизнеса) реализуются прикладными программами на клиентских установках (RDA-модель) или на сервере приложений (AS-модель).
Модульное проектирование Реализация метода нисходящего проектирования тесно связана с другим понятием программирования - модульным проектированием, так как на практике при декомпозиции сложной программы возникает вопрос о разумном пределе ее дробления на составные части. Вместе с тем понятие модульности нельзя сводить только к представлению сложных программных комплексов в виде набора отдельных функциональных блоков. Модуль - это последовательность логически взаимосвязанных фрагментов задачи, оформленных как отдельная часть программы. При этом программные модули должны обладать следующими свойствами: § на модуль можно ссылаться (т.е. обращаться к нему) по имени, в том числе и из других модулей; § по завершении работы модуль должен возвращать управление тому модулю, который его вызывал; § модуль должен иметь один вход и выход; § модуль должен иметь небольшой размер, обеспечивающий его обозримость. При разработке сложных программ в них выделяют головной управляющий модуль, подчиненные ему модули, обеспечивающие реализацию отдельных функций управления, функциональную обработку (т.е. непосредственную реализацию основного назначения программного комплекса), а также вспомогательные модули, обеспечивающие сервисное обслуживание пакета (например, сбор и анализ статистики работы программы, обработка различного рода ошибочных ситуаций, обучение и выдача подсказок и т.п.). Модульный принцип разработки программ обладает следующими преимуществами: § большую программу могут разрабатывать одновременно несколько исполнителей, и это позволяет сократить сроки ее разработки; § появляется возможность создавать и многократно использовать в дальнейшем библиотеки наиболее употребимых программ; § упрощается процедура загрузки больших программ в оперативную память, когда требуется ее сегментация; § возникает много естественных контрольных точек для наблюдения за осуществлением хода разработки программ, а в последующем для контроля за ходом исполнения программ; § обеспечивается более эффективное тестирование программ, проще осуществляются проектирование и последующая отладка. Преимущества модульного принципа построения программ особенно наглядно проявляются на этапе сопровождения и модификации программных продуктов, позволяя значительно сократить затраты сил и средств на реализацию этого этапа. Структурное программирование Актуальная для начального периода развития и использования ЭВМ проблема разработки программ, занимающих минимум основной памяти и выполняющихся за кратчайшее время, в последующем в связи резким падением стоимости аппаратной части ЭВМ, значительным возрастанием их быстродействия и объемов памяти сменилась необходимостью разработки и применения принципиально новых методов составления программ. Все это нашло свое воплощение в разработке принципа структурного программирования. Одной из целей структурного программирования было стремление облегчить разработку и отладку программных модулей, а главное - их последующее сопровождение и модификацию. В настоящее время структурное программирование - это целая дисциплина, объединяющая несколько взаимосвязанных способов создания ясных, легких для понимания программ. Эффективность применения современных универсальных языков программирования во многом определяется удобством написания с их помощью структурных программ. CASE-технологии За последнее десятилетие в области средств автоматизации программирования сформировалось новое направление под общим названием CASE-технологии (Computer Aided Software Engineering). CASE-технология представляет собой совокупность средств системного анализа, проектирования, разработки и сопровождения сложных программных систем, поддерживаемых комплексом взаимоувязанных инструментальных средств автоматизации всех этапов разработки программ. Благодаря структурным методам CASE-технология на стадиях анализа и проектирования обеспечивает разработчиков широкими возможностями для различного рода моделирования, а централизованное хранение всей необходимой для проектирования информации и контроль за целостностью данных гарантируют согласованность взаимодействия всех специалистов, занятых в разработке ПО. Технологии RAD В начале 80-х годов появилась методология, по которой разработка программы начиналась не после завершения процесса выработки окончательных требований к ней, а как только устанавливались требования на первый, “стартовый” (пилотный) вариант прикладной программы, позволяющий начать содержательную работу по ее реализации на компьютере. Это дало пользователю возможность, получая уже с первых шагов конкретное представление о характере реализации задачи, уточнять ее постановку. Тем самым облегчался процесс экспериментального поиска нужного решения автоматизации задачи. Благодаря тесному взаимодействию разработчика с заказчиком (пользователем) на самом ответственном этапе создания прикладных программ между ними достигалось быстрое взаимопонимание цели поставленной задачи и возможности ее автоматизации в данных конкретных условиях. Это повышало скорость разработки программ и послужило основанием для названия такой технологии RAD (Rapid Application Development - быстрая разработка программ), которая получила широкое распространение. Data Warehouse Другое направление разработки прикладных программных средств, олицетворяющее собой современный подход к реализации широкого