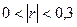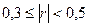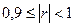|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Построение таблицы частот (простая группировка данных)Стр 1 из 3Следующая ⇒
Исследование массовых явлений включает этапы сбора статистической информации и ее первичной обработки, сведения и группировки результатов наблюдения в определенные совокупности, обобщения и анализа полученных материалов. Разбиение совокупности на группы, однородные по какому-либо признаку, называется группировкой. Признак, по которому происходит объединение отдельных единиц совокупности в однородные группы, называется группировочным признаком (он может быть как количественным, так и качественным). Количественные границы выделяемых групп очерчивает интервал, представляющий собой промежуток между максимальными и минимальными значениями признака в группе. Интервал – это значение варьирующего признака, лежащее в определенных границах. Группировка позволяет представить первичные данные в компактном виде, выявить закономерности варьирования изучаемого признака. Количество классов можно приблизительно наметить, пользуясь следующим: при количестве наблюдений 25-40 - 5-6 классов, при количестве наблюдений 40-60 - 6-8 классов, при количестве наблюдений 60-100 - 7-10 классов, при количестве наблюдений 100-200 - 8-12 классов, более 200 наблюдений - 10-15 классов Группировка, в которой для характеристики групп применяется численность группы, называется рядом распределения. Ряд распределениясостоит из двух элементов: варианты – отдельного значения варьирующего признака, которое он принимает в ряду распределения, и частоты – численность отдельных вариант, т.е. частота повторения каждой варианты. Таблицы частот представляют собой простейший метод анализа, когда группировка данных и построение ряда распределения производится по одному группировочному признаку. Пусть из генеральной совокупности X извлечена выборка
где n – объем выборки, ni – число появлений значения xi. Число ni появлений значения xi называют частотой, а частное Если объем выборки значителен, то дискретный вариационный ряд теряет наглядность. В этом случае выполняют группировку данных – построение интервального статистического ряда. Интервальныйстатистический рядстроится в случае непрерывной вариации группировочного признака у единиц совокупности (величина признака может принимать в определенных пределах любые значения, отличающиеся друг от друга на сколь угодно малую величину). При выполнении группировки весь диапазон
Частоты, соответствующие каждому разряду, находятся как суммы частот всех вариант, попавших в этот разряд (если в исходной выборке каждая варианта встречается только один раз, то частота находится как количество вариант, попавших в интервал). Графическим изображением вариационного ряда при дискретной вариации признака является полигон распределения, при непрерывной вариации – гистограмма. Определение. Полигоном частотназывают ломаную, отрезки которой соединяют точки с координатами Полигон служит для изображения дискретного статистического ряда. Полигон частостей является аналогом многоугольника распределения дискретной случайной величины в теории вероятностей.
Определение. Гистограммой частот (частостей) называют ступенчатую фигуру, состоящую из прямоугольников, основания которых расположены на оси
Гистограмма является графическим изображением интервального ряда. Площадь гистограммы частот равна Гистограмма позволяет сделать предварительное суждение о плотности распределении генеральной совокупности.
Можно построить полигон для интервального ряда, если его преобразовать в дискретный ряд. В этом случае интервалы заменяют их серединными значениями и ставят в соответствие интервальные частоты (частости). Полигон получим, соединив отрезками середины верхних оснований прямоугольников гистограммы.
