
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Показатели тесноты связи между качественными признаками
Метод корреляционных таблиц применим не только к количественным, но и к описательным (качественным) признакам, взаимосвязи между которыми часто приходится изучать при проведении различных социологических исследований путем опросов или анкетирования. В этом случае такие таблицы называют таблицами сопряженности. Они могут иметь различную размерность. Простейшая размерность – 2х2 (таблица «четырех полей»), когда по альтернативному признаку («да» – «нет», «хорошо» – «плохо» и т.д.) выделяются 2 группы. В таблице 48 приведены условные данные о распределении 500 опрошенных человек по двум показателям: наличие (отсутствии) у них прививки против гриппа и факт заболевания (незаболевания) гриппом во время его эпидемии. Таблица 48. Распределение 500 опрошенных человек
Нетрудно заметить, что среди сделавших прививку подавляющее большинство (270 из 300, или 90%) не заболели гриппом, а среди не сделавших большая часть заболела (120 из 200, или 60%). Таким образом, можно предположить, что прививка положительно влияет на предупреждение заболевания; другими словами, можно предположить, что распределение в таблице (a, b, c, d) не случайно и существует стохастическая зависимость между группировочными признаками. Однако выводы о зависимости, сделанные «на глаз», часто могут быть ненадежными (ошибочными), поэтому они должны подкрепляться определенными статистическими критериями, например критерием Пирсона χ 2. Он позволяет судить о случайности (или неслучайности) распределения в таблицах взаимной сопряженности, а следовательно, и об отсутствии или наличии зависимости между признаками группировки в таблице. Чтобы воспользоваться критерием Пирсона χ 2, в таблице взаимной сопряженности наряду с эмпирическими частотами записывают теоретические частоты, рассчитываемые исходя из предположения, что распределение внутри таблицы случайно и, следовательно, зависимость между признаками группировки отсутствует. То есть считается, что распределение частот в каждой строке (столбце) таблицы пропорционально распределению частот в итоговой строке (столбце). Поэтому теоретические частоты по строкам (столбцам) рассчитывают пропорционально распределению единиц в итоговой строке (столбце). Так, в нашем примере в итоговой строке число заболевших 150 из 500, т.е. их доля – 30%, а доля не заболевших – 70%. Следовательно, теоретические частоты в первой строке для заболевших составят 30% от 300, т.е. 0, 3*300=90, а для не заболевших – 0, 7*300=210. По второй строке произведем аналогичные расчеты и их результаты занесем в таблицу в скобках. Таблица 49. Эмпирические и теоретические частоты
На сопоставлении эмпирических и теоретических частот и основан критерий Пирсона χ 2, рассчитываемый по формуле (44):
Рассчитанное (фактическое) значение χ 2 сопоставляют с табличным (критическом), определяемым по таблице Приложения 3 для заданного уровня значимости α и числа степеней свободы В рассматриваемом примере ν =(2-1)(2-1)=1, а приняв уровень значимости α =0, 01, по таблице Приложения 3 находим χ 2табл=6, 63. Поскольку рассчитанное значение χ 2> χ 2табл, значит существует стохастическая зависимость между рассматриваемыми показателями. При независимости признаков част о ты теоретического и эмпирического распределений совпадают, а значит χ 2=0. Чем больше различия между теоретическими и эмпирическими частотами, тем больше значение χ 2 и вероятность того, что оно превысит критическое табличное значение, допустимое для случайных расхождений. Аналогично рассчитываются теоретические частоты и χ 2 в таблицах большей размерности. В корреляционном анализе недостаточно лишь выявить тем или иным методом наличие связи между исследуемыми показателями. Теснота такой связи может быть различной, поэтому весьма важно ее измерить, т.е. определить меру связи в каждом конкретном случае. В статистике для этой цели разработан ряд показателей (коэффициентов), используемых как для количественных, так и для качественных признаков. Для измерения тесноты связи между группировочными признаками в таблицах взаимной сопряженности могут быть использованы такие показатели, как коэффициент ассоциации и контингенции (для «четырехклеточных таблиц»), а также коэффициенты взаимной сопряженности Пирсона и Чупрова (для таблиц любой размерности). Применительно к таблице «четырех полей», частоты которых можно обозначить через a, b, c, d, коэффициент ассоциации (Д. Юла) выражается формулой (158):
Его существенный недостаток: если в одной из четырех клеток отсутствует частота (т.е. равна 0), то Чтобы этого избежать, предлагается (К. Пирсоном) другой показатель – коэффициент контингенции [53] :
Рассчитаем коэффициенты (158) и (159) для нашего примера (таблица 48):
Связь считается достаточно значительной и подтвержденной, если Поэтому в нашем примере оба коэффициента характеризуют достаточно большую обратную зависимость между исследуемыми признаками. Теснота связи между 2 и более признаками измеряется с помощью коэффициентов взаимной сопряженности Пирсона (160) или Чупрова (161), рассчитываемых на основе показателя χ 2:
В нашем примере Множественная корреляция При решении практических задач исследователи сталкиваются с тем, что корреляционные связи не ограничиваются связями между двумя признаками: результативным y и факторным x. В действительности результативный признак зависит от нескольких факторных. Например, инфляция тесно связана с динамикой потребительских цен, розничным товарооборотом, численностью безработных, объемами экспорта и импорта, курсом доллара, количеством денег в обращении, объемом промышленного производства и другими факторами. В условиях действия множества факторов показатели парной корреляции оказываются условными и неточными. Количественно оценить влияние различных факторов на результат, определить форму и тесноту связи между результативным признаком y и факторными признаками x1, x2, …, xk можно методами множественной (многофакторной) корреляции. Математически задача сводится к нахождению аналитического выражения, наилучшим образом описывающего связь факторных признаков с результативным, т.е. к отысканию функции Среди многофакторных регрессионных моделей выделяют линейные (относительно независимых переменных) и нелинейные. Наиболее простыми для построения, анализа и экономической интерпретации являются многофакторные линейные модели, которые содержат независимые переменные только в первой степени:
где
Если связь между результативным признаком и анализируемыми факторами нелинейна, то выбранная для ее описания нелинейная многофакторная модель (степенная, показательная и т.д.) может быть сведена к линейной путем линеаризации. Параметры уравнения множественной регрессии, как и парной, рассчитываются методом наименьших квадратов, при этом решается система нормальных уравнений с (k+1) неизвестным:
где
Как правило, прежде чем найти параметры уравнения множественной регрессии, определяют и анализируют парные коэффициенты корреляции. При этом систему нормальных уравнений можно видоизменить таким образом, чтобы при вычислении параметров регрессии использовать уже найденные парные коэффициенты корреляции. Для этого в уравнении регрессии заменим переменные y, x1, x2, …, xk переменными tj, полученными следующим образом:
Эта процедура называется стандартизацией переменных. В результате осуществляется переход от натурального масштаба переменных xij к центрированным и нормированным отклонениям tij. В стандартизированном масштабе среднее значение признака равно 0, а среднее квадратическое отклонение равно 1, т.е.
где Параметры уравнения множественной регрессии в натуральном масштабе и уравнения регрессии в стандартизированном виде взаимосвязаны:
Нетрудно заметить, что это обычная формула коэффициента регрессии, выраженного через линейный коэффициент корреляции. Стандартизированные коэффициенты множественной регрессии
где
После того как получено уравнение множественной регрессии (в стандартизированном или натуральном масштабе), необходимо измерить тесноту связи между результативным признаком и факторными признаками. Для измерения степени совокупного влияния отобранных факторов на результативный признак рассчитывается совокупный коэффициент детерминации R2 и совокупный коэффициент множественной корреляции R – общие показатели тесноты связи многих признаков независимо от формы связи. Приведем несколько формул для их расчета. 1. При линейной форме связи расчет совокупного коэффициента детерминации можно выполнить, используя парные коэффициенты корреляции:
где 2. Еще легче вычислить совокупный коэффициент детерминации, используя уравнение регрессии в стандартизированном виде:
3. Через соотношение факторной и общей дисперсий (или остаточной и общей дисперсий):
где Совокупный коэффициент множественной корреляции R представляет собой корень квадратный из совокупного коэффициента детерминации R2. Пределы его изменения: Для более глубокого знакомства с темой «Множественная корреляция» необходимо воспользоваться литературой курса «Эконометрика». 7.7. Контрольные задания На основе исходных данных контрольных заданий по теме 6 (таблица 38) с использованием таблицы 50 проанализировать взаимосвязь между признаками x и y всеми возможными методами, изложенными в теме 7. Таблица 50. Распределение вариантов для выполнения контрольного задания
Индексы Назначение и виды индексов Индекс – относительная величина, показывающая во сколько раз уровень изучаемого явления в данных условиях отличается от уровня того же явления в других условиях. Различие условий может проявляться во времени (тогда получается индекс динамики), в пространстве (территориальный индекс), в выборе в качестве базы сравнения планового показателя (индекс выполнения плана) и т.п. Каждый индекс включает 2 вида данных: оцениваемые данные, которые принято называть отчетными и обозначать значком «1», и данные, которые используются в качестве базы сравнения – базисные, обозначаемые значком «0». Индекс, который строится как сравнение обобщенных величин, называется общим (сводным) и обозначается I. Если же сравниваются необобщенные величины, то индекс называется индивидуальным и обозначается i. Как правило, подстрочно ставится значок, показывающий для оценки какой величины построе индекс. Например, Iq и iq – это общий и индивидуальный индекс для величины q. В статистическе индексы используются не только для сопоставления уровней изучаемого явления, но и для определения экономической значимости факторов, объясняющих абсолютное различие сравниваемых уровней. В зависимости от сложности сравниваемых уровней принято выделять 2 типа индексов: индивидуальные и общие. Индивидуальные индексы Относительная величина, получаемая при сравнении уровней, называется индивидуальным индексом, если не имеет значения структура изучаемого явления. Индивидуальные индексы обозначаются i. Расчет индивидуальных индексов прост: их определяют вычислением отношения двух индексируемых величин, то есть по формуле (2). Например, если уровень товарооборота iQ=Q1/Q0. (170) Разность между числителем и знаментелем формулы (170) представляет собой абсолютное изменение выручки (171), показывающее на сколько в денежных единицах (например, рублях) изменилась выручка в отчетном периоде по сравнению с базисным: ∆ Q = Q1 – Q0. (171) Аналогично определяются индивидуальные индексы можно для любого интересующего показателя (производительности, заработной платы, себестоимости и т.д.). В частности, поскольку сумма выручки определяется ценой товара p (от англ. «price») и количеством (физическим объемом, или объемом продаж в натуральном выражении) q (от англ. «quantity») т.