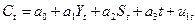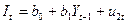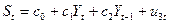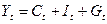|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
МЕТОДИЧЕСКИЕ УКАЗАНИЯ К РЕШЕНИЮ КОНТРОЛЬНЫХ ЗАДАНИЙ
Задача 1 составлена по теме «Однофакторная линейная регрессионная модель» и предполагает построение и анализ уравнения парной линейной регрессии. Для выполнения задачи изучите следующий материал []. Различают два типа взаимосвязей между экономическими переменными: функциональную (или жестко детерминированную) и статистическую (или стохастически детерминированную). Функциональная связь — это вид причинной зависимости, при которой определенному значению факторного признака соответствует вполне определенное значение результативного признака. Стохастическая (статистическая) связь — это вид причинной зависимости, проявляющейся не в каждом отдельном случае, а в общем, в среднем, при большом числе наблюдений, когда каждому значению одной переменной соответствует множество возможных значений другой переменной. Иначе говоря, каждому значению одной переменной соответствует определенное (условное) распределение другой переменной. Корреляционная связь — это зависимость среднего значения результативного признака от изменения факторного признака; в то время как каждому отдельному значению факторного признака Х может соответствовать множество различных значений результативного (Y). Задачами корреляционного анализа являются: 1) изучение степени тесноты связи двух и более явлений; 2) отбор факторов, оказывающих наиболее существенное влияние на результативный признак; 3) выявление неизвестных причинных связей. Исследование корреляционных зависимостей включает ряд этапов: 1) предварительный анализ свойств совокупности; 2) установление факта наличия связи, определение ее направления и формы; 3) измерение степени тесноты связи между признаками; 4) построение регрессионной модели, т. е. нахождение аналитического выражения связи; 5) оценка адекватности модели, ее экономическая интерпретация ипрактическое использование. Цель регрессионного анализа — установить конкретную аналитическую зависимость результативных показателей от одного или нескольких признаков-факторов. Полученное при этом уравнение регрессии используется для содержательного описания изучаемого процесса, прогнозирования, выбора оптимального варианта и т. д. Если в уравнение регрессии включены признаки-факторы, учитывающие и возможное случайное поведение результативного признака, то такое выражение представляет регрессионную модель явления или процесса. Наибольшее применение получили уравнения регрессии, отражающие взаимосвязь одного результативного признака с одним (парная регрессия) или несколькими (множественная регрессия) признаками-факторами. Для того чтобы приступить к выполнению 1 задачи, определите причинную зависимость результативного признака (его вариации) от вариации факторного признак, т.е. определите, какой из данных показателей является фактором, а какой результатом. Например.Расходы на питание — это переменная Данные выборки. Табл. 1
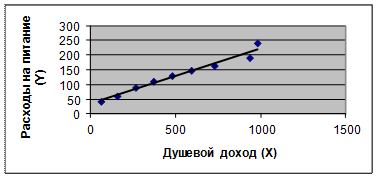
Пункт 1 первой задачисвязан с использованием графического метода. Этот метод используется для наглядного изображения формы связи между изучаемыми признаками. Для этого в прямоугольных осях координат строят график, Каждая точка на графике – это пара значений из выборки (Х, Y), по оси ординат которого откладывают индивидуальные значения результативного признака Y, а по оси абсцисс - индивидуальные значения факторного признака X. Совокупность точек называется полем корреляции (рис. 1).
Рис. 1. Поле корреляции Таким образом выполнено задание: Постройте поле корреляции и сделайте выводы о направлении и характере связи, выявите форму воздействия фактора X на результат Y.
В Пункте 2 необходимо определить неизвестные параметры уравнения регрессии и дать им экономическую интерпретацию. В модели парной линейной регрессии зависимость между переменными
где Когда вид функции известен, то для решения задачи используют МНК (метод наименьших квадратов), который заключается в следующем. Рассмотрим задачу нахождения оценок неизвестных параметров Если исследуемые переменные
где В соответствии с МНК определяем такие значения параметров
В дальнейшем индексы суммирования в целях упрощения обозначений будем опускать. На основании необходимого условия экстремума функции двух переменных, приравниваем к нулю ее частные производные:
После преобразования получим систему нормальных уравнений для определения оценок неизвестных параметров линейной регрессии:
Разделив обе части системы (1.3) на
где соответствующие средние (means) определяются по формулам
Подставляя значение
где Оценку функции регрессии (эмпирическую регрессию, выборочную регрессию, уравнение прямой регрессии
Линия регрессии всегда проходит через точку Постоянная
Суммирование ведется по n наблюдениям. В примере n=9. Решая данную систему уравнений, найдите неизвестные параметры линейного уравнения регрессии и дайте им необходимую интерпретацию. Расчет производных величин для определения параметров уравнения a и b, а также коэффициента корреляции проведем в таблице следующего вида:
Для определения оценок параметров a и b по известным выборочным данным расчетная таблица с результатами будет выглядеть так:
Используя данные таблицы, получим решение системы (3)
Параметрам линейной регрессии можно придать экономический смысл. Выполним экономическую интерпретацию параметров уравнения, а также уравнения в целом: a) Коэффициент в) Коэффициент с) Связь между у и х определяет знак коэффициента регрессии d) Подставив в уравнение регрессии соответствующие значения х из выборки, можно определить выровненные (теоретические) значения результативного показателя для каждого наблюдения Результаты необходимо оформить в виде таблицы:
Необходимо также построить график полученного уравнения регрессии:
Рис.2.
Далее нужно рассчитать показатель тесноты связи. Таким показателем является линейный коэффициент корреляции Линейный коэффициент корреляции принимает значения от –1 до +1. Если
Таким образом, связь между расходами на питание и душевым доходом очень тесная. Интерпретируйте полученное значение коэффициента корреляции. Увяжите этот результат с выводами, сделанными в пунктах 1 и 2. Замечание: Коэффициент корреляции можно использовать для нахождения неизвестных параметров регрессии.
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака. R2= Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах. Например, R2=0.8 означает, что доля вариации результата, объясненная вариацией фактора X, включенного в уравнение регрессии, равна 80%. Остальные 20% приходятся на долю прочих факторов, не учтенных в уравнении регрессии. В нашем примере R2=0, 97. Это означает, что фактором душевого дохода можно объяснить почти 97% изменения расходов на питание. Остальные 3% изменения расходов на питание объясняются факторами, не учтенными в модели. Оценки параметров модели (коэффициенты регрессии) (в примере 0н показывает, на сколько процентов изменяется результативный признак у при изменении факторного признака х на 1%. Он не учитывает степень колеблемости факторов. В примере, а=0, 1257, среднее значение х Бета – коэффициент показывает, на какую часть величины своего среднего квадратичного отклонения изменится в среднем значение результативного признака при изменении факторного признака на величину его среднеквадратического отклонения: β =
Пункты 3 и 4, связаны с темой «Проверка статистических гипотез». Рекомендуется использовать следующую общую процедуру проверки гипотез: 1. Выдвинете нулевую гипотезу H0 о том, что коэффициент регрессии статистически незначим; H0: a = 0. 2. Определите фактическое значение соответствующего критерия. 3. Сравните полученное фактическое значение с табличным (критическим). 4. Если фактическое значение используемого критерия превышает табличное, нулевая гипотеза отклоняется и с вероятностью (1 - α ) принимается альтернативная гипотеза о статистической значимости коэффициента регрессии или уравнения в целом. Если фактическое значение t — критерия меньше табличного, то говорят, что нет оснований отклонить ноль-гипотезу. Для парной линейной регрессии оценка статистической значимости коэффициента b производится по следующему алгоритму: 1. Выдвигается нулевая гипотеза о том, что коэффициент регрессии статистически незначим: H0: b=0. 2. Определяется фактическое значение t-критерия для коэффициента регрессии по формуле Процедура оценивания существенности параметра а не отличается от рассмотренной для коэффициента регрессии b: 3. Табличное значение определяется по таблицам распределения Стьюдента (таблица 3) для заданного уровня значимости a, принимая во внимание, что число степеней свободы для распределения Стьюдента равно (n-m). 4. Если фактическое значение t-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу. В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-a) принимается альтернативная гипотеза о статистической значимости коэффициента уравнения. В рассматриваемом примере S(b)= и tфакт.> tкрит., где tкрит.=2, 36. Значит, параметр b существенно отличен от нуля и зависимость является достоверной.
Проверка значимости модели регрессии. Вопрос о том, отличается ли Значение
где
Если m – число факторов в модели. В рассматриваемом примере Fфакт.=
Экономическое прогнозирование Под прогнозированиемв эконометрике понимается построение оценки будущего значения зависимой переменной Задача прогнозирования разрешима в рамках следующей модели наблюдений:
При этом предполагается, что результаты наблюдений Различают точечное и интервальное прогнозирование. В первом случае прогноз – некоторое число, во втором – интервал, в котором находится прогнозируемая величина с заданным уровнем надежности. Точечный прогноз индивидуального и среднего значений зависимой переменной определяется статистикой
Интервальный прогноз среднего и индивидуального значений зависимой переменной определяется неравенствами:
где
Продолжим рассмотрение нашего примера. С доверительной вероятностью 0, 95 постройте доверительный интервал ожидаемого значения результативного признака, если факторный признак увеличится на 5% от своего среднего значения. Построим точечный прогноз Задача 2 составлена по теме «Классическая обобщенная линейная модель множественной регрессии» и предполагает построение и анализ двухфакторного уравнения линейной регрессии вида: Расчет параметров такого уравнения множественной регрессии (пункт 1) осуществляется обычным МНК c помощью Пакета анализа MS Excel. Поясните экономический смысл коэффициентов регрессии Пункты 2, 3 и 4 связаны с расчетом и анализом относительных показателей силы связи в уравнении множественной регрессии – частных коэффициентов эластичности и стандартизованных коэффициентов регрессии. Пункт 6 предполагает ознакомление с методикой дисперсионного анализа по модели множественной регрессии. Задача 3 составлена по теме «Системы эконометрических уравнений». Для ее выполнения необходимо ознакомиться со следующими понятиями: Система одновременных уравнений — это система эконометрических уравнений (эконометрическая модель), содержащая взаимозависимые переменные, которые включены в одно из уравнений модели в качестве результативного признака, а в другие уравнения - в качестве факторного признака. Примером системы одновременных уравнений может служить следующая гипотетическая модель:
где Эндогенные переменные — это взаимозависимые переменные, которые определяются внутри модели (системы). Как правило, каждое уравнение модели определяет одну эндогенную переменную, стоящую в левой части уравнения. Таким образом, число уравнений в системе равно числу эндогенных переменных. Экзогенные переменные — это независимые переменные, которые определяются вне системы. В приведенной выше системе одновременных уравнений Предопределенные переменные — это экзогенные и лаговые (за предшествующие промежутки или моменты времени) эндогенные переменные системы. Структурная форма модели — это система уравнений, отражающая взаимосвязь между переменными в соответствии с положениями экономической теории и характеризующая структуру экономики или ее сектора. Параметры структурной формы модели называют структурными параметрами (в приведенной выше системе это параметры Приведенная форма модели — это система уравнений, в которой каждая эндогенная переменная есть линейная функция от всех предопределенных переменных модели. Структурные параметры системы одновременных уравнений нельзя определить обычным МНК, так как правая часть системы одновременных уравнений содержит эндогенные переменные В этом случае была бы нарушена предпосылка о причинно-следственной зависимости между факторным и результативным признаками, а также ряд других предпосылок обычного МНК. Наиболее распространенными методами расчета структурных параметров системы одновременных уравнений являются косвенный и двухшаговый методы наименьших квадратов Косвенный МНК состоит в следующем: (а) Составляют приведенную форму модели и определяют численные значения параметров каждого ее уравнения обычным МНК. (б) Путем алгебраических преобразований переходят от приведенной формы к уравнениям структурной формы модели, получая тем самым численные опенки структурных параметров. Двухшаговый МНК состоит в следующем: (а) Составляют приведенную форму модели и определяют численныезначения ее параметров обычным МНК. (б) Выявляют эндогенные переменные, находящиеся в правой части структурного уравнения, параметры которого определяют двухшаговым МНК, и находят их расчетные значения по соответствующим уравнениям приведенной формы модели. (в) Обычным МНК определяют параметры структурного уравнения, используя в качестве исходных данных фактические значения предопределенных переменных и расчетные значения эндогенных переменных, стоящих в правой части данного структурного уравнения. Возможность применения косвенного или двухшагового МНК для оценки структурных параметров уравнения модели зависит от того, можно ли однозначно выразить структурные параметры через приведенные коэффициенты модели. Данную проблему называют проблемой идентификации. Если структурные параметры уравнения модели однозначно определяются по приведенным коэффициентам, то говорят, что данное уравнение точно идентифицировано. Структурные параметры такого уравнения можно найти косвенным МНК. Если из приведенной формы модели можно получить несколько оценок структурных параметров, то говорят, что уравнение сверхидентифицировано. Структурные параметры такого уравнения определяются двухшаговым МНК. Если структурные параметры уравнения модели нельзя найти через приведенные коэффициенты, то такое структурное уравнение называется сверхидентифицируемым, и численные оценки его найти нельзя. Чтобы определить, идентифицировано ли структурное уравнение модели, применяют так называемое порядковое условие идентификации. Для этого по каждому уравнению и модели в целом подсчитывают: K — число предопределенных переменных модели; k — число предопределенных переменных в каждом уравнении; m — число эндогенных переменных в каждом уравнении. Далее для каждого уравнения в отдельности проверяют следующее соотношение: K - k * m - 1. Если это соотношение имеет знак больше ( K - k > m - 1 ), то уравнение сверхидентифицировано. Если это соотношение имеет знак равно ( K - k = m - 1 ), то уравнение точно идентифицировано. Если это соотношение имеет знак меньше ( K - k < m - 1 ), то уравнение неидентифицировано. Примете во внимание, что нет необходимости исследовать на идентификацию тождества модели, поскольку их структурные параметры известны и равны 1. Однако переменные, входящие в тождества, учитываются при подсчете числа эндогенных и предопределенных переменных модели. Пример. Пусть имеется следующая эконометрическая модель: Функция потребление: Функция инвестиций: Функция заработной платы: Тождество дохода: где Ct- расходы на конечное потребление в период t; Yt, Yt-1 — совокупный доход в периоды t, t-1 соответственно; It—валовые инвестиции периода t; St — расход на зарплату в период t; Gt— государственные расходы в году t; u1, u2, u3 — случайные ошибки. Данная модель представляет собой систему одновременных уравнений, так как она содержит взаимозависимые переменные. Проверим выполнение порядкового условия идентификации для каждого уравнения модели пункт 1 задачи 3. В модели 4 эндогенных переменных, находящиеся в левой части каждого из уравнений. Это переменные: C_t, I_t, S_t, Y_t. остальные 2 переменные модели t и G_t — это экзогенные переменные. Кроме того, модель содержит лаговую эндогенную переменную Y_t-1. Таким образом, общее число предопределенных переменных модели K = 3. Для первого уравнения m = 3 (в него входят эндогенные переменные C_t, I_t, S_t ), k = 1 (уравнение включает одну предопределенную переменную t ). Имеем: K - k = 3 - 1 = m - 1 = 3 - 1, Следовательно, уравнение точно идентифицировано. Для второго уравнения: m = 1 (I_t), k = 1 (Y_t-1). Имеем: K - k = 3 - 1 = 2 > m - 1 = 1 - 1 = 0, Следовательно, второе уравнение сверх идентифицировано. Для третьего уравнения: m = 2 (S_t, Y_t), k = 1 (Y_t-1). Имеем: K - k = 3 - 1 = 2 > m - 1 = 2 - 1 = 1, Следовательно, третье уравнение сверх идентифицировано. Последнее уравнение модели представляет собой тождество, его не надо проверять на идентификацию. Приведенная форма модели пункт 2 имеет вид: C_t = A_0 + A_1 Y_t-1 + A_2 G_t + A_3 t + \nu_1 I_t = B_0 + B_1 Y_t-1 + B_2 G_t + B_3 t + \nu_2 S_t = D_0 + D_1 Y_t-1 + D_2 G_t + D_3 t + \nu_3 Y_t = E_0 + E_1 Y_t-1 + E_2 G_t + E_3 t + \nu_2 Через заглавные буквы A, B, D, E обозначены приведенные коэффициенты модели v_1, v_2, v_3, v_4 — случайные ошибки (обозначения выбраны произвольно). Следовательно, пункт 3, параметры первого уравнения модели можно оценить косвенным МНК. Для этого: 1) определим обычным МНК параметры каждого из уравнений приведенной формы модели; 2) выразим зависимость C_t = a_0 + a_1 Y_t + a_2 S_t + a_3 t + u_1 из приведенной формы модели.
Порядковое условие показало, что второе уравнение модели сверхидентифицировано. Однако заметим, что правая часть этого уравнения не содержит эндогенных переменных. Поэтому нарушения предпосылок обычного МНК не происходит, и параметры данного уравнения можно оценивать обычным МНК. Третье уравнение модели сверхидентифицировано. В его правой части содержится эндогенная переменная Y_t, что приводит к нарушению предпосылок обычного МНК. Чтобы найти структурные параметры этого уравнения: 1) определим обычным МНК параметры четвертого уравнения приведенной формы модели; 2) найдем расчетные значения переменной Y_t: Y_t = E_0 + E_1 Y_t-1 + E_2 G_t + E_3 t Популярное:
|
Последнее изменение этой страницы: 2017-03-11; Просмотров: 770; Нарушение авторского права страницы
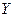 , а душевой доход — переменная
, а душевой доход — переменная 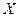 . Здесь ясно, какой признак выступает как независимая переменная (фактор), а какой как зависимая переменная (результат).
. Здесь ясно, какой признак выступает как независимая переменная (фактор), а какой как зависимая переменная (результат).
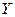 и
и  представляется в виде следующей формулы:
представляется в виде следующей формулы: 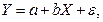 (1.1)
(1.1)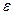 – случайная ошибка модели ( error , или disturbance ). Постоянные
– случайная ошибка модели ( error , или disturbance ). Постоянные 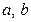 – неизвестные параметры модели. Наличие случайного члена
– неизвестные параметры модели. Наличие случайного члена 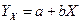 .
.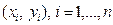 .
.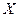 и
и 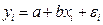 , (1.2)
, (1.2)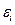 – случайная ошибка
– случайная ошибка 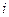 -го наблюдения. Чем меньше
-го наблюдения. Чем меньше 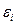 , тем ближе значение функции регрессии
, тем ближе значение функции регрессии 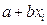 к значению
к значению 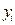 . Будем искать такие значения
. Будем искать такие значения 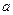 и
и  , при которых одновременно все значения
, при которых одновременно все значения 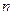 наблюдениях:
наблюдениях: 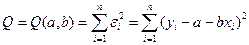 .
.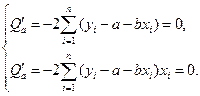

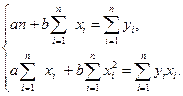 (1.3)
(1.3)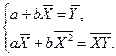 (1.4)
(1.4)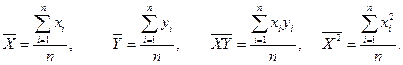
 из первого уравнения (1.4) во второе уравнение, найдем оценки неизвестных параметров регрессии:
из первого уравнения (1.4) во второе уравнение, найдем оценки неизвестных параметров регрессии: 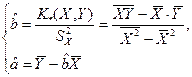 (1.5)
(1.5)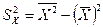 – выборочная дисперсия (sample variances) переменной
– выборочная дисперсия (sample variances) переменной 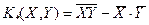 – выборочная ковариация или выборочный ковариационный момент. Статистики
– выборочная ковариация или выборочный ковариационный момент. Статистики 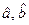 называются оценками наименьших квадратов (least squares estimates) неизвестных параметров
называются оценками наименьших квадратов (least squares estimates) неизвестных параметров 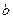 , или LS-оценками.
, или LS-оценками.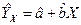 и
и 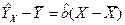 . (1.6)
. (1.6)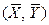 . Коэффициент
. Коэффициент  – угловой коэффициент регрессии. Он показывает, на сколько единиц в среднем изменится переменная
– угловой коэффициент регрессии. Он показывает, на сколько единиц в среднем изменится переменная 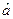 дает оценку среднего значения зависимой переменной при
дает оценку среднего значения зависимой переменной при  . Эта интерпретация возможна или невозможна в зависимости от того, насколько далеко находится
. Эта интерпретация возможна или невозможна в зависимости от того, насколько далеко находится 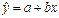
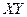
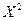
 =1179
=1179
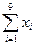 =4568
=4568
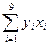 =761206
=761206
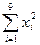 =3180132
=3180132
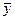 =131
=131
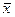 =507, 56
=507, 56
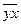 =84578, 44
=84578, 44
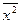 =20694, 78
=20694, 78
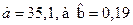 . Таким образом, модель имеет вид:
. Таким образом, модель имеет вид: 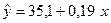 -уравнение регрессии.
-уравнение регрессии. — показывает среднее изменение результативного показателя (в единицах измерения у) с повышением или понижением величины фактора на единицу его измерения. В данном примере с увеличением дохода на 1 единицу расходы на питание повышаются в среднем на 0, 19. Другими словами, из каждого дополнительного рубля дохода 19 копеек будут израсходованы на питание.
— показывает среднее изменение результативного показателя (в единицах измерения у) с повышением или понижением величины фактора на единицу его измерения. В данном примере с увеличением дохода на 1 единицу расходы на питание повышаются в среднем на 0, 19. Другими словами, из каждого дополнительного рубля дохода 19 копеек будут израсходованы на питание.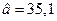 формально показывает прогнозируемый уровень у, но только в том случае, если х=0 находится близко с выборочными значениями. Но если х=0 находится далеко от выборочных значений х, то буквальная интерпретация может привести к неверным результатам, и даже если линия регрессии довольно точно описывает значения наблюдаемой выборки, нет гарантий, что также будет при экстраполяции влево или вправо.
формально показывает прогнозируемый уровень у, но только в том случае, если х=0 находится близко с выборочными значениями. Но если х=0 находится далеко от выборочных значений х, то буквальная интерпретация может привести к неверным результатам, и даже если линия регрессии довольно точно описывает значения наблюдаемой выборки, нет гарантий, что также будет при экстраполяции влево или вправо.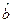 (если > 0 – прямая связь, иначе - обратная). В нашем примере связь прямая, т.е. с увеличением душевого дохода расходы на питание также увеличиваются.
(если > 0 – прямая связь, иначе - обратная). В нашем примере связь прямая, т.е. с увеличением душевого дохода расходы на питание также увеличиваются.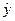 . Полученные величины показывают, какой бы был расход на питание при соответствующих доходах, если бы данная группа использовала бы свои доходы в такой степени, как в среднем все анализируемые группы.
. Полученные величины показывают, какой бы был расход на питание при соответствующих доходах, если бы данная группа использовала бы свои доходы в такой степени, как в среднем все анализируемые группы.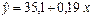
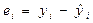
 , который рассчитывается по формуле:
, который рассчитывается по формуле:  ,
, 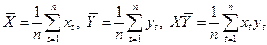 — выборочные средние,
— выборочные средние, 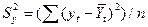 и
и 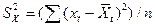 — выборочные дисперсии.
— выборочные дисперсии. , то связь считается сильной. Если
, то связь считается сильной. Если 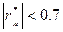 , слабая связь. Этот коэффициент дает объективную оценку лишь при линейной зависимости. В нашем примере
, слабая связь. Этот коэффициент дает объективную оценку лишь при линейной зависимости. В нашем примере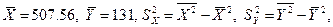 то коэффициент корреляции будет равен
то коэффициент корреляции будет равен 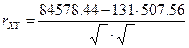 =0, 98.
=0, 98.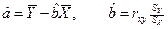
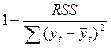 =
= 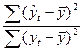 .
.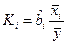 , где i- номер факторного признака, если рассматривается множественная регрессия и
, где i- номер факторного признака, если рассматривается множественная регрессия и 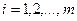 и m – число параметров в модели.
и m – число параметров в модели.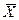 =6080, 6 и среднее значение у
=6080, 6 и среднее значение у 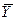 =1313, 9. Коэффициент эластичности тогда равен 0, 58, что говорит о том, что если фактор x изменится на 1%, то фактор y изменится на 0, 58%.
=1313, 9. Коэффициент эластичности тогда равен 0, 58, что говорит о том, что если фактор x изменится на 1%, то фактор y изменится на 0, 58%.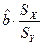 Т.е. увеличение душевого дохода на величину среднеквадратического отклонения этого показателя приведет к увеличению среднего значения расходов на питание на 0, 79 среднеквадратичного отклонения этих расходов.
Т.е. увеличение душевого дохода на величину среднеквадратического отклонения этого показателя приведет к увеличению среднего значения расходов на питание на 0, 79 среднеквадратичного отклонения этих расходов.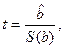 где
где 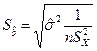 , где S(b) – стандартная ошибка коэффициента регрессии используется для проверки существенности коэффициента регрессии и для расчета его доверительных интервалов;
, где S(b) – стандартная ошибка коэффициента регрессии используется для проверки существенности коэффициента регрессии и для расчета его доверительных интервалов; 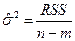 остаточная дисперсия на одну степень свободы,
остаточная дисперсия на одну степень свободы, 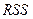 =
=  , где
, где 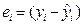 .
.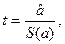 где
где 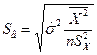
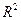 существенно от нуля, решается путем проверки гипотезы о значимости линейной регрессионной модели. При этом проверяется нулевая гипотеза
существенно от нуля, решается путем проверки гипотезы о значимости линейной регрессионной модели. При этом проверяется нулевая гипотеза  (коэффициент детерминации генеральной совокупности равен нулю, модель регрессии незначима), при конкурирующей гипотезе:
(коэффициент детерминации генеральной совокупности равен нулю, модель регрессии незначима), при конкурирующей гипотезе: 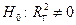 (модель регрессии значима). Проверка значимости модели осуществляется с помощью F-критерия Фишера.
(модель регрессии значима). Проверка значимости модели осуществляется с помощью F-критерия Фишера.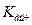 статистики F-критерия находится по формуле
статистики F-критерия находится по формуле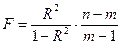 ,
, 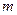 — число параметров модели (1.1). При условии справедливости нулевой гипотезы F-статистика критерия имеет распределение Фишера с
— число параметров модели (1.1). При условии справедливости нулевой гипотезы F-статистика критерия имеет распределение Фишера с 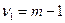 и
и 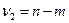 степенями свободы. Критическое значение статистики находится по табл. 5 и 6 и определяется по формуле
степенями свободы. Критическое значение статистики находится по табл. 5 и 6 и определяется по формуле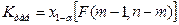 .
.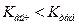 , то гипотезу
, то гипотезу 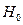 о незначимости модели следует принять, т.е. нет оснований отклонить эту гипотезу. Если
о незначимости модели следует принять, т.е. нет оснований отклонить эту гипотезу. Если 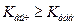
 , то гипотезу о незначимости
, то гипотезу о незначимости 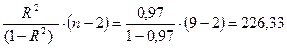 , а Fтабл.=5, 59. Таким образом, Fфакт.> Fтабл. и принимается гипотеза о статистической значимости уравнения в целом.
, а Fтабл.=5, 59. Таким образом, Fфакт.> Fтабл. и принимается гипотеза о статистической значимости уравнения в целом.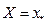 . Прогнозируемое значение обозначим
. Прогнозируемое значение обозначим 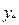 и будем называть его индивидуальным значением зависимой переменной. Наряду с решением этой задачи нас будет интересовать также проблема оценивания среднего значения зависимой переменной в этих же условиях. Это значение обозначим
и будем называть его индивидуальным значением зависимой переменной. Наряду с решением этой задачи нас будет интересовать также проблема оценивания среднего значения зависимой переменной в этих же условиях. Это значение обозначим 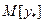 .
.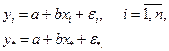
 удовлетворяют классическим предположениям. С содержательной точки зрения это означает, что условия, в которых осуществляется прогноз, совпадают с условиями, в которых осуществлялись имеющиеся
удовлетворяют классическим предположениям. С содержательной точки зрения это означает, что условия, в которых осуществляется прогноз, совпадают с условиями, в которых осуществлялись имеющиеся 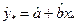
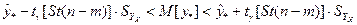 ,
, 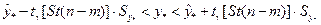 ,
, 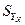 – стандартная ошибка оценки среднего значения зависимой переменной
– стандартная ошибка оценки среднего значения зависимой переменной 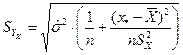 .
. – стандартная ошибка оценки индивидуального значения зависимой переменной
– стандартная ошибка оценки индивидуального значения зависимой переменной  определяется по формуле:
определяется по формуле: 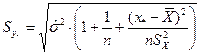 .
. при
при 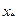 =1, 05
=1, 05 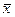 =1, 05*6080, 6, т.е. путем подстановки в уравнение регрессии
=1, 05*6080, 6, т.е. путем подстановки в уравнение регрессии  соответствующего значения
соответствующего значения 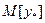 .
.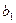 и
и 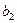 : это показатели силы связи, характеризующие абсолютное (в натуральных единицах измерения) изменение результативного признака при изменении факторного признака на единицу своего измерения при фиксированном влиянии второго фактора.
: это показатели силы связи, характеризующие абсолютное (в натуральных единицах измерения) изменение результативного признака при изменении факторного признака на единицу своего измерения при фиксированном влиянии второго фактора.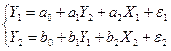
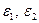 — случайные ошибки.
— случайные ошибки.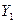 и
и 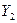 являются эндогенными, a
являются эндогенными, a 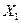 и
и 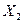 — экзогенными переменными.
— экзогенными переменными.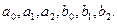 .Если модель содержит тождества, то без потери общности их можно назвать уравнениями, в которых структурные параметры при переменных равны 1.
.Если модель содержит тождества, то без потери общности их можно назвать уравнениями, в которых структурные параметры при переменных равны 1.