Меры центральной тенденции Положение «центра» распределения генеральной совокупности может быть охарактеризовано тремя различными точечными оценками – оценкой медианы, оценкой моды и оценкой математического ожидания. Статистическими точечными оценками генеральной совокупности называют медиану, моду и дисперсию наблюдаемых значений. Свойства точечной оценки - состоятельности, несмещенности и эффективности Состоятельность. Оценка Если оценка несостоятельная, то она не имеет практического смысла: увеличение объема исходной информации не будет приближать нас к истине. Поэтому свойство состоятельности следует проверять в первую очередь. Несмещенность. Оценка M( Требование несмещенности гарантирует отсутствие систематических ошибок при оценивании. Эффективность. Несмещенная оценка Медиана— это значение, которое делит упорядоченное множество данных пополам, так что одна половина значений оказывается больше медианы, а другая — меньше. Если данные содержат нечетное число различных значений, например 11, 13, 18, 19, 20, то медиана есть центральное значение для случая, когда они упорядочены, т. е. Мe = 18. Если данные содержат четное число различных значений, например 4, 9, 13, 14, то медиана есть точка, лежащая посредине между двумя центральными значениями, когда они упорядочены: Мe = (9 + 13)/2 = 11. Таким образом,
Мода — это число, которое чаще других встречается в выборке (наиболее модное). Классический пример использования моды — выбор размера выпускаемой партии обуви или цвета обоев. Если распределение имеет несколько мод, то говорят, что оно мультимодально или многомодально (имеет два или более «пика»). Мультимодальность распределения дает важную информацию о природе исследуемой переменной. Например, в социологических опросах, если переменная представляет собой предпочтение или отношение к чему-то, то мультимодальность может означать, что существуют несколько определенно различных мнений. Мультимодальность также служит индикатором того, что выборка не является однородной и наблюдения, возможно, порождены двумя или более «наложенными» распределениями. В отличие от среднего арифметического, выбросы на моду не влияют. Для непрерывно распределенных случайных величин, например, для показателей среднегодовой доходности взаимных фондов, мода иногда вообще не существует (или не имеет смысла). Поскольку эти показатели могут принимать самые разные значения, повторяющиеся величины встречаются крайне редко. Оценкой математического ожидания является выборочное среднее – среднее арифметическое вариант
Отметим некоторые особенности рассмотрения мер центральной тенденции. 1. В небольших выборках мода может быть совершенно нестабильной. 2. На медиану не влияют величины самых больших и самых малых значений. 3. На величину среднего значения оказывает влияние каждый элемент выборки, если какой-либо элемент выборки изменится на величину с, то среднее значение изменится в том же направлении, на величину с/n. 4. Некоторые выборки вообще нельзя охарактеризовать с помощью мер центральной тенденции. Особенно это справедливо для выборок, имеющих более, чем 1 моду. 5. Если выборка является унимодальной, т.е. имеет 1 моду и гистограмма такой выборки является симметричной, то в этом случае мода, медиана и среднее значение совпадают. В табл. 2 приводятся данные о возможности использования тех или иных мер центральной тенденции в зависимости от типа измерительных шкал. Меры изменчивости Для характеристики «рассеяния» значений около «центра» используют оценки дисперсии, среднего квадратичного и среднего абсолютного отклонения. Дисперсия определяется по формуле
Дисперсия не удовлетворяет свойству несмещенности, в качестве несмещенной оценки дисперсии используют величину
Ценность дисперсии заключается в том, что, являясь мерой варьирования числовых значений признака вокруг его среднего значения, она измеряет внутреннюю изменчивость значений признака, зависящую от разностей между наблюдениями. Чем больше дисперсия выборки, тем больше разбросаны наши исходные значения по числовой оси относительно среднего значения выборки. Дисперсия является мерой изменчивости, вариации признака и представляет собой средний квадрат отклонений случаев от среднего значения признака. В отличии от других показателей вариации дисперсия может быть разложена на составные части, что позволяет тем самым оценить влияние различных факторов на вариацию признака. Дисперсия - один из существеннейших показателей, характеризующих явление или процесс, один из основных критериев возможности создания достаточно точных моделей. Поскольку оценка – это случайная величина, то показателем разброса значений случайной величины около ее математического ожидания является дисперсия. Так как математические ожидания несмещенных оценок равны оцениваемому параметру, следовательно, они одинаковы, следовательно, естественно считать лучшей, более эффективной ту оценку, у которой меньше дисперсия. В табл. 1 приведены оценки основных числовых характеристик случайной величины (математического ожидания, дисперсии, вероятности) и их свойств. Таблица 3 Оценки основных числовых характеристик случайной величины
