
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ НЕПРЕРЫВНОГО ТИПА.
Если возможные значения случайной величины сплошь заполняют некоторый промежуток < a, b> Ì R (быть может, и всюось), то табличный способ задания случайной величины непригоден. Такая случайная величина называется случайной величиной непрерывного типа. Ее функция распределения F(x) будет непрерывна. Напомним, что F(- ¥ ) = 0, F(+ ¥ ) = 1, F(x) - монотонная неубывающая функция. Производная такой функции F(x) будет функцией неотрицательной. Она называется плотностью распределения вероятностей или дифференциальной функцией распределения вероятностей. Ее обозначение Часто по условию задачи задают именно плотность распределения, зная которую можно вычислить и (интегральную) функцию распределения ( по формуле Ньютона - Лейбница ): F(x) = F(x) - F(- ¥ ) = Заметим, что f(x) - не обязательно непрерывная функция, она допускает в отдельных точках разрывы 1-го рода. Итак, f(x) - неотрицательная кусочно-непрерывная функция, причем, согласно одному из свойств F(x), F(+ ¥ ) = Последнее равенство, называемое условием нормировки f(x), показывает, что f(x) - не любая неотрицательная функция: площадь между графиком плотности распределения и осью абсцисс должна быть равна 1.(Для дискретной случайной величины условием нормировки являлось равенство Для непрерывных случайных величин справедливы равенства F(b) - F(a) = P(a £ X < b) = P(a < X < b) = P(a < X £ b) = = P(a £ X £ b) = М(Х) и D(X) определяются формулами M(X) = Вычислительная формула для D(X): D(X) = M(X2) - (M(X))2 =
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ХАРАКТЕРИСТИКИ
Нормальный (гауссовский) закон распределения задается плотностью распределения по формуле
Числа а Î R и s > 0 называются параметрами нормального закона. Нормальный закон с такими параметрами обозначается N(a, s). При а = 0 функция f(x) четная ( f(-x) = f(x) ), ее график симметричен относительно оси OY, и поэтому среднее значение М(Х) = 0. График f(x) для закона N(a, s) получается из графика f(x) для N(0, s) сдвигом на а единиц вправо ( это известно из курса средней школы ), поэтому в общем случае М(Х) = а для нормального закона. Дисперсия же вычисляется по формуле D(X) =s2.
Пример. Случайная величина Х распределена по нормальному закону с плотностью вероятности
Найти А, М (Х), D(X), P(-3< X< 3). Т. к. Показатель экспоненты
P (-3 < X < 3) = F(3) - F(-3) = = Этот интеграл не вычисляется в элементарных функциях, его численное значение можно найти по таблицам. В большинстве учебников имеются таблицы для вычисления функций Ф(х) =
Ф(х) - нечетная функция, т.е. Ф(-х) = - Ф(х). В общем случае Р(x1 < X < x2) = где а и s - параметры нормального закона. Следовательно, для данного примера P(|X| < 3) = Ф1(1) - Ф1(-5) = Ф(1) - Ф(-5) = Ф(1) + Ф(5) = = 0, 3413 + 0, 5 = 0, 8413.
ДРУГИЕ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ НЕПРЕРЫВНЫХ СЛУЧАЙНЫХ ВЕЛИЧИН
Кроме нормального закона есть и другие случайные величины, часто встречающиеся в приложениях. Приведем некоторые из них. Для равномерного закона плотность вероятности и функция распределения задаются формулами
а числовые характеристики М(Х)=
Для показательного закона плотность вероятности и функция распределения задаются формулами
а числовые характеристики М(Х)= 1/a, D(X)= 1/a2. Эти формулы можно использовать при решении задач.
МЕТОДИЧЕСКИЕ УКАЗАНИЯ К ВЫПОЛНЕНИЮ ЗАДАНИЯ № 5 Математическая статиcтика изучает массовые явления и процессы, ставя целью получение выводов по данным наблюдений за ними. В результате появляются утверждения об общих характеристиках таких явлений в предположении постоянства начальных условий явления. Теоретической основой математической статистики является теория вероятностей. Поскольку число наблюдений конечно, их результаты можно записать в таблицу аналогично дискретной случайной величине, только в нижней строке не вероятности, а частоты тех или иных значений, а чаще – диапазонов. При этом при анализе такой таблицы нередко возникает предположение, что данная величина распределена по одному из известных непрерывных законов (см. комментарии к задаче № 4), чаще всего – нормальному (гауссовскому).
Типовой пример
Получены статистические данные (N=500) зависимости результатов измерения роста студентов (Х) от окружности груди (Y). Измерения проводились с точностью до 1 см.
Таблица 1 Статистические данные типового примера
…………..
Требуется: 1 часть. 1) произвести выборку из 200 значений; 2) построить эмпирическую функцию распределения, полигон, гистограмму для случайной величины Х; 3) построить точечные и интервальные оценки для мат. ожидания и дисперсии генеральной совокупности Х; 4) сделать статистическую проверку гипотезы о законе распределения случайной величины Х; часть 2. 1) нанести на координатную плоскость данные выборки (x; y) и по виду корреляционного облака подобрать вид функции регрессии; 2) составить корреляционную таблицу по сгруппированным данным; 3) вычислить коэффициент корреляции; 4) получить уравнение регрессии;
Решение. 1) Произведём из генеральной совокупности N=500 выборку n=200 значений. Для этого воспользуемся таблицей случайных чисел (Приложение А). Выберите столбец, номер которого соответствует месяцу Вашего рождения. В этом столбце отсчитайте порядковый номер даты дня рождения. В полученном случайном числе определите номера ещё трёх столбцов. Для данного примера выбрана дата 31 декабря. В 12 столбце определили 31 номер случайного числа. Это число 0436. Значит выбранными будут столбцы №12; 4; 13; 16. (№12 – месяц Вашего рождения, №4 – первая или вторая цифра в случайном числе, которая не использовалась, №13 – третья цифра в случайном числе +10, №16 – четвёртая цифра в случайном числе +10). Если цифры повторяются, то нужно взять со3седние номера. Например, случайное число во втором столбце - 4422. Нужно выбрать номера 2, 4, 12, 13. Для осуществления выборки берутся последние три цифры в случайном числе, которые определяют порядковый номер выборочного значения. Если в выборке встретился номер, которого нет в генеральной совокупности, то необходимо вычислить разность между этим числом и 500. Если полученный номер уже выбрали, то необходимо выбрать следующий за ним номер. Для представленного примера получилась выборка:
Таблица 2 Выборочные данные X и Y
Продолжение таблицы 2
Составим ранжированный (по увеличению) ряд для случайной величины Х. Таблица 3 Ранжированный ряд случайной величины Х
Окончание таблицы 3
Cоставим новую таблицу, в которой отразим частоты появления случайных величин Таблица 4 Дискретный вариационный ряд
В данном примере случайные величины сплошь заполняют промежуток (148; 190). Число возможных значений велико. Их нельзя представить в виде случайных величин, принимающих отдельные, изолированные значения, тем самым отделить одно возможное значение от другого промежутком, не содержащим возможных значений случайной величины. Поэтому для построения вариационного ряда будем использовать интервальный ряд распределения. Весь возможный интервал варьирования разобьём на конечное число интервалов и подсчитаем частоту попадания значений величины в каждый интервал. Минимальное и максимальное значения случайной величины:
При этом значение признака, находящегося на границе интервалов относят к правой границе интервала. На практике считают, что правильно составленный ряд распределения содержит от 6 до 15 частичных интервалов. Часто интервальный вариационный ряд заменяют дискретным вариационным рядом, выбирая средние значения интервала (таблица №7). Для данного примера Таблица 5 Популярное:
|
Последнее изменение этой страницы: 2016-09-01; Просмотров: 693; Нарушение авторского права страницы
 .
.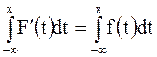
 = 1
= 1 ).
). .
. , D(X) =
, D(X) =  .
. - (M(X))2.
- (M(X))2. , - ¥ < x < +¥
, - ¥ < x < +¥ 
 , то
, то 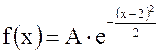
 приравняем к
приравняем к  , откуда а = 2, s = 1. Числовой коэффициент
, откуда а = 2, s = 1. Числовой коэффициент  должен быть равен А, следовательно,
должен быть равен А, следовательно,  , M (X) = a = 2, D(X) = s 2 = 1.
, M (X) = a = 2, D(X) = s 2 = 1.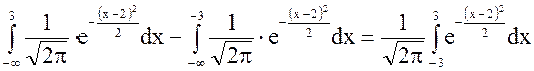
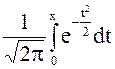 или Ф1(х) =
или Ф1(х) =  =
=  + Ф(х)
+ Ф(х)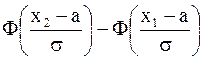 ,
,  ,
,  ,
, 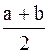 , D(X)=
, D(X)=  .
. ,
, 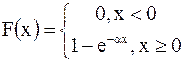 ,
,  и относительные частоты
и относительные частоты  .
.





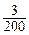



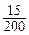




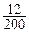


 Тогда интервал варьирования R («размах») будет равен R=
Тогда интервал варьирования R («размах») будет равен R=  Длину интервала рассчитывают по формуле:
Длину интервала рассчитывают по формуле:  (6)
(6)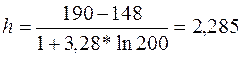 , округлим до 3, т.е. размер интервала h=3, а число интервалов будет равно 14. Соответствующий интервальный вариационный ряд приведён в таблице №5.
, округлим до 3, т.е. размер интервала h=3, а число интервалов будет равно 14. Соответствующий интервальный вариационный ряд приведён в таблице №5.