
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Содержательная классификация моделей ⇐ ПредыдущаяСтр 3 из 3
В работе Пайерлса[17] дана классификация математических моделей, используемых в физике и, шире, в естественных науках. В книге А. Н. Горбаня и Р. Г. Хлебопроса[18] эта классификация проанализирована и расширена. Эта классификация сфокусирована, в первую очередь, на этапе построения содержательной модели. Гипотеза Модели первого типа — гипотезы («такое могло бы быть»), «представляют собой пробное описание явления, причем автор либо верит в его возможность, либо считает даже его истинным». По Пайерлсу это, например, модель Солнечной системы по Птолемею и модель Коперника (усовершенствованная Кеплером), модель атома Резерфорда и модель Большого Взрыва. Модели-гипотезы в науке не могут быть доказаны раз и навсегда, можно лишь говорить об их опровержении или неопровержении в результате эксперимента[19]. Если модель первого типа построена, то это означает, что она временно признаётся за истину и можно сконцентрироваться на других проблемах. Однако это не может быть точкой в исследованиях, но только вре́ менной паузой: статус модели первого типа может быть только вре́ менным. Феноменологическая модель Второй тип — феноменологическая модель («ведем себя так, как если бы…»), содержит механизм для описания явления, хотя этот механизм недостаточно убедителен, не может быть достаточно подтверждён имеющимися данными или плохо согласуется с имеющимися теориями и накопленным знанием об объекте. Поэтому феноменологические модели имеют статус вре́ менных решений. Считается, что ответ всё ещё неизвестен, и необходимо продолжить поиск «истинных механизмов». Ко второму типу Пайерлс относит, например, модели теплорода и кварковую модель элементарных частиц. Роль модели в исследовании может меняться со временем, может случиться так, что новые данные и теории подтвердят феноменологические модели и те будут повышены до статуса гипотезы. Аналогично новое знание может постепенно прийти в противоречие с моделями-гипотезами первого типа, и те могут быть переведены во второй. Так, кварковая модель постепенно переходит в разряд гипотез; атомизм в физике возник как временное решение, но с ходом истории перешёл в первый тип. А вот модели эфира проделали путь от типа 1 к типу 2, а сейчас находятся вне науки. Идея упрощения очень популярна при построении моделей. Но упрощение бывает разным. Пайерлс выделяет три типа упрощений в моделировании. Приближение Третий тип моделей — приближения («что-то считаем очень большим или очень малым»). Если можно построить уравнения, описывающие исследуемую систему, то это не значит, что их можно решить даже с помощью компьютера. Общепринятый прием в этом случае — использование приближений (моделей типа 3). Среди них модели линейного отклика. Уравнения заменяются линейными. Стандартный пример — закон Ома. Если мы используем модель идеального газа для описания достаточно разреженных газов, то это — модель типа 3 (приближение). При более высоких плотностях газа тоже полезно представлять себе более простую ситуацию с идеальным газом для качественного понимания и оценок, но тогда это уже тип 4. Упрощение Четвёртый тип — упрощение («опустим для ясности некоторые детали»), в такой отбрасываются детали, которые могут заметно и не всегда контролируемо повлиять на результат. Одни и те же уравнения могут служить моделью типа 3 (приближение) или 4 (опустим для ясности некоторые детали) — это зависит от явления, для изучения которого используется модельПримеры: применение модели идеального газа к неидеальному, уравнение состояния Ван-дер-Ваальса, большинство моделей физики твердого тела, жидкостей и ядерной физики. Путь от микроописания к свойствам тел (или сред), состоящих из большого числа частиц, очень длинен. Приходится отбрасывать многие детали. Это приводит к моделям четвёртого типа. Эвристическая модель Пятый тип — эвристическая модель («количественного подтверждения нет, но модель способствует более глубокому проникновению в суть дела»), такая модель сохраняет лишь качественное подобие реальности и даёт предсказания только «по порядку величины». Типичный пример — приближение средней длины свободного пробега в кинетической теории. Оно даёт простые формулы для коэффициентов вязкости, диффузии, теплопроводности, согласующиеся с реальностью по порядку величины. Но при построении новой физики далеко не сразу получается модель, дающая хотя бы качественное описание объекта — модель пятого типа. В этом случае часто используют модель по аналогии, отражающую действительность хоть в какой-нибудь черте. Аналогия Тип шестой — модель-аналогия («учтём только некоторые особенности»). Пайерлс приводит историю использования аналогий в первой статье Гейзенберга о природе ядерных сил[20]. Мысленный эксперимент Седьмой тип моделей — мысленный эксперимент («главное состоит в опровержении возможности»). Такой тип моделирования часто использовался Эйнштейном, в частности, один из таких экспериментов привёл к построению специальной теории относительности. Предположим, что в классической физике мы движемся за световой волной со скоростью света. Мы будем наблюдать периодически меняющееся в пространстве и постоянное во времени электромагнитное поле. Согласно уравнениям Максвелла, этого быть не может. Отсюда Эйнштейн заключил: либо законы природы меняются при смене системы отсчёта, либо скорость света не зависит от системы отсчёта, и выбрал второй вариант.