. Однако на практике не всегда оценки удовлетворяют всем трем требованиям. Может оказаться, что даже если эффективная оценка существует, то формулы для ее вычисления оказываются слишком сложными, и тогда используют оценку, дисперсия которой несколько больше. Иногда, в интересах простоты расчетов, применяются незначительно смещенные оценки. Выбору оценки всегда должно предшествовать ее критическое рассмотрение Оценка стандартного (среднего квадратичного) отклонения связана с оценкой дисперсии соотношением
Стандартное отклонение часто является полезной мерой вариации, так как для многих распределений мы приблизительно знаем, какой процент данных лежит внутри одного, двух, трех и более стандартных отклонений среднего. Оно показывает на какую величину в среднем отклоняются случаи от среднего значения признака. Особенно большое значение имеет при исследовании нормальных распределений. В нормальном распределении 68% всех случаев лежит в интервале + одного отклонения от среднего, 95% - + двух стандартных отклонений от среднего и 99, 7% всех случаев - в интервале + трех стандартных отклонений от среднего. Стандартная ошибка оценки математического ожидания вычисляется как частное от деления стандартного отклонения на квадратный корень из объема выборки (как корень из частного от деления дисперсии на объем выборки). Оценка среднего абсолютного отклонения равна
Среднее отклонение не часто используется как мера изменчивости в связи с тем, что среднее отклонение не имеет теоретического обоснования в отличии, например, от дисперсии. Квантиль – это такое значение признака, которое делит распределение в заданной пропорции: слева 0, 5%, справа 99, 5%; слева 2, 5%, справа 97, 5% и т.п. Обычно выделяют следующие разновидности квантилей: 1) Квартили Q1, Q 2, Q3 – делят распределение на четыре части по 25% в каждой; 2) Квинтили К1, К2, К3, К4 – делят распределение на пять частей по 20% в каждой; 3) Децили D1, ..., D9, их девять, и делят распределение на десять частей по 10% в каждой; 4) Процентили P1, Р2..., Р99, их девяносто девять, и они делят распределение на сто частей по 1% в каждой части. Поскольку процентиль – наиболее мелкое деление, то все другие квантили могут быть представлены через процентили. Так, первый квартиль – это двадцать пятый процентиль, первый квинтиль – второй дециль или двадцатый процентиль, и т.п. Характеристиками рассеяния вариант также являются нижняя x1/4 и верхняя x3/4 квартили – значения, для которых число вариант, удовлетворяющих неравенствам Оценки моментов третьего и четвертого порядков и связанные с ними безразмерные величины – оценки асимметрии и эксцесса – используются реже. Оценка асимметрии
характеризует «скос» распределения относительно его «центра» в положительном или отрицательном направлениях, соответственно. Оценка эксцесса
характеризует «островершинность» (при
Первая кривая (А) является совсем острой: подобная кривая называется островершинной. Вторая (Б) — сравнительно плоская: такие кривые называются плосковершинными. «Островершинность», или степень эксцесса, третьей кривой (В) представляет собой норму, по отношению к которой измеряется эксцесс других кривых. Третья кривая на рис. 1.3 — нормальная кривая, принято говорить, что она является средневершинной. Теперь мы рассмотрим способ измерения эксцесса кривой. Однако сначала необходимо подчеркнуть, что понятие «эксцесс» применимо лишь к одномодальным распределениям и относится к крутизне кривой в окрестности единственной моды. (Если распределение имеет две моды, то принято говорить об эксцессе кривой в окрестности каждой моды.) Обычная мера эксцесса (Ex) определяется следующей формулой
Соотношения между величиной статистики асимметрии и «островершинностью» распределения, для которого она вычислялась, показаны в табл. 4. Таблица 4 Соотношение величины статистики эксцесса с «островершинностью» распределения частот
В практике довольно часто приходится сравнивать изменчивость признаков, выраженных разными единицами. В таких случаях используют не абсолютные, а относительные показатели вариации. Дисперсия и среднее отклонение как величины, выражаемые теми же единицами, что и характеризуемый ими признак, для оценки изменчивости разноимённых величин непригодны. Одним из относительных показателей вариации является коэффициент вариации. Этот показатель представляет собой среднее квадратическое отклонение, выраженное в процентах от величины среднего значения:
