|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Общие свойства поля (зависят от типа данных) ⇐ ПредыдущаяСтр 5 из 5
3. Размер поля (FildSize) задает максимальный размер данных, сохраняемых в поле. Для поля с типом данных Текстовый задается размер от 1 до 255 байтов (по умолчанию 50 байт). Для поля с типом данных Числовой можно задать следующий размер поля: – Байт для целых чисел от 0 до 255 – 1 байт – Целое для целых чисел от -32 768 до + 32 767 – 2 байта занимает – Длинное целое для целых чисел от - 2 147 483 648 до + 2 147 483 647 – занимает 4 байта – Одинарное с плавающей точкой 4 байта для чисел от – Двойное с плавающей точкой 8 байт для чисел от – Действительное(Decimal) для целых от
Рекомендуется задавать минимальный размер поля, необходимый для сохраняемых значений. Требует меньше памяти, обработка данных выполнятся быстрее. Изменение размеров поля с большего на меньший может привести к их искажению или полной потере. 4. Формат поля (Format) является форматом отображения заданного типа данных и задает правила представления данных при выводе их на экран или печать. 5. Число десятичных знаков (Dicimal Places) задает число знаков после запятой (от 0 до 15). Это свойство влияет на количество десятичных знаков, отображаемых на экране, и не влияет на число сохраняемых в памяти. 6. Подпись поля (Caption) задает текст, который выводится в таблицах. 7. Условие на значение (Validation Rule) позволяет осуществлять контроль ввода, задает ограничения на вводимые значения, при нарушении условий запрещает ввод и выводит текст, заданный свойством сообщения об ошибке(Validation Text). 8. Сообщение об ошибке задает текст сообщения, выводимый на экран при нарушении ограничений, заданных свойством условие на значение.
Классификация БД По технологии обработки данных различают: 1) Централизованную БД. Она хранится в памяти одной вычислительной системы. Если эта вычислительная система является компонентом сети. Возможен распределенный доступ к такой базе. Такой способ использования БД часто применяют в локальных сетях ПК. 2) Распределенную БД. Она состоит из нескольких, возможно повторяющихся или дублирующих друг друга частей, хранимых в различных машинах вычислительной сети. Работа в такой базе осуществляется с помощью системы управления распред-й БД (СУБДР). По способу доступа к данным разделяются на БД с локальным доступом и БД с удаленным(сетевым) доступом. Системы централизованных БД с удаленным (сетевым) доступом предполагают различную архитектуру подобных систем: 1. Файл – сервер. Архитектура систем БД с сетевым доступом предполагает выделение 1 из машин сети в качестве центральной (сервер файлов). На такой машине хранится совместно используемая централизованная БД. Все другие машины сети выполняют функции рабочих станций, с помощью которых поддерживается доступ пользователей системы к централизованной БД. Файлы БД в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится обработка. При большой интенсивности доступа к одним и тем же данным производительность информационной системы падает. Пользователи могут создавать также на рабочих станциях локальные БД, которые используются ими монопольно.
2. Клиент – сервер. В этой концепции подразумевается, что помимо хранения централизованной БД центральная машина (сервер БД) должна обеспечивать выполнение основного объема обработки данных. Запрос на данные, выдаваемые клиентом (раб.ст.) порождает поиск и извлечение данных на сервере. Извлеченные данные (но не файлы) транспортируются по сети к клиенту. Спецификой архитектуры клиент – сервер является использование языка запросов SQL.
рабочие станции
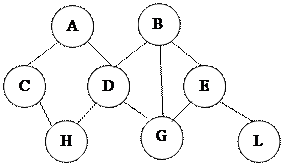
Виды моделей данных (МД) Ядром любой БД является модель данных. Модель данных представляет собой множество структур данных, ограничений целостности и операций манипулирования данными. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними. Модель данных – совокупность структур данных и операций их обработки. СУБД основывается на использовании иерархической, сетевой или реляционной модели данных, на комбинации этих моделей или на некотором их подмножестве. Рассмотрим 3 основных типа МД: 1) Иерархическая МД представляет совокупность элементов, связанных между собой по определенным правилам. Объекты, связанные иерархическими отношениями образуют ориентированный граф(перевернутое дерево). Основные понятия – узел (элемент), уровень, связь.
Ур.1 Ур.3
Узел – совокупность атрибутов данных, описывающих некоторый объект. Узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на 2, 3 и т.д. уровнях. Количество деревьев в БД определяется числом корневых записей. К каждой записи в БД существует только один (иерархический) путь от корневой записи. Например, для записи
2) Сетевая модель данных В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом.
