
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Реляционный подход к построению инфологической моделиСтр 1 из 5Следующая ⇒
Понятие информационного объекта Информационный объект – описание некоторой сущности(реального объекта, явления, события) в виде совокупности логически связанных реквизитов (информационных элементов). И.о. определенного реквизитного состава и структуры образует класс(тип), которому присваивается уникальное имя (или символьное обозначение). Например, Телефон, Словарь. И.о. имеет множество реализаций – экземпляров, каждый из которых представлен совокупностью конкретных значений реквизитов и идентифицируется значением ключа(простого – один реквизит или составной -несколько реквизитов). Остальные реквизиты И.о. являются описательными. При этом одни и те же реквизиты в одних И.о. могут быть ключевыми, а в других – описательными. Например. В И.о. телефон ключом является реквизит Номер, к описательным относятся имя, адрес, Категория. А записи являются экземплярами И.о. Телефон.
Представляется т.о.:
Нормализация отношений Одни и те же данные могут группироваться в таблицы (отношения) различными способами. Группировка атрибутов в отношениях должна быть рациональной, т.е. минимизирующей дублирование данных и упрощающей процедуры их обработки и обновления.
Нормализация отношений – формальный аппарат ограничения на формирование отношений (таблиц), который позволяет устранить дублирование, обеспечивает непр-ть данных, уменьшает трудозатраты на ведение(ввод, корректировку) БД. Нам понадобиться def повторяющихся групп. Пример повторяющихся групп. Пусть разрабатывается БД системы управления персоналом. Разработчик стремиться включить как можно больше информации о работнике. Если включать все в одну основную таблицу, то придется брать число полей по максимально возможному. Допустим, ученый может иметь до 30 премий, в таблицу придется добавить 60 полей. Data N – дата премии и код N – код премии. Следовательно, большая часть значений этих полей в конкретных записях будет «пустой» (или на примере телефонного справочника). Такую def информацию, разную по объему для каждого экземпляра, называют повторяющимися группами. Нормализация таблиц – устранение избыточности данных. Признаки нормализованности таблиц: 1. Каждое поле таблицы неделимо и не содержит повторяющиеся группы. Неделимость поля означает, что содержащиеся в нем значения не должны делиться на более мелкие. 2. Все поля зависят от первичного ключа, т.е. первичный ключ однозначно определяет запись, и не избыточен. Т.е. поля, которые зависят только от части первичного ключа (в случае составного ключа), должны быть выделены в составе отдельных таблиц. 3. Значение любого поля, не входящего в первичный ключ не зависит от значения другого поля, так же не входящего в первичный ключ, т.е. чтобы не было зависимостей между неключевыми полями.
Теория нормализации основывается на наличии той или иной зависимости между полями таблицы. Определены два вида таких зависимостей: функциональные и многозначные. 1а) Функциональная зависимость. Поле В таблицы функционально зависит от поля А той же таблицы в том и только в том случае, когда в любой заданный момент времени для каждого из различных значений поля А обязательно существует только одно из различных значений поля В. Отметим, что здесь допускается, что поля А и В могут быть составными. б) Полная функциональная зависимость. Поле В находится в полной функциональной зависимости от составного поля А, если оно функционально зависит от А и не зависит функционально от любого подмножества поля А. Обозначается функциональная зависимость стрелочками. 2 Многозначная зависимость. Поле А многозначно определяет поле В той же таблицы, если для каждого значения поля А существует хорошо определенное множество соответствующих значений В. Например, таблица Обучение.
В ней есть многозначная зависимость « Дисциплина – Преподаватель»: дисциплина (Информатика) может читаться несколькими преподавателями( Шипиловым и Голованевским). Есть и другая многозначная зависимость «Дисциплина – Учебник»: при изучении Информатики используются учебники «Паскаль для всех» и «язык Си». При этом Преподаватель и Учебник не связаны функциональной зависимостью, что приводит к появлению избыточности( для добавления еще одного учебника придется ввести в таблицу две новых строки). Дело улучшается при замене этой таблицы на две: (Дисциплина – Преподаватель и Дисциплина – Учебник). Таблица находится в первой нормальной форме (1НФ) тогда и только тогда, когда ни одна из ее строк не содержит в любом своем поле одного значения и ни одно из ее ключевых полей не пусто. Преобразование отн-я 1НФ может привести к увеличению реквизитов таблицы и уменьшению ключа. Таблица находится во второй нормальной форме (2НФ), если она удовлетворяет определению 1НФ и все ее поля, не входящие в первичный ключ, связаны полной функциональной зависимостью с первичным ключом. Таблица находится в третьей нормальной форме (3НФ), если она удовлетворяет определению 2НФ и не одно из ее ключевых полей не зависит от любого другого не ключевого поля. Существует 4НФ, 5НФ – это высшие нормальные формы. Здесь они рассматриваться не будут. Для данного случая достаточно 3НФ. Процедура нормализации основывается на том, что единственными функциональными зависимостями в любой таблице должны быть зависимости вида K Возможны два случая: 1. Таблица имеет составной первичный ключ вида, скажем, (К1, К2) и включает также поле F, которое функционально зависит от части этого ключа, например, от К2, но не от полного ключа. В этом случае рекомендуется сформировать другую таблицу, содержащую К2 и F (первичный ключ – К2), и удалить F из первоначальной таблицы: Заменить Т ( К1, К2, F), первичный ключ (К1, К2) Ф3 К2 на Т1 (К1, К2), первичный ключ (К1, К2), и Т2(К2, F), первичный ключ К2. 2. Таблица имеет первичный ключ К, не являющееся ключом поле F1, которое функционально зависит от К, и другое не ключевое поле F2, которое функционально зависит от F1. Формируется другая таблица, содержащая F1 и F2, с первичным ключом F1, и F2 удаляется из первоначальной таблицы: Заменить Т( К1, К2, F), первичный ключ К, Ф3 F1 на Т1(К, F1), первичный ключ К, и Т2 (F1, F2), первичный ключ F1. Для любой заданной таблицы, повторяя применение двух рассмотренных правил, почти во всех практических ситуациях можно получить, в конечном счете, множество таблиц, которые находятся в нормальной форме и, таким образом, не содержат каких-либо функциональных зависимостей вида, отличного от К
С учетом рассмотренных понятий уточним понятие видов связей. Связи между объектами существуют, если логически взаимосвязаны экземпляры из этих информационных объектов. Связи информационных объектов могут быть разного типа: 1) Одно – однозначные связи (1: 1) имеют место, когда каждому экземпляру первого объекта (А) соответствует только один экземпляр второго объекта (В) и наоборот, каждому экземпляру второго объекта (В) соответствует только один экземпляр первого объекта (А).
Такие объекты легко могут быть объединены в один, строение, которого образуется объединением реквизитов обоих исходных объектов, а в качестве ключевого реквизита может быть выбран любой из альтернативных ключей, т.е. ключей исходных объектов.
2) Одно – многозначные связи ( 1: М) характеризуется тем, что каждому экземпляру одного объекта (А) может соответствовать несколько экземпляров другого объекта (В), а каждому экземпляру второго объекта (В) может соответствовать только 1 экземпляр первого объекта (А).
главный инф- й подчиненный информационный объект объект 3) Много - многозначные связи (М: М) Каждому экземпляру одного объекта (А) может соответствовать несколько экземпляров второго объекта (В) и наоборот, каждому экземпляру второго объекта (В) может соответствовать тоже несколько экземпляров первого объекта (А).
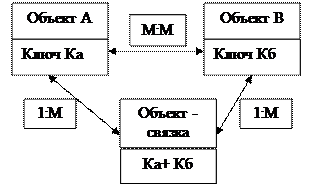
Много – многозначные связи не могут непосредственно реализовываться в реальной БД. Поэтому, если такие связи выявлены, может понадобиться их преобразование путем введения дополнительного объекта «связка». Исходные объекты будут связаны с этим объектом одно – многозначными связями. Т.о,, объект – связка является подчиненным в одно – многозначных связях по отношению к каждому из исходных объектов. Объект – связка должен иметь идентификатор, образованный из идентификаторов исходных объектов, например, К При рассмотренном ниже подходе к выделению информационных объектов объект – связка, как правило, выявляется в результате анализа функциональных зависимостей реквизитов. Много – многозначные связи в этом случае не требуют специальной реализации, т.к. осуществляется через объект, выполняющий роль объекта – связки. Популярное:
|
Последнее изменение этой страницы: 2017-03-11; Просмотров: 749; Нарушение авторского права страницы

 F, где K – первичный ключ, а F – некоторое другое поле. Заметим, что это следует из определения первичного ключа таблицы, в соответствии с которым K
F, где K – первичный ключ, а F – некоторое другое поле. Заметим, что это следует из определения первичного ключа таблицы, в соответствии с которым K 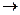 F
F
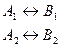
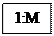


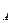 и К
и К 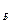 .
.