е. ip=p1/p0, (172) iq=q1/q0. (173) Очевидно, что произведение индивидуальных индексов цены и количества дает индивидуальный индекс выручки (174): iQ=iqip. (174) Например, вчера бабушка торговала семечками по 5 руб. за кулёк и всего продала 50 кульков, а сегодня – по 7 руб. и продала 20 кульков. Определим индивидуальный индекс цены по формуле (172): ip = 7/5 = 1, 4, то есть бабушка увеличила цену семечек в 1, 4 раза, или на 40%. Рассчитаем индивидуальный индекс количества по формуле (173): iq = 20/50 = 0, 4, то есть количество проданных семечек сегодня составило 40% от вчерашнего, то есть уменьшилось на 60%. Найдем индивидуальный индекс выручки по формуле (174): iQ = 0, 4*1, 4 = 0, 56, то есть выручка сегодня составила 56% от вчерашней, то есть она уменьшилась на 44%. Рассчитав выручку вчера Q0 = 50*5 = 250 (руб.) и сегодня Q1 = 20*7 = 140 (руб.), можно получить аналогичный результат по формуле (170): iQ = 140/250 = 0, 56. Очевидно, что абсолютное изменение выручки по формуле (171) составило: ∆ Q = 140 – 250 = –110 (руб.), то есть выручка уменьшилась на 110 руб. (или на 44%), что объясняется изменением количества проданных семечек в 0, 4 раза (уменьшением на 60%) и изменением их цены в 1, 4 раза (повышением цены на 40%). Подставим формулу (170) в формулу (174) и выразим выручку отчетного периода: Q1=iqipQ0. (175) Формула (175) представляет собой двухфакторную мультипликативную индексную модель итогового показателя, в данном случае – выручки, посредством которой находят изменение этого показателя под влиянием каждого фактора (цены и количества) в отдельности (факторный анализ), то есть: ∆ Q = ∆ Qq + ∆ Qp, (176) где ∆ Qq – изменение выручки под влиянием изменения количества товара q (экстенсивный фактор); ∆ Qp – изменение выручки под влиянием изменения цены p товара (интенсивный фактор). Для проведения факторного анализа по формуле (176) необходимо определить очередность влияния факторов на результативный показатель (выручку), которая может быть следующей: 1) сначала менялось количество q, а затем цена p (то есть количество – это 1-ый фактор, а цена – 2-ой)[54]; 2) сначала менялась цена p, а потом количество q (то есть цена – это 1-ый фактор, а количество – 2-ой). В соответствии с этой очередностью влияния факторов запись факторов в мультипликатиавной модели: то есть формула (175) – это ее запись для количества как 1-го фактора и цены как 2-го. В случае, когда цена является 1-ым фактором, а количество – 2-ым, необходимо мультипликативную модель записывать в виде (177), то есть меняя факторы местами: Q1=ipiqQ0. (177) Чтобы найти изменение результативного показателя на основе мультипликативной модели за счет 1-го фактора, необходимо исключить влияние остальных факторов. Тогда при использовании формулы (175) влияние 1-го определяем по формуле (178), а при использовании формулы (177) – по формуле (179): ∆ Qq= iqQ0 –Q0 = (iq – 1)Q0, (178) ∆ Qp= ipQ0 –Q0 = (ip – 1)Q0. (179) В нашем примере про бабушку сначала изменилась цена, то есть цена – это 1-ый фактор, а количество – 2-ой, значит необходимо использовать формулу (177) и, как следствие, влияние 1-го фактора – цены определяем по формуле (179): ∆ Qp= (1, 4–1)*250 = 100 (руб.), то есть повышение цены семечек с 5 до 7 руб. за кулёк должно было увеличить сегодняшнюю выручку на 100 руб., однако выручка уменьшилась на 110 руб., значит – это отрицательное влияние 2-го фактора – изменение количества. Чтобы найти изменение результативного показателя на основе мультипликативной модели за счет 2-го фактора, необходимо из общего изменения результативного показателя вычесть его изменение под влиянием только 1-го фактора. Тогда, подставляя формулы (171) и (178) в формулу (176), можно выразить влияние второго фактора – цена: ∆ Qp = ∆ Q – ∆ Qq = (Q1 – Q0)– (iqQ0 –Q0) = iqipQ0 – Q0– iqQ0 +Q0 = (iqip – 1 – iq + 1)Q0 = iq (ip–1)Q0. В итоге получим формулу для расчета влияния второго фактора – цена (180): ∆ Qp = iq (ip–1)Q0. (180) Аналогично, подставляя формулы (171) и (177) в формулу (176) выводится формула для определения влияния второго фактора – количества: ∆ Qq = ∆ Q – ∆ Qp = (Q1 – Q0)– (ipQ0 –Q0) = ipiqQ0 – Q0– ipQ0 +Q0 = (ipiq – 1 – ip + 1)Q0 = ip (iq–1)Q0. В итоге получим формулу для расчета влияния второго фактора – количества (181): ∆ Qq = ip (iq–1)Q0. (181) В нашем примере про бабушку изменение выручки под влиянием второго фактора – количества определим по формуле (181): ∆ Qq = 1, 4*(0, 4–1)*250 = –210 (руб.), то есть снижение количества проданных семечек с 50 кульков до 20 уменьшило выручку на 210 руб. Проверка правильности расчета влияния факторов осуществляется по формуле (176): ∆ Q = 100 + (–210) = –110, что совпадает с общим изменением выручки, рассчитанным ранее по формуле (171). В статистике нередки случаи использования индексных моделей с тремя и более факторными индексами[55]. В случае необходимости проведения факторного анализа таких моделей применяется метод Чалиева: для определения влияния i-го фактора на результативный показатель необходимо его базисную величину умножить на индексы факторов, влиявших на него с 1-го до i-го фактора и на темп изменения самого i-го фактора. Темп изменения определяется по формуле (80), то есть надо из индекса вычесть единицу (100%). Например, общая сумма материальных затрат (M) зависит от объема производства продукции (q), от расхода данного материала на единицу продукции – удельного расхода (m) и от цены единицы данного материала (p) т.е. M = qmp. Сравнивая сумму материальных затрат в отчетном периоде с суммой материальных затрат базисного периода получаем (если q - 1-ый фактор, m – 2-ой и p – 3-ий):
Тогда, применяя метод Чалиева, изменение общей суммы материальных затрат ∆ M = M1 – M0 объясняется: 1) изменением объема продукции ∆ Mq = TqM0 = (iq – 1)M0; 2) изменением удельного расхода материала ∆ Mm = iqTmM0 = iq(im – 1)M0; 3) изменением цены на материал ∆ Mp = iqimTpM0 = iqim(ip – 1)M0. Общие индексы Если изучаемое явление неоднородно и сравнение уровней можно провести только после приведения их к общей мере, экономический анализ выполняют посредством общих индексов. Индекс становится общим, когда в его расчетной формуле показывается неоднородность изучаемой совокупности. Примером неоднородной совокупности является общая масса проданных товаров всех или нескольких видов. Действительно нельзя, например, складывать непосредственно килограммы мяса и рыбы, так как полученный результат в прямом смысле не являлся бы «ни рыбой, ни мясом». Любые общие индексы могут быть построены 2-мя способами: как агрегатные и как средние из индивидуальных. Агрегатный индекс является основной и наиболее распространенной формой индекса, если числитель и знаменатель представляют собой набор – «агрегат» (от лат. aggregatus – складываемый, суммируемый) непосредственно несоизмеримых и не поддающихся суммированию элементов – сумму произведений двух величин, одна из которых меняется (индексируется), а другая остается неизменной в числителе и знаменателе (вес индекса). Вес индекса служит для целей соизмерения индексируемых величин. Например, общую сумму выручки можно записать в виде агрегата (суммы произведений объемного показателя q на взвешивающий – p), т.е. ∑ Q = ∑ qp. (183) Отношение агрегатов, построенных для разных условий, дает общий индекс показателя в агрегатной форме. Так получают индекс общего объема товарооборота (выручки), показывающий во сколько раз он изменился (или сколько процентов составляет) в отчетном периоде по сравнению с базисным: I Q= Разность между числителем и знаментелем формулы (184) представляет собой абсолютное изменение общего товарооборота (выручки) (185), показывающее на сколько в денежных единицах (например, рублях) он изменился в отчетном периоде по сравнению с базисным: ∆ ∑ Q = ∑ Q1 – ∑ Q0 = ∑ q1p1 – ∑ q0p0. (185) Например, дедушка торговал яблоками двух сортов: «антоновкой» и «белым наливом», результаты торговли за 2 дня представлены в таблице 51: Таблица 51. Условные данные о торговле яблоками дедушкой за 2 дня
Рассчитаем выручку дедушки по формуле (183): – в отчетном периоде: ∑ Q1= 18*160+25*120 = 5880 (руб.) – это выручка от продажи яблок сегодня; – в базисном периоде: ∑ Q0= 20*100+22*150 = 5300 (руб.) – это выручка от продажи яблок вчера. Теперь определим изменение общей выручки дедушки: – по формуле (184): I Q= 5880/5300 = 1, 1094, то есть выручка увеличилась в 1, 1094 раза, или на 10, 94%. – по формуле (185): ∆ ∑ Q = 5880 – 5300 = 580, то есть выручка увеличилась на 580 руб. При анализе изменения общего объема товарооборота (выручки) это изменение также объясняется изменением уровня цен и количества проданных товаров. Влияние этих факторов выражается агрегатными индексами физического объема (количества) и цен. Если уровни взвешивающего показателя взяты по данным базисного периода, то получают агрегатный индекс Ласпейреса: Формула (186) применяется, когда количество – это 1-ый фактор, а формула (187) – когда цена является 1-ым фактором. Если уровни взвешивающего показателя взяты по данным отчетного периода, то получают агрегатный индекс Пааше: Формула (188) применяется, когда количество – это 2-ой фактор, а формула (189) – когда цена является 2-ым фактором. Произведение агрегатных индексов Ласпейреса и Пааше дает общий индекс выручки: IQ = Для облегчения запоминания студентами формул Ласпейреса и Пааше предлагаю обратить внимание на букву «Ш» в слове «Пааше», которая напоминает «111» - так обозначены отчетные периоды в общей формуле (две единицы – в числителе и одна – в знаменателе). В формуле Ласпейреса нет буквы «Ш», значит в ней не будет трех единиц, а будут три нуля (два нуля – в знаменателе и один – в числителе). В нашем примере про дедушку (как и в примере про бабушку) цена яблок – это 1-ый фактор, а количество – 2-ой. Поэтому для определения агрегатного индекса цен применяем формулу (187): Определим агрегатный индекс количества проданных яблок по формуле (188): Контроль правильности расчетов производим по формуле (191): I Q = 1, 0472*1, 0594 = 1, 1094, то есть изменение общей выручки дедушки в 1, 1094 раза (на 10, 94%) объясняется изменением цены в 1, 0472 раза (на 4, 72%) и изменением количества продаж в 1, 0594 раза (на 5, 94%). Из формул (186) – (189) видно, что индексы Ласпейреса и Пааше по одному и тому же фактору не равны между собой, то есть Когда нет возможности определить очередность влияния факторов на результативный показатель (какой из факторов 1-ый – цена или количество) проблематично выбрать одну из формул (186) или (187) и (188) или (189). В таких случаях рекомендуется применить все формулы (186) – (189) и рассчитать среднюю геометрическую величину из однофакторных индексов – индексы Фишера: Сравнивая значения индексов Фишера, которые показывают среднее изменение цен (193) и количества (192), решается вопрос об очередности влияния факторов: какой из индексов показывает большее изменение, тот фактор и считают 1-ым. Из формул (190) и (191) легко получить двухфакторные мультипликативные индексные модели общей выручки, подставив в них формулу (184) и выразив ∑ Q1: ∑ Q1= Формула (194) применяется, когда количество товара – 1-ый фактор, а цена 2-ой, а формула (195) – наоборот, цена – 1-ый фактор, а количество – 2-ой. Тогда, применяя метод Чалиева, можно выполнить факторный анализ, то есть объяснить изменение результативного показателя (общей выручки) изменением каждого фактора (цен и количества) в отдельности в абсолютных (денежных) единицах. Более детальный анализ изменения итогового показателя возможен при изучении так называемых структурных сдвигов. В нашем примере про дедушку мы применяли формулу (187), значит должны производить факторный анализ по модели (195). Тогда, применяя метод Чалиева, изменение общей выручки ∆ ∑ Q = ∑ Q1 – ∑ Q0 объясняется изменением: 1) количества проданных проданных яблок ∆ ∑ Qq = ( 2) цены яблок ∆ ∑ Qp = Проверка правильности расчета влияния факторов: ∆ ∑ Q = 265 + 315 = 580, что совпадает с общим изменением общей выручки, рассчитанным ранее по формуле(185). Помимо записи общих индексов в агрегатной форме на практике часто используют формулы их расчета как величин, средних из соответствующих индивидуальных индексов. Так, общий индекс выручки может быть записан как средняя арифметическая взвешенная (196) или средняя гармоническая взвешенная (197) из индивидуальных индексов выручки по отдельным товарным группам:
В формуле (196) весами являются показатели объема товарооборота отдельных товарных групп в отчетном периоде, в формуле (197) – в базисном. Аналогично через индивидуальных индексы количества товара и цены могут быть выражены общие агрегатные индексы Ласпейреса и Пааше: Индексы средних величин При изучении качественных показателей часто приходится рассматривать изменение во времени (или пространстве) средней величины индексируемого показателя для определенной однородной совкупности. Например, в статистических сборниках публикуются данные о динамике средних цен, средней номинальной заработной плате в отдельных отраслях и т.д. Средняя величина является обощающей характеристикой качественного показателя и складывается как под влиянием значений показателя у индивидуальных элементов (единиц), из которых состоит объект, так и под влиянием соотношения их весов («структуры» объекта). Популярное:
|
Последнее изменение этой страницы: 2016-03-17; Просмотров: 1525; Нарушение авторского права страницы
 .
. , где k1 и k2 – число групп по одному и второму признакам группировки (число строк и число столбцов в таблице).
, где k1 и k2 – число групп по одному и второму признакам группировки (число строк и число столбцов в таблице). . (158)
. (158)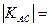 1, и тем самым преувеличена мера действительной связи.
1, и тем самым преувеличена мера действительной связи. . (159)
. (159)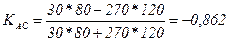 ;
; 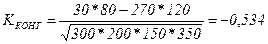
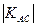 > 0, 5 или
> 0, 5 или  > 0, 3.
> 0, 3. , (160)
, (160)  (161)
(161) . Рассчитывать коэффициент Чупрова для таблицы «четырех полей» не рекомендуется, так как при числе степеней свободы ν =(2-1)(2-1)=1 он будет больше коэффициента Пирсона (в нашем примере КЧ=0, 54). Для таблиц же большей размерности всегда КЧ< КП.
. Рассчитывать коэффициент Чупрова для таблицы «четырех полей» не рекомендуется, так как при числе степеней свободы ν =(2-1)(2-1)=1 он будет больше коэффициента Пирсона (в нашем примере КЧ=0, 54). Для таблиц же большей размерности всегда КЧ< КП.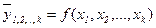 . Выбрать форму связи довольно сложно. Эта задача на практике основывается на априорном теоретическом анализе изучаемого явления и подборе известных типов математических моделей.
. Выбрать форму связи довольно сложно. Эта задача на практике основывается на априорном теоретическом анализе изучаемого явления и подборе известных типов математических моделей. , (162)
, (162)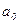 – свободный член;
– свободный член;  – коэффициенты регрессии;
– коэффициенты регрессии;  – факторные признаки.
– факторные признаки. (163)
(163)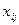 – значение j-го факторного признака в i-м наблюдении;
– значение j-го факторного признака в i-м наблюдении; 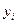 – значение результативного признака в i-м наблюдении.
– значение результативного признака в i-м наблюдении. ,
, 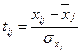 . (
. ( 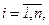
 ).
). =0,
=0,  =1. При переходе к стандартизированному масштабу переменных уравнение множественной регрессии принимает вид
=1. При переходе к стандартизированному масштабу переменных уравнение множественной регрессии принимает вид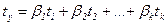 , (164)
, (164)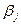 (
(  (
(  (166)
(166) – парный коэффициент корреляции результативного признака y с j-м факторным;
– парный коэффициент корреляции результативного признака y с j-м факторным;  – парный коэффициент корреляции j-го факторного признака с l-м факторным.
– парный коэффициент корреляции j-го факторного признака с l-м факторным. , (167)
, (167)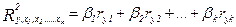 . (168)
. (168) , или
, или  , (169)
, (169)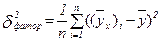 – факторная дисперсия, характеризующая вариацию результативного признака, обусловленную вариацией включенных в анализ факторов;
– факторная дисперсия, характеризующая вариацию результативного признака, обусловленную вариацией включенных в анализ факторов;  – общая дисперсия результативного признака;
– общая дисперсия результативного признака;  – остаточная дисперсия, характеризующая отклонения фактических уровней результативного признака
– остаточная дисперсия, характеризующая отклонения фактических уровней результативного признака  .
.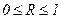 . Чем ближе его значение к 1, тем точнее уравнение множественной линейной регрессии отражает реальную связь. Иначе говоря, среди отобранных факторов присутствуют те, которые решающим образом влияют на результативный. Малое значение R можно объяснить тем либо тем, что в уравнение множественной регрессии не включены существенно влияющие на результат факторы, либо тем, что установленная линейная форма зависимости не отражает реальной взаимосвязи признаков. Добиться адекватности модели множественной регрессии эмпирическим данным возможно, соответственно, либо включением в уравнение регрессии дополнительных, ранее не учитываемых факторов, либо построением нелинейной модели множественной регрессии.
. Чем ближе его значение к 1, тем точнее уравнение множественной линейной регрессии отражает реальную связь. Иначе говоря, среди отобранных факторов присутствуют те, которые решающим образом влияют на результативный. Малое значение R можно объяснить тем либо тем, что в уравнение множественной регрессии не включены существенно влияющие на результат факторы, либо тем, что установленная линейная форма зависимости не отражает реальной взаимосвязи признаков. Добиться адекватности модели множественной регрессии эмпирическим данным возможно, соответственно, либо включением в уравнение регрессии дополнительных, ранее не учитываемых факторов, либо построением нелинейной модели множественной регрессии.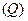 в виде суммы выручки от продажи товара в условиях отчетного периода сравнивается с аналогичным показателем базисного периода, то в итоге получаем индивидуальный индекс выручки (170), показывающий во сколько раз изменилась (или сколько процентов составляет) выручка в отчетном периоде по сравнению с базисным:
в виде суммы выручки от продажи товара в условиях отчетного периода сравнивается с аналогичным показателем базисного периода, то в итоге получаем индивидуальный индекс выручки (170), показывающий во сколько раз изменилась (или сколько процентов составляет) выручка в отчетном периоде по сравнению с базисным:  можно определить соответствующие индивидуальные индексы – цены (172) и количества (173):
можно определить соответствующие индивидуальные индексы – цены (172) и количества (173):  или
или  (182)
(182) . (184)
. (184) ; (186)
; (186) 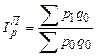 . (187)
. (187)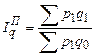 ; (188)
; (188) 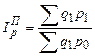 . (189)
. (189)
 ; (190) IQ =
; (190) IQ = 
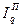 . (191)
. (191)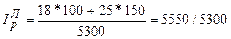 = 1, 0472, то есть цена на яблоки увеличилась в 1, 0472 раза (на 4, 72%).
= 1, 0472, то есть цена на яблоки увеличилась в 1, 0472 раза (на 4, 72%).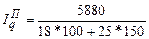 = 1, 0594, то есть количество проданных яблок выросло в 1, 0594 раза (на 5, 94%).
= 1, 0594, то есть количество проданных яблок выросло в 1, 0594 раза (на 5, 94%). ≠
≠  и
и  ≠
≠ 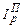 . Американский экономист Гершенкрон обширными расчетами установил, что по одному и тому же фактору индекс Ласпейреса обычно больше индекса Пааше, и это открытие названо эффектом Гершенкрона [56] , то есть
. Американский экономист Гершенкрон обширными расчетами установил, что по одному и тому же фактору индекс Ласпейреса обычно больше индекса Пааше, и это открытие названо эффектом Гершенкрона [56] , то есть  ; (192)
; (192) 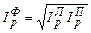 . (193)
. (193)
 Q0. (195)
Q0. (195) (196)
(196)  (197)
(197) ; (198)
; (198) 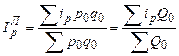 ; (199)
; (199) ; (200)
; (200) 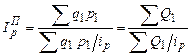 . (201)
. (201)