3) Реляционная МД ориентирована на организацию данных в виде двумерных таблиц, и возможность использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных.
Реляционная таблица представляет собой двумерный массив и обладает следующими свойствами: – каждый элемент таблицы – один элемент данных – все столбцы однородные, т.е. все элементы в столбце имеют одинаковый тип данных и размер – каждый столбец имеет уникальное имя – одинаковые строки в таблице отсутствуют – порядок следования строк и столбцов может быть произвольным
БД состоящая из реляционных таблиц называют Реляционной БД. В дальнейшем мы будем рассматривать только такие БД.
В БД совокупности данных представляются в виде простой двумерной таблицы. Примером может служить обыкновенный телефонный справочник.
TELEFON Словарь
Простейшая двумерная таблица, состоящая из одиночных строк, называется реляционной таблицей. Каждая таблица состоит из фиксированного количества столбцов и переменного количества строк. Описание столбцов, составляемое разработчиком, называется макетом таблицы. Каждый столбец – конкретное поле (данное) Каждая строка таблицы называется записью Каждое поле может входить в несколько таблиц Каждая запись в таблице должна иметь первичный ключ, т.е. идентификатор ( или адрес), значение которого однозначно определяет эту и только эту запись. Ключ может состоять из одного поля, тогда его называют простым или из нескольких полей, тогда его называют составным ключом.
Первичный ключ должен обладать свойствами: 1. Однозначная идентификация записи, т.е. запись должна однозначно определяться значением ключа. 2. Отсутствие избыточности: никакое поле нельзя удалить из ключа, не нарушая при этом свойства однозначной идентификации.
Каждое значение первичного ключа в пределах таблицы должно быть уникальным, в противном случае невозможно отличить одну запись от другой! Фамилия никогда не может быть ключом таблицы. Кроме первичного существует вторичный ключ. Его значение может быть неуникальным. Первичный ключ в каждой таблице может быть только один, а вторичных – множество.
Ключи используются при индексировании (упорядочивании) таблиц, для более быстрой и удобной сортировки данных. По определению ключей СУБД автоматически строит индексы, которые представляют собой механизмы быстрого доступа к хранящимся в таблице данным. Индекс – набор указателей на строки таблицы, упорядоченный по значению ключа. Каждый элемент этого набора состоит из двух частей: порядкового номера записи в таблице и значения ключа сортировки. Например, индекс для телефонного справочника – сортировка по возрастанию номеров: Индексы
номер номер телефона в данной записи(по возрастанию) записи в таблице
Вернемся к телефонному справочнику. В таблице «Словарь» мы можем указать те категории, для которых в таблице «Телефон» еще нет записей. Но не имеет смысла включать в таблицу «Телефон» номер, для которого не определена категория в «Словаре». Т.о., «Словарь» - главная таблица, «Телефон» - подчиненная. Главная таблица называется родительской, подчиненная – дочерней. Данные таблицы связаны по полю категория. Категория – первичный ключ для «Словаря». И каждому значению первичного ключа в главной таблице соответствует одна, несколько или ни одной записи в подчиненной таблице. Такое отношение между двумя таблицами называется связью. «Один – ко – многим». Это самый распространенный тип связи в реляционных БД(в телефоне может быть несколько абонентов с категорией ДР, один с РД, или ни одного с МН). Реже встречается отношение «Один – к – одному». В этом случае каждому значению первичного ключа в главной таблице соответствует одна или ни одной записи в подчиненной таблице. В таблице «Словарь» поле категория – первичный ключ, ключ связи в подчиненной таблице. В таблице «Телефон» поле категория – внешний ключ, т.к. ключ связи в главной таблице всегда уникальный первичный ключ. Словарь – главная таблица. В таблице «Телефон» первичный ключ – поле Номер. Логические связи между таблицами в реляционной БД реализуются за счет одинаковых полей в связывающих таблицах. Каждому значению первичного ключа соответствует несколько записей в подчиненной таблице и наоборот.
Популярное:
|
Последнее изменение этой страницы: 2017-03-11; Просмотров: 715; Нарушение авторского права страницы
 до
до  с точностью до 7 знаков.
с точностью до 7 знаков. до
до 
 до
до 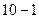 и от
и от  до
до  (.mdb) c точностью до 28 знаков, занимает 12 байт.
(.mdb) c точностью до 28 знаков, занимает 12 байт.


 рабочие станции
рабочие станции - хранение
- хранение - обработка
- обработка

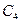 путь проходит через записи А и
путь проходит через записи А и  .
.