Вопрос Формализация Формализация информации о некотором объекте — это ее отражение в определенной форме.Можно еще сказать так: формализация — это сведение содержания к форме. Формулы, описывающие физические процессы, — это формализация этих процессов. Радиосхема электронного устройства — это формализация функционирования этого устройства. Ноты, записанные на нотном листе, — это формализация музыки и т.п. Формализованная информационная модель — это определенные совокупности знаков (символов), которые существуют отдельно от объекта моделирования, могут подвергаться передаче и обработке. Реализация информационной модели на компьютере сводится к ее формализации в форматы данных, с которыми " умеет" работать компьютер. Но можно говорить и о другой стороне формализации применительно к компьютеру. Программа на определенном языке программирования есть формализованное представление процесса обработки данных. Это не противоречит приведенному выше определению формализованной информационной модели как совокупности знаков, поскольку машинная программа имеет знаковое представление. Компьютерная программа — это модель деятельности человека по обработке информации, сведенная к последовательности элементарных операций, которые умеет выполнять процессор ЭВМ. Поэтому программирование на ЭВМ есть формализация процесса обработки информации. А компьютер выступает в качестве формального исполнителя программы. Вопрос Этапы и цели компьютерного моделирования К основным этапам компьютерного моделирования относятся:
Вопрос Статистическая гипотеза — предположение о виде распределения и свойствах случайной величины, которое можно подтвердить или опровергнуть применением статистических методов к данным выборки[1]. Статистический критерий — строгое математическое правило, по которому принимается или отвергается та или иная статистическая гипотеза с известным уровнем значимости. Построение критерия представляет собой выбор подходящей функции от результатов наблюдений (ряда эмпирически полученных значений признака), которая служит для выявления меры расхождения между эмпирическими значениями и гипотетическими. Виды критериев Статистические критерии подразделяются на следующие категории: · Критерии значимости. Проверка на значимость предполагает проверку гипотезы о численных значениях известного закона распределения: {\displaystyle H_{0}: \quad a=a_{0}} — нулевая гипотеза. {\displaystyle H_{1}: \quad a> a_{0}\quad (a< a_{0})} или {\displaystyle a\neq a_{0}} — конкурирующая гипотеза. · Критерии согласия. Проверка на согласие подразумевает проверку предположения о том, что исследуемая случайная величина подчиняется предполагаемому закону. Критерии согласия можно также воспринимать, как критерии значимости. Критериями согласия являются: 1. Критерий Пирсона 2. Критерий Колмогорова 3. Критерий Андерсона-Дарлинга 4. Критерий Крамера — Мизеса — Смирнова 5. Критерий согласия Купера 6. Z-тест 7. Критерий Жака-Бера (англ.) 8. Критерий Шапиро-Уилка (англ.) 9. График нормальности (англ.) — не столько критерий, сколько графическая иллюстрация: точки специально построенного графика должны лежать почти на одной прямой. Вопрос Статистическая методология — это система приемов, способов и методов, направленных на изучение количественных закономерностей, проявляющихся в структуре, динамике и взаимосвязях социально-экономических явлений. Общей основой статистического метода познания является диалектический метод, согласно которому общественные явления и процессы рассматриваются в развитии взаимной связи и причинной обусловленности. Статистика опирается на такие диалектические категории, как количество и качество, причинность и закономерность, индивидуальное и общее. В процессе исследования статистика может использовать и другие общенаучные методы: § Аналогия — перенесение свойств одного объекта на другой. § Гипотезы — научно обоснованные предположения о возможных причинных связях между явлениями. Статистическое исследование Статистические методы используются комплексно. Применение конкретных методов предопределяется поставленными задачами и зависит от характера исходной информации. Статистическое исследование состоит из трех стадий: § Сбор первичной статистической информации § Сводка и группировка § Обработка статистических показателей Наблюдение. С помощью массового научно обоснованного наблюдения получают первичную информацию об отдельных фактах изучаемого явления. При этом применяют метод массового статистического наблюдения, обеспечивающий полноту и репрезентативность полученной информации. Сводкаигруппировкаматериала. Представляет собой расчленение всей массы случаев на однородные группы и подгруппы, подсчет итогов в каждой группе и оформление полученных результатов в виде