
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Кафедра «Экономика транспорта»Стр 1 из 4Следующая ⇒
Кафедра «Экономика транспорта» ЭКОНОМЕТРИКА Методические указания к практическим занятиям Часть I
САНКТ-ПЕТЕРБУРГ ПГУПС
Предназначены для студентов-бакалавров, обучающихся по направлению 080100.62 «Экономика» профиль «Экономика предприятий и организаций» (транспорт).
Лабораторная работа № 1
Задание
Исходные данные для лабораторной работы представлены табл. 1.1 значений переменных x и y (по вариантам). Расчёты произвести с помощью таблиц MS Excel. Принять уровень значимости 1. Рассчитать линейный коэффициент парной корреляции 2. Оценить значимость линейного коэффициента парной корреляции 3. Рассчитать доверительный интервал для статистически значимого коэффициента парной корреляции Таблица 1.1 Исходные данные к лабораторной работе № 1 по вариантам
Решение типового примера Пусть даны следующие значения переменных x и y по месяцам 2012 г., а также вид уравнения нелинейной зависимости (табл. 1.2): Таблица 1.2 Исходные данные типового примера
1. Для расчёта линейного коэффициента парной корреляции Таблица 1.3 Промежуточные расчёты типового примера
Тогда согласно формулам 1.2 и 1.3 имеем следующее значение линейного коэффициента парной корреляции:
Таким образом, для рассматриваемых переменных характерна сильная линейная корреляционная связь, причём положительная (прямая) – с ростом эксплуатационных расходов растёт себестоимость и наоборот. Индекс корреляции
Как видно из расчёта индекса корреляции 2. Расчётный критерий Стьюдента для оценки значимости
Критическое значение статистики Стьюдента находим по табл. 1 Приложения 2 для заданного уровня значимости Расчётный критерий Фишера для оценки значимости
Критическое значение статистики Фишера находим по табл. 2 Приложения 2 для заданного уровня значимости 3. Для построения доверительного интервала для статистически значимого
Квентиль стандартного нормального распределения порядка
Тогда имеем следующие границы доверительного интервала
Теперь оценим границы доверительного интервала
Таким образом, доверительный интервал для
Лабораторная работа № 2
ПАРНАЯ ЛИНЕЙНАЯ РЕГРЕССИЯ Наиболее простой эконометрической моделью, построенной на основе парной линейной корреляционной связи, является модель парной линейной регрессии, имеющая вид:
где Оценка параметров
В результате минимизации остатков строится система нормальных уравнений. Решением системы находятся следующие формулы для расчёта оценок параметров
Качество регрессионной модели оценивают с помощью коэффициента детерминации
где Для проверки значимости уравнения регрессии рассчитывается значение критерия Фишера по формуле (k – число факторов):
где Далее находится критическое значение критерия Фишера Одним из методов оценки значимости коэффициентов регрессионного уравнения
При этом исправленные выборочные оценки стандартных отклонений (ошибок) МНК-коэффициентов регрессии вычисляются по формулам
а критическое значение Если по результатам расчёта доверительного интервала окажется, что доверительный интервал включает 0, то соответствующий коэффициент регрессии объявляется незначимым, в противном случае соответствующий коэффициент значим. Альтернативным методом оценки значимости рассчитанных коэффициентов регрессионного уравнения является использование расчётных значений t-критерия Стьюдента, которые определяются по формулам:
Расчётные значения t-статистик сравниваются (по модулю) с критическими значениями t -статистик, определёнными для количества степеней свободы Точность построенного уравнения регрессии можно оценить с помощью средней ошибки аппроксимации (допустимый предел значений
Средний коэффициент эластичности показывает, на сколько процентов в среднем по совокупности изменится результат
Прогнозное значение Для построения доверительного интервала прогноза сначала вычисляется средняя стандартная ошибка прогноза
Затем строится сам доверительный интервал по формуле (для заданного уровня значимости
Быстрое развитие эконометрики во второй половине ХХ – начале ХХI века одновременно с развитием компьютерных технологий привело к появлению специализированных эконометрических пакетов для построения и анализа эконометрических моделей на компьютерах. К получившим известность эконометрическим пакетам относятся SAS, GAUSS, STATA, TSP, SPSS, Microfit386, Econometric Views. В данной лабораторной работе для расчетов используется некоммерческий эконометрический пакет Gretl, версия 1.9.14 (официальный сайт пакета: http: //gretl.sourceforge.net/).