Различные признаки характеризуются различными коэффициентами вариации. Но в отношении одного и того же признака значение этого показателя Cv остаётся более или менее устойчивым и при симметричных распределениях обычно не превышает 50 %. При сильно асимметричных рядах распределения коэффициент вариации может достигать 100 % и даже выше. Варьирование считается · слабым, если не превосходит 10 %, · средним, когда Cv составляет 11—25 %, · значительным при Cv > 25 %. Числовые характеристики эмпирического распределения называются выборочными характеристиками. При выборке малого объема точечная оценка может существенно отличаться от оцениваемого параметра. В этом случае целесообразно использовать интервальные оценки. Определение. Интервальнойназывают оценку, которая определяется двумя числами – концами интервала. Определение. Доверительной вероятностью ( надежностью) оценки Обычно задается надежность Неравенство Определение. Доверительным интервалом называется интервал
Меры связи между признаками Анализ связей между признаками – главный вид задач, встречающийся практически в любом эмпирическом исследовании. Изучение связей между переменными, интересует исследователя не само по себе, а как отражение соответствующих причинно-следственых отношений. Корреляционный анализ – вид статистического анализа, который состоит в количественной оценке силы и направления связи между двумя ( парная корреляция ) или несколькими ( множественная корреляция ) наборами данных. Для количественной оценки силы связи используются коэффициенты парной корреляции r и множественной корреляции R. Основные условия применения 1. Наличие достаточно большой по объему выборочной совокупности. Считается, что число наблюдений должно превышать более чем в 10 раз число факторов, влияющих на результат. 2. Наличие качественно однородной исследуемой совокупности. 3. Подчинение распределения совокупности по результативному и факторным признакам нормальному закону или близость к нему. Выполнение этого условия обусловлено использованием метода наименьших квадратов (МНК) при расчете параметров корреляции и некоторых др. Основные задачи корреляционного анализа 1. Измерение тесноты связи между результативным и факторным признаком (признаками). В зависимости от количества влияющих на результат факторов задача решается путем вычисления корреляционного отношения, коэффициентов парной, частной, множественной корреляции или детерминации. 2. Оценка параметров уравнения регрессии, выражающего зависимость средних значений результативного признака от значений факторного признака (признаков). Задача решается путем вычисления коэффициентов регрессии. 3. Определение важнейших факторов, влияющих на результативный признак. Задача решается путем оценки тесноты связи факторов с результатом. 4. Прогнозирование возможных значений результативного признака при задаваемых значениях факторных признаков. Задача решается путем подстановки ожидаемых значений факторов в регрессионное уравнение и вычисления прогнозируемых значений результата. При изучении корреляций стараются установить, существует ли какая-то связь между двумя показателями в одной выборке (например, между ростом и весом детей или между уровнем IQ и школьной успеваемостью) либо между двумя различными выборками (например, при сравнении пар близнецов), и если эта связь существует, то сопровождается ли увеличение одного показателя возрастанием (положительная корреляция) или уменьшением (отрицательная корреляция) другого. Иными словами, корреляционный анализ помогает установить, можно ли предсказывать возможные значения одного показателя, зная величину другого. Первоначальное значение термина " корреляции" – взаимная связь. Когда говорят о корреляции, используют термины " корреляционная связь" и " корреляционная зависимость". Корреляционная связь – это согласованные изменения двух признаков или большего количества признаков (множественная корреляционная связь). Корреляционная зависимость – это изменения, которые вносят значения одного признака в вероятность появления разных значений другого признака. Зависимость подразумевает влияние, связь – любые согласованные изменения, которые могут объясняться сотнями причин. Корреляционные связи не могут рассматриваться как свидетельство причинно-следственной связи, они свидетельствуют лишь о том, что изменениям одного признака, как правило, сопутствуют определенные изменения другого, но находится ли причина изменений в одном из признаков или она оказывается за пределами исследуемой пары признаков, нам неизвестно. Корреляционные связи различаются по форме, направлению и степени (силе). По форме корреляционная связь может быть прямолинейной или криволинейной. При повышении мотивации эффективность выполнения задачи сначала возрастает, затем достигается оптимальный уровень мотивации, которому соответствует максимальная эффективность выполнения задачи; дальнейшему повышению мотивации сопутствует уже снижение эффективности. По направлению корреляционная связь может быть положительной (" прямой" ) и отрицательной (" обратной" ). При положительной прямолинейной корреляции более высоким значениям одного признака соответствуют более высокие значения другого, а более низким значениям одного признака – низкие значения другого (см. рис. 1.2). При отрицательной корреляции соотношения обратные. При положительной корреляции коэффициент корреляции имеет положительный знак, например r=+0, 207, при отрицательной корреляции – отрицательный знак, например r=-0, 207.
