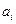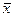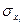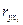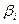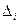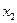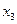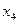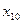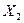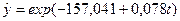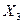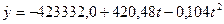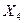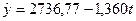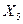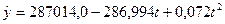|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Прогнозирование на основе множественной корреляционно-регрессионной модели с помощью пакета STATGRAFICS
В системе STATGRAFICS реализовано несколько методов корреляционно-регрессионного анализа, позволяющих установить связь между результативным признаком и одним или более факторными переменными. В основном модуле Relate (Связи) представлены: - Simple Regression (простая регрессия); - Polynomia l Regression (полиномиальная регрессия); - Multiple Regression (множественная регрессия) В этом модуле реализована возможность пошаговой регрессии. С целью исключения мультиколлинеарных факторов построим множественную линейную модель, используя пошаговую регрессию. Матрица исходной информации представлена в Приложении Б. В качестве исходной информации, используются следующие показатели: У− средняя обеспеченность населения жильём всего м2 общей площади на одного жителя; Х2 − средняя стоимость строительства за 1 м Х3 − денежные доходы в расчете на душу населения в среднем за месяц, тыс.руб. (в сопоставимых ценах); Х4 − удельный вес частного жилого фонда, %; Х5 − удельный вес числа семей, состоящих на учете для получения жилья, в общем числе семей, %; Х6 − удельный вес семей улучшивших свои жилищные условия в % от числа семей, состоящих на учете на получение жилья; Х7 − капитально отремонтированных жилых домов за год, всего тыс. м Х8 − индекс потребительских цен (декабрь текущего года в % к декабрю предыдущего года); Х9 − численность безработных, человек; Х10 − ввод в действие жилых домов, тыс. м2 общей площади; Х11 − инвестиции в жилища млн руб. (в сопоставимых ценах). В главном меню выбираем модуль Relate (связи) и находим процедуру Multiple Regression (множественная регрессия). Система STATGRAFICS покажет входную панель множественной регрессии (рисунок 4.2.1)
Dependent Variable – зависимая переменная; Independent Variable – независимые переменные; Select – выбрать; Weights – веса. Рисунок 4.2.1 – Входная панель процедуры Multiple Regression (множественная регрессия) После нажатия клавиши OK появится окно с предварительными результатами анализа (рисунок 4.2.2).
Multiple Regression Analysis ----------------------------------------------------------------------------- Dependent variable: Y --------------------------------------------------------------------------- Standard T Parameter Estimate Error Statistic P-Value ----------------------------------------------------------------------------- CONSTANT 10, 861 2, 001 5, 428 0, 012 X1 -0, 138 0, 571 -0, 241 0, 825 X10 0, 539 0, 359 1, 501 0, 230 X2 1, 808 2, 109 0, 857 0, 454 X3 0, 127 0, 026 4, 976 0, 016 X4 0, 098 0, 040 2, 431 0, 093 X5 -0, 169 0, 174 -0, 969 0, 404 X6 0, 000 0, 000 0, 338 0, 757 X7 -0, 001 0, 001 -1, 354 0, 269 X8 0, 000 0, 000 -0, 979 0, 399 X9 0, 003 0, 003 1, 088 0, 356 ----------------------------------------------------------------------------- Analysis of Variance ----------------------------------------------------------------------------- Source Sum of Squares Df Mean Square F-Ratio P-Value ----------------------------------------------------------------------------- Model 27, 413 10 2, 741 80, 89 0, 002 Residual 0, 102 3 0, 034 ----------------------------------------------------------------------------- Total (Corr.) 27, 5143 13 R-squared = 99, 6305 percent R-squared (adjusted for d.f.) = 98, 399 percent Standard Error of Est. = 0, 184 Mean absolute error = 0, 069 Durbin-Watson statistic = 2, 875
Рисунок 4.2.2 − Предварительные результаты построения модели Щелкнем правой кнопкой мыши, появится меню, в котором нужно выбрать Analysis Options (опции анализа) для вызова пошаговой регрессии. Процедура пошаговой регрессии дает возможность автоматического подбора адекватной модели. При этом используются два основных подхода: Forward Selection (включения факторов) или Backward Selection (исключения факторов) (рисунок 4.2.3).
