
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Базы данных СУБД MS Access 2000
Базы данных СУБД MS Access 2000 Что такое БД?
Вы себе наверняка что – то представляете, когда слышите это словосочетание. Например, БД по металлам и сплавам (металлургия), БД по театральным постановкам (культура), БД пациентов(медицина). Может быть кто – то сможет сформулировать определение?
БД – совокупность связанных между собой сведений о конкретных объектах реального мира в какой – то предметной области. Для чего создаются БД? 1. Дают возможность упорядочивать информацию по различным признакам ( книги по году издания). 2. Дают возможность быстро извлекать выборки с произвольным сочетанием признаков. 3. Возможно постоянное обновление. Для создания БД необходимо структурировать вводимую информации (удобнее искать книгу в библиотеке по алфавиту, а не просто по списку). Структурирование – введение каких то соглашений о способах представления данных. Обычно это таблицы.
Итак, мы сказали, что в БД структурируется информация об объектах. Что такое объект? Объект – нечто, для которого существует название и способ отличать один подобный объект от другого ( город, человек, хим.соединение).
Для описания объектов используют значения атрибутов, т.е. данные. Данные – некоторый показатель (признак, свойство), который характеризует объект и принимает для конкретного экземпляра объекта некоторое значение(текстовое или числовое). В теории СУБД Access «данное» называют полем. Для поля (данного) всегда должно быть определено его имя, тип и формат (дата и время).
Свойства поля 1. Каждое поле должно иметь уникальное имя. Имя не может начинаться с пробела, максимальная длина имени 64 символа. 2. Тип данных определяется значениями, которые предполагается вводить в поле, и операциями, которые будут выполняться с этими значениями. Возможные типы данных: а) Текстовый (Text тип данных по умолчанию) – текст или цифры, не участвующие в расчетах. Число символов в поле не должно превышать 255 символов. б) MEMO – длительный текст (примечание или описание), максимальная длина 64000 символов. в) Числовой(Number) – Числовые данные, используемые в математических вычислениях. г) Денежный(Currency) – денежные значения и числовые данные, используемые в расчетах, проводящихся с точностью до 15 знаков в целой и до 4 знаков в дробной части. При вычислениях предотвращается округление. Длина поля 8 байт. д) Дата/время(Date/Time) – значения даты или времени, относящиеся к годам с 100 по 9999 включительно. Длина поля 8 байт. е) Счетчик(AutoNumber) – тип данных поля, в котором для каждой новой строки автоматически вводятся уникальные целые, последовательно возрастающие на 1 или случайные числа. Значение этого поля нельзя изменить или удалить. Длина поля 4 байта. По умолчанию в поле вводятся последовательные значения. В таблице не может быть более одного поля этого типа. Используется для определения уникального ключа таблицы. ж) Логический(Yes/No) – логические данные, которые могут иметь одно из двух возможных значений Да/Нет; Истина/ложь; Вкл/Выкл. Длина 1 бит. з) Поле объекта OLE ( OLE Object) – объект может быть электр. таблицей MS Excel, документ MS Word, рисунок, звукозапись. Объект может быть связанный или внедренный. Длина поля ограничивается объемом диска. Для полей типа OLE и Memo не допускается сортировка и индексирование.
Внедренный объект OLE сохраняется в файле БД, всегда является доступным, редактируется непосредственно в файле БД средством приложения, в котором объект был создан. Связанный объект OLE сохранятся в файле объекта. Файл объекта можно обновлять независимо от БД. Последние изменения будут выведены на экран при следующем открытии формы (или отчета). Объект можно редактировать и непосредственно в файле БД. Если связанный файл объекта перемещен, необходимо повторно установить связь.
и) Гиперссылка(Hyperlink) – в качестве гиперссылки можно указывать путь к файлу на жестком диске или адрес URL. Максимальная длина 64000 символов. к) Мастер подстановок…(Look up Wizard...) – Мастер строит для поля список значений на основе полей из другой таблицы. Значения в такое поле будут вводиться из одного из полей списка. Тип данных поля определяется типом данных поля списка.
Классификация БД По технологии обработки данных различают: 1) Централизованную БД. Она хранится в памяти одной вычислительной системы. Если эта вычислительная система является компонентом сети. Возможен распределенный доступ к такой базе. Такой способ использования БД часто применяют в локальных сетях ПК. 2) Распределенную БД. Она состоит из нескольких, возможно повторяющихся или дублирующих друг друга частей, хранимых в различных машинах вычислительной сети. Работа в такой базе осуществляется с помощью системы управления распред-й БД (СУБДР). По способу доступа к данным разделяются на БД с локальным доступом и БД с удаленным(сетевым) доступом. Системы централизованных БД с удаленным (сетевым) доступом предполагают различную архитектуру подобных систем: 1. Файл – сервер. Архитектура систем БД с сетевым доступом предполагает выделение 1 из машин сети в качестве центральной (сервер файлов). На такой машине хранится совместно используемая централизованная БД. Все другие машины сети выполняют функции рабочих станций, с помощью которых поддерживается доступ пользователей системы к централизованной БД. Файлы БД в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится обработка. При большой интенсивности доступа к одним и тем же данным производительность информационной системы падает. Пользователи могут создавать также на рабочих станциях локальные БД, которые используются ими монопольно.
2. Клиент – сервер. В этой концепции подразумевается, что помимо хранения централизованной БД центральная машина (сервер БД) должна обеспечивать выполнение основного объема обработки данных. Запрос на данные, выдаваемые клиентом (раб.ст.) порождает поиск и извлечение данных на сервере. Извлеченные данные (но не файлы) транспортируются по сети к клиенту. Спецификой архитектуры клиент – сервер является использование языка запросов SQL.
рабочие станции
Виды моделей данных (МД) Ядром любой БД является модель данных. Модель данных представляет собой множество структур данных, ограничений целостности и операций манипулирования данными. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними. Модель данных – совокупность структур данных и операций их обработки. СУБД основывается на использовании иерархической, сетевой или реляционной модели данных, на комбинации этих моделей или на некотором их подмножестве. Рассмотрим 3 основных типа МД: 1) Иерархическая МД представляет совокупность элементов, связанных между собой по определенным правилам. Объекты, связанные иерархическими отношениями образуют ориентированный граф(перевернутое дерево). Основные понятия – узел (элемент), уровень, связь.
Ур.1 Ур.3
Узел – совокупность атрибутов данных, описывающих некоторый объект. Узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на 2, 3 и т.д. уровнях. Количество деревьев в БД определяется числом корневых записей. К каждой записи в БД существует только один (иерархический) путь от корневой записи. Например, для записи
2) Сетевая модель данных В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом.
3) Реляционная МД ориентирована на организацию данных в виде двумерных таблиц, и возможность использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных.
Реляционная таблица представляет собой двумерный массив и обладает следующими свойствами: – каждый элемент таблицы – один элемент данных – все столбцы однородные, т.е. все элементы в столбце имеют одинаковый тип данных и размер – каждый столбец имеет уникальное имя – одинаковые строки в таблице отсутствуют – порядок следования строк и столбцов может быть произвольным
БД состоящая из реляционных таблиц называют Реляционной БД. В дальнейшем мы будем рассматривать только такие БД.
В БД совокупности данных представляются в виде простой двумерной таблицы. Примером может служить обыкновенный телефонный справочник.
TELEFON Словарь
Простейшая двумерная таблица, состоящая из одиночных строк, называется реляционной таблицей. Каждая таблица состоит из фиксированного количества столбцов и переменного количества строк. Описание столбцов, составляемое разработчиком, называется макетом таблицы. Каждый столбец – конкретное поле (данное) Каждая строка таблицы называется записью Каждое поле может входить в несколько таблиц Каждая запись в таблице должна иметь первичный ключ, т.е. идентификатор ( или адрес), значение которого однозначно определяет эту и только эту запись. Ключ может состоять из одного поля, тогда его называют простым или из нескольких полей, тогда его называют составным ключом.
Первичный ключ должен обладать свойствами: 1. Однозначная идентификация записи, т.е. запись должна однозначно определяться значением ключа. 2. Отсутствие избыточности: никакое поле нельзя удалить из ключа, не нарушая при этом свойства однозначной идентификации.
Каждое значение первичного ключа в пределах таблицы должно быть уникальным, в противном случае невозможно отличить одну запись от другой! Фамилия никогда не может быть ключом таблицы. Кроме первичного существует вторичный ключ. Его значение может быть неуникальным. Первичный ключ в каждой таблице может быть только один, а вторичных – множество.
Ключи используются при индексировании (упорядочивании) таблиц, для более быстрой и удобной сортировки данных. По определению ключей СУБД автоматически строит индексы, которые представляют собой механизмы быстрого доступа к хранящимся в таблице данным. Индекс – набор указателей на строки таблицы, упорядоченный по значению ключа. Каждый элемент этого набора состоит из двух частей: порядкового номера записи в таблице и значения ключа сортировки. Например, индекс для телефонного справочника – сортировка по возрастанию номеров: Индексы
номер номер телефона в данной записи(по возрастанию) записи в таблице
Вернемся к телефонному справочнику. В таблице «Словарь» мы можем указать те категории, для которых в таблице «Телефон» еще нет записей. Но не имеет смысла включать в таблицу «Телефон» номер, для которого не определена категория в «Словаре». Т.о., «Словарь» - главная таблица, «Телефон» - подчиненная. Главная таблица называется родительской, подчиненная – дочерней. Данные таблицы связаны по полю категория. Категория – первичный ключ для «Словаря». И каждому значению первичного ключа в главной таблице соответствует одна, несколько или ни одной записи в подчиненной таблице. Такое отношение между двумя таблицами называется связью. «Один – ко – многим». Это самый распространенный тип связи в реляционных БД(в телефоне может быть несколько абонентов с категорией ДР, один с РД, или ни одного с МН). Реже встречается отношение «Один – к – одному». В этом случае каждому значению первичного ключа в главной таблице соответствует одна или ни одной записи в подчиненной таблице. В таблице «Словарь» поле категория – первичный ключ, ключ связи в подчиненной таблице. В таблице «Телефон» поле категория – внешний ключ, т.к. ключ связи в главной таблице всегда уникальный первичный ключ. Словарь – главная таблица. В таблице «Телефон» первичный ключ – поле Номер. Логические связи между таблицами в реляционной БД реализуются за счет одинаковых полей в связывающих таблицах. Каждому значению первичного ключа соответствует несколько записей в подчиненной таблице и наоборот.
Нормализация отношений Одни и те же данные могут группироваться в таблицы (отношения) различными способами. Группировка атрибутов в отношениях должна быть рациональной, т.е. минимизирующей дублирование данных и упрощающей процедуры их обработки и обновления.
Нормализация отношений – формальный аппарат ограничения на формирование отношений (таблиц), который позволяет устранить дублирование, обеспечивает непр-ть данных, уменьшает трудозатраты на ведение(ввод, корректировку) БД. Нам понадобиться def повторяющихся групп. Пример повторяющихся групп. Пусть разрабатывается БД системы управления персоналом. Разработчик стремиться включить как можно больше информации о работнике. Если включать все в одну основную таблицу, то придется брать число полей по максимально возможному. Допустим, ученый может иметь до 30 премий, в таблицу придется добавить 60 полей. Data N – дата премии и код N – код премии. Следовательно, большая часть значений этих полей в конкретных записях будет «пустой» (или на примере телефонного справочника). Такую def информацию, разную по объему для каждого экземпляра, называют повторяющимися группами. Нормализация таблиц – устранение избыточности данных. Признаки нормализованности таблиц: 1. Каждое поле таблицы неделимо и не содержит повторяющиеся группы. Неделимость поля означает, что содержащиеся в нем значения не должны делиться на более мелкие. 2. Все поля зависят от первичного ключа, т.е. первичный ключ однозначно определяет запись, и не избыточен. Т.е. поля, которые зависят только от части первичного ключа (в случае составного ключа), должны быть выделены в составе отдельных таблиц. 3. Значение любого поля, не входящего в первичный ключ не зависит от значения другого поля, так же не входящего в первичный ключ, т.е. чтобы не было зависимостей между неключевыми полями.
Теория нормализации основывается на наличии той или иной зависимости между полями таблицы. Определены два вида таких зависимостей: функциональные и многозначные. 1а) Функциональная зависимость. Поле В таблицы функционально зависит от поля А той же таблицы в том и только в том случае, когда в любой заданный момент времени для каждого из различных значений поля А обязательно существует только одно из различных значений поля В. Отметим, что здесь допускается, что поля А и В могут быть составными. б) Полная функциональная зависимость. Поле В находится в полной функциональной зависимости от составного поля А, если оно функционально зависит от А и не зависит функционально от любого подмножества поля А. Обозначается функциональная зависимость стрелочками. 2 Многозначная зависимость. Поле А многозначно определяет поле В той же таблицы, если для каждого значения поля А существует хорошо определенное множество соответствующих значений В. Например, таблица Обучение.
В ней есть многозначная зависимость « Дисциплина – Преподаватель»: дисциплина (Информатика) может читаться несколькими преподавателями( Шипиловым и Голованевским). Есть и другая многозначная зависимость «Дисциплина – Учебник»: при изучении Информатики используются учебники «Паскаль для всех» и «язык Си». При этом Преподаватель и Учебник не связаны функциональной зависимостью, что приводит к появлению избыточности( для добавления еще одного учебника придется ввести в таблицу две новых строки). Дело улучшается при замене этой таблицы на две: (Дисциплина – Преподаватель и Дисциплина – Учебник). Таблица находится в первой нормальной форме (1НФ) тогда и только тогда, когда ни одна из ее строк не содержит в любом своем поле одного значения и ни одно из ее ключевых полей не пусто. Преобразование отн-я 1НФ может привести к увеличению реквизитов таблицы и уменьшению ключа. Таблица находится во второй нормальной форме (2НФ), если она удовлетворяет определению 1НФ и все ее поля, не входящие в первичный ключ, связаны полной функциональной зависимостью с первичным ключом. Таблица находится в третьей нормальной форме (3НФ), если она удовлетворяет определению 2НФ и не одно из ее ключевых полей не зависит от любого другого не ключевого поля. Существует 4НФ, 5НФ – это высшие нормальные формы. Здесь они рассматриваться не будут. Для данного случая достаточно 3НФ. Процедура нормализации основывается на том, что единственными функциональными зависимостями в любой таблице должны быть зависимости вида K Возможны два случая: 1. Таблица имеет составной первичный ключ вида, скажем, (К1, К2) и включает также поле F, которое функционально зависит от части этого ключа, например, от К2, но не от полного ключа. В этом случае рекомендуется сформировать другую таблицу, содержащую К2 и F (первичный ключ – К2), и удалить F из первоначальной таблицы: Заменить Т ( К1, К2, F), первичный ключ (К1, К2) Ф3 К2 на Т1 (К1, К2), первичный ключ (К1, К2), и Т2(К2, F), первичный ключ К2. 2. Таблица имеет первичный ключ К, не являющееся ключом поле F1, которое функционально зависит от К, и другое не ключевое поле F2, которое функционально зависит от F1. Формируется другая таблица, содержащая F1 и F2, с первичным ключом F1, и F2 удаляется из первоначальной таблицы: Заменить Т( К1, К2, F), первичный ключ К, Ф3 F1 на Т1(К, F1), первичный ключ К, и Т2 (F1, F2), первичный ключ F1. Для любой заданной таблицы, повторяя применение двух рассмотренных правил, почти во всех практических ситуациях можно получить, в конечном счете, множество таблиц, которые находятся в нормальной форме и, таким образом, не содержат каких-либо функциональных зависимостей вида, отличного от К
С учетом рассмотренных понятий уточним понятие видов связей. Связи между объектами существуют, если логически взаимосвязаны экземпляры из этих информационных объектов. Связи информационных объектов могут быть разного типа: 1) Одно – однозначные связи (1: 1) имеют место, когда каждому экземпляру первого объекта (А) соответствует только один экземпляр второго объекта (В) и наоборот, каждому экземпляру второго объекта (В) соответствует только один экземпляр первого объекта (А).
Такие объекты легко могут быть объединены в один, строение, которого образуется объединением реквизитов обоих исходных объектов, а в качестве ключевого реквизита может быть выбран любой из альтернативных ключей, т.е. ключей исходных объектов.
2) Одно – многозначные связи ( 1: М) характеризуется тем, что каждому экземпляру одного объекта (А) может соответствовать несколько экземпляров другого объекта (В), а каждому экземпляру второго объекта (В) может соответствовать только 1 экземпляр первого объекта (А).
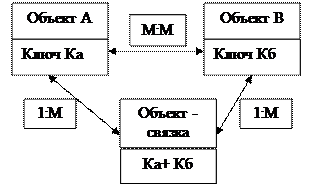
главный инф- й подчиненный информационный объект объект 3) Много - многозначные связи (М: М) Каждому экземпляру одного объекта (А) может соответствовать несколько экземпляров второго объекта (В) и наоборот, каждому экземпляру второго объекта (В) может соответствовать тоже несколько экземпляров первого объекта (А).
Много – многозначные связи не могут непосредственно реализовываться в реальной БД. Поэтому, если такие связи выявлены, может понадобиться их преобразование путем введения дополнительного объекта «связка». Исходные объекты будут связаны с этим объектом одно – многозначными связями. Т.о,, объект – связка является подчиненным в одно – многозначных связях по отношению к каждому из исходных объектов. Объект – связка должен иметь идентификатор, образованный из идентификаторов исходных объектов, например, К При рассмотренном ниже подходе к выделению информационных объектов объект – связка, как правило, выявляется в результате анализа функциональных зависимостей реквизитов. Много – многозначные связи в этом случае не требуют специальной реализации, т.к. осуществляется через объект, выполняющий роль объекта – связки. СУБД Access СУБД – это универсальный комплекс прикладных программ, предназначенных для создания и обслуживания БД, а также обеспечения многоаспектного доступа к данным и их обработки.
Обзор СУБД Системой управления БД называют программную систему, предназначенную для создания на ЭВМ общей БД, используемой для решения множества задач. Подобные системы служат для поддержания БД а актуальном состоянии и обеспечивают эффективный доступ пользователей к содержащимся в ней данным в рамках предоставленных пользователем полномочий. СУБД предназначена для централизованного управления БД в интересах всех работающих в этой системе. По степени универсальности различают два класса СУБД: – системы общего назначения; – специализированные системы. СУБД общего назначения не ориентированы на какую – либо предметную область или на информационные потребности какой – либо группы пользователей. Каждая система такого рода реализуется как программный продукт, способный функционировать на некоторой модели ЭВМ в определенной операционной системе и поставляется многим пользователям как коммерческое изделие. Такие СУБД обладают средствами настройки на работу с конкретной БД. Использование СУБД общего назначения в качестве инструментального средства для создания автоматизированных информационных систем, основанных на технологии БД, позволяет существенно сокращать сроки разработки, экономить трудовые ресурсы. Этим СУБД присущи развитые функциональные возможности и даже определения функциональная избыточность. Специализированные СУБД создаются в редких случаях при невозможности или нецелесообразности использования СУБД общего назначения. СУБД общего назначения – это сложные программные комплексы, предназначенные для выполнения всей совокупности функций, связанных с созданием и эксплуатацией БД информационной системы.
Основные характеристики СУБД: 1. Производительность 2. Обеспечение целостности данных на уровне БД 3. Обеспечение безопасности 4. Работа в многопользовательских средах 5. Импорт – экспорт 6. Доступ к данным SQL 7. Возможности запросов и инструментальные средства разработки прикладных программ
Производительность СУБД Производительность СУБД оценивается: 1) временем выполнения запросов; 2) скоростью поиска информации в неиндексированных полях; 3) временем выполнения операций импортирования БД из других форматов; 4) скоростью создания индексов и выполнения таких массовых операций, как обновление, вставка, удаление данных; 5) максимальным числом параллельных обращений к данным в многопользовательском режиме; 6) временем генерации отчета.
Обеспечение безопасности Средства обеспечения безопасности данных выполняют следующие операции: – шифрование прикладных программ; – шифрование данных; – защиту паролем; – ограничение уровня доступа.
Импорт – экспорт Эта характеристика отражает: 1) возможность обработки СУБД информации, подготовленной доугими программными средствами; 2) возможность использования другими программами данных, сформированных средствами рассматриваемой СУБД.
Объекты Access Таблицы(Tables) создаются для хранения данных об одном информационном объекте модели данных предметной области. Каждое поле содержит одну характеристику объекта предметной области. В записи собраны сведения об 1 экземпляре этого объекта. Запросы(Queries) создаются для выборки нужных данных из одной или нескольких связанных таблиц. Результатом выполнения запроса является таблица, которая может быть использована наряду с другими таблицами БД при обработке данных. Запрос может формироваться в виде запросов по образцу (QBE) или с помощью инструкции SQL – языка структурированных запросов. С помощью запроса можно обновить, удалить добавить данные в таблицы или создать новые таблицы на основе уже существующих. Формы(Forms) являются основным средством создания диалогового интерфейса приложения пользователя. Форма может создаваться для ввода и просмотра взаимосвязанных данных базы на экране в удобном виде. Формы также могут использоваться для создания панелей управления в приложении. Отчеты(Reports) – предназначены для формирования выходных документов, содержащих результаты решения задач пользователя, и вывода их на печать. Страницы(Pages) доступа к данным является диалоговыми Web – страницами, которые поддерживают динамическую связь с БД и позволяют просматривать, редактировать и вводить данные в без., работая в окне приложения Web –страницах. Макросы(Macros) является программой, которая содержит описание последовательности действий, выполняемых при поступлении некоторого события в объекте или элементе управления приложения. Каждое действие реализуется макрокомандой. Создание макросов осуществляется в диалоговом режиме путем выбора нужных макросов и задания параметров, используемых ими при выполнении. Модули(Modules) содержат процедуры на языке VBA/ Могут создаваться процедуры – функции, которые разрабатываются пользователем для реализации нестандартных функций в приложении пользователя, и процедуры для обработки событий.
В Access 2000 для удобства пользователя объекты БД могут объединены в группы по функциональному признаку. Группы содержат ссылки на объекты БД различных типов. Для пользователей, которые совместно работают с приложением, но не всегда имеют возможность подключения к сети, Access предлагает использовании репликации БД. Репликацией называют создание специальных копий – реплик общей БД, с которыми пользователи могут одновременно работать на разных рабочих станциях ( в командировке, дома). Отличие репликаций от обычного копирования файлов БД заключается в том, что для копий БД возможна синхронизация изменений. При выполнении команды меню Сервис/Репликация – создать реплику Access присваивает БД статус основной реплики и создает одну новую реплику. При проведении сеанса синхронизации изменения, сделанные одним пользователем, могут автоматически вноситься в общую реплику и реплику других пользователей, и наоборот. Сеанс синхронизации выполняется с помощью команды Сервис/Репликация/Синхронизация. Если пользователи двух разных реплик по – разному изменяли одну и ту же запись, то при синхронизации реплик создается конфликтная таблица. Для просмотра и исправления конфликтных записей, следует выполнить команду Устранить конфликты. После проведения сеанса синхронизации работа с БД может продолжаться. Обеспечение связной целостности данных означает, что Access при корректировке БД не допускает выполнения следующих операций: 1. В подчиненную таблицу не может быть добавлена запись с не существующим в главной таблице значением ключа связи. 2. В главной таблице нельзя удалить запись, если не удалены связанные с ней записи в подчиненной таблице. 3. Изменение значений ключа связи в записи главной таблице невозможно, если в подчиненной таблице имеются связанные с ней записи. Задание параметров целостности данных возможно только если: 1) Связываемые поля имеют одинаковый тип данных, причем имена полей могут быть различными. 2) Главная таблица связывается с подчиненной по первичному ключу главной таблицы. 3) Главная таблица связывается с подчиненной по первичному ключу главной таблицы. Если для встроенной связи обеспечивается поддержание целостности может задать 2 режима: 1. В режиме каскадного обновления связанных полей при изменении значения поля связи в записи главной таблицы, автоматически меняется значения в соответствующем поле в подчиненных записях. 2. В режиме каскадного удаления связанных записей при удалении записи из главной таблицы будут автоматически удаляться все связанные записи в подчиненных таблицах. Мастера Access Множество мастеров Access позволяет автоматизировать процесс создания таблиц БД, формирование запросов, отчетов и страниц доступа к данным; анализировать таблицы. Практически для любых работ имеется мастер(Wizand), который поможет их выполнить. Мастер подстановок создает в поле таблицы раскрывающийся список значений из поля другой таблицы для выбора и ввода нужного значения. Мастера запросов позволяют создавать простые запросы на выборку или запросы на выборку, в которых выполняются групповые операции над данными из одной или нескольких таблиц. Мастер перекрестных запросов формирует из взаимосвязанных таблиц или запросов БД таблиц, подобную электронной, в которой одно поле используется. Мастера по созданию форм и отчетов упрощают и ускоряют процесс создания однотабличных и многотабличных форм и отчетов, в диалоге с мастером пользователю достаточно выбрать таблицы и поля, которые необходимо включить в форму, выбрать источник основной и подчиненной части формы. Мастер условного форматирования устанавливает разные виды форматирования поля в зависимости от значений данных в поле или других формируемых пользователем условий. Мастер кнопок создает командные кнопки – элементы управления в форме и на страницах доступа к данным. Мастер предлагает большой набор действий, которые могут быть выполнены при щелчке на кнопке. Диспетчер кнопочных форм позволяет создать многоуровневую панель управления приложением, которая объединяет его разрозненные компоненты и позволяет структурировать их по функциональному назначению. Мастер по анализу таблиц позволяет выполнить нормализацию данных базы. Мастер разделяет ненормализованную таблицу с дублированными данными на две или несколько таблиц меньшего размера, в которых данные сохраняются без повторений.
В меню Сервис – Анализ наряду с мастера представлены еще: – Анализатор Быстродействия, который позволяет проанализировать основные характеристики объектов БД или БД в целом и выдает рекомендации по их изменениям, для улучшения ее эффективности. – Архивариус, который позволяет создать полное описание любых из объектов БД или базы целиком и распечатать или передать его в Word.
Мастер сводных таблиц вставляет сводную таблицу Excel в форму Access, используя Excel, чтобы создать объект «Сводная таблица» и Access, чтобы создать форму, в которую он вставляет объект. Мастера по импорту таблиц и объектов вызываемые командой. Файл – Внешние данные – Импорт позволяет импортировать их из внешнего файла в текущую БД. Импортировать данные можно из файла другой БД Access, Excel, Paradox. Возможен импорт текстовых файлов и HTML таблиц. Мастер связанных таблиц(Файл – Внешние данные – Связь с таблицами) создает в текущей БД таблицы, связанные с таблицами во внешних файлах, но в отличии от мастера по импорту, не размещает новую таблицу в файле БД, а только устанавливает связь с источником данных этой таблицы. Но связанная таблица доступна до тех пор, пока связь не разрушена по каким – либо причинам. Мастер экспорта (Файл – Экспорт) позволяет экспортировать объекты БД в другие БД, в текстовые файлы, в различные электронные таблицы. Мастер наклеек входит в группу мастеров создания отчетов. Автоматизирует процесс создания почтовых наклеек на основе данных таблицы или запроса и предлагает многочисленные шаблоны наклеек различных типов. Мастер защиты позволяет определить новые параметры защиты БД. Он создает новую незащищенную БД, в которую копируются все объекты из исходной БД, снимает все права, присвоенные членом группы пользователей, и затем защищает БД. ПО завершении работы мастера администратор может присвоить новые права доступа пользователям и группам. Мастер по разделению БД позволяет разделить на два файла, в первый из которых помещаются таблицы, а во второй - формы, отчеты, страницы доступа к данным, макросы и модули. При этом, пользователи, работающие в сети, могут иметь общую БД, в то же время они могут изменять формы, отчеты, и другие объекты, используемые для обработки общих данных по своему усмотрению и иметь индивидуальные приложения. К мастерам еще относят 2 служебные программы: – Convert Database(Преобразовать БД), которая позволяет конвертировать БД из предыдущих версий в текущую версию БД Access, и из текущей версии в предыдущую. Популярное:
|
Последнее изменение этой страницы: 2017-03-11; Просмотров: 842; Нарушение авторского права страницы



 рабочие станции
рабочие станции - хранение
- хранение - обработка
- обработка

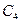 путь проходит через записи А и
путь проходит через записи А и  .
.



 F, где K – первичный ключ, а F – некоторое другое поле. Заметим, что это следует из определения первичного ключа таблицы, в соответствии с которым K
F, где K – первичный ключ, а F – некоторое другое поле. Заметим, что это следует из определения первичного ключа таблицы, в соответствии с которым K 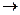 F
F
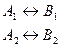


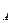 и К
и К 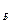 .
.