круга задач для принятия управленческих решений, базируется на концепции создания специального хранилища данных (Data Warehouse). Основное отличие концепции Data Warehouse от традиционного представления баз данных заключается в следующем: § во-первых, в том, что актуализация данных в Data Warehouse означает не обновление элементов информации, а добавление новых элементов к уже имеющимся (что расширяет возможности проведения различного рода сравнительного анализа); § во-вторых, в том, что наряду с информацией, непосредственно отражающей состояние системы управления, в Data Warehouse аккумулируются и метаданные. Метаданные (данные о данных) облегчают возможность визуального представления содержимого Data Warehouse, позволяют, " перемещаясь" по хранилищу, быстро отбирать необходимые данные для последующей обработки. Основные типы метаданных Data Warehouse отражают: § структуру и содержимое хранилища; § соответствие между исходными и выходными данными; § объемные характеристики данных; § критерии архивирования; § отношения между данными; § информацию по кодированию; § интервал жизни данных и т.п. Концепция Data Warehouse поддерживается RAD средствами разработки прикладного ПО. Концепция Data Warehouse обеспечивает возможность разработки программных приложений для поддержки процессов принятия решений с использованием OLAP-систем. Система OLAP (On-Line Analytical Process) предоставляет возможность разработки информационных систем, ориентированных на yна организацию многомерных баз данных и создание корпоративных сетей, а также обеспечивает поддержку Web-технологий в сетях Internet/Intranet Успешное применение инструментальных средств OLAP-систем объясняется быстротой разработки приложений, гибкостью и широкими возможностями в области доступа к данным и их преобразования. В настоящее время на рынке ПО предлагается большое число OLAP-стем, разработчиками которых являются различные фирмы, например IBM, Informix, Microsoft, Oracle, Sybase и др.
CASE-технологии
CASE-технологии - относительно новое направление, формировавшееся на рубеже 80-х годов. CASE-технологии делятся на две группы: § встроенные в систему реализации, в которых все решения по проектированию и реализации привязаны к выбранной системе явления базами данных (СУБД); § независимые от системы реализации, в которых все решения по проектированию ориентированы на унификацию начальных этапов жизненного цикла, средств их документирования и обеспечивают большую гибкость в выборе средств реализации. Основное достоинство CASE-технологии - поддержка коллективной работы над проектом за счет возможности работы в локальной сети разработчиков, экспорта/импорта любых фрагментов проекта, организационного управления проектом. Некоторые CASE-технологии ориентированы только на системных проектировщиков и предоставляют специальные графические средства для изображения различного вида моделей: § диаграмм потоков данных (DFD - data flow diagrams) совместно со словарями данных и спецификациями процессов; § диаграмм " сущность-связь" (ERD - entity relationship diagrams), являющихся информационной моделью предметной области; § диаграмм переходов состояний (STD - state transition diagrams), учитывающих события и реакцию на них системы обработки данных. Диаграммы DFD устанавливают связь источников информации с потребителями, выделяют логические функции (процессы) образования информации, определяют группы элементов данных и их хранилища (базы данных). Описание структуры потоков данных, определение их компонентов хранятся в актуальном состоянии в словаре данных, который выступает как база данных проекта. Каждая логическая функция может детализироваться с помощью DFD нижнего уровня согласно методам исходящего проектирования. Этими CASE-технологиями выполняются автоматизированное проектирование спецификаций программ (задание основных характеристик для разработки программ) и ведение словаря данных. Другой класс CASE-технологий поддерживает только разработку программ, включая: § автоматическую генерацию кодов программ на основании их спецификаций; § проверку корректности описания моделей данных и схем потоков данных; § документирование программ согласно принятым стандартам и актуальному состоянию проекта; § тестирование и отладку программ. Кодогенерация программ выполняется двумя способами: создание каркаса программ и создание полного продукта. Каркас программы служит для последующего ручного варианта редактирования исходных текстов, обеспечивая возможность вмешательства программиста; полный продукт не редактируется вручную. В рамках CASE-технологий проект сопровождается целиком, а не только его программные коды. Проектные материалы, подготовленные в CASE-технологии, служат заданием программистам, а само программирование скорее сводится к кодированию - переводу на определенный язык структур данных и методов их обработки, если не предусмотрена автоматическая кодогенерация.
Pascal (Паскаль) Язык Паскаль, созданный в конце 70-х годов, во многом напоминает Алгол, но в нем ужесточен ряд требований к структуре программы и имеются возможности, позволяющие успешно применять его при создании крупных проектов. Basic (Бейсик) Для этого языка имеются и компиляторы, и интерпретаторы, а по популярности он занимает первое место в мире. Он создавался в 60-х годах в качестве учебного языка и очень прост в изучении. С (Си) Популярное:
|
Последнее изменение этой страницы: 2016-05-30; Просмотров: 1173; Нарушение авторского права страницы

 I
I