Рис. 1.2. Схема прямолинейных корреляционных связей: а) положительная (прямая) связь, б) отрицательная (обратная) связь Степень, сила или теснота корреляционной связи определяется по величине коэффициента корреляции. Сила связи не зависит от ее направленности и определяется по абсолютному значению коэффициента корреляции. Линейный коэффициент корреляции
Коэффициент корреляции – это величина, которая может варьировать в пределах от +1 до –1. В случае полной положительной корреляции этот коэффициент равен плюс 1, а при полной отрицательной – минус 1. На графике этому соответствует прямая линия, проходящая через точки пересечения значений каждой пары данных: В случае если коэффициент корреляции равен 0, обе переменные полностью независимы друг от друга. Для качественной оценки силы связи используются специальные табличные соотношения (например, шкала Чеддока, табл. 5) Таблица 5 Шкала Чеддока
Направление связи определяется знаками ±: близость к +1 означает, что возрастанию одного набора значений соответствует возрастание другого набора, близость к -1 означает обратное. 4.2. . Методы проверки статистических гипотез. Статистические гипотезы Любое исследование направлено на определение некоторой характеристики изучаемой генеральной совокупности или выявление связи между признаками (факторами). Такая связь часто исследуется в причинно-следственном аспекте, когда некоторые факторы рассматриваются как причины (независимые переменные), а другие - как следствия или результаты (зависимые переменные). Связь может характеризоваться не только величиной (степенью связи) и направлением (что показывает, например, коэффициент корреляции), но также и статистической достоверности. Последняя характеристика связи показывает, можно ли распространить результаты, полученные на данной выборке, на всю генеральную совокупность, из которой взята эта выборка. Любое заключение, полученное из статистического наблюдения / исследования / анализа, - индуктивно и строится на конечном числе наблюдений, поэтому оно не полно и может быть недостоверно. Необходимо обоснование заключения, Т.е. тестирование результатов, на которых строится гипотеза, на статистическую достоверность. Достоверность непосредственно связана с репрезентативностью выборки, Т.е. с тем, насколько уверенно данные, полученные по выборке, позволяют судить о соответствующих параметрах генеральной совокупности. Целью исследования почти никогда не является изучение данной конкретной выборки; выборка представляет интерес лишь постольку, поскольку она дает информацию обо всей генеральной совокупности. Статистическая достоверность связи определяется тем, насколько вероятно, что обнаруженная в выборке связь подтвердится (будет вновь обнаружена) на другой выборке той же генеральной совокупности. Основной задачей статистической проверки гипотез является репрезентативное выборочное описание свойств генеральных совокупностей. Для описания значительных по объему совокупностей свойств, состояний, процессов требуется накопление огромного выборочного материала или проведение исследований в национальном масштабе. Поэтому задача репрезентативного описания сводится к задаче проверки однородности выборочных описаний, полученных в разных исследованиях, и к объединению однородных данных. Для проверки однородности, необходимы: а) однообразность статистических описаний одних и тех же явлений разными авторами; б) указание на величину объектов выборок, из которых вычислялись статистические оценки параметров и функций. Начало любого исследования – это постановка проблемы. Самые простые, наивные вопросы являются прототипами проблемы. В отличие от житейской, научная проблема формулируется в терминах определенной научной отрасли. Постановка проблемы влечет за собой формулировку гипотезы. Гипотеза – это научное предположение, вытекающее из теории, которое еще не подтверждено и не опровергнуто. Научная гипотеза должна удовлетворять: • принципам фальсифицируемости – быть опровергаемой в эксперименте; принцип фальсифицируемости абсолютен, так как опровержение теории всегда окончательно, • принципам верифицируемости – быть подтверждаемой в эксперименте, этот принцип относителен, так как всегда есть вероятность опровержения гипотезы в следующем исследовании. Различают научные и статистические гипотезы. Научные гипотезы формулируются как предполагаемое решение проблемы. Статистическая гипотеза – утверждение в отношении неизвестного параметра, сформулированное на языке математической статистики. Любая научная гипотеза требует перевода на язык статистики. После проведения