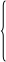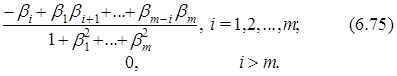|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Непараметрические тесты стационарности
Параметрические критерии проверки стационарности достаточно неудобны в практических исследованиях и весьма ограничены в применении из-за своих достаточно строгих предположений относительно нормальности закона распределения временного ряда уt, t=1, 2,.... Они требуют значительных вычислений. Вместе с тем, реальные временные ряды могут быть распределены по закону, отличающемуся от нормального, и, как это будет показано далее, условие нормальности распределения ряда уt не является обязательным при построении эконометрических моделей, описывающих такие ряды. Вследствие этого на практике при проверке свойств стационарности процессов часто используются непараметрические критерии, которые не имеют подобных ограничений по закону распределения временного ряда уt, да и не столь сложны по своим вычислениям. Тест Манна-Уитни (тестирование математического ожидания). В частности, вместо критерия Стьюдента может быть использован непараметрический критерий Манна-Уитни (критерий и*). Он чуть слабее критерия Стьюдента в случае временных рядов с нормальным распределением, однако имеет неоспоримые преимущества по сравнению с параметрическими критериями в случае, если распределение временного ряда отличается от нормального. Критерий и* применяется для проверки идентичности распределений двух совокупностей (в нашем случае, временных последовательностей одного временного ряда уt, определенных на разных временных частях интервала t=1,..., Т). Предположим, что первая совокупность образована Т1 последовательными значениями уt, а вторая – Т2 его последовательными значениями, и эти последовательности не пересекаются. Все значения этих совокупностей объединяются в один ряд, в котором они располагаются в порядке возрастания с первого по (Т1+Т2)-й вне зависимости от принадлежности к той или иной последовательности. Вместе с тем, в этой единой последовательности символом у1 отметим элементы первой последовательности, а символом у2 – второй. В результате формируется структурный временной ряд, состоящий из Т1+Т2 элементов, в котором символы у1 (Т1 элементов) и символы у2 (Т2 элементов) оказываются перемешанными между собой. Для сформированного таким образом временного ряда возможно Логика теста состоит в следующем. Если ряд стационарный, то последовательности у1 и у2 практически не отличаются одна от другой и их элементы перемешаны между собой. При этом появление каждой из возможных структур имеет равную вероятность. Если же ряд отличается от стационарного, то общая последовательность будет разделена на более или менее однородные массивы, состоящие в основном из единиц той или иной совокупности. Например, элементы совокупностей будут скапливаться на разных концах общей последовательности. Такие структуры в случае, например, увеличивающегося (или уменьшающегося) нестационарного временного ряда будут иметь большую вероятность появления. Соответствующий тест Манна-Уитни осуществляет проверку гипотезы о стационарности временного ряда уt на основе расчета статистики и* (значения критерия), представляющей собой число случаев, когда элементы из совокупности у1 предшествуют элементам совокупности у2. Иными словами, значение и* равно количеству элементов из у1, предшествующих наименьшему по величине элементу из у2, плюс количество элементов из у1, предшествующих следующему за ним элементу из у2, включая и ранее уже учтенные элементы первой совокупности и т. д., пока не будет включено в сумму количество элементов из у1, предшествующих последнему элементу из у2. На практике значение и* рассчитывается либо через сумму рангов элементов первой совокупности, либо через сумму рангов элементов второй совокупности, с которыми оно связано следующими соотношениями:
где R1 и R2 – суммы рангов элементов первой и второй совокупностей соответственно, определяемых по их общей последовательности. Для больших последовательностей (Т> 50; 100) случайная величина и* распределена по нормальному закону с математическим ожиданием
и дисперсией
Таким образом, случайная величина z, определяемая как
является нормированной величиной с нулевым средним и единичной дисперсией, распределенной по стандартизованному нормальному закону, z~N(0, 1). В формуле (6.31) поправка 1/2 вводится для обеспечения непрерывности величины z. Она прибавляется, если z< 0, и вычитается, при z> 0. Таким образом, если обе совокупности идентичны, и их элементы будут перемешаны между собой, то можно ожидать, что значения и* будут находиться недалеко от своего среднего уровня (соответственно z – около нуля). Гипотеза о стационарности процесса уt, t=1, 2,..., Т в этом случае может быть принята с доверительной вероятностью p*, если будет выполнено следующее неравенство
где х1 и х2 определяются из следующего равенства: х2
х1
где В частности, при p*=0, 95, расчетное значение z должно находиться в следующем интервале:
–1, 96£ z£ 1, 96.
Тест Сиджела-Тьюки. Вместо параметрического критерия Фишера (F-критерия) для проверки гипотезы о постоянстве дисперсии временного ряда уt на интервале t=1, 2,..., Т может быть использован непараметрический критерий Сиджела-Тьюки, который также основан на сопоставлении рангов элементов двух совокупностей из рассматриваемого интервала. Тест проверки этой гипотезы состоит в следующем. Исходный временной ряд уt, t=1, 2,..., Т центрируется, т. е. определяются значения Таким образом, в таблице номера рангов увеличиваются от краев к центру согласно следующей закономерности: нечетные номера (отрицательных элементов) – сверху к центру; четные (положительных элементов) – снизу к центру. Рассчитанная на основе этих рангов случайная величина w* оказывается приблизительно распределенной по нормальному закону с математическим ожиданием, оцениваемым как
и дисперсией
где R1 – сумма рангов элементов первой совокупности у1, Т1+Т2 – количество элементов в первой и второй совокупности соответственно. Из выражений (6.33) и (6.34) непосредственно следует, что нормированная случайная величина z, определяемая как
распределена по нормальному стандартизованному закону с нулевым средним и единичной дисперсией. Здесь также поправка 1/2 вводится для обеспечения непрерывности z. Она добавляется при z< 0, и вычитается при z> 0. Гипотеза о равенстве дисперсий рассмотренных совокупностей принимается, если для z удовлетворяется соотношение (6.32). Сериальные критерии стационарности. Для проверки гипотезы о стационарном характере процесса (имеется в виду стационарность второго порядка) может быть использованы достаточно универсальные относительно закона распределения значений ряда уt, t=1, 2,..., Т непараметрические тесты, основанные на анализе закономерностей серий этих значений (сериальные критерии). Необходимым условием их применения является достаточно большой объем временного ряда, что позволяет с определенной обоснованностью считать обнаруженные закономерности устойчивыми (характерными для данного ряда). При этом серией называют последовательность значений, предшествующая или следующая за некоторым значением, характерный признак которого отличается от признака элементов, входящих в серию. В качестве такого признака часто рассматривается расположение элемента последовательности относительно ее медианы. В этом случае серии с положительным знаком образуют элементы по уровню выше медианы, и серии с отрицательным знаком – элементы, чей уровень не превосходит медианы. Здесь следует иметь в виду, что один элемент – это тоже серия. Примером сериального критерия является критерий Вальда-Вольфовитца, основанный на подсчете общего числа серий. Среднее значение числа серий определяется согласно следующему выражению:
а его дисперсия – согласно формуле
где N1 – количество элементов с положительным знаком; N2 – количество элементов с отрицательным знаком. N1+N2=Т – количество элементов во временном ряду. Ns – число серий. При большом объеме временного ряда Т нормированная переменная z , определяемая как
распределена по стандартизованному нормальному закону N(0, 1). В этом случае для проверки гипотезы о стационарности используется двухсторонний критерий (6.32). 6.1.3. Преобразование нестационарных временных рядов в стационарные Реальные процессы свойством стационарности второго порядка могут и не обладать. Однако с помощью достаточно несложных преобразований часто удается привести наблюдаемый ряд к стационарному процессу. Примерами таких преобразований являются: а) взятие конечных разностей
D yt – первая разность. Это преобразование целесообразно использовать, когда закон изменения yt близок к линейному.
D хt – вторая разность. Преобразование применяется, когда закон изменения yt близок к квадратической зависимости и т. д.; б) логарифмирование цепных индексов
Применяется при экспоненциальном росте уt, t =1, 2,..., Т; в) расчет темпов прироста
а также некоторые другие. Заметим, что преобразование (6.41) предоставляет исследователю несколько большие “удобства” в формировании исходной информации по сравнению с другими. Это связано с тем, что оно позволяет достаточно просто изменять временные серии исходных данных в связи, например, с укрупнением временных интервалов. В самом деле, предположим, что возникла необходимость проанализировать временные ряды серии удвоенного временного интервала (t–1, t+1), т. е., например, у1, у3, у5,..., уt–1, уt +1,.... Для такой серии преобразование (6.41) приводит к следующему временному ряду:
где хt+1, 2 – преобразованное значение показателя на удвоенном интервале. Его величина представляет собой простую арифметическую сумму преобразованных значений показателей исходных интервалов, объединение которых привело к новой серии. В то же время для преобразования (6.42) в этом случае получим более сложное выражение, определяющее для значения нового временного ряда:
Для превращения исходного нестационарного ряда в стационарный могут быть использованы и другие преобразования. Например, хt=lnуt, В условиях постоянства математического ожидания и дисперсии особенности конкретного стационарного процесса второго порядка полностью определяются характером его автокорреляционной функции, имеющей вид зависимости значений коэффициентов автокорреляции от сдвига. Иными словами, автокорреляционная функция является дискретной и представляет собой последовательность значений коэффициентов автокорреляции r0, r1,..., ri–1,..., поставленных в зависимость от сдвига i, где r0=1, –1£ ri£ 1, i=1, 2,.... Аналогично можно сформировать автоковариационную функцию стационарного процесса уt, представив ее в виде последовательности коэффициентов автоковариаций g0, g1,..., gi,..., поставленных в зависимость от сдвига i. Напомним, что между соответствующими значениями этих функций существует однозначная взаимосвязь gi =ri × s y2, i=0, 1,..., т. е. g 0=s y2. Автокорреляционную функцию можно представить как проекцию диагональных элементов автокорреляционной матрицы на ось сдвигов (см. рис. 6.1). Все множество стационарных процессов второго порядка в общем случае в зависимости от особенностей их автокорреляционных функций разбивается на несколько однородных групп, для каждой из которых можно подобрать и построить адекватную модель. В общем случае можно выделить три группы таких моделей – модели авторегрессии (autoregressive), модели скользящего среднего (moving average) и смешанные модели авторегрессии-скользящего среднего (autoregressive- moving average).
0 –1 Рис. 6.1
Вопросы их построения рассмотрены в последующих разделах данной главы. Модели авторегрессии Использование моделей авторегрессии при моделировании закономерностей реального стационарного процесса второго порядка, допускающего представление в виде дискретного временного ряда его значений, основано на предположении о том, что текущее значение такого процесса может быть выражено в виде линейной комбинации некоторого количества предыдущих его значений и случайной ошибки, обладающей свойствами белого шума. Общий вид модели авторегрессии k-го порядка – АР(k) может быть выражен следующим уравнением:
где уt, уt–i, i=1, 2,..., k – значения переменной у в соответствующие моменты времени; k – порядок модели; a1,..., ak – коэффициенты модели; et – случайная ошибка с нулевым математическим ожиданием, конечной дисперсией и единичной автокорреляционной матрицей, свидетельствующей об отсутствии автокорреляционной связи между рядами ошибки et, et–1,..., et–i,..., т. е. et ~N(0, se2), Cov ( e )=se2 × E. Построение модели АР(k) типа (6.45), адекватной реальному временному ряду уt, t=1, 2,..., Т, предполагает решение двух взаимосвязанных задач: определения рационального порядка модели (величины k) и оценки значений ее коэффициентов. Рассмотрим сначала общие подходы к оценке параметров модели типа (6.45). Без ограничения общности будем предполагать, что математическое ожидание ряда уt равно нулю, т. е. M[уt ]=0. В противном случае вместо переменной уt в выражении (6.45) можно рассмотреть центрированную переменную Из выражения (6.45) непосредственно следует, что параметры модели a1,..., ak могут быть выражены через коэффициенты автокорреляции. Чтобы показать это, умножим выражение (6.36) под знаком математического ожидания на переменную уt–i, i=1, 2,..., k. Получим
где M[уt-i, уt--j] – математическое ожидание произведения двух центрированных переменных уt–i, уt–j, представляющих собой их ковариацию gr, на практике оцениваемую по формуле
где r=i–j, i ³ j. В результате для i=1, 2,..., k вместо (6.46) можно записать
Выражение (6.48) получено в предположении, что M[уt-i, et]=0 при i> 0, так как et – случайная величина со свойствами “белого шума”, не имеющая корреляционной связи с предшествующими моменту t значениями рассматриваемого процесса уt. Разделив левую и правую части выражения (6.48) на дисперсию процесса уt sу2=g 0, получим следующее выражение:
которое связывает коэффициенты автокорреляции процесса уt и коэффициенты модели АР(k). Подставив в (6.49) вместо истинных значений коэффициентов автокорреляции ri процесса уt их выборочные оценки r1, r2,..., последовательно для i=1, 2,..., k, получим следующую систему линейных уравнений:
в которой известными являются оценки коэффициентов автокорреляции r1, r2,..., rk, а неизвестными – оценки коэффициентов модели АР(k) a1 , a2 ,..., ak. Систему (6.50) называют уравнениями Юла-Уокера, а полученные на ее основе значения a1, a2,..., ak – оценками коэффициентов модели авторегрессии АР(k) Юла-Уокера. Напомним, что эти оценки могут быть получены, например, с использованием определителей, либо на основе векторно-матричной формы записи системы (6.50). На основе определителей оценки Юла-Уокера получают в следующем виде:
где D – определитель системы (6.41).
Di – определитель, получаемый из определителя D путем замены его i-го столбца на столбец, состоящий из коэффициентов автокорреляции, образующих левую часть системы (6.50) – r1, r2,..., rk. В векторно-матричной форме записи систему (6.50) можно переписать в следующем виде:
r = R × a, (6.53)
где r – вектор-столбец известных оценок коэффициентов автокорреляции с первого по k-й включительно, r =(r1, r2, ..., rk)¢; a – вектор-столбец неизвестных оценок параметров модели, a =(a1, a2,..., ak)¢; R – матрица, составленная из оценок коэффициентов автокорреляции, определитель которой выражен формулой (6.52). Непосредственно из выражения (6.53) вытекает, что неизвестные оценки коэффициентов модели авторегрессии определяются как a = R –1× r. (6.54)
Теоретически оценки Юла-Уокера должны обладать свойствами несмещенности и эффективности. Однако, на практике, в моделях авторегрессии большого порядка эти свойства могут не подтверждаться. Особенно это относится к свойству несмещенности. Как и в моделях с лаговыми зависимыми переменными, смещенность в оценках коэффициентов моделей авторегрессии может быть обусловлена существующей зависимостью между сдвинутыми рядами рассматриваемой переменной у t–1, у t–2 и ошибкой e t. Этой возможной зависимостью при построении системы уравнений Юла-Уокера обычно пренебрегают, полагая et белым шумом. Неэффективность оценок может быть вызвана плохой обусловленностью матрицы R, что, как правило, является свидетельством зависимости уже между рядами у t–1, у t–2,.... Вместе с тем, при небольших порядках модели (k =1, 2, 3) оценки Юла-Уокера обычно являются достаточно “хорошими”. В крайнем случае их можно рассматривать как первое приближение к “оптимальным” оценкам, которые могут быть получены путем уточнения оценок Юла-Уокера на основе использования более мощных методов оценивания, например, нелинейных. Качество оценок Юла-Уокера может быть проверено путем исследования свойств ряда ошибки et, t=1, 2,..., Т. Если ее свойства близки к характеристикам “белого шума”, то оценки Юла-Уокера можно считать “достаточно хорошими”. Об этом, в частности, может свидетельствовать критерий Дарбина-Уотсона, значение которого должно лежать примерно в интервале от 1 до 3 (см. раздел 1.4). Для этих целей могут использоваться и другие мощные критерии, например, Бартлетта, Тейла. Обоснование целесообразности применения моделей авторегрессии. Целесообразность использования моделей авторегрессии в анализе закономерностей временного ряда обычно устанавливается на основе сопоставления двух дисперсий – дисперсии исходного процесса sу2 и дисперсии ошибки модели se2. Для того чтобы выявить взаимосвязