|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Лекционный курс Математика и Информатика - 2
Лекционный курс Математика и Информатика - 2 Содержание лекционного курса Информатика как наука и как вид практической деятельности – 2 часа Информация. Её виды и свойства – 2 часа Передача и кодирование информации – 2 часа История развития вычислительной техники – 2 часа. Архитектура ЭВМ – 2 часа. Персональный компьютер и его устройство – 2 часа. Устройства хранения информации – 2 часа. Внешние устройства ЭВМ: физические принципы и характеристики – 4 часа. Операционные системы – 2 часа. Прикладные программные средства – 2 часа Локальные сети – 2 часа Глобальные сети– 2 часа Компьютерная безопасность и средства защиты информации – 2 часа Базы данных и системы управления базами данных – 2 часа Лекция 6. Информатика как наука и как вид практической деятельности
План
Информатика как единство науки и технологии Информатика – отнюдь не только “чистая наука”. У нее, безусловно, имеется научное ядро, но важная особенность информатики – широчайшие приложения, охватывающие почти все виды человеческой деятельности: производство, управление, науку, образование, проектные разработки, торговлю, финансовую сферу, медицину, криминалистику, охрану окружающей среды и др. И, может быть, главное из них – совершенствование социального управления на основе новых информационных технологий. Как наука, информатика изучает общие закономерности, свойственные информационным процессам (в самом широком смысле этого понятия). Когда разрабатываются новые носители информации, каналы связи, приемы кодирования, визуального отображения информации и многое другое, конкретная природа этой информации почти не имеет значения. Для разработчика системы управления базами данных (СУБД) важны общие принципы организации и эффективность поиска данных, а не то, какие конкретно данные будут затем заложены в базу многочисленными пользователями. Эти общие закономерности есть предмет информатики как науки. Объектом приложений информатики являются самые различные науки и области практической деятельности, для которых она стала непрерывным источником самых современных технологий, называемых часто “новые информационные технологии” (НИТ). Многообразные информационные технологии, функционирующие в разных видах человеческой деятельности (управлении производственным процессом, проектировании, финансовых операциях, образовании и т.п.), имея общие черты, в то же время существенно различаются между собой. Перечислим наиболее впечатляющие реализации информационных технологий, используя, ставшие традиционными, сокращения. АСУ – автоматизированные системы управления – комплекс технических и программных средств, которые во взаимодействии с человеком организуют управление объектами в производстве или общественной сфере. Например, в образовании используются системы АСУ-ВУЗ. АСУТП – автоматизированные системы управления технологическими процессами. Например, такая система управляет работой станка с числовым программным управлением (ЧПУ), процессом запуска космического аппарата и т.д. АСНИ – автоматизированная система научных исследований – программно-аппаратный комплекс, в котором научные приборы сопряжены с компьютером, вводят в него данные измерений автоматически, а компьютер производит обработку этих данных и представление их в наиболее удобной для исследователя форме. АОС – автоматизированная обучающая система. Есть системы, помогающие учащимся осваивать новый материал, производящие контроль знаний, помогающие преподавателям готовить учебные материалы и т.д. САПР-система автоматизированного проектирования – программно-аппаратный комплекс, который во взаимодействии с человеком (конструктором, инженером-проектировщиком, архитектором и т.д.) позволяет максимально эффективно проектировать механизмы, здания, узлы сложных агрегатов и др. Упомянем также диагностические системы в медицине, системы организации продажи билетов, системы ведения бухгалтерско-финансовой деятельности, системы обеспечения редакционно-издательской деятельности – спектр применения информационных технологий чрезвычайно широк. С развитием информатики возникает вопрос о ее взаимосвязи и разграничении с кибернетикой. При этом требуется уточнение предмета кибернетики, более строгое его толкование. Информатика и кибернетика имеют много общего, основанного на концепции управления, но имеют и объективные различия. Один из подходов разграничения информатики и кибернетики – отнесение к области информатики исследований информационных технологий не в любых кибернетических системах (биологических, технических и т.д.), а только в социальных системах. В то время как за кибернетикой сохраняются исследования общих законов движения информации в произвольных системах, информатика, опираясь на этот теоретический фундамент, изучает конкретные способы и приемы переработки, передачи, использования информации. Впрочем, многим современным ученым такое разделение представляется искусственным, и они просто считают кибернетику одной из составных частей информатики. Лекция 7. Информация, ее виды и свойства
План 1. Различные уровни представлений об информации 2. Непрерывная и дискретная информация 3. Единицы количества информации: вероятностный и объемный подходы 4. Информация: более широкий взгляд 5. Свойства информации
Единицы количества информации: вероятностный и объемный подходы Определить понятие “количество информации” довольно сложно. В решении этой проблемы существуют два основных подхода. Исторически они возникли почти одновременно. В конце 40-х годов XX века один из основоположников кибернетики американский математик Клод Шеннон развил вероятностный подход к измерению количества информации, а работы по созданию ЭВМ привели к “объемному” подходу. Вероятностный подход Рассмотрим в качестве примера опыт, связанный с бросанием правильной игральной.кости, имеющей N граней (наиболее распространенным является случай шестигранной кости: N = 6). Результаты данного опыта могут быть следующие: выпадение грани с одним из следующих знаков: 1, 2,... N. Введем в рассмотрение численную величину, измеряющую неопределенность - энтропию (обозначим ее Н). Величины N и Н связаны между собой некоторой функциональной зависимостью: H = f (N), (1.1) а сама функция f является возрастающей, неотрицательной и определенной (в рассматриваемом нами примере) для N = 1, 2,... 6. Рассмотрим процедуру бросания кости более подробно: 1) готовимся бросить кость; исход опыта неизвестен, т.е. имеется некоторая неопределенность; обозначим ее H1; 2) кость брошена; информация об исходе данного опыта получена; обозначим количество этой информации через I; 3) обозначим неопределенность данного опыта после его осуществления через H2. За количество информации, которое получено в ходе осуществления опыта, примем разность неопределенностей “до” и “после” опыта: I = H1 – H2 (1.2) Очевидно, что в случае, когда получен конкретный результат, имевшаяся неопределенность снята (Н2 = 0), и, таким образом, количество полученной информации совпадает с первоначальной энтропией. Иначе говоря, неопределенность, заключенная в опыте, совпадает с информацией об исходе этого опыта. Заметим, что значение Н2 могло быть и не равным нулю, например, в случае, когда в ходе опыта следующей выпала грань со значением, большим “З”. Следующим важным моментом является определение вида функции f в формуле (1.1). Если варьировать число граней N и число бросаний кости (обозначим эту величину через М), общее число исходов (векторов длины М, состоящих из знаков 1, 2,.... N) будет равно N в степени М: X=NM. (1.3) Так, в случае двух бросаний кости с шестью гранями имеем: Х=62=36. Фактически каждый исход Х есть некоторая пара (X1, X2), где X1 и X2 – соответственно исходы первого и второго бросаний (общее число таких пар – X). Ситуацию с бросанием М раз кости можно рассматривать как некую сложную систему, состоящуюиз независимых друг от друга подсистем – “однократных бросаний кости”. Энтропия такой системы в М раз больше, чем энтропия одной системы (так называемый “принцип аддитивности энтропии”): f(6M) = M ∙ f(6) Данную формулу можно распространить и на случай любого N: F(NM) = M ∙ f(N) (1.4) Прологарифмируем левую и правую части формулы (1.3): lnX=M ∙ lnN, М=lnX/1nM. Подставляем полученное для M значение в формулу (1.4):
Обозначив через К положительную константу, получим: f(X) =К ∙ lnХ, или, с учетом (1.1), H=K ∙ ln N. Обычно принимают К = 1 / ln 2. Таким образом H = log2 N. (1.5) Это – формула Хартли. Важным при введение какой-либо величины является вопрос о том, что принимать за единицу ее измерения. Очевидно, Н будет равно единице при N=2. Иначе говоря, в качестве единицы принимается количество информации, связанное с проведением опыта, состоящего в получении одного из двух равновероятных исходов (примером такого опыта может служить бросание монеты при котором возможны два исхода: “орел”, “решка”). Такая единица количества информации называется “бит”. Все N исходов рассмотренного выше опыта являются равновероятными и поэтому можно считать, что на “долю” каждого исхода приходится одна N-я часть общей неопределенности опыта: (log2 N)1N. При этом вероятность i-го исхода Рi равняется, очевидно, 1/N. Таким образом, Та же формула (1.6) принимается за меру энтропии в случае, когда вероятности различных исходов опыта неравновероятны (т.е. Рi могут быть различны). Формула (1.6) называетсяформулой Шеннона. В качестве примера определим количество информации, связанное с появлением каждого символа в сообщениях, записанных на русском языке. Будем считать, что русский алфавит состоит из 33 букв и знака “пробел” для разделения слов. По формуле (1.5) Н = log2 34 ≈ 5 бит. Однако, в словах русского языка (равно как и в словах других языков) различные буквы встречаются неодинаково часто. Ниже приведена табл. 1 вероятностей частоты употребления различных знаков русского алфавита, полученная на основе анализа очень больших по объему текстов. Таблица 1. Частотность букв русского языка
Воспользуемся для подсчета Н формулой (1.6) и получим, что Н ≈ 4, 72 бит. Полученное значение Н, как и можно было предположить, меньше вычисленного ранее. Величина Н, вычисляемая по формуле (1.5), является максимальным количеством информации, которое могло бы приходиться на один знак. Аналогичные подсчеты Н можно провести и для других языков, например, использующих латинский алфавит – английского, немецкого, французского и др. (26 различных букв и “пробел”). По формуле (1.5) получим H = log2 27 ≈ 4, 76 бит. Как и в случае русского языка, частота появления тех или иных знаков не одинакова. Если расположить все буквы данных языков в порядке убывания вероятностей, то получим следующие последовательности: АНГЛИЙСКИЙ ЯЗЫК: “пробел”, E, T, A, O, N, R, … НЕМЕЦКИЙ ЯЗЫК: “пробел”, Е, N, I, S, Т, R, … ФРАНЦУЗСКИЙ ЯЗЫК: “пробел”, Е, S, А, N, I, Т, … Рассмотрим алфавит, состоящий из двух знаков 0 и 1. Если считать, что со знаками 0 и 1 в двоичном алфавите связаны одинаковые вероятности их появления (Р(0)=Р(1)=0, 5), то количество информации на один знак при двоичном кодировании будет равно H = 1оg2 2 = 1 бит. Таким образом, количество информации (в битах), заключенное в двоичном слове, равно числу двоичных знаков в нем. Объемный подход В двоичной системе счисления знаки 0 и 1 будем называть битами (от английского выражения Binary digiTs – двоичные цифры). Отметим, что создатели компьютеров отдают предпочтение именно двоичной системе счисления потому, что в техническом устройстве наиболее просто реализовать два противоположных физических состояния: некоторый физический элемент, имеющий два различных состояния: намагниченность в двух противоположных направлениях; прибор, пропускающий или нет электрический ток; конденсатор, заряженный или незаряженный и т.п. В компьютере бит является наименьшей возможной единицей информации. Объем информации, записанной двоичными знаками в памяти компьютера или на внешнем носителе информации подсчитывается просто по количеству требуемых для такой записи двоичных символов. При этом, в частности, невозможно нецелое число битов (в отличие от вероятностного подхода). Для удобства использования введены и более крупные, чем бит, единицы количества информации. Так, двоичное слово из восьми знаков содержит один, байт информации, 1024 байта образуют килобайт (кбайт), 1024 килобайта – мегабайт (Мбайт), а 1024 мегабайта – гигабайт (Гбайт). Между вероятностным и объемным количеством информации соотношение неоднозначное. Далеко не всякий текст, записанный двоичными символами, допускает измерение объема информации в кибернетическом смысле, но заведомо допускает его в объемном. Далее, если некоторое сообщение допускает измеримость количества информации в обоих смыслах, то они не обязательно совпадают, при этом кибернетическое количество информации не может быть больше объемного. В дальнейшем практически всегда количество информации понимается в объемном смысле. Свойства информации Свойства информации: • запоминаемость; • передаваемость; • преобразуемость; • воспроизводимость; • стираемость. Свойство запоминаемости – одно из самых важных. Запоминаемую информацию будем называть макроскопической (имея ввиду пространственные масштабы запоминающей ячейки и время запоминания). Именно с макроскопической информацией мы имеем дело в реальной практике. Передаваемость информации с помощью каналов связи (в том числе с помехами) хорошо исследована в рамках теории информации К. Шеннона. В данном случае имеется ввиду несколько иной аспект – способность информации к копированию, т.е. к тому, что она может быть “запомнена” другой макроскопической системой и при этом останется тождественной самой себе. Очевидно, что количество информации не должно возрастать при копировании. Воспроизводимость информации тесно связана с ее передаваемостью и не является ее независимым базовым свойством. Если передаваемость означает, что не следует считать существенными пространственные отношения между частями системы, между которыми передается информация, то воспроизводимость характеризует неиссякаемость и неистощимость информации, т.е. что при копировании информация остается тождественной самой себе. Фундаментальное свойство информации – преобразуемость. Оно означает, что информация может менять способ и форму своего существования. Копируемость есть разновидность преобразования информации, при котором ее количество не меняется. В общем случае количество информации в процессах преобразования меняется, но возрастать не может. Свойство стираемости информации также не является независимым. Оно связано с таким преобразованием информации (передачей), при котором ее количество уменьшается и становится равным нулю. Подводя итог сказанному, отметим, что предпринимаются (но отнюдь не завершены) попытки ученых, представляющих самые разные области знания, построить единую теорию, которая призвана формализовать понятие информации и информационного процесса, описать превращения информации в процессах самой разной природы. Движение информации есть сущность процессов управления, которые суть проявление имманентной активности материи, ее способности к самодвижению. С момента возникновения кибернетики управление рассматривается применительно ко всем формам движения материи, а не только к высшим (биологической и социальной). Многие проявления движения в неживых – искусственных (технических) и естественных (природных) – системах также обладают общими признаками управления, хотя их исследуют в химии, физике, механике в энергетической, а не в информационной системе представлений. Информационные аспекты в таких системах составляют предмет новой междисциплинарной науки – синергетики. Высшей формой информации, проявляющейся в управлении в социальных системах, являются знания. Это наддисциплинарное понятие, широко используемое в педагогике и исследованиях по искусственному интеллекту, также претендует на роль важнейшей философской категории. В философском плане познание следует рассматривать как один из функциональных аспектов управления. Такой подход открывает путь к системному пониманию генезиса процессов познания, его основ и перспектив. План 1. Передача информации. Информационные каналы 2. Характеристики информационного канала 3. Абстрактный алфавит 4. Кодирование и декодирование 5. Понятие о теоремах Шеннона 6. Международные системы байтового кодирования 7. Кодирование информации 7.1. Двоичное кодирование текстовой информации 7.2. Кодирование графической информации 7.2.1. Кодирование растровых изображений 7.2.2. Кодирование векторных изображений. 7.3. Двоичное кодирование звука
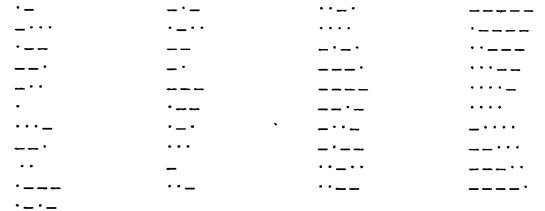
Абстрактный алфавит Информация передается в виде сообщений. Дискретная информация записывается с помощью некоторого конечного набора знаков, которые будем называть буквами, не вкладывая в это слово привычного ограниченного значения (типа “русские буквы” или “латинские буквы”). Буква в данном расширенном понимании – любой из знаков, которые некоторым соглашением установлены для общения. Например, при привычной передаче сообщений на русском языке такими знаками будут русские буквы – прописные и строчные, знаки препинания, пробел; если в тексте есть числа – то и цифры. Вообще, буквой будем называть элемент некоторого конечного множества (набора) отличных друг от друга знаков. Множество знаков, в котором определен их порядок, назовем алфавитом (общеизвестен порядок знаков в русском алфавите: А, Б,..., Я). Рассмотрим некоторые примеры алфавитов. 1, Алфавит прописных русских букв: А Б В Г Д Е Е Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я 2. Алфавит Морзе:
3. Алфавит клавиатурных символов ПЭВМ IBM (русифицированная клавиатура):
4. Алфавит знаков правильной шестигранной игральной кости:
5. Алфавит арабских цифр: 6. Алфавит шестнадцатиричных цифр: 0 1 2 3 4 5 6 7 8 9 A B C D E F Этот пример, в частности, показывает, что знаки одного алфавита могут образовываться из знаков других алфавитов. 7. Алфавит двоичных цифр: 0 1 Алфавит 7 является одним из примеров, так называемых, “двоичных” алфавитов, т.е. алфавитов, состоящих из двух знаков. Другими примерами являются двоичные алфавиты 8 и 9: 8. Двоичный алфавит “точка, “тире”:. _ 9. Двоичный алфавит “плюс”, “минус”: + - 10. Алфавит прописных латинских букв: A B C D E F G H I J K L M N O P Q R S T U V W X Y Z 11. Алфавит римской системы счисления: I V Х L С D М 12. Алфавит языка блок-схем изображения алгоритмов:
Кодирование и декодирование В канале связи сообщение, составленное из символов (букв) одного алфавита, может преобразовываться в сообщение из символов (букв) другого алфавита. Правило, описывающее однозначное соответствие букв алфавитов при таком преобразовании, называют кодом. Саму процедуру преобразования сообщения называют перекодировкой. Подобное преобразование сообщения может осуществляться в момент поступления сообщения от источника в канал связи (кодирование) и в момент приема сообщения получателем (декодирование). Устройства, обеспечивающие кодирование и декодирование, будем называть соответственно кодировщиком и декодировщиком. На рис. 3 приведена схема, иллюстрирующая процесс передачи сообщения в случае перекодировки, а также воздействия помех (см. следующий пункт).
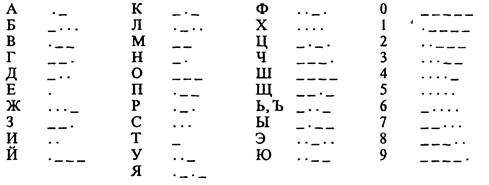
Рис. 3. Процесс передачи сообщения от источника к приемнику Рассмотрим некоторые примеры кодов. 1. Азбука Морзе в русском варианте (алфавиту, составленному из алфавита русских заглавных букв и алфавита арабских цифр ставится в соответствие алфавит Морзе):
2. Код Трисиме (знакам латинского алфавита ставятся в соответствие комбинации из трех знаков: 1, 2, 3):
Код Трисиме является примером, так называемого, равномерного кода (такого, в котором все кодовые комбинации содержат одинаковое число знаков – в данном случае три). Пример неравномерного кода – азбука Морзе. 3. Кодирование чисел знаками различных систем счисления см. лекцию 3. Понятие о теоремах Шеннона Теоремы Шеннона затрагивают проблему эффективного кодирования Первая теорема декларирует возможность создания системы эффективного кодирования дискретных сообщений, у которой среднее число двоичных символов на один символ сообщения асимптотически стремится к энтропии источника сообщений (в отсутствии помех). Вторая теорема Шеннона гласит, что при наличии помех в канале всегда можно найти такую систему кодирования, при которой сообщения будут переданы с заданной достоверностью. Подробнее> > Таблица 2. Таблица кодов ASCII (расширенная)
Одним из достоинств этой системы кодировки русских букв является их естественное упорядочение, т.е. номера букв следуют друг за другом в том же порядке, в каком сами буквы стоят в русском алфавите. Это очень существенно при решении ряда задач обработки текстов, когда требуется выполнить или использовать лексикографическое упорядочение слов. Из сказанного выше следует, что даже 8-битная кодировка недостаточна для кодирования всех символов, которые хотелось бы иметь в расширенном алфавите. Все препятствия могут быть сняты при переходе на 16-битную кодировку Unicode, допускающую 65536 кодовых комбинаций. Кодирование информации Двоичное кодирование звука Развитие способов кодирования звуковой информации, а также движущихся изображений – анимации и видеозаписей – происходило с запаздыванием относительно рассмотренных выше разновидностей информации. Заметим, что под анимацией понимается похожее на мультипликацию “оживление” изображений, но выполняемое с помощь средств компьютерной графики. Анимация представляет собой последовательность незначительно отличающихся друг от друга, полученных с помощью компьютера картинок, которые фиксируют близкие по времени состояния движения какого-либо объекта или группы объектов. Приемлемые способы хранения и воспроизведения с помощью компьютера звуковых и видеозаписей появились только в девяностых годах двадцатого века. Эти способы работы со звуком и видео получили название мультимедийных технологий. Звук представляет собой достаточно сложное непрерывное колебание воздуха. Оказывается, что такие непрерывные сигналы можно с достаточной точностью представлять в виде суммы некоторого числа простейших синусоидальных колебаний. Причем каждое слагаемое, то есть каждая синусоида, может быть точно задана некоторым набором числовых параметров – амплитуды, фазы и частоты, которые можно рассматривать как код звука в некоторый момент времени. Такой подход к записи звука называется преобразованием в цифровую форму, оцифровыванием или дискретизацией, так как непрерывный звуковой сигнал заменяется дискретным (то есть состоящим из раздельных элементов) набором значений сигнала в некоторые моменты времени. Количество отсчетов сигнала в единицу времени называется частотой дискретизации. В настоящее время при записи звука в мультимедийных технологиях применяются частоты 8, 11, 22 и 44 кГц. Так, частота дискретизации 44 килогерца означает, что одна секунда непрерывного звучания заменяется набором из сорока четырех тысяч отдельных отсчетов сигнала. Чем выше частота дискретизации, тем лучше качество оцифрованного звука. Как отмечалось выше, каждый отдельный отсчет можно описать некоторой совокупностью чисел, которые затем можно представить в виде некоторого двоичного кода. Качество преобразования звука в цифровую форму определяется не только частотой дискретизации, но и количеством битов памяти, отводимых на запись кода одного отсчета. Этот параметр принято называть разрядностью преобразования. В настоящее время обычно используется разрядность 8, 16 и 24 бит. На описанных выше принципах основывается формат WAV (от WAVeform-audio – волновая форма аудио) кодирования звука. Получить запись звука в этом формате можно от подключаемых к компьютеру микрофона, проигрывателя, магнитофона, телевизора и других стандартно используемых устройств работы со звуком. Однако формат WAV требует очень много памяти. Так, при записи стереофонического звука с частотой дискретизации 44 килогерца и разрядностью 16 бит – параметрами, дающими хорошее качество звучания, – на одну минуту записи требуется около десяти миллионов байтов памяти. Кроме волнового формата WAV, для записи звука широко применяется формат с названием MIDI (Musical Instruments Digital Interface – цифровой интерфейс музыкальных инструментов). Фактически этот формат представляет собой набор инструкций, команд так называемого музыкального синтезатора – устройства, которое имитирует звучание реальных музыкальных инструментов. Команды синтезатора фактически являются указаниями на высоту ноты, длительность ее звучания, тип имитируемого музыкального инструмента и т. д. Таким образом, последовательность команд синтезатора представляет собой нечто вроде нотной записи музыкальной мелодии. Получить запись звука в формате MIDI можно только от специальных электромузыкальных инструментов, которые поддерживают интерфейс MIDI. Формат MIDI обеспечивает высокое качество звука и требует значительно меньше памяти, чем формат WAV. Кодирование видеоинформации еще более сложная проблема, чем кодирование звуковой информации, так как нужно позаботиться не только о дискретизации непрерывных движений, но и о синхронизации изображения со звуковым сопровождением. В настоящее время для этого используется формат, которой называется AVI (Audio-Video Interleaved – чередующееся аудио и видео). Основные мультимедийные форматы AVI и WAV очень требовательны к памяти. Поэтому на практике применяются различные способы компрессии, то есть сжатия звуковых и видео- кодов. В настоящее время стандартными стали способы сжатия, предложенные MPEG (Moving Pictures Experts Group – группа экспертов по движущимся изображениям). В частности, стандарт MPEG описывает несколько популярных в настоящее время форматов записи звука. Так, например, при записи в формате МР3 при практически том же качестве звука требуется в десять раз меньше памяти, чем при использовании формата WAV. Существуют специальные программы, которые преобразуют записи звука из формата WAV в формат МР3. Совсем недавно был разработан стандарт MPEG-4, применение которого позволяет записать полнометражный цветной фильм со звуковым сопровождением на компакт-диск обычных размеров и качества. Перед завершением обсуждения общих принципов кодирования информации хотелось бы обратить внимание на один важный момент. Возьмем какой-либо двоичный код, например 1000 1100(2). Если обратиться к приведенному выше фрагменту кодовой таблицы, то можно утверждать, что это код буквы “М”. С другой стороны, можно сказать, что этим кодом задается цвет одного из пикселов монохромного изображения. Наконец, если воспользоваться правилами перевода из двоичной системы в десятичную, то можно утверждать, что это код числа +14010 (в другой интерпретации это код числа –12010). Что же это на самом деле? Интерпретация, то есть истолкование смысла одного и того же машинного кода, может быть самой разной. Один и тот же код разными программами может рассматриваться и как число, и как текст, и как изображение, и как звук. Другими словами, как именно трактуется тот или иной машинный код, определяется обрабатывающей этот код программой. План
Поколения ЭВМ В истории вычислительной техники существует своеобразная периодизация ЭВМ по поколениям. В ее основу первоначально был положен физико-технологический принцип: машину относят к тому или иному поколению в зависимости от используемых в ней физических элементов или технологии их изготовления. Границы поколений во времени размыты, так как в одно и то же время выпускались машины совершенно разного уровня. Когда приводят даты, относящиеся к поколениям, то скорее всего имеют в виду период промышленного производства; проектирование велось существенно раньше, а встретить в эксплуатации весьма экзотические устройства можно и сегодня. В настоящее время физико-технологический принцип не является единственным при определении принадлежности той или иной ЭВМ к поколению. Следует считаться и с уровнем программного обеспечения, с быстродействием, другими факторами, основные из которых сведены в прилагаемую табл. 1. Следует понимать, что разделение ЭВМ по поколениям весьма относительно. Первые ЭВМ, выпускавшиеся до начала 50-х годов, были “штучными” изделиями, на которых отрабатывались основные принципы; нет особых оснований относить их к какому-либо поколению. Нет единодушия и при определении признаков пятого поколения. В середине 80-х годов считалось, что основной признак этого (будущего) поколения – полновесная реализация принципов искусственного интеллекта. Эта задача оказалась значительно сложнее, чем виделось в то время, и ряд специалистов снижают планку требований к этому этапу (и даже утверждают, что он уже состоялся). В истории науки есть аналоги этого явления: так, после успешного запуска первых атомных электростанций в середине 50-х годов ученые объявили, что запуск многократно более мощных, дающих дешевую энергию, экологически безопасных термоядерных станций, вот-вот произойдет; однако, они недооценили гигантские трудности на этом пути, так как термоядерных электростанций нет и по сей день. В то же время среди машин четвертого поколения разница чрезвычайно велика, и поэтому в табл. 1 соответствующая колонка разделена на две: А и Б. Указанные в верхней строчке даты соответствуют первым годам выпуска ЭВМ. Здесь ограничимся кратким комментарием. Таблица 1. Поколения ЭВМ
Чем младше поколение, тем отчетливее классификационные признаки. ЭВМ первого, второго и третьего поколений сегодня, в конце 90-х годов – в лучшем случае музейные экспонаты. Машина первого поколения – десятки стоек, каждая размером с большой книжный шкаф, наполненных электронными лампами, лентопротяжными устройствами, громоздкие печатающие агрегаты, и все это на площади сотни квадратных метров, со специальными системами охлаждения, источниками питания, постоянно гудящее и вибрирующее (почти как в цехе машиностроительного завода). Обслуживание – ежечасное. Часто выходящие из строя узлы, перегорающие лампы, и вместе с тем невиданные, волшебные возможности для тех, кто, например, занят математическим моделированием. Быстродействие до 1000 операций/с и память на 1000 чисел делало доступным решение задач, к которым раньше нельзя было и подступиться. Популярное:
|
Последнее изменение этой страницы: 2016-09-01; Просмотров: 533; Нарушение авторского права страницы
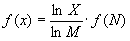
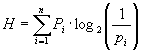 (1.6)
(1.6)