конкретного эксперимента проверяются многочисленные статистические гипотезы, поскольку в каждом исследовании регистрируется не один, а множество поведенческих параметров. Каждый параметр характеризуется несколькими статистическими мерами: центральной тенденции, изменчивости, распределения. Можно вычислить меры связи параметров и оценить значимость этих связей. Научные гипотезы. Экспериментальная гипотеза служит для организации эксперимента, а статистическая – для организации процедуры сравнения регистрируемых параметров. Статистическая гипотеза необходима на этапе математической интерпретации данных эмпирических исследований. Большое количество статистических гипотез необходимо для подтверждения или опровержения основной – экспериментальной гипотезы. Экспериментальная гипотеза – первична, статистическая – вторична. Процесс выдвижения и опровержения гипотез можно считать основным и наиболее творческим этапом деятельности исследователя. Установлено, что количество и качество гипотез определяется общей креативностью (общей творческой способностью) исследователя – «генератора идей». Гипотеза может отвергаться, но никогда не может быть окончательно принятой. Любая гипотеза открыта для последующей проверки. Формулирование гипотез систематизирует предположения исследователя и представляет их в четком и лаконичном виде. Статистические гипотезы. В обычном языке слово «гипотеза» означает предположение. В том же смысле оно употребляется в научном языке, используясь в основном для предположений, вызывающих сомнение. В математической статистике термин «гипотеза» означает предположение, которое не только вызывает сомнения, но и которое мы собираемся в данный момент проверить. При построении статистической модели приходиться делать много различных допущений и предположений, и далеко не все из них мы собираемся или можем проверить. Статистическая проверка гипотезы состоит в выяснении того, насколько совместима эта гипотеза с имеющимся результатом случайного выбора. Определение. Статистическая гипотеза – это предположение о распределении вероятностей, которое мы хотим проверить по имеющимся данным. Гипотезы различают простые и сложные: • простая гипотеза полностью задает распределение вероятностей; • сложная гипотеза указывает не одно распределение, а некоторое множество распределений. Обычно это множество распределений, обладающих определенным свойством. Статистические гипотезы подразделяются на нулевые и альтернативные. Гипотезу, выдвинутую для проверки ее согласия с выборочными данными, называют нулевой гипотезой и обозначают H0. Вместе с гипотезой H0 выдвигается альтернативная или конкурирующая гипотеза, которая обозначается H1. Например:
Бывают задачи, когда мы хотим доказать незначимость различий, то есть подтвердить нулевую гипотезу. Например, если нам нужно убедиться, что разные испытуемые получают хотя и различные, но уравновешенные по трудности задания, или что экспериментальная и контрольная выборки не различаются между собой по каким-то значимым характеристикам. Чаще всего требуется доказать значимость различий, ибо они более информативны для нас в поиске нового. Проверка гипотез осуществляется с помощью критериев статистической оценки различий. Статистические критерии Статистическим критерием называется случайная величина К с известным законом распределения, служащая для проверки нулевой гипотезы. В большинстве случаев для того, чтобы мы признали различия значимыми, необходимо, чтобы эмпирическое значение критерия превышало критическое, в некоторых критериях придерживаются противоположного правила. Эти правила оговариваются в описании каждого критерия. Одно и то же эмпирическое значение критерия может оказаться значимым или незначимым в зависимости от количества наблюдений в выборке (n) или от так называемого количества степеней свободы, которое обозначается как ν. Число степеней свободы. Число степеней свободы равно числу классов вариационного ряда минус число условий, при которых он был сформирован. К числу таких условий относятся: объем выборки, средние и дисперсии. Популярное:
|
Последнее изменение этой страницы: 2016-06-05; Просмотров: 6086; Нарушение авторского права страницы
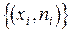 ,
,  ,
,
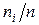 от деления частоты на объем выборки – относительной частотой. Последовательность вариант и соответствующих им частот, упорядоченная в возрастающем порядке, называется дискретным статистическим рядом. Ряды распределения, построенные по качественным группировочным признакам, называютсяатрибутивными.
