
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Схема построения казуальных моделей ⇐ ПредыдущаяСтр 6 из 6
Рассмотрим схему построения казуальных моделей на примере построения прогнозной модели производительности труда. Первый этап - это постановка задачи. Постановка задачи - это четкое определение цели создания модели и определение объекта моделирования. Например, необходимо составить план по производительности труда на следующую пятилетку на одном из предприятий г. Рязани. Мы можем поставить задачу об увеличении производительности труда в два раза, но это не будет обосновано. Необходимо определить, от чего качественно зависит производительность труда, затем построить количественную модель, сделать прогноз по этим факторам и подставить прогнозные значения факторов в модель, а затем уже определить прогнозное значение производительности труда. Второй этап - это - сбор и систематизация статистической информации. Производительность труда называется результативным признаком -
Третий этап - статистическая оценка значимости факторов или корреляционный анализ. Максимальный перечень факторов, составленный экспертами, может содержать несколько факторных признаков, которые слабо влияют на результативный, и которые не целесообразно включать в модель. Для оценки степени влияния двух случайных величин Результаты расчета коэффициентов парной корреляции оформляется в виде таблицы.
Матрица имеет единицы по диагонали и симметрична относительно этой главной диагонали. В нашем примере получена следующая таблица:
Выбор факторов, включенных в модель, производится в два шага. На первом шаге рассматриваются коэффициенты корреляции между результативными и факторными признаками. Если коэффициент превышает некоторое предварительно заданное число, то данный фактор включается в модель, в обратном случае - исключается из рассмотрения. В нашем случае отбрасываем третий фактор. На втором шаге рассматриваются коэффициенты парной корреляции между оставшимися факторными признаками. Если рассматриваемый показатель превышает некоторое пороговое значение, то один из факторных признаков исключается. В обратном случае оба фактора включаются в модель. Четвертый этап - построение эмпирического уравнения регрессии. Строятся графики зависимостей Пятый этап - построение однофакторных уравнений регрессии. Рассмотрим построение линейной регрессии.
Из этих уравнений получаем значение неизвестных коэффициентов регрессии

Для нелинейных моделей метод наименьших квадратов не работает, поэтому необходимо привести нелинейную модель к линейной. Это делается путем логарифмирования и замены переменной. Шестой этап - построение многофакторной модели. Ее построение начинается с выбора формы зависимости. Если среди эмпирических зависимостей преобладают линейные зависимости, то строится многофакторная линейная зависимость Седьмой этап - оценка точности и адекватности регрессионной модели или дисперсионный анализ. В данном случае можно рассчитать несколько видов дисперсий: D0 - рассеивание относительно уравнения регрессии; Dр - рассеивание точек, лежащих на уравнении регрессии относительно среднего значения. Общая дисперсия Остаточная дисперсия (относительно уравнения регрессии) Дисперсия, обусловленная регрессией, Используются следующие показатели: - остаточная дисперсия. Если у нас зависимость функциональная, то точка выборки будет лежать на уравнении регрессии и остаточная дисперсия будет равна нулю; - коэффициент множественной корреляции. Существует несколько формул для его расчета. - средняя относительная ошибка - доверительный интервал позволяет оценить качество модели. Для k-й точки доверительный интервал вычисляется следующим образом: однофакторная модель - критерий Фишера оценивает адекватность модели Популярное:
|
Последнее изменение этой страницы: 2016-08-24; Просмотров: 524; Нарушение авторского права страницы
 , факторные признаки – это признаки от которых зависит производительность труда
, факторные признаки – это признаки от которых зависит производительность труда  , где
, где  . При выборе факторного признака он должен быть количественно выражен; легко управляем; зависеть от нас и влиять на производительность труда. Мы выбираем: удельный вес новой техники; заработную плату; основные фонды; продолжительность рабочего дня. Мы должны собрать информацию по этим признакам. Информация берется из документов предприятия. Причем исследуется максимальный перечень факторных признаков. Результат сбора информации оформляется в виде таблицы. Первый столбец - результативный признак, а последующие факторные признаки. Точка выборки - год (квартал). Мы также можем исследовать производительность на нескольких предприятиях, в течение несколько лет, тогда точка выборки - завод-год.
. При выборе факторного признака он должен быть количественно выражен; легко управляем; зависеть от нас и влиять на производительность труда. Мы выбираем: удельный вес новой техники; заработную плату; основные фонды; продолжительность рабочего дня. Мы должны собрать информацию по этим признакам. Информация берется из документов предприятия. Причем исследуется максимальный перечень факторных признаков. Результат сбора информации оформляется в виде таблицы. Первый столбец - результативный признак, а последующие факторные признаки. Точка выборки - год (квартал). Мы также можем исследовать производительность на нескольких предприятиях, в течение несколько лет, тогда точка выборки - завод-год. - производительность труда, в тыс. р./чел.
- производительность труда, в тыс. р./чел.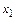 - фондовооруженность, тыс. р./чел.
- фондовооруженность, тыс. р./чел. - энерговооруженность, кВт/чел.
- энерговооруженность, кВт/чел. - коэффициент специализации, %.
- коэффициент специализации, %. и
и  ,
,  смешанный центральный момент второго порядка.
смешанный центральный момент второго порядка. 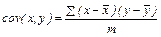 . Коэффициент корреляции
. Коэффициент корреляции  , где
, где  - объем выборки. Коэффициент парной корреляции меняется от -1(если связь обратная) до 1(если связь прямая). Если
- объем выборки. Коэффициент парной корреляции меняется от -1(если связь обратная) до 1(если связь прямая). Если  и
и  не связаны между собой, то коэффициент равен нулю.
не связаны между собой, то коэффициент равен нулю.

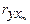





 . Если большинство зависимостей линейно, то и общая модель будет линейной.
. Если большинство зависимостей линейно, то и общая модель будет линейной. . Для нахождения коэффициентов регрессии
. Для нахождения коэффициентов регрессии  используется метод наименьших квадратов.
используется метод наименьших квадратов. 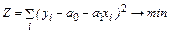 .
.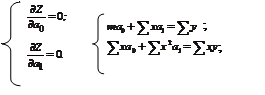

 . Если преобладают нелинейные зависимости, то и множественная регрессия будет нелинейной. Можно использовать в этом случае мультистепенную зависимость
. Если преобладают нелинейные зависимости, то и множественная регрессия будет нелинейной. Можно использовать в этом случае мультистепенную зависимость 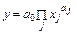 , которую путем логарифмирования приводим к линейной:
, которую путем логарифмирования приводим к линейной:  . Коэффициенты регрессии
. Коэффициенты регрессии  определяются с помощью метода наименьших квадратов
определяются с помощью метода наименьших квадратов  . Дифференцируя
. Дифференцируя  по
по  и приравнивая частные производные к нулю, получаем систему уравнений, которую запишем в матричной форме -
и приравнивая частные производные к нулю, получаем систему уравнений, которую запишем в матричной форме -  , где
, где  - матрица факторных признаков размерностью
- матрица факторных признаков размерностью  ,
,  - вектор-строка коэффициентов регрессии размерностью
- вектор-строка коэффициентов регрессии размерностью  ,
,  .
.

 .
. . Если остаточная дисперсия равна нулю, то коэффициент равен единице, т.е. зависимость функциональная.
. Если остаточная дисперсия равна нулю, то коэффициент равен единице, т.е. зависимость функциональная.  ,
,  . Здесь надо вычислить матрицу, обратную матрице коэффициентов парной корреляции, и взять ее первый элемент
. Здесь надо вычислить матрицу, обратную матрице коэффициентов парной корреляции, и взять ее первый элемент  . Коэффициент множественной корреляции меняется от нуля до единицы, квадрат данного коэффициента называется коэффициентом детерминации и показывает долю изменчивости результативного признака за счет вариации всех факторных, включенных в модель;
. Коэффициент множественной корреляции меняется от нуля до единицы, квадрат данного коэффициента называется коэффициентом детерминации и показывает долю изменчивости результативного признака за счет вариации всех факторных, включенных в модель;  ;
;  , для многофактор-ной модели
, для многофактор-ной модели 

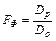 . Полученный критерий сравнивается с табличным значением, для вероятности
. Полученный критерий сравнивается с табличным значением, для вероятности  и число степеней свободы
и число степеней свободы  . Если вычисленное значение больше табличного, то модель адекватна. На практике желательно, чтобы вычисленное значение было больше табличного в четыре раза.
. Если вычисленное значение больше табличного, то модель адекватна. На практике желательно, чтобы вычисленное значение было больше табличного в четыре раза.