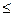|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Определение дисперсии методом моментов
Преобразованием приведенных выше логических формул определения дисперсии могут быть получены ее новые формулы для расчета, например, методом моментов, которым иногда значение дисперсии получается быстрее.
Окончательно записываем, что дисперсия методом моментов определяется по формуле Д = где Эти параметры нередко имеют и другие названия. Вычитаемое называют начальным моментом первого порядка, уменьшаемое – начальным моментом второго порядка, а сама дисперсия при этом называется центральным моментом второго порядка. Для иллюстрации пользования формулами дисперсии рассмотрим простейший пример, приняв абстрактно Х1 = 2, Х2 = 4, Х3 = 6, для которых среднее значение, очевидно, равняется Д3 = ((2-4)2 + (4-4)2 + (6-4)2)/3 = 8/3 = 2, 67 Применив формулу моментов (1.32), получим тот же результат Д3 =(22 + 42 + 6 2 )/3 – 42 = 56/3 – 16 = 2, 67 В данном примере быстрота определения дисперсии методом моментов не достаточно ощутима, но она проявляется очень заметно при большом количестве статистических данных. 19. Свойства средней арифметической и дисперсии В статистических расчетах эти характеристики статистической совокупности зачастую применяются во взаимодействии. При этом с целью приведения их к удобному для анализа виду при громоздких значениях статистических величин используют следующие свойства. 1. Если каждую статистическую величину изменить на одно число (прибавить или отнять), то средняя арифметическая изменится на это число, а дисперсия при этом не изменится. 2. Если каждую статистическую величину изменить в одинаковое число раз (умножить или разделить), то средняя арифметическая изменится во столько же раз, а дисперсия изменится в квадрат таких раз. Доказать эти свойства можно путем математических преобразований соответствующих формул, но гораздо проще доказательство получается с помощью следующего численного примера. Принимая предыдущие три статистические величины с их значениями 2, 4, и 6, сначала прибавим к каждой из них 5, а потом умножим каждую из них на 5. Тогда получим измененные значения статистических величин, представленные матрицей X1=2; X1’=2+5=7; X1’’=2*5=10. X2=4; X2’=4+5=9; X2’’=4*5=10. X3=6; X3’=6+5=11; X3’’=6*5=30. Д=2, 67; Д’=2, 67; Д’’=66, 67. В этой матрице значения средних арифметических очевидны, а первоначальное значение дисперсии было найдено в предыдущем примере. Расчет других ее значений приведен ниже по логической формуле (1.24) Д’= ((7-9)2 + (9-9)2 + (11-9)2)/3 = 2, 67 Д’’= ((10-20)2 + (20-20)2 + (30-20)2)/3 = 66, 67 Отмечаем, что отношение 66, 67/2, 67 дает ровно 25 или 52. То есть при увеличении каждой статистической величины в 5 раз дисперсия увеличилась в 25 раз. Аналогичные численные доказательства можно выполнить и в случаях противоположного изменения статистических величин. Понятие и отбор единиц Выборочный метод используется, когда применение сплошного наблюдения физически невозможно из-за огромного массива данных или экономически нецелесообразно. Физическая невозможность имеет место, например, при изучении пассажиропотоков, рыночных цен, семейных бюджетов. Экономическая нецелесообразность имеет место при оценке качества товаров, связанной с их уничтожением. Например, дегустация, испытание кирпичей на прочность и т.п. Выборочное наблюдение используется также для проверки результатов сплошного. Статистические величины, отобранные для наблюдения, составляют выборочную совокупность или выборку, а весьих массив - генеральную совокупность. При этом число величин в выборке обозначают п, во всей генеральной совокупности — как обычно N. Отношение n/N называется относительный размер или частость выборки, измеряемая в процентах. Качество результатов выборочного наблюдения зависит от репрезентативности выборки, т.е. от того, насколько она представительна в генеральной совокупности. Для обеспечения репрезентативности выборки надо соблюдать принцип случайности отбора статистических величин, который реализуется разными способами. 1. Собственно случайный отбор или «метод лото», когда статистическим величинам присваиваются порядковые номера, заносимые на определенные предметы (бумажки, фишки, кубики, бочонки, шары), которые затем перемешиваются в некоторой емкости (шапка, мешок, ящик, барабан) и выбираются наугад. Этот способ можно осуществить также с помощью математических таблиц случайных чисел. 2. Механический отбор, согласно которому отбирается каждая (N/п)-я величина генеральной совокупности. Так, если она содержит 100000 величин, а требуется выбрать 1000, то в выборку попадет каждая 100000 / 1000 = 100-я величина. Причем, если они не ранжированы, то первая выбирается наугад из первой сотни, а номера других будут на сотню больше. Например, если первой оказалась статистическая величина № 19, то следующей должна быть № 119, затем № 219, затем № 319 и т. д. Если статистические величины ранжированы, то первой выбирается № 50, затем № 150, затем № 250 и так далее. 3. Отбор величин из неоднородного массива данных ведется стратифицированным (расслоенным) способом, когда генеральная совокупность предварительно разбивается на однородные группы, к которым применяется случайный или механический отбор. 4. Особый способ составления выборки представляет собой серийный или гнездовой отбор, при котором случайно или механически выбирают не отдельные величины, а их серии или гнезда, внутри которых ведут сплошное наблюдение. Качество выборочных наблюдений зависит и от типа выборки: повторная или бесповторная. В первом случае попавшие в выборку статистические величины или их серии после использования возвращаются в генеральную совокупность, имея шанс попасть в новую выборку. При этом у всех величин генеральной совокупности одинаковая вероятность включения в выборочную совокупность. Бесповторный отбор означает, что попавшие в выборку статистические величины или их серии после использования не возвращаются в генеральную совокупность, а потому для остальных величин последней повышается вероятность попадания в следующую выборку. Бесповторный отбор дает более точные результаты, поэтому применяется чаще. Но есть ситуации, когда его применить нельзя (изучение пассажиропотоков, потребительского спроса и т.п.) и тогда ведется повторный отбор. Средняя ошибка выборки Выборочную совокупность можно сформировать по количественному признаку статистических величин, а также по альтернативному или атрибутивному. В первом случае обобщающей характеристикой выборки служит выборочная средняя величина, обозначаемая Разности Величина ошибки выборки зависит от структуры последней. Например, если при определении среднего балла успеваемости студентов факультета в одну выборку включить больше отличников, а в другую - больше неудачников, то выборочные средние баллы и ошибки выборки будут разными. Поэтому в статистике определяется средняя ошибка повторной и бесповторной выборки в виде ее удельного среднего квадратического отклонения по формулам где Дв — выборочная дисперсия, определяемая при количественном признаке статистических величин по обычным формулам из гл.2. При альтернативном или атрибутивном признаке выборочная дисперсия определяется по формуле Дв = w(1-w).(1.37) Из формул (1.35) и (1.36) видно, что средняя ошибка меньше у бесповторной выборки, что и обусловливает ее более широкое применение. Предельная ошибка выборки Учитывая, что на основе выборочного обследования нельзя точно оценить изучаемый параметр (например, среднее значение) генеральной совокупности, необходимо найти пределы, в которых он находится. В конкретной выборке разность где t – коэффициент доверия, зависящий от вероятности, с которой определяется предельная ошибка выборки. Вероятность появления определенной ошибки выборки находят с помощью теорем теории вероятностей. Согласно теореме П. Л. Чебышёва, при достаточно большом объеме выборки и ограниченной дисперсии генеральной совокупности вероятность того, что разность между выборочной средней и генеральной средней будет сколь угодно мала, близка к единице:
А. М. Ляпунов доказал, что независимо от характера распределения генеральной совокупности при увеличении объема выборки распределение вероятностей появления того или иного значения выборочной средней приближается к нормальному распределению. Это так называемая центральная предельная теорема. Следовательно, вероятность отклонения выборочной средней от генеральной средней, т.е. вероятность появления заданной предельной ошибки, также подчиняется указанному закону и может быть найдена как функция от t с помощью интеграла вероятностей Лапласа:
где Значения интеграла Лапласа для разных t рассчитаны и имеются в специальных таблицах, из которых в статистике широко применяется сочетание:
Задавшись конкретным уровнем вероятности, выбирают величину нормированного отклонения t и определяют предельную ошибку выборки по формуле (1.38) При этом чаще всего применяют После исчисления предельной ошибки находят доверительный интервал обобщающей характеристики генеральной совокупности. Такой интервал для генеральной средней величины имеет вид ( адля генеральной доли аналогично (w- Следовательно, при выборочном наблюдении определяется не одно, точное значение обобщающей характеристики генеральной совокупности, а лишь ее доверительный интервал с заданным уровнем вероятности. И это серьезный недостаток выборочного метода статистики. Популярное:
|
Последнее изменение этой страницы: 2016-08-24; Просмотров: 1046; Нарушение авторского права страницы
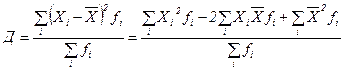 =
= 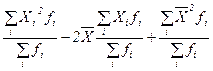 =
= 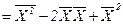 =
= 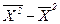
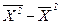 , (1.32)
, (1.32) 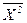 – средняя квадратов статистических величин;
– средняя квадратов статистических величин; 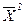 – квадрат их средней величины.
– квадрат их средней величины.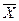 = 4. Тогда дисперсия простая по логической формуле (1.24) будет равна
= 4. Тогда дисперсия простая по логической формуле (1.24) будет равна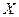 , а во втором — выборочная доля величин, обозначаемая w. В генеральной совокупности соответственно: генеральная средняя
, а во втором — выборочная доля величин, обозначаемая w. В генеральной совокупности соответственно: генеральная средняя 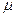 =
= 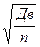 - повторная; (1.35)
- повторная; (1.35) 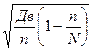 - бесповторная; (1.36)
- бесповторная; (1.36)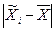 может быть больше, меньше или равна
может быть больше, меньше или равна 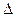 . Она определяется в долях средней ошибки с заданной вероятностью, т.е.
. Она определяется в долях средней ошибки с заданной вероятностью, т.е.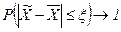 при
при 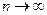 .
.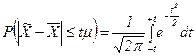 ,
, 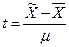 – нормированное отклонение выборочной средней от генеральной средней.
– нормированное отклонение выборочной средней от генеральной средней.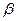 = 0, 95 и t = 1, 96, т.е. считают, что с вероятностью 95% предельная ошибка выборки вдвое больше средней. Поэтому в статистике величина t иногда именуется коэффициентом кратности предельной ошибки относительно средней.
= 0, 95 и t = 1, 96, т.е. считают, что с вероятностью 95% предельная ошибка выборки вдвое больше средней. Поэтому в статистике величина t иногда именуется коэффициентом кратности предельной ошибки относительно средней.