Fit – подбирать; All Variable – все переменные; Forward Selection − включение факторов; Backward Selection − исключение Факторов; Constant in Model − свободный член модели; F-to-Enter – включение; F-to-Remove – исключение; Max Steps – максимальное число шагов; Display – показать; Final Model Only – только заключительная модель; All Steps – все шаги. Рисунок 4.2.3 – Окно Multiple Regression Option (опции множественной регрессии). Модель пошаговой регрессии
Флажок в поле Constant in Model (свободный член модели) предполагает наличие в модели свободного члена. Установлено также, что F-критерий для включения (F-to-Enter) и исключения (F-to-Remove) независимых переменных равен 4. Максимальное количество шагов при построении модели (Max Steps) − 50. Флажок в поле All Steps (все шаги) требует вывод на экран всех промежуточных этапов построения уравнения регрессии. Отметив поле Forward Selection (включения факторов) и Final Model Only получим результаты заключительной модели (промежуточные этапы построения модели не показаны) (рисунок 4.2.4).
Multiple Regression Analysis ----------------------------------------------------------------------------- Dependent variable: Y ----------------------------------------------------------------------------- Standard T Parameter Estimate Error Statistic P-Value ----------------------------------------------------------------------------- CONSTANT 9, 994 0, 955 10, 469 0, 000 X10 0, 156 0, 036 4, 330 0, 002 X2 3, 809 1, 029 3, 702 0, 005 X3 0, 120 0, 0126 9, 521 0, 000 X4 0, 069 0, 025 2, 739 0, 023 ----------------------------------------------------------------------------- Analysis of Variance ----------------------------------------------------------------------------- Source Sum of Squares Df Mean Square F-Ratio P-Value ----------------------------------------------------------------------------- Model 27, 272 4 6, 818 252, 92 0, 000 Residual 0, 243 9 0, 027 ----------------------------------------------------------------------------- Total (Corr.) 27, 5143 13
R-squared = 99, 118 percent R-squared (adjusted for d.f.) = 98, 726 percent Standard Error of Est. = 0, 164 Mean absolute error = 0, 098 Durbin-Watson statistic = 2, 026
Stepwise regression ------------------- Method: forward selection F-to-enter: 4, 0 F-to-remove: 4, 0 Final model selected
Рисунок 4.2.4 − Окончательные результаты выбора модели Основные результаты расчета сведены в две таблицы: в первой отражены результаты регрессионного анализа, во второй представлен дисперсионный анализ. Внизу показана дополнительная информация: R-squared – коэффициент детерминации; R-squared (adjusted for d.f.) − коэффициент детерминации, приведенный с учетом степеней свободы; Standard Error of Est. (SE) – стандартная ошибка оценивания; Mean absoluteerror –стандартная ошибка оценивания; Durbin-Watsonstatistic – статистика Дарбина− Уотсона. На основе частных F-критериев из 10 независимых переменных в модель средней обеспеченности населения жильём всего м2 общей площади на одного жителя включены 4 фактора: средняя стоимость строительства за 1 м2, руб (в сопоставимых ценах) (Х2); денежные доходы в расчете на душу населения в среднем за месяц, тыс.руб. (в сопоставимых ценах) (Х3); удельный вес частного жилого фонда, % (Х4); ввод в действие жилых домов, тыс. м2 общей площади; (Х10). Построена следующая модель: Y=9, 994 + 3, 809*X2 + 0, 120*X3 + 0, 069*X4+ 0, 156*X10 Все отобранные факторы статистически значимы, так как фактический t-критерий Стьюдента больше табличного (приложение В). Об этом свидетельствует графа 5 таблицы рисунка 4.2.4 (P-Value), в которой отражены вероятности наиболее существенных факторов динамики средней обеспеченности населения жильём. Дисперсионный анализ ( AnalysisofVariance ) позволяет получить F-критерий для оценки адекватности модели. Представленные на рисунке 4.2.4 данные свидетельствуют о хорошей адекватности модели. Фактический критерий Фишера (F-Ratio), равный 252, 92, в 69, 7 раза больше табличного значения. Стандартная ошибка остатков (StandardErrorofEst.) составляет 0, 164. Приведенный с учетом степеней свободы коэффициент детерминации (R-squared(adjustedford.f.) равный 98, 726% свидетельствует о том, что вариация средней обеспеченности населения жильём на 98, 7% обусловлена включенными в модель факторами. Статистика Дарбина–Уотсона (Durbin-Watsonstatistic), составляющая 2, 026, говорит об отсутствии автокорреляции (рисунок 4.2.5 и приложение А). 2, 026
(+) (-) Рисунок 4.2.5 − Таблица определения наличия или отсутствия автокорреляции на основе критерия Дарбина − Уотсона На рисунке 4.2.6 приведено также неполное содержание окна статистического консультанта ( Stat Advisor ). Внизу рисунка дополнительно дан русский перевод. Таким образом, по всем проверенным критериям полученное уравнение регрессии имеет статистически значимые коэффициенты, сама модель является типичной, без автокорреляции в остатках, следовательно, данное уравнение можно использовать для получения достоверных и точных прогнозов.
The StatAdvisor The output shows the results of fitting a multiple linear regression model to describe the relationship between Y and 10 independent variables. The equation of the fitted model is
Y = 9, 994 + 0, 156*X10 + 3, 809*X2 + 0, 120*X3 + 0, 069*X4
Since the P-value in the ANOVA table is less than 0.01, there is a tatistically significant relationship between the variables at the 99% confidence level. The R-Squared statistic indicates that the model as fitted explains 99, 1183% of the variability in Y. The adjusted R-squared statistic, which is more suitable for comparing models with different numbers of independent variables, is 98, 7264%. The standard error of the estimate shows the standard deviation of the residuals to be 0, 164184. This value can be used to construct prediction limits for new observations by selecting the Reports option from the text menu.The mean absolute error (MAE) of 0, 0978855 is the average value of the residuals. The Durbin-Watson (DW) statistic tests the residuals to determine if there is any significant correlation based on the order in which they occur in your data file. Since the DW value is greater than 1.4, there is probably not any serious autocorrelation in the residuals.
Вывод показывает результаты построения модели линейной регрессии между Y и 10 независимыми переменными. Уравнение регрессионной модели имеет вид:
Y = 9, 994 + 0, 156*X10 + 3, 809*X2 + 0, 120*X3 + 0, 069*X4
Так как P-значение в таблице дисперсионного анализа меньше чем 0.01, то имеется статистически существенная связь между анализируемыми переменными при уровне доверия 99%. Коэффициент детерминации (R-Squared) указывает, что 99, 118% дисперсии зависимой переменной Y объясняется включенными в модель факторами. Скорректированный R-squared, который является более подходящим для сравнения моделей с различным количеством независимых переменных, равен 98, 726%. Стандартная ошибка оценивания, означающая среднеквадратическое отклонение остатков, равна 0, 164. это значение может быть использовано при расчете доверительных интервалов для новых наблюдений при выборе пункта Reports из табличных опций. Средняя абсолютная ошибка (MAE) – 0, 098 – средняя оценка residuals (остатков). Статистика Дарбина – Уотсона (DW) свидетельствует об отсутствии автокорреляции остатков.
Рисунок 4.2.6 − Окно Stat Advisor с русским переводом. Дадим интерпретацию коэффициентов уравнения. Из построенной модели видно, что при увеличении средней стоимости строительства за 1 м2, на 1 рубль показатель обеспеченности возрастает на 3, 809 м2; при росте среднедушевых месячных доходов населения на 1 тыс. руб. средняя обеспеченность населения края жильем увеличится на 0, 12 м2 на человека; при увеличении удельного веса частного жилого фонда на 1% обеспеченность возрастает на 0, 069 м2; при повышении ввода в действие жилых домов 1 тыс. м2 общей площади средняя обеспеченность увеличивается на 0, 156 м2. Расчет коэффициентов эластичности Рассмотрим принципы анализа степени влияния факторов на нашем примере (таблица 4.2.1.) ( Таблица 4.2.1 − Расчет коэффициентов эластичности,
Если сопоставить значения коэффициентов эластичности, то можно видеть, что главным фактором изменения результативного показателя является фактор Х3 (денежные доходы в расчете на душу населения в среднем за месяц, тыс.руб.). При его увеличении на 1% У (средняя обеспеченность населения жильём всего м2 общей площади на одного жителя) возрастает на 0, 296%. Вторым по силе влияния на результат является фактор Х4 (удельный вес частного жилого фонда, %). С ростом этой переменной на 1% средняя обеспеченность жильем на 0, 07%. Третьим – фактор Х2 (средняя стоимость строительства за 1 м2, руб), с увеличением этого фактора на 1% средняя обеспеченность возрастает на 0, 065%. Самым незначительным влиянием обладает переменная Х10 (ввод в действие жилых домов, тыс. м2 общей площади), с ростом этого фактора на 1% обеспеченность жильем населения края увеличивается на 0, 008%. Сравнение Сопоставление значений коэффициентов Следовательно, наибольшие возможности в изменении выручки от реализации У связаны с изменением факторов Х3 (денежные доходы в расчете на душу населения в среднем за месяц, тыс. руб.) и Х4 (удельный вес частного жилого фонда, %) Для построения прогноза по множественной корреляционно-регрессионной модели построим отдельно для каждого фактора его регрессию на фактор времени, другими словами построим трендовые модели, а также прогноз для каждого фактора. Выбор формы тренда и построение прогноза проводим в соответствии с методикой, описанной ранее (раздел 3.5)(таблица 4.2.2). Таблица 4.2.2 − Трендовые модели для факторов, включенных во множественную корреляционно-регрессионную модель
Используя трендовые модели, представленные в таблице 4.2.2 построим точечные и интервальные прогнозы по исследуемым факторам (таблица 4.2.3). Таблица 4.2.3 − Прогнозные значения факторов, включенных во множественную корреляционно-регрессионную модель.
Полученные прогнозные значения подставим в уравнение множественной регрессии: Y=9, 994 + 3, 809*X2 + 0, 120*X3 + 0, 069*X4+ 0, 156*X10. В результате подстановки получим прогнозные значения, которые приведены в таблице 4.2.4. Таблица 4.2.4 – Прогнозные значения и доверительные интервалы средней обеспеченности жильем жителей Хабаровского края, полученные на основе множественной регрессии
Результаты прогноза показывают, что население Хабаровского края в ближайшем будущем ожидает повышение средней обеспеченности жильем (в основном за счет роста денежных доходов). К 2009 году средняя обеспеченность жильем составит 21, 63 м2 на человека, т.е. возрастет по сравнению с 2005 годов на 8, 7% (среднегодовой темп прироста составит 2, 1%). Контрольные вопросы к разделу 4 1. Охарактеризуйте основные этапы прогнозирования по множественной корреляционно-регрессионной модели. 2. С помощью каких критериев можно оценить адекватность множественной корреляционно-регрессионной модели? 3. В чем сущность пошаговой регрессии? Какие виды пошаговой регрессии реализованы в пакете STATGRAFICS? 4. На основе каких показателей можно определить наиболее значимые факторы влияния на результат? 5. Каким образом проводится прогноз по множественной регрессии в системе STATGRAFICS? Популярное:
|
Последнее изменение этой страницы: 2017-03-11; Просмотров: 943; Нарушение авторского права страницы
 ., руб (в сопоставимых ценах);
., руб (в сопоставимых ценах); 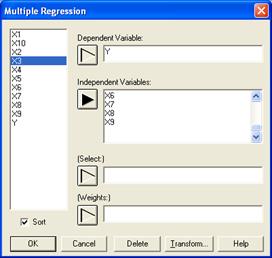
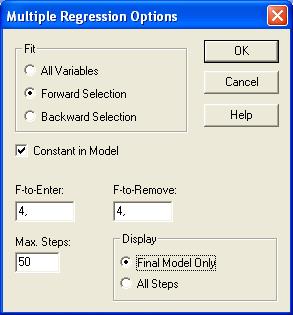

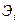 ,
, 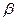 -коэффициентов (стандартизованные коэффициенты регрессии),
-коэффициентов (стандартизованные коэффициенты регрессии), 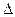 -коэффициентов позволит определить степень влияния факторной переменной на результат.
-коэффициентов позволит определить степень влияния факторной переменной на результат.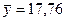 ;
; 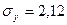 ;
; 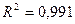 ).
).