
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Спектральный, корреляционный и вейвлет-анализ сложных сигналовСтр 1 из 6Следующая ⇒
МИНОБРНАУКИ РОССИИ Федеральное государственное бюджетное образовательное учреждение высшего профессионального образования «Юго-Западный государственный университет» Спектральный, корреляционный и вейвлет-анализ сложных сигналов Курс лекций Специальность 210020 «Конструирование и технология электронных средств» ОСНОВНЫЕ ПОЛОЖЕНИЯ КОРРЕЛЯЦИОННОГО АНАЛИЗА
Понятия корреляции и регрессии появились в середине XIX в. благодаря работам английских статистиков Ф. Гальтона и К. Пирсона. Первый термин произошел от латинского «correlatio» — соотношение, взаимосвязь. Второй термин (от лат. «regressio» — движение назад) введен Ф. Гальтоном, который, изучая зависимость между ростом родителей и их детей, обнаружил явление «регрессии к среднему» — у детей, родившихся у очень высоких родителей, рост имел тенденцию быть ближе к средней величине. В естественных науках часто речь идет о функциональной зависимости (связи), когда каждому значению одной переменной соответствует вполне определенное значение другой (например, скорость свободного падения тела в вакууме в зависимости от времени и т.п.). В экономике в большинстве случаев между переменными величинами существуют зависимости, когда каждому значению одной переменной соответствует не какое-то определенное, а множество возможных значений другой переменной. Иначе говоря, каждому значению одной переменной соответствует определенное (условное) распределение другой переменной. Такая зависимость получила название статистической (или с тохастической, вероятностной ). Возникновение понятия статистической связи обусловливается тем, что зависимая переменная подвержена влиянию ряда неконтролируемых или неучтенных факторов, а также тем, что измерение значений переменных неизбежно сопровождается некоторыми случайными ошибками. Примером статистической связи является зависимость урожайности от количества внесенных удобрений, производительности труда на предприятии от его энерговооруженности и т.п. В силу неоднозначности статистической зависимости между Y и X для исследователя, в частности, представляет интерес усредненная по x схема зависимости, т.е. закономерность в изменении условного математического ожидания МХ(Y) (математического ожидания случайной переменной Y, вычисленного в предположении, что переменная X приняла значение х в зависимости от х. Определение. Корреляционной зависимостью между двумя переменными величинами называется функциональная зависимость между значениями одной из них и условным математическим ожиданием другой. Корреляционная зависимость может быть представлена в виде: Мх(Y)=φ (x) (1) или МY(X)=φ (y) (2) Уравнения (1) и (2) называются модельными уравнениями регрессии (или просто уравнениями регрессии) соответственно Y по X и X по Y, функции φ (х) и ψ (у) - модельными функциями регрессии (или функциями регрессии), а их графики — модельными линиями регрессии (или линиями регрессии). Для отыскания модельных уравнений регрессии, вообще говоря, необходимо знать закон распределения двумерной случайной величины (Х, Y). На практике исследователь, как правило, располагает лишь выборкой пар значений (хi, уi) ограниченного объема. В этом случае речь может идти об оценке (приближенном выражении) по выборке функции регрессии. Такой наилучшей (в смысле метода наименьших квадратов) оценкой является выборочная линия (кривая) регрессии Y по X:
где yх — условная (групповая) средняя переменной Y при фиксированном значении переменной Х= х; b0, b1…bp — параметры кривой. Аналогично определяется выборочная линия (кривая) регрессии Х по Y:
где ху — условная (групповая) средняя переменной X при фиксированном значении переменной Y = у; c0, c1,..., cp — параметры кривой. Уравнения (3), (4) называют также выборочными уравнениями регрессии соответственно Y по X и X по Y. Статистические связи между переменными можно изучать методами корреляционного и регрессионного анализа. Основной задачей регрессионного анализа является установление формы и изучение зависимости между переменными. Основной задачей корреляционного анализа — выявление связи между случайными переменными и оценка ее тесноты.
Линейная парная регрессия Данные о статистической зависимости удобно задавать в виде корреляционной таблицы. Рассмотрим в качестве примера зависимость между суточной выработкой продукции Y (т) и величиной основных производственных фондов X (млн руб.) для совокупности 50 однотипных предприятий (табл. 1). В дальнейшем для краткости там, где это очевидно по смыслу, мы часто и выборочные уравнения (линии) регрессии будем называть просто уравнениями (линиями) регрессии. (В таблице через хi и уj обозначены середины соответствующих интервалов, а ni и nj — соответственно их частоты). Изобразим полученную зависимость графически точками координатной плоскости (рис. 1). Такое изображение статистической зависимости называется полем корреляции. Для каждого значения хi (i = 1, 2,..., l), т.е. для каждой строки корреляционной таблицы вычислим групповые средние
где nij — частоты пар (хi, уj ) и Таблица 1
Рис. 1
Вычисленные групповые средние Аналогично для каждого значения yj (j = 1, 2,..., m) по формуле
вычислим групповые средние х, (см. нижнюю строку корреляционной таблицы), где По виду ломаной можно предположить наличие линейной корреляционной зависимости Y по X между двумя рассматриваемыми переменными, которая графически выражается тем точнее, чем больше объем выборки (число рассматриваемых предприятий) п:
Поэтому уравнение регрессии (3) будем искать в виде:
Найдем формулы расчета неизвестных параметров уравнения линейной регрессии. С этой целью применим метод наименьших квадратов, согласно которому неизвестные параметры Ь0 и Ь1 выбираются таким образом, чтобы сумма квадратов отклонений эмпирических групповых средних
На основании необходимого условия экстремума функции двух переменных S = S(Ь0, b1, ) приравниваем нулю ее частные производные, т.е.
откуда после преобразований получим систему нормальных уравнений для определения параметров линейной регрессии:
Учитывая (5), преобразуем выражения:
Теперь с учетом (7), разделив обе части уравнений (10) на п, получим систему нормальных уравнений в виде:
где соответствующие средние определяются по формулам:
Подставляя значение Ь0 = Коэффициент Ь1 в уравнении регрессии, называемый выборочным коэффициентом регрессии (или просто коэффициентом регрессии) У по X, будем обозначать символом Ьух. Теперь уравнение регрессии Y по X запишется так:
Коэффициент регрессии У по X показывает, на сколько единиц в среднем изменяется переменная Y при увеличении переменной X на одну единицу. Решая систему (12.11), найдем
где
μ — выборочный корреляционный момент или выборочная ковариация:
Рассуждая аналогично и полагая уравнение регрессии (4) линейным, можно привести его к виду:
— выборочный коэффициент регрессии (или просто коэффициент регрессии) X по Y, показывающий, на сколько единиц в среднем изменяется переменная X при увеличении переменной У на одну единицу,
—выборочная дисперсия переменной Y. Так как числители в формулах (17) и (21) для Ьyx и Ьxy совпадают, а знаменатели — положительные величины, то коэффициенты регрессии Ьyx и Ьxy, имеют одинаковые знаки, определяемые знаком μ. Из уравнений регрессии (16) и (20) следует, что коэффициенты Ьyx и 1/Ьxy определяют угловые коэффициенты (тангенсы углов наклона) к оси oх соответствующих линий регрессии, пересекающихся в точке (
Коэффициент корреляции
Перейдем к оценке тесноты корреляционной зависимости. Рассмотрим наиболее важный для практики и теории случай линейной зависимости вида (16). На первый взгляд подходящим измерителем тесноты связи Y от X является коэффициент регрессии Ьуx ибо, как уже отмечено, он показывает, на сколько единиц в среднем изменяется Y, когда X увеличивается на одну единицу. Однако Ьуx зависит от единиц измерения переменных. Например, в полученной ранее зависимости он увеличится в 1000 раз, если величину основных производственных фондов X выразить не в млн руб., а в тыс. руб. Очевидно, что для «исправления» Ьуx как показателя тесноты связи нужна такая стандартная система единиц измерения, в которой данные по различным характеристикам оказались бы сравнимы между собой. Статистика знает такую систему единиц. Эта система использует в качестве единицы измерения переменной ее среднее квадратическое отклонение S. Представим уравнение (16) в эквивалентном виде:
В этой системе величина
показывает, на сколько величин Sy изменится в среднем Y, когда X увеличится на одно Sx Величина r является показателем тесноты связи и называется выборочным коэффициентом корреляции (или просто коэффициентом корреляции). На рис. 2 приведены две корреляционные зависимости переменной Y по X. Очевидно, что в случае а) зависимость между переменными менее тесная и коэффициент корреляции должен быть меньше, чем в случае б), так как точки корреляционного поля а) дальше отстоят от линии регрессии, чем точки поля б). Нетрудно видеть, что r совпадает по знаку с Ьуx (а значит, и с Ьху).
Рис. 2 Если r > 0 (Ьух> 0, Ьху> 0), то корреляционная связь между переменными называется прямой, если r < О (Ьуx < 0, Ьху< 0) — обратной. При прямой (обратной) связи увеличение одной из переменных ведет к увеличению (уменьшению) условной (групповой) средней другой. Учитывая (17), формулу для r представим в виде:
Отсюда видно, что формула для r симметрична относительно двух переменных, т.е. переменные Х и Y можно менять местами. Тогда аналогично (24) можно записать:
Найдя произведение обеих частей равенств (29) и (31), получим
т.е. коэффициент корреляции r переменных X и Y есть средняя геометрическая коэффициентов регрессии, имеющая их знак.
АНАЛОГОВОЕ И ДИСКРЕТНОЕ ПРЕОБРАЗОВАНИЕ ФУРЬЕ.
Непрерывную или дискретную функцию Таблица2.1. Аналоговые и дискретные сигналы и их спектры Дискретный непериодический сигнал (Д=1, П=0) при цифровой обработке обычно рассматривают как периодический (Д=1, П=1) с большими и физически разумными значениями периода
АПФ – это преобразование Фурье для аналогового сигнала, представляемого непрырывной функцией
Ряд (11.1) можно переписать в виде
2.3. Дискретное преобразование Фурье (ДПФ).
Безразмерные переменные
Таблица 2.2
Используя (11.1), нетрудно показать, что гармоническое колебание
Сравнение ДПФ и АПФ
В (2.15), (2.16) суммируется конечное количество гармоник, а в АПФ их количество может быть бесконечным.
Периодичность спектра.
Пусть
Получили
Наложение частот в ДПФ.
Другое название теоремы – теорема Котельникова, которое используется в отечественной литературе. Пусть исходный сигнал имеет спектр, ограниченный частотой
Пример телевизионного сигнала
Контроль точности.
Количество операций в ДПФ. Популярное:
|
Последнее изменение этой страницы: 2016-03-17; Просмотров: 1384; Нарушение авторского права страницы
 (3)
(3) (4)
(4) (5)
(5) , m — число интервалов по переменной Y.
, m — число интервалов по переменной Y.

 поместим в последнем столбце корреляционной таблицы и изобразим графически в виде ломаной, называемой эмпирической линией регрессии Y по X (рис. 1).
поместим в последнем столбце корреляционной таблицы и изобразим графически в виде ломаной, называемой эмпирической линией регрессии Y по X (рис. 1). (6)
(6) , l - число интервалов по переменной X.
, l - число интервалов по переменной X.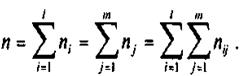 (7)
(7) (8)
(8) вычисленных по формуле (5), от значений
вычисленных по формуле (5), от значений  , найденных по уравнению регрессии (8), была минимальной:
, найденных по уравнению регрессии (8), была минимальной:  (9)
(9)
 (10)
(10)
 (11
(11
 - Ьx из первого уравнения системы (11) в уравнение регрессии (8), получим
- Ьx из первого уравнения системы (11) в уравнение регрессии (8), получим 


 — выборочная дисперсия переменной X:
— выборочная дисперсия переменной X: 



 ) (см. рис. 3).
) (см. рис. 3). (28)
(28) (29)
(29)



 одного переменного
одного переменного  можно представить рядов Фурье по тригонометрическим функциям
можно представить рядов Фурье по тригонометрическим функциям  ,
,  или интегралом Фурье от этих функций. Задача спектрального анализа состоит в определении спектра функции – кооффициентов ряда Фурье и спектральной плотности в интеграле Фурье в зависимости от частоты
или интегралом Фурье от этих функций. Задача спектрального анализа состоит в определении спектра функции – кооффициентов ряда Фурье и спектральной плотности в интеграле Фурье в зависимости от частоты  или круговой частоты
или круговой частоты  . Спектральный анализ сигналов имеет очень важное значение в радиоэлектронике, поэтому функцию
. Спектральный анализ сигналов имеет очень важное значение в радиоэлектронике, поэтому функцию  обычно рассматривают как сигнал, зависящей от времени
обычно рассматривают как сигнал, зависящей от времени  с постоянным шагом дискретизации
с постоянным шагом дискретизации  , т.е. время
, т.е. время  , где
, где  – номер отсчета. Цифровой сигнал получается при дискретизации аналогового сигнала
– номер отсчета. Цифровой сигнал получается при дискретизации аналогового сигнала  , представляемого непрерывной функцией времени.
, представляемого непрерывной функцией времени. 
 .
.  определяет разрешение в спектре, т.е. разность частот соседних составляющих равна
определяет разрешение в спектре, т.е. разность частот соседних составляющих равна  . Очевидно, что при
. Очевидно, что при  получаем
получаем  , т.е. сплошной спектр (Д=0).
, т.е. сплошной спектр (Д=0). на периоде
на периоде  .
. .
. , имеющую период
, имеющую период  , можно представить рядом Фурье.
, можно представить рядом Фурье. ,
,
 - основная круговая частота сигнала,
- основная круговая частота сигнала,  - круговая частота
- круговая частота  -й гармоники сигнала,
-й гармоники сигнала, 



 – амплитуда гармоники с номером
– амплитуда гармоники с номером  ,
,  – фаза той же гармоники. Значения
– фаза той же гармоники. Значения  определяются по коэффициентам
определяются по коэффициентам  ,
,  с помощью формул
с помощью формул ,
, 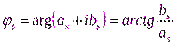
 , его модуль
, его модуль  и
и  аргумент показаны на рис.2.1.
аргумент показаны на рис.2.1.
 гармоники по коэффициентам
гармоники по коэффициентам  ,
,  .
.
 называют комплексной амплитудой гармоники.
называют комплексной амплитудой гармоники. , когда
, когда  , ряд Фурье (11.1) или (11.2) и выражения для его коэффициентов переходят в интегралы Фурье.
, ряд Фурье (11.1) или (11.2) и выражения для его коэффициентов переходят в интегралы Фурье.

 выборкой
выборкой  его значений
его значений  ,
,  ,
,  . Оно основано на следующих положениях.
. Оно основано на следующих положениях. - период.
- период.  .
.  , где
, где  – номера отсчетов,
– номера отсчетов,  .
. .
. , т.е.
, т.е.  .
.  – это номера гармоник. Для вещественного сигнала (комплексный будет рассмотрен позже) значения
– это номера гармоник. Для вещественного сигнала (комплексный будет рассмотрен позже) значения  для четного
для четного  возможны, но мы их рассматривать не будем. Значение
возможны, но мы их рассматривать не будем. Значение  .
.  синусных составляющих и
синусных составляющих и  косинусных составляющих, т.к. две синусные составляющие
косинусных составляющих, т.к. две синусные составляющие  и
и  являются нулевыми и не учитываются в формулах.
являются нулевыми и не учитываются в формулах.

 , период
, период  , частота
, частота  -ой гармоники
-ой гармоники  , шаг дискретизации
, шаг дискретизации  , и для каждой переменной используется ее безразмерный аналог, см. таблицу 11.2.
, и для каждой переменной используется ее безразмерный аналог, см. таблицу 11.2.


 – количество отсчетов на периоде,
– количество отсчетов на периоде,  – номера отсчетов,
– номера отсчетов,  ,
,  ,
,  ,
,  ,
, 
 – частота первой гармоники, называемая также основной,
– частота первой гармоники, называемая также основной,  - безразмерный шаг дискретизации. Безразмерные переменные позволяют использовать универсальные стандартные подпрограммы ДПФ для любых сигналов, т.к. размерные значения периода
- безразмерный шаг дискретизации. Безразмерные переменные позволяют использовать универсальные стандартные подпрограммы ДПФ для любых сигналов, т.к. размерные значения периода  и частот
и частот  в основных формулах не используются. Для спектрального анализа важны номера гармоник, а не размерные значения частот.
в основных формулах не используются. Для спектрального анализа важны номера гармоник, а не размерные значения частот. или
или  может быть записано в виде
может быть записано в виде  или
или  , т.к.
, т.к.  .
. . Его формулы записаны в выше. Здесь укажем лишь на различия формул ДПФ и АПФ для периодического сигнала.
. Его формулы записаны в выше. Здесь укажем лишь на различия формул ДПФ и АПФ для периодического сигнала. до
до  . Что будет, если вычислить гармонику с номером
. Что будет, если вычислить гармонику с номером  ?
?  , т.е.
, т.е.  . Используем (2.17) получим
. Используем (2.17) получим ,
,
 .
. ,
,
 ,
,
 . Кроме того, относительно имеется симметрия для
. Кроме того, относительно имеется симметрия для  и антисимметрия для
и антисимметрия для  .
.  , то далее все повторяется и поэтому вычисления при
, то далее все повторяется и поэтому вычисления при  никогда не проводятся, см.рис.2.3.
никогда не проводятся, см.рис.2.3.
 ) правильно вычисляется половинка любой " шапочки" рис.2.3, что используется при вычислении спектров модулированных сигналов, например, для
) правильно вычисляется половинка любой " шапочки" рис.2.3, что используется при вычислении спектров модулированных сигналов, например, для  .
. сигнала на периоде выбрано недостаточно большим.
сигнала на периоде выбрано недостаточно большим. . Пусть
. Пусть  - его амплитудный спектр, который в общем случае содержит бесконечное количество гармоник. Пусть рассматриваемый сигнал дискретизирован и по
- его амплитудный спектр, который в общем случае содержит бесконечное количество гармоник. Пусть рассматриваемый сигнал дискретизирован и по  , содержащий
, содержащий  гармоник.
гармоник.  и
и  совпадают. Если же
совпадают. Если же  недостаточно велико, то спектры
недостаточно велико, то спектры 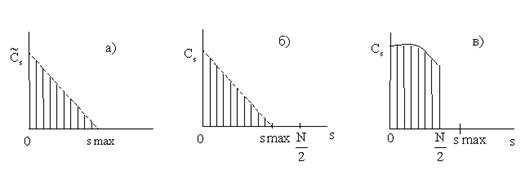
 , а далее эти гармоники повторяются в соответствии с рис.2.3. Большие погрешности в спектре рис.2.1в обусловлены тем, что в исходном аналоговом сигнале есть гармоники с номерами
, а далее эти гармоники повторяются в соответствии с рис.2.3. Большие погрешности в спектре рис.2.1в обусловлены тем, что в исходном аналоговом сигнале есть гармоники с номерами  , а в ДПФ они не рассматриваются из-за периодичности спектра.
, а в ДПФ они не рассматриваются из-за периодичности спектра. - отсчет исходного аналогового сигнала
- отсчет исходного аналогового сигнала  , т.е.
, т.е.  ,
,  .
. будет означать суммирование по этим значением
будет означать суммирование по этим значением  , т.е. по всем отсчетам. Используем целый индекс
, т.е. по всем отсчетам. Используем целый индекс  для гармоник аналогового сигнала,
для гармоник аналогового сигнала,  в общем случае. Тогда аналоговое преобразование Фурье (АПФ) можно записать в соответствии с (2.2) в виде
в общем случае. Тогда аналоговое преобразование Фурье (АПФ) можно записать в соответствии с (2.2) в виде
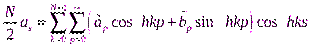



 . Поэтому для коэффициента
. Поэтому для коэффициента  (или
(или  и слагаемые, для которых
и слагаемые, для которых  кратно
кратно  .
.
 . Из (2.26) делаем следующие выводы:
. Из (2.26) делаем следующие выводы:  , хотя в исходном аналоговом сигнале могут присутствовать гармоники с номерами
, хотя в исходном аналоговом сигнале могут присутствовать гармоники с номерами  .
. то при вычислении ДПФ они накладываются на гармоники с номерами
то при вычислении ДПФ они накладываются на гармоники с номерами  и искажают их. Наложение происходит для гармоник с номерами
и искажают их. Наложение происходит для гармоник с номерами  , если
, если  кратно
кратно 
 - амплитудный спектр аналогового сигнала; здесь для ДПФ
- амплитудный спектр аналогового сигнала; здесь для ДПФ  , т.к.
, т.к.  .
.
 . Если такие гармоники есть, то они не должны превышать заданной погрешности вычисления спектра.
. Если такие гармоники есть, то они не должны превышать заданной погрешности вычисления спектра. ,
,  ,
,  ,
,  , выбрано
, выбрано  . Это ошибка, т.к. при ДПФ гармоники 50 и 49 накладываются на нулевую и первую соответственно, что даст погрешность 20%. Нужно выбрать
. Это ошибка, т.к. при ДПФ гармоники 50 и 49 накладываются на нулевую и первую соответственно, что даст погрешность 20%. Нужно выбрать  .
. , которая соответствует номеру гармоники
, которая соответствует номеру гармоники  , где
, где  – период сигнала.
– период сигнала. ,
,
 ,
,
 ,
,  ,
,  эти формулы можно записать в более известном виде
эти формулы можно записать в более известном виде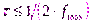 ,
,
 .
. МГц до
МГц до  МГц. Здесь
МГц. Здесь  – несущая частота конкретного канала. Пусть
– несущая частота конкретного канала. Пусть  МГц. Получаем
МГц. Получаем  МГц. За период выберем длительность одной строки
МГц. За период выберем длительность одной строки  мксек, т.е. основная частота
мксек, т.е. основная частота  МГц.
МГц. на периоде, что соответствует частоте дискретизации
на периоде, что соответствует частоте дискретизации  МГц.
МГц.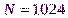 и
и  МГц, реализуемые в современной цифровой обработке.
МГц, реализуемые в современной цифровой обработке. гармоник. Затем шаг дискретизации
гармоник. Затем шаг дискретизации  уменьшается в 2 раза и ДПФ вычисляют по
уменьшается в 2 раза и ДПФ вычисляют по  точкам, что дает
точкам, что дает  гармоник. Можно также выполнить контроль, взяв точки через одну, т.е. по
гармоник. Можно также выполнить контроль, взяв точки через одну, т.е. по  отсчетам сигнала.
отсчетам сигнала. и
и  , например.
, например.