Задание
Исходные данные для лабораторной работы представлены табл. 1.1 значений переменных x и y (по вариантам, см. лабораторную работу № 1, столбцы «№ варианта», «Переменная x», «Переменная y»). Для пунктов 1–8 ниже расчёты произвести в MS Excel, для пунктов 9–10 – в Gretl. Принять для данной лабораторной работы уровень значимости 1. Составить уравнение парной линейной регрессии 2. С помощью коэффициента детерминации 3. Оценить значимость уравнения регрессии с помощью дисперсионного анализа. 4. Построить доверительные интервалы для оценки параметров регрессии 5. С помощью значений t-статистики Стьюдента для параметров регрессии подтвердить вывод о значимости параметров, полученный в п. 4. 6. Оценить точность построенного уравнения регрессии с помощью средней ошибки аппроксимации. 7. Рассчитать и интерпретировать средний коэффициент эластичности. 8. Определить точечный прогноз 9. Определить параметры уравнения регрессии, коэффициент детерминации, расчётные и критические значения t- и F-статистик, исправленные выборочные оценки стандартных отклонений (ошибок) МНК-коэффициентов, доверительные интервалы для коэффициентов регрессии, стандартную ошибку модели с помощью эконометрического пакета Gretl и сравнить с результатами расчёта в MS Excel (результаты должны совпасть). 10. Построить график наблюдаемых значений и прямую регрессии в Gretl, объяснить порядок построения графика. Решение типового примера Пусть даны следующие значения переменных x и y по месяцам 2012 г. (табл. 1.2, см. лабораторную работу № 1). 1. Для расчётов согласно формулам 2.3, 2.4, 2.6, 2.9, 2.11, 2.12, 2.13, 2.14 произведём промежуточные вычисления с помощью таблиц MS Excel в табл. 2.1. Таблица 2.1 Промежуточные расчёты типового примера
Продолжение табл. 2.1
Согласно формулам 2.3 и промежуточным вычислениям в табл. 2.1 имеем следующие значения оценок коэффициентов регрессии:
тогда искомое уравнение парной линейной регрессии выглядит следующим образом:
2. Согласно формуле 2.4 и промежуточным вычислениям в таблице 2.1 рассчитаем коэффициент детерминации
таким образом построенное уравнение регрессии объясняет 59% вариации (дисперсии) зависимой переменной 3. Для проверки значимости уравнения регрессии рассчитаем значение критерия Фишера по формуле 2.5:
При этом критическое значение критерия Фишера для заданного уровня значимости 4. Для построения доверительных интервалов для коэффициентов регрессионного уравнения воспользуемся формулами 2.9 для расчёта исправленных выборочных оценок стандартных отклонений
Критическое значение статистики Стьюдента находим по табл. 1 Приложения 2 для заданного уровня значимости
Т.к. доверительный интервал для 5. Определим расчётные значения t-критерия Стьюдента для коэффициентов регрессии
Критическое значение статистики Стьюдента находим по табл. 1 Приложения 2 для заданного уровня значимости Так как 6. Оценим точность построенного уравнения регрессии с помощью расчёта средней ошибки аппроксимации по формуле 2.11:
т.е. в среднем расчётные значения 7. Рассчитаем средний коэффициент эластичности по формуле 2.12:
Таким образом, при изменении фактора 8. Прогнозное значение независимой переменной
Рассчитаем среднюю стандартную ошибку прогноза Тогда по формуле 2.14 искомый доверительный интервал для
9. Данные для расчёта в Gretl проще всего импортировать в эконометрический пакет из MS Excel. Перенесём исходные данные (табл. 2.1, столбцы 2 и 3) на лист Excel. Импортируем данные из подготовленной таблицы Excel в Gretl с помощью функции Файл-Открыть-Импорт-Excel. Теперь построим модель линейной парной регрессии в Gretl с помощью функции Модель-Метод наименьших квадратов с выбором зависимой и независимой переменных. Рассмотрим построенную в окне Gretl модель. В столбце «Коэффициенты» показаны коэффициенты регрессии Критическое значения t-статистики Стьюдента в Gretl может быть получено из основного окна программы с помощью функции Инструменты-Критические значения с последующим выбором соответствующей статистики, степеней свободы и уровня значимости. Аналогично находится критическое значение F-статистики Фишера. Доверительные интервалы для коэффициентов регрессии могут быть рассчитаны в Gretl с помощью функции Анализ-Доверительные интервалы для коэффициентов в окне модели Gretl. Результаты расчёта в эконометрическом пакете совпадают с результатами расчёта в MS Excel, приведенными выше в типовом примере данной лабораторной работы. 10. График наблюдаемых значений и прямая регрессии в Gretl строится с помощью функции Графики-График наблюдаемых и расчётных значений-В зависимости от Х в окне построенной модели.
Лабораторная работа № 3
Задание
Исходные данные для лабораторной работы представлены табл. 3.1 значений зависимой и независимых переменных (по вариантам). Для пунктов 1–6 ниже расчёты произвести в Gretl, для пункта 7 – в Gretl и MS Excel. Принять уровень значимости Таблица 3.1 Исходные данные к лабораторной работе №3 по вариантам
1. Построить матрицу парных линейных коэффициентов корреляции для зависимой и всех независимых переменных. Установить, какие факторы коллинеарны. 2. Построить уравнение множественной линейной регрессии, обосновав выбор факторов. 3. Оценить статистическую значимость уравнения множественной регрессии и статистическую значимость коэффициентов уравнения регрессии с использованием p-значений t- и F-статистик. 4. Построить уравнение множественной регрессии со статистически значимыми факторами. 5. Определить значение коэффициента множественной корреляции и детерминации, скорректированное значение коэффициента множественной детерминации. 6. Провести тестирование ошибок уравнения множественной регрессии на гетероскедастичность с использованием теста Вайта. 7. Рассчитать и интерпретировать средние коэффициенты эластичности, бета- и дельта-коэффициенты.
Решение типового примера Пусть даны следующие значения зависимой и независимых переменных (табл. 3.2). Таблица 3.2 Исходные данные типового примера
1. Импортируем данные в Gretl и построим матрицу парных линейных коэффициентов корреляции для зависимой и всех независимых переменных с помощью функции Вид-Корреляционная матрица. По результатам расчета 2. Построим уравнение множественной линейной регрессии с помощью функции Модель-Метод наименьших квадратов. Фактор X11 исключаем из построения, т.к. он коллинеарен с X10 и его связь с другими факторами сильнее, нежели у X10 (
3. Построенное уравнение множественной линейной регрессии статистически значимо, так как p-значение для расчётной статистики Фишера (количество степеней свободы Коэффициент 4. Построим уравнение множественной линейной регрессии с помощью функции Модель-Метод наименьших квадратов, исключив фактор X4. Полученное уравнение множественной линейной регрессии выглядит следующим образом:
На основе анализа р-значений для расчётных t- и F-статистик построенное уравнение регрессии и все коэффициенты регрессии являются статистически значимыми. 5. Рассчитанное значение коэффициента множественной детерминации: Популярное:
|
Последнее изменение этой страницы: 2016-03-17; Просмотров: 1161; Нарушение авторского права страницы
 .
. и индекс корреляции
и индекс корреляции  . В случае необходимости изменить уравнение нелинейной зависимости для математически корректного расчёта индекса корреляции
. В случае необходимости изменить уравнение нелинейной зависимости для математически корректного расчёта индекса корреляции  .
.

















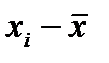






 ,
,  ,
,  .
. , т.е. является вещественным числом. Поэтому необходимо изменить предлагаемое уравнение нелинейной зависимости из условия работы (в противном случае подкоренное выражение по данным табл. 1.3 получается отрицательным). Заменяем коэффициент при
, т.е. является вещественным числом. Поэтому необходимо изменить предлагаемое уравнение нелинейной зависимости из условия работы (в противном случае подкоренное выражение по данным табл. 1.3 получается отрицательным). Заменяем коэффициент при  с
с  на
на  в уравнении и пересчитываем суммы
в уравнении и пересчитываем суммы  в табл. 1.3. Тогда получаем следующее значение индекса корреляции
в табл. 1.3. Тогда получаем следующее значение индекса корреляции  .
. согласно формуле 1.5 равен
согласно формуле 1.5 равен .
. и количества степеней свободы
и количества степеней свободы  :
:  . Так как
. Так как  , то найденное значение
, то найденное значение  согласно формуле 1.6 равен
согласно формуле 1.6 равен .
. и количества степеней свободы
и количества степеней свободы  и
и  :
:  . Так как
. Так как  , то найденное значение
, то найденное значение  признается статистически незначимым.
признается статистически незначимым. по формуле 1.7 (Z-преобразование Фишера):
по формуле 1.7 (Z-преобразование Фишера):  .
. можно получить с помощью функции MS Excel НОРМСТОБР (0, 975):
можно получить с помощью функции MS Excel НОРМСТОБР (0, 975):  .
. для
для  ,
,  .
. для
для  на основе границ доверительного интервала
на основе границ доверительного интервала  согласно формуле 1.9 с помощью функции ФИШЕРОБР (z) из MS Excel:
согласно формуле 1.9 с помощью функции ФИШЕРОБР (z) из MS Excel:  ,
,  .
. равен (0, 3471; 0, 9314).
равен (0, 3471; 0, 9314). , (2.1)
, (2.1) – независимая (факторная) переменная;
– независимая (факторная) переменная;  – зависимая (результативная) переменная;
– зависимая (результативная) переменная;  – параметры (коэффициенты) уравнения регрессии;
– параметры (коэффициенты) уравнения регрессии; 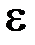 – независимая, нормально распределённая случайная величина, остаток с нулевым математическим ожиданием и постоянной дисперсией.
– независимая, нормально распределённая случайная величина, остаток с нулевым математическим ожиданием и постоянной дисперсией. производится классическим методом наименьших квадратов (МНК) путём минимизации суммы квадратов остатков:
производится классическим методом наименьших квадратов (МНК) путём минимизации суммы квадратов остатков:  . (2.2)
. (2.2) через наблюдаемые значения переменных
через наблюдаемые значения переменных 
 ,
,  . (2.3)
. (2.3) , который определяется по формуле
, который определяется по формуле , (2.4)
, (2.4) ,
,  – расчётные (прогнозные) значения величины
– расчётные (прогнозные) значения величины  , полученные подстановкой соответствующих значений
, полученные подстановкой соответствующих значений  в уравнение регрессии. Коэффициент детерминации показывает, какую часть вариации (дисперсии) зависимой переменной
в уравнение регрессии. Коэффициент детерминации показывает, какую часть вариации (дисперсии) зависимой переменной  , (2.5)
, (2.5) ,
,  . (2.6)
. (2.6) для заданного уровня значимости
для заданного уровня значимости  и количества степеней свободы
и количества степеней свободы  и
и  . Если
. Если  , то делается вывод о значимости уравнения регрессии (нулевая гипотеза о статистической незначимости уравнения регрессии отвергается), в противном случае уравнение регрессии признается статистически незначимым.
, то делается вывод о значимости уравнения регрессии (нулевая гипотеза о статистической незначимости уравнения регрессии отвергается), в противном случае уравнение регрессии признается статистически незначимым. является построение доверительных интервалов. Доверительные интервалы для коэффициентов регрессии
является построение доверительных интервалов. Доверительные интервалы для коэффициентов регрессии  имеют соответственно вид
имеют соответственно вид , (2.7)
, (2.7) . (2.8)
. (2.8) ,
,  ,
,  , (2.9)
, (2.9) критерия Стьюдента определяется для количества степеней свободы
критерия Стьюдента определяется для количества степеней свободы  и заданного уровня значимости
и заданного уровня значимости  .
. ,
,  (
(  в общем случае). (2.10)
в общем случае). (2.10) и заданного уровня значимости
и заданного уровня значимости  . Если расчётное значение превосходит критическое, то нулевая гипотеза о равенстве нулю коэффициента регрессии отвергается и соответствующий параметр признается значимым, в противном случае – незначимым.
. Если расчётное значение превосходит критическое, то нулевая гипотеза о равенстве нулю коэффициента регрессии отвергается и соответствующий параметр признается значимым, в противном случае – незначимым. – не более 8–10%):
– не более 8–10%):  . (2.11)
. (2.11) на 1% от своего значения:
на 1% от своего значения: 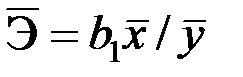 . (2.12)
. (2.12) (точечный прогноз) определяется путём подстановки в уравнение регрессии
(точечный прогноз) определяется путём подстановки в уравнение регрессии  соответствующего (прогнозного) значения независимой переменной
соответствующего (прогнозного) значения независимой переменной 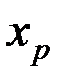 .
. :
:  . (2.13)
. (2.13) ):
):  . (2.14)
. (2.14) .
. .
. оценить качество построенной модели.
оценить качество построенной модели. и сделать вывод о значимости параметров.
и сделать вывод о значимости параметров. . Построить доверительный интервал прогноза
. Построить доверительный интервал прогноза  .
.



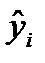







 ,
,  ,
,  .
. ,
,  ,
,  ,
,  .
. и количества степеней свободы
и количества степеней свободы  и
и  согласно табл. 2 Приложения 2 равно
согласно табл. 2 Приложения 2 равно  . Так как
. Так как  , то делаем вывод о значимости уравнения регрессии.
, то делаем вывод о значимости уравнения регрессии. :
:  ,
,  ,
,  .
.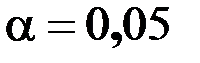 и количества степеней свободы
и количества степеней свободы  . Соответственно, согласно формулам 2.7 и 2.8 искомые доверительные интервалы для
. Соответственно, согласно формулам 2.7 и 2.8 искомые доверительные интервалы для  следующие:
следующие:  ,
,  .
.
 включает в себя 0, то коэффициент
включает в себя 0, то коэффициент  незначим. Доверительный интервал для
незначим. Доверительный интервал для 
 не включает в себя 0, поэтому коэффициент
не включает в себя 0, поэтому коэффициент  значим.
значим. по формулам 2.10:
по формулам 2.10:  ,
,  .
.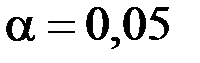 и количества степеней свободы
и количества степеней свободы  .
. , то коэффициент
, то коэффициент  незначим; т.к.
незначим; т.к.  , то коэффициент
, то коэффициент  значим. Таким образом, вывод о значимости коэффициентов, полученный в п. 4 лабораторной работы с использованием доверительных интервалов, подтверждён.
значим. Таким образом, вывод о значимости коэффициентов, полученный в п. 4 лабораторной работы с использованием доверительных интервалов, подтверждён. ,
,  .
. (эксплуатационные расходы) на +1% от своего значения, результат
(эксплуатационные расходы) на +1% от своего значения, результат  , тогда прогнозное значение
, тогда прогнозное значение  (точечный прогноз) равен:
(точечный прогноз) равен:  .
. .
. (
(  для
для  и количества степеней свободы
и количества степеней свободы  :
:  .
. (0, 059 и 1, 382× 10–5 соответственно); R-квадрат (коэффициент детерминации) равен 0, 589; расчетные значения t-статистик для
(0, 059 и 1, 382× 10–5 соответственно); R-квадрат (коэффициент детерминации) равен 0, 589; расчетные значения t-статистик для 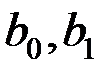 показаны в столбце «t-статистика» (0, 1628 и 3, 792 соответственно); расчетное значение F-статистики (F(1, 10)) для уравнения регрессии равно 14, 38; стандартные отклонения (ошибки)
показаны в столбце «t-статистика» (0, 1628 и 3, 792 соответственно); расчетное значение F-статистики (F(1, 10)) для уравнения регрессии равно 14, 38; стандартные отклонения (ошибки)  равны 0, 362 и 3, 643× 10–6 соответственно (столбец «Ст. ошибка»); стандартная ошибка модели
равны 0, 362 и 3, 643× 10–6 соответственно (столбец «Ст. ошибка»); стандартная ошибка модели  («Ст. ошибка модели») равна 0, 0864.
(«Ст. ошибка модели») равна 0, 0864. .
. 0, 1688,
0, 1688,  ,
,  ,
,  ,
,  ,
,  . Таким образом, переменные X10 и X11 явно коллинеарны.
. Таким образом, переменные X10 и X11 явно коллинеарны. ). При этом теснота связи X10 с результативным признаком высокая (
). При этом теснота связи X10 с результативным признаком высокая (  ). Итак, искомое уравнение множественной линейной регрессии выглядит следующим образом:
). Итак, искомое уравнение множественной линейной регрессии выглядит следующим образом: 
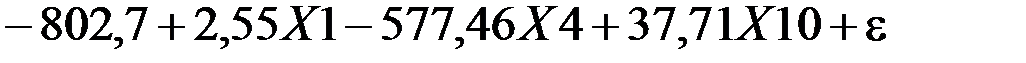 .
. и
и  ) меньше уровня значимости
) меньше уровня значимости  :
: 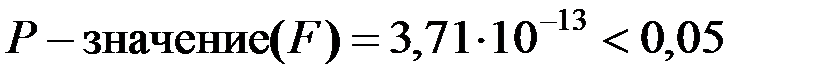 .
. статистически незначим, т.к. для расчётного значения t-статистики (количество степеней свободы
статистически незначим, т.к. для расчётного значения t-статистики (количество степеней свободы  ) p-значение больше уровня значимости
) p-значение больше уровня значимости 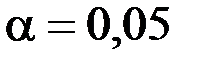 :
:  . Аналогичные p-значения для коэффициентов
. Аналогичные p-значения для коэффициентов 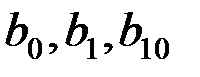 меньше
меньше  , следовательно коэффициенты
, следовательно коэффициенты 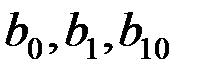 статистически значимы.
статистически значимы.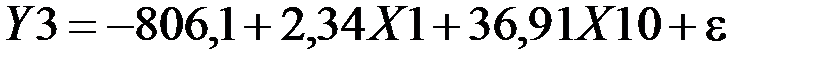 .
. ; скорректированное значение коэффициента множественной детерминации:
; скорректированное значение коэффициента множественной детерминации:  . Таким образом, построенное уравнение регрессии объясняет 54% вариации (дисперсии) зависимой переменной
. Таким образом, построенное уравнение регрессии объясняет 54% вариации (дисперсии) зависимой переменной  .
.