статистических таблиц. После проведения группировки приступают к обобщению данных наблюдения по выделенным частям и целому. Эта работа носит название сводка. Методы группировки различаются в зависимости от задач исследования. Обработка статистических показателей. Анализ результатов для получения обоснованных выводов о состоянии изучаемого объекта и закономерностях его развития. Для этого применяются обобщающие статистические показатели: абсолютные, относительные и средние величины, вариации и статистические индексы. Выявляются причинно-следственные связи, закономерности, оценивается эффективность и возможности экономических и социальных явлений. Вопрос Математи́ ческое ожида́ ние — среднее значение случайной величины (распределение вероятностей случайной величины, рассматривается в теории вероятностей)[1]. Вопрос Статистическое Среднее - СТАТИСТИЧЕСКОЕ СРЕДНЕЕ, в статистике - число, результат вычислений, которое дает типичное представление обо всем множестве чисел. Эта величина представляет собой АРИФМЕТИЧЕСКОЕ СРЕДНЕЕ - Вопрос Ранговая корреляция Силу связи случайных величин можно оценивать, сравнивая не только численные значения этих случайных величин, но и соответствующие им ранги. Заданы две выборки Выборкам
Корреляция последовательностей рангов Вопрос Дисперсионный анализ — метод в математической статистике, направленный на поиск зависимостей в экспериментальных данных путём исследования значимости различий в средних значениях[1][2]. В отличие от t-критерия позволяет сравнивать средние значения трёх и более групп. Разработан Р. Фишером для анализа результатов экспериментальных исследований. В литературе также встречается обозначение ANOVA (от англ. ANalysis Of VAriance)[3]. В зависимости от типа и количества переменных различают: · однофакторный и многофакторный дисперсионный анализ (одна или несколько независимых переменных); · одномерный и многомерный дисперсионный анализ (одна или несколько зависимых переменных); · дисперсионный анализ с повторными измерениями (для зависимых выборок); · дисперсионный анализ с постоянными факторами, случайными факторами, и смешанные модели с факторами обоих типов; Исходными положениями дисперсионного анализа являются · нормальное распределение зависимой переменной; · равенство дисперсий в сравниваемых генеральных совокупностях; · случайный и независимый характер выборки. Вопрос Мо́ да — значение во множестве наблюдений, которое встречается наиболее часто. (Мода = типичность.) Иногда в совокупности встречается более чем одна мода (например: 6, 2, 6, 6, 8, 9, 9, 9, 10; мода = 6 и 9). В этом случае можно сказать, что совокупность мультимодальна. Из структурных средних величин только мода обладает таким уникальным свойством. Как правило мультимодальность указывает на то, что набор данных не подчиняется нормальному распределению. Мода как средняя величина употребляется чаще для данных, имеющих нечисловую природу. Среди перечисленных цветов автомобилей — белый, черный, синий металлик, белый, синий металлик, белый — мода будет равна белому цвету. При экспертной оценке с её помощью определяют наиболее популярные типы продукта, что учитывается при прогнозе продаж или планировании их производства. Для интервального ряда мода определяется по формуле: Мо = XMо + hМо * (fМо - fМо-1): ((fМо - fМо-1) + (fМо - fМо+1)), здесь XMо — левая граница модального интервала, hМо — длина модального интервала, fМо-1 — частота премодального интервала, fМо — частота модального интервала, fМо+1 — частота послемодального интервала[1]. Модой абсолютно непрерывного распределения называют любую точку локального максимума плотности распределения. Для дискретных распределений модой считают любое значение ai, вероятность которого pi больше, чем вероятности соседних значений.[2]. Вопрос Диспе́ рсия случа́ йной величины́ — мера разброса данной случайной величины, то есть её отклонения от математического ожидания. Обозначается {\displaystyle D[X]} в русской литературе и {\displaystyle \operatorname {Var} (X)} (англ. variance) в зарубежной. В статистике часто употребляется обозначение {\displaystyle \sigma _{X}^{2}} или {\displaystyle \displaystyle \sigma ^{2}}. Квадратный корень из дисперсии, равный {\displaystyle \displaystyle \sigma }, называется среднеквадрати́ ческим отклоне́ нием, станда́ ртным отклоне́ нием или стандартным разбросом. Стандартное отклонение измеряется в тех же единицах, что и сама случайная величина, а дисперсия измеряется в квадратах этой единицы измерения. Из неравенства Чебышёва следует, что вероятность того, что случайная величина отстоит от своего математического ожидания более чем на {\displaystyle k} стандартных отклонений, составляет менее {\displaystyle 1/k^{2}}. В специальных случаях оценка