от деления частоты на объем выборки – относительной частотой. Последовательность вариант и соответствующих им частот, упорядоченная в возрастающем порядке, называется дискретным статистическим рядом. Ряды распределения, построенные по качественным группировочным признакам, называютсяатрибутивными.  изменения величины x делится на несколько интервалов – разрядов, число которых выбирают по правилу Стерджеса:
изменения величины x делится на несколько интервалов – разрядов, число которых выбирают по правилу Стерджеса:  .
.
 ; полигоном частостей – с координатами
; полигоном частостей – с координатами 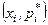 , где
, где  ,
,  .
.
 и длины их равны длинам частичных интервалов
и длины их равны длинам частичных интервалов  , а высоты равны отношению:
, а высоты равны отношению:  - для гистограммы частот;
- для гистограммы частот; 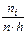 - для гистограммы частостей.
- для гистограммы частостей. , а гистограммы частостей равна 1.
, а гистограммы частостей равна 1.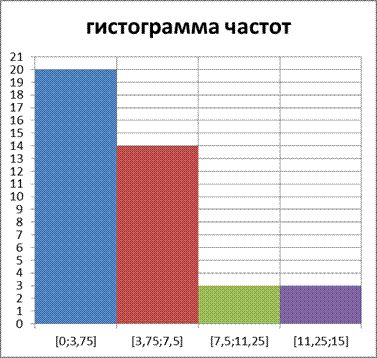

 характеристики
характеристики  называется состоятельной, если она удовлетворяет закону больших чисел, т.е. сходится по вероятности к оцениваемому параметру: Если говорить коротко то, чем больше объем исходной информации, тем ближе оценка к оцениваемому параметру. Если это так, то
называется состоятельной, если она удовлетворяет закону больших чисел, т.е. сходится по вероятности к оцениваемому параметру: Если говорить коротко то, чем больше объем исходной информации, тем ближе оценка к оцениваемому параметру. Если это так, то  .
. .
. .
.
 .
.
 (1.5)
(1.5) .
.



 .
.
 .
.
 и
и  , составляет 25% и 75%, соответственно.
, составляет 25% и 75%, соответственно.

 ) или «плосковершинность» (при
) или «плосковершинность» (при  ) распределения по сравнению с нормальным. На рис. 1.1 изображены 3 кривые, отличающиеся по «остроконечности», или эксцессу.
) распределения по сравнению с нормальным. На рис. 1.1 изображены 3 кривые, отличающиеся по «остроконечности», или эксцессу.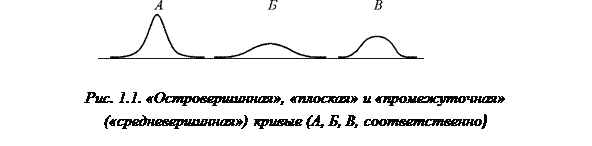
 (1.11)
(1.11) (1.12)
(1.12) параметра
параметра  называется вероятность
называется вероятность  , с которой выполняется неравенство
, с которой выполняется неравенство  .
. . Чаще всего надежность задается значениями от 0, 95 и выше, в зависимости от конкретно решаемой задачи.
. Чаще всего надежность задается значениями от 0, 95 и выше, в зависимости от конкретно решаемой задачи.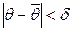 можно записать
можно записать  .
. , который покрывает неизвестный параметр с заданной надежностью
, который покрывает неизвестный параметр с заданной надежностью 
 Пирсона, который можно рассчитать по следующей формуле:
Пирсона, который можно рассчитать по следующей формуле: