
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Возможности пакета STATGRAFIC при однофакторном прогнозировании
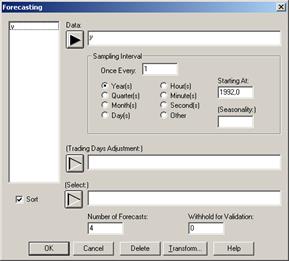
Выберем в пункте Специальный ( Special) главного меню модуль Анализ временных рядов (Time–Series Analysis). Система выдаст входную панель Forecasting (Прогнозирование) (рисунок 3.5.1). В поле Data (данные) введем имя переменной splan 1 (х или у), установим кнопку Year(s) (годы). Number of Forecasts (период упреждения, прогноза) выбираем 1/3 исследуемого временного ряда (рисунок 3.5.1).
Forecasting – прогнозирование; Data – данные (имя переменной); Sampling Interval – выборочный интервал; Once Every – выбор времени; Year(s) – годы; Quarter(s) – кварталы; Month(s) – месяцы; Day(s) – дни; Hour(s) – часы; Minute(s) – минуты; Second(s) − секунды; Other – другое; Starting At – начинать за; (Seasonafity: ) − сезонность; (Trading Days Adjustment: ) − корректировка данных; (Select: ) − выбор; Number of Forecasts – период упреждения (прогноза); Withhold of Validation – скрыть действия; Transform – трансформировать. Рисунок 3.5.1 − Окно Forecasting ( входная панель процедуры прогнозирования) После нажатия кнопки OK система выдаст сводку предварительного анализа Analysis Summary (резюме анализа). Для вывода на экран результатов анализа по нескольким трендовым моделям необходимо нажать вторую кнопку слева (рисунок 3.5.2)
Рисунок 3.5.2 – Панель инструментов. Появится окно Tabular Options (табличные Опции) (рисунок 3.5.3). Выберем операцию Model Comparison (сравнение моделей), затем нажмем OK. Analysis Summary − резюме Анализа; Forecast Table − таблица Прогноза; Model Comparison – сравнение моделей; Residual Autocorrelations − остаточные автокорреляции; Residual Partial Autocorrelations − остаточная частные автокорреляции; Residual Periodogram Table − остаточная таблица периодoграмм; Residual Tests for Randomness − остаточные критерии случайности.
Рисунок 3.5.3 − Oкно Tabular Options (табличные опции)
Щелкнем на панели правой кнопкой мыши и в появившемся окне выберем Analysis Options ( опции анализа ) (рисунок 3.5.4)
Pane Options − опции области окна; Analysis Options − опции анализа; Print – напечатать; Copy to Gallery − копия к галерее.
Рисунок 3.5.4 – Контекстовое меню
Система STATGRAFICS покажет модуль Model Specification Option (опции спецификации модели) (рисунок 3.5.5).
Model – модель; None − ни один; Math – математика; Natural log – натуральный логарифм; Base 10 log – основание десятичного логарифма; Square root − квадратный корень; Reciprocal − обратная величина; Power − степень; Box-Cox – основной блок; Addend – слагаемое; Type – Тип; Random Walk – случайная выборка; Mean – средний; Linear Trend − линейная тенденция; Quadratic Trend − квадратическая тенденция; Exponential Trend − показательная тенденция; S-Curve − S-кривая; Moving average − скользящее среднее значение; Simple Exp. Smoothing − простое экспоненциальное сглаживание; Brown´ s Linear Exp. Smoothing – линейное экспоненциальное сглаживание Брауна; Holt´ s Exp. Smoothing – линейное экспоненциальное сглаживание Хольта; Quadratic Exp. Smoothing – квадратическое экспоненциальное сглаживание; Winter´ s Exp. Smoothing − экспоненциальное сглаживание Винтера; ARIMA Model – объединенная модель авторегрессии и скользящего среднего; Seasonal – сезонность; Multiplicative – мультипликативный; Additive – аддитивный; Differencing − различия; Nonseasonal Order – несезонная последовательность; S easonal Order − сезонная последовательность; Inflation – наполнение; Apply at − применить в; End of Period − конец периода; Middle of Period − середина периода; Rate – норма; Parameters and Terms - параметры и сроки; Optimize – оптимизировать; Constant – постоянный. Рисунок 3.5.5 − Модуль Model Specification Option (опции спецификации модели) Учитывая, что STATGRAFICS может сравнивать одновременно пять типов моделей, оптимизируя их параметры, выберем для анализа Linear Trend (линейная тенденция), Quadratic Trend (квадратическая тенденция), Exponential Trend ( показательная тенденция) и S-Curve ( S-кривая). Указанные модели выбираются в окне Model Specification Option (опции спецификации модели) (рисунок 3.5.5) следующим образом. В области Model (модель) щелкнем на пункте А, а в области Type (тип) установим флажок Linear Trend (линейная тенденция). Затем выберем пункт В и установим флажок на Quadratic Trend (квадратическая тенденция). Для модели С выберем Exponential Trend ( показательная тенденция). Для модели D установим флажок в поле S-Curve ( S-кривая). Остальные поля оставим со значением по умолчанию. На рисунке 3.5.6. представлен листинг сравнения моделей. Model Comparison ---------------- Data variable: y Number of observations = 14 Start index = 1 Sampling interval = 1, 0 year(s)
Models ------ (A) Linear trend = 15, 1791 + 0, 343736 t (B) Quadratic trend = 15, 3522 + 0, 278832 t + 0, 00432692 t^2 (C) Exponential trend = exp(2, 7284 + 0, 0193701 t) (D) S-curve trend = exp(2, 93191 + -0, 25073 /t) (E) Simple exponential smoothing with alpha = 0, 9999
Estimation Period Model MSE MAE MAPE ME MPE ------------------------------------------------------------------------ (A) 0, 0528425 0, 16562 0, 945267 1, 39571E-15 -0, 0129212 (B) 0, 0526901 0, 161421 0, 922914 5, 07531E-16 -0, 013535 (C) 0, 0486203 0, 16052 0, 917722 0, 00123114 -0, 00682013 (D) 0, 95851 0, 811367 4, 55073 0, 0240537 -0, 12694 (E) 0, 180789 0, 321464 1, 80398 0, 321454 1, 80391
Model RMSE RUNS RUNM AUTO MEAN VAR ----------------------------------------------- (A) 0, 229875 * OK OK OK OK (B) 0, 229543 * OK OK OK OK (C) 0, 2205 * OK OK OK OK (D) 0, 979035 *** ** *** *** OK (E) 0, 425193 OK OK OK OK OK
Key: RMSE = Root Mean Squared Error RUNS = Test for excessive runs up and down RUNM = Test for excessive runs above and below median AUTO = Box-Pierce test for excessive autocorrelation MEAN = Test for difference in mean 1st half to 2nd half VAR = Test for difference in variance 1st half to 2nd half OK = not significant (p > = 0.10) * = marginally significant (0.05 < p < = 0.10) ** = significant (0.01 < p < = 0.05) *** = highly significant (p < = 0.01)
The StatAdvisor --------------- This table compares the results of five different forecasting models. You can change any of the models by pressing the alternate mouse button and selecting Analysis Options. Looking at the error statistics, the model with the smallest mean squared error (MSE) during the estimation period is model C. The model with the smallest mean absolute error (MAE) is model C. The model with the smallest mean absolute percentage error (MAPE) is model C. You can use these results to select the most appropriate model for your needs. The table also summarizes the results of five tests run on the residuals to determine whether each model is adequate for the data. An OK means that the model passes the test. One * means that it fails at the 90% confidence level. Two *'s means that it fails at the 95% confidence level. Three *'s means that it fails at the 99% confidence level. Note that the currently selected model, model D, passes only one test. Since one or more tests are statistically significant at the 95% or higher confidence level, you should seriously consider selecting another model. Рисунок 3.5.6 − Листинг сравнения моделей прогнозирования Листинг содержит стандартную ошибку остатков (RMSE) и пять тестов RUNS, RUNM, AUTO, MEAN и VAR. RUNS (Test for excessive runs up and down) – тест на чрезмерное число пиков и впадин. Определяет количество повышений или понижений в последовательности анализируемых данных. Тест чувствителен к долгосрочным циклам. RUNM (Test for excessive runs above and below median) – тест на чрезмерное количество отклонений от медианы; рассчитывают число наблюдений, значение которых выше или ниже медиан, игнорируют значения, которые являются равными медиане. Тест чувствителен к наличию тренда в последовательности данных. AUTO (Box-Pierce test for excessive autocorrelation) – тест на чрезмерную автокорреляцию рассчитывает коэффициент сериальной корреляции Бокса-Пирса. MEAN (Test for difference in mean 1st half to 2nd half) – тест на существенность разности средних служит для определения тенденции среднего значения. VAR (Test for difference in variance 1st half to 2nd half) – тест на существенность разности дисперсий позволяет установить тенденцию вариабельности. Данные листинга, приведенные на рисунках 3.5.6 и 3.5.7, показывают, что данная модель наиболее удачно аппроксимирует эмпирические данные. Поэтому для производства прогноза лучше использовать эту модель. Текстовые и графические результаты прогнозирования можно показать на экране. Щелкнем правой кнопкой мыши и выберем из меню пункт Analysis Option – появится панель Model Specification Option (Спецификации модели). После этого установим переключатель в положение Exponential trend (показательный тренд). Вызовем панель Tabular Options (табличные опции) (рисунок 3.5.3), установим флажок в полях Forecast Table (таблица прогнозов).
Сравнение моделей ---------------- Переменная данных: y Число наблюдений = 14 Индекс начала = 1 Осуществление выборки интервала = 1, 0 года (года) Модели ------ (A) Линейная тенденция = 15, 1791 + 0, 343736 t (B) Квадратная тенденция = 15, 3522 + 0, 278832 t + 0, 00432692 t^2 (C) Показательная тенденция = exp (2, 7284 + 0, 0193701 t) (D) Тенденция S-кривой = exp (2, 93191 +-0, 25073/t) (E) Простое показательное сглаживание с альфой = 0, 9999 Период Оценки Модели MSE MAE MAPE ME MPE ------------------------------------------------------------------------ (A) 0, 0528425 0, 16562 0, 945267 1, 39571E-15 -0, 0129212 (B) 0, 0526901 0, 161421 0, 922914 5, 07531E-16 -0, 013535 (c) 0, 0486203 0, 16052 0, 917722 0, 00123114 -0, 00682013 (D) 0, 95851 0, 811367 4, 55073 0, 0240537 -0, 12694 (E) 0, 180789 0, 321464 1, 80398 0, 321454 1, 80391
Модели RMSE RUNS RUNM AUTO MEAN VAR ----------------------------------------------- (A) 0, 229875 * OK OK OK OK (B) 0, 229543 * OK OK OK OK (c) 0, 2205 * OK OK OK OK (D) 0, 979035 *** ** *** *** OK (E) 0, 425193 OK OK OK OK OK
Ключ: RMSE = Стандартная ошибка остатков RUNS = Тест на чрезмерное количество пиков и впадин RUNM = Тест на чрезмерные количество отклонений от медианы AUTO = Тест на чрезмерную автокорреляцию MEAN = Тест на существенность разности средних VAR = Тест на существенность разности дисперсий OK = не существенный (p> = 0.10) * = незначительно существенный (0.05 < p < = 0.10) ** = существенный (0.01 < p < = 0.05) *** = очень существенный (p < = 0.01) StatAdvisor --------------- Эта таблица сравнивает результаты пяти различных моделей прогнозирования Вы можете изменить любую из моделей, нажимая на правую кнопку мыши и выбирая из меню Analysis Options (Опции Анализа). Изучение статистик остатков показывает, что модель с самой маленькой среднеквадратической ошибкой (MSE)в оцениваемом периоде модель C. Модель с наименьшим результатом средней абсолютной погрешностью (МАЕ) - модель C. Модель с самой маленькой абсолютной процентной ошибкой (MAPE) - модель C. Вы можете использовать эти результаты, чтобы выбирать наиболее соответствующую модель для ваших потребностей. Таблица также подводит итог результатов пяти тестов остатков для определения адекватности модели данных. OK означает, что модель проходит тест. Одина звездочка * означает, что модель не подходит на 90%-ом доверительном уровне. Две звездочки ** означают, что модель не подходит на 95%-м уровне доверия. Три звездочки *** означают, что модель не походит на 99%-м уровне доверия. Обратите внимание, что модель D, выбранная в качестве текущей модели проходит только один тест. Так как один или более тестов статистически существенны на 95%-м или более высоком доверительном уровень, Вы должны серьезно рассмотреть отбор другой модели. Рисунок 3.5.7 – Панель статистического сравнения с переводом
Система STATGRAFICS выдаст таблицу прогноза (рисунок 3.5.8).
Forecast Table for y
Model: Exponential trend = exp(-35, 8182 + 0, 0193701 t) Period Data Forecast Residual ------------------------------------------------------------------------------ 1992 15, 4 15, 6077 -0, 207726 1993 16, 1 15, 913 0, 187003 1994 16, 5 16, 2242 0, 275762 1995 16, 6 16, 5416 0, 0584329 1996 16, 9 16, 8651 0, 0348973 1997 17, 0 17, 195 -0, 194966 1998 17, 1 17, 5313 -0, 431282 1999 17, 9 17, 8742 0, 0258249 2000 18, 2 18, 2238 -0, 0237751 2001 18, 5 18, 5802 -0, 0802129 2002 19, 3 18, 9436 0, 356378 2003 19, 5 19, 3141 0, 18586 2004 19, 7 19, 6919 0, 0080962 2005 19, 9 20, 0771 -0, 177057 ------------------------------------------------------------------------------
Lower 95, 0% Upper 95, 0% Period Forecast Limit Limit ------------------------------------------------------------------------------ 2006 20, 4697 19, 8341 21, 1258 2007 20, 8701 20, 2053 21, 5568 2008 21, 2783 20, 5817 21, 9985 2009 21, 6945 20, 9637 22, 4508 ------------------------------------------------------------------------------
Таблица Прогноза для y
Модель: Показательная тенденция = exp (-35, 8182 + 0, 0193701 t)
Период Фактические данные Теоретические данные Остатки ------------------------------------------------------------------------------ 1992 15, 4 15, 6077 -0, 207726 1993 16, 1 15, 913 0, 187003 1994 16, 5 16, 2242 0, 275762 1995 16, 6 16, 5416 0, 0584329 1996 16, 9 16, 8651 0, 0348973 1997 17, 0 17, 195 -0, 194966 1998 17, 1 17, 5313 -0, 431282 1999 17, 9 17, 8742 0, 0258249 2000 18, 2 18, 2238 -0, 0237751 2001 18, 5 18, 5802 -0, 0802129 2002 19, 3 18, 9436 0, 356378 2003 19, 5 19, 3141 0, 18586 2004 19, 7 19, 6919 0, 0080962 2005 19, 9 20, 0771 -0, 177057 ------------------------------------------------------------------------------ Доверительный интервал прогноза с 95% вероятностью Период Точечный прогноз Нижняя граница Верхняя граница ------------------------------------------------------------------------------ 2006 20, 4697 19, 8341 21, 1258 2007 20, 8701 20, 2053 21, 5568 2008 21, 2783 20, 5817 21, 9985 2009 21, 6945 20, 9637 22, 4508
Рисунок 3.5.8 − Прогноз тренда по показательной модели Панель прогноза (рисунок 3.5.8.) содержит две таблицы. В верхней таблице отражены фактические и модельные значения средней обеспеченности населения Хабаровского края жильем, также остатки (отклонение фактических и теоретических значений). В нижней таблице приведены точечный и интервальный прогнозы с вероятностью 95%. Таким образом, прогноз на 4 года показывает, что с 2006 по 2009 год среднегодовой абсолютный прирост обеспеченности жильем населения Хабаровского края составит 0, 41 м2 (1, 98%.) и в 2009 году достигнет 21, 69 м2 на человека. Сохраним остатки (отклонение фактических значений от теоретических) под именем Residuals. Для этого щелкнем по пиктограмме
Save – сохранить; Data – данные; Adjusted data - выравненные данные Forecast – прогноз; Upper forecast limits – верхняя граница прогноза; Lower forecast limits – нижняя граница прогноза; Residuals – остатки; Autocorrelations – автокорреляция; Partial autocorrelations – частная автокорреляция Рисунок 3.5.9 − Окно Save Results Options (сохранение результатов анализа) Для получения графического изображения результатов прогноза необходимо щелкнуть мышью по кнопке графических опций (рисунок 3.5.1):
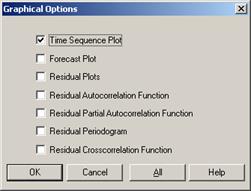
Рисунок 3.5.10 – Панель инструментов. В появившейся панели Graphical Options (опции графика) (рисунок 3.5.11) установим флажок в поле Time Sequence Plot (график временной последовательности)
Time Sequence Plot − график временной последовательности; Forecast Plot – график прогноза; Residual Plot – график остатков; Residual Autocorrelation Function – график автокорреляционной функции; Residual Partial Autocorrelation Function – график частной автокорреляционной функции; Residual Crosscorrelation Function – график кросскорреляционной функции. Рисунок 3.5.11 − Панель Graphical Options (опции графика) Система построит график исходного ряда и прогноз по экспоненциальному тренду (показательному тренду) (рисунок 3.5.12).
Рисунок 3.5.12 − График прогноза тренда по показательной модели График остатков представлен на рисунке 3.5.13.
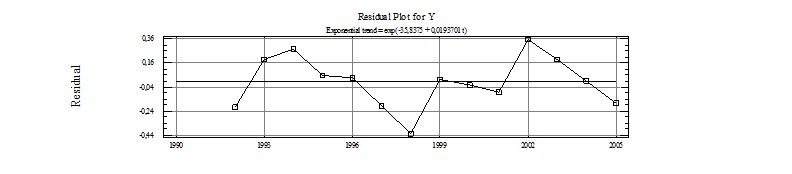
Рисунок 3.5.13 − График остатков Особый интерес представляют графики Residual Autocorrelation Function ( график автокорреляционной функции) и Residual Partial Autocorrelation Function ( график частной автокорреляционной функции) (рисунок 3.5.14 и 3.5.15). Уменьшение высоты столбца графика автокорреляционной функции свидетельствуют об ослаблении связи с прошлым и возможности использования авторегрессии.
Рисунок 3.5.14 − График автокорреляционной функции остатков График частной автокорреляционной функции применяется для уточнения количества членов авторегрессионной модели, необходимых для адекватного описания остатков. На рисунке 3.5.15 коэффициенты частной автокорреляции отображаются в виде столбцов, высота которых пропорциональна величине коэффициента. Границы в виде штриховых линий, расположенных выше и ниже нуля, применяются для выявлений частных автокорреляций, значимо отличаются от нуля.
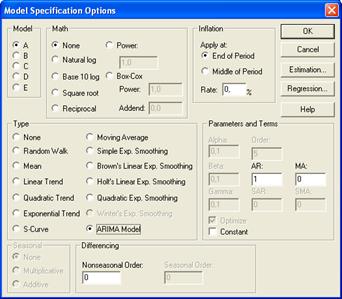
Рисунок 3.5.15 − График частной автокорреляционной функции остатков Как видно из графика, остатки обеспеченности населения жильем слабо коррелированны с предыдущим значением. Следовательно, их можно описывать авторегрессией первого порядка. Откроем окно входной панели (рисунок 3.5.1) и введем имя переменной Residuals, период упреждения, равный четырем годам, и Year(s) год. По умолчанию система осуществит прогноз по модели случайной выборки. Вызовем панель Model Specification Options (модуль опции спецификации модели) (рисунок 3.5.16) и выберем ARIMA Model. Уберем флажок в поле Constant, т.е. построим модель без свободного члена. Остальные значения оставим без изменения.
Рисунок 3.5.16 – Модуль Model Specification Options (опции спецификации модели) STATGRAFICS рассчитает авторегрессию первого порядка. Выходное окно, содержит результаты подбора модели (рисунок 3.5.17) Analysis Summary Data variable: RESIDUALS Number of observations = 14 Start index = 1992 Sampling interval = 1, 0 year(s) Forecast Summary ---------------- Forecast model selected: ARIMA(1, 0, 0) Number of forecasts generated: 4 Number of periods withheld for validation: 0 Estimation Validation Statistic Period Period -------------------------------------------- MSE 0, 0421983 MAE 0, 156276 MAPE ME -0, 00121477 MPE ARIMA Model Summary Parameter Estimate Stnd. Error t P-value ---------------------------------------------------------------------------- AR(1) 0, 366778 0, 25729 4, 42554 0, 000568 ---------------------------------------------------------------------------- Backforecasting: yes Estimated white noise variance = 0, 0423153 with 13 degrees of freedom Estimated white noise standard deviation = 0, 205707 Number of iterations: 1 Рисунок 3.5.17 − Панель сводных итогов авторегрессии Итоги авторегрессии показывают, что оценка авторегрессионнного параметра значима по Следовательно, для прогнозирования обеспеченности жильем можно использовать авторегрессию первого порядка. Она имеет вид
Вызовем панель Tabular Options (табличных опций) На рисунке 3.5.18. изображена только часть информации панели Forecast Table (Таблица прогноза). Представленные результаты свидетельствуют, что прогноз остатков увеличивается с -0, 034 до -0, 002. В целом остатки отрицательно влияют на тренд.
Forecast Table for RESIDUALS
Model: ARIMA(1, 0, 0) Lower 95, 0% Upper 95, 0% Period Forecast Limit Limit ------------------------------------------------------------------------------ 2006 -0, 033 -0, 478 0, 411 2007 -0, 012 -0, 486 0, 461 2008 -0, 005 -0, 482 0, 473 2009 -0, 002 -0, 479 0, 476 ------------------------------------------------------------------------------ Рисунок 3.5.18 − Прогноз остатков Итоги прогнозирования обеспеченности жильем населения Хабаровского края сведены в таблице 3.5.1. Таблица 3.5.1 − Результаты прогнозирования обеспеченности жильем население Хабаровского края
Результаты прогнозирования свидетельствуют, что объединенный прогноз обеспеченности жильем меньше прогноза по экспоненциальному тренду из-за отрицательного прогноза остатков. За прогнозируемые годы обеспеченность жильем вырастет на 6, 1% и к 2009 году достигнет 21, 21 м2. Контрольные вопросы к разделу 3 1. Охарактеризуйте основные типы кривых роста, наиболее часто используемые на практике при построении трендовых моделей одномерных временных рядов. 2.Назовите важнейшие характеристики точности моделей прогнозирования. 3. Каким образом определяется значение критической статистики в тесте Дарбина − Уотсона? 4. Опишите алгоритм проверки гипотезы об отсутствии автокорреляции первого порядка в остатках модели с помощью критерия Дарбина− Уотсона. 5. Какова интерпретация коэффициентов линейной трендовой модели? Популярное:
|
Последнее изменение этой страницы: 2017-03-11; Просмотров: 742; Нарушение авторского права страницы





 , откроется окно Save Results Options (сохранение результатов анализа) (рисунок 3.5.9) Отметим флажком Residual (остатки) и нажмем OK.
, откроется окно Save Results Options (сохранение результатов анализа) (рисунок 3.5.9) Отметим флажком Residual (остатки) и нажмем OK. 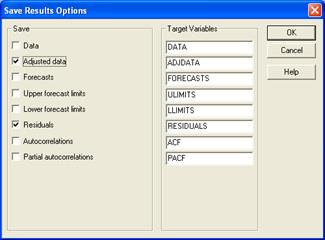




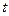 -критерию. Фактический критерий Стьюдента существенно больше табличного, так как
-критерию. Фактический критерий Стьюдента существенно больше табличного, так как 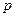 -значение равно 0, 000 568.
-значение равно 0, 000 568.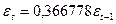
 и установимфлажокв поле Forecast Table (Таблица прогноза) (рисунок 3.5.18).
и установимфлажокв поле Forecast Table (Таблица прогноза) (рисунок 3.5.18).