может быть усилена. Так, например, как минимум в 95 % случаев случайная величина, имеющая нормальное распределение, удалена от её среднего не более чем на два стандартных отклонения, а в примерно 99, 7 % — не более чем на три. Пусть {\displaystyle X} — случайная величина, определённая на некотором вероятностном пространстве. Тогда дисперсией называется {\displaystyle D[X]=M\left[(X-M[X])^{2}\right]} где символ {\displaystyle M} обозначает математическое ожидание · Дисперсия любой случайной величины неотрицательна: {\displaystyle D[X]\geqslant 0; } · Если дисперсия случайной величины конечна, то конечно и её математическое ожидание; · Если случайная величина равна константе, то её дисперсия равна нулю: {\displaystyle D[a]=0.} Верно и обратное: если {\displaystyle D[X]=0, } то {\displaystyle X=M[X]} почти всюду; · Дисперсия суммы двух случайных величин равна: {\displaystyle D[X+Y]=D[X]+D[Y]+2\, {\text{cov}}(X, Y)}, где {\displaystyle {\text{cov}}(X, Y)} — их ковариация; · Для дисперсии произвольной линейной комбинации нескольких случайных величин имеет место равенство: {\displaystyle D\left[\sum _{i=1}^{n}c_{i}X_{i}\right]=\sum _{i=1}^{n}c_{i}^{2}D[X_{i}]+2\sum _{1\leqslant i< j\leqslant n}c_{i}c_{j}\, {\text{cov}}(X_{i}, X_{j})}, где {\displaystyle c_{i}\in \mathbb {R} }; · В частности, {\displaystyle D[X_{1}+...+X_{n}]=D[X_{1}]+...+D[X_{n}]} для любых независимых или некоррелированных случайных величин, так как их ковариации равны нулю; · {\displaystyle D\left[aX\right]=a^{2}D[X]; }{\displaystyle D\left[-X\right]=D[X]; }{\displaystyle D\left[X+b\right]=D[X].} Вопрос Медиа́ на (от лат. mediā na — середина) в математической статистике — число, характеризующее выборку (например, набор чисел). Если все элементы выборки различны, то медиана — это такое число выборки, что ровно половина из элементов выборки больше него, а другая половина меньше него. В более общем случае медиану можно найти, упорядочив элементы выборки по возрастанию или убыванию и взяв средний элемент. Например, выборка {11, 9, 3, 5, 5} после упорядочивания превращается в {3, 5, 5, 9, 11} и её медианой является число 5. Если в выборке чётное число элементов, медиана может быть не определена однозначно: для числовых данных чаще всего используют полусумму двух соседних значений (то есть медиану набора {1, 3, 5, 7} принимают равной 4), подробнее см. ниже. Также медиану можно определить для случайных величин: в этом случае она делит пополам распределение. Грубо говоря, медианой случайной величины является такое число, что вероятность получить значение случайной величины справа от него равна вероятности получить значение слева от него (и они обе равны 1/2); более точное определение см. ниже. Можно также сказать, что медиана является 50-м персентилем, 0, 5-квантилем или вторым квартилем выборки или распределения. Вопрос Среднеквадрати́ ческое отклоне́ ние (синонимы: среднее квадрати́ ческое отклоне́ ние, среднеквадрати́ чное отклоне́ ние, квадрати́ чное отклоне́ ние; близкие термины: станда́ ртное отклоне́ ние, станда́ ртный разбро́ с) — в теории вероятностей и статистике наиболее распространённый показатель рассеивания значений случайной величины относительно её математического ожидания. При ограниченных массивах выборок значений вместо математического ожидания используется среднее арифметическое совокупности выборок. Среднеквадратическое отклонение измеряется в единицах измерения самой случайной величины и используется при расчёте стандартной ошибки среднего арифметического, при построении доверительных интервалов, при статистической проверке гипотез, при измерении линейной взаимосвязи между случайными величинами. Определяется как квадратный корень из дисперсии случайной величины. Среднеквадратическое отклонение: {\displaystyle \sigma ={\sqrt {{\frac {1}{n}}\sum _{i=1}^{n}\left(x_{i}-{\bar {x}}\right)^{2}}}.} Популярное:
|
Последнее изменение этой страницы: 2017-03-03; Просмотров: 971; Нарушение авторского права страницы
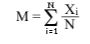
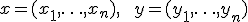 , измеренные в ранговых шкалах. Примером выборки, измеренной в ранговых шкалах, могут служить экспертные оценки: эксперт проставляет оценки от 1 до 5 просмотренным
, измеренные в ранговых шкалах. Примером выборки, измеренной в ранговых шкалах, могут служить экспертные оценки: эксперт проставляет оценки от 1 до 5 просмотренным  фильмам.
фильмам. и
и  соответствуют последовательности рангов:
соответствуют последовательности рангов:  , где
, где  — ранг
— ранг  -го объекта в вариационном ряду выборки
-го объекта в вариационном ряду выборки 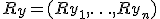 , где
, где  — ранг
— ранг  и
и  называется ранговой корреляцией.
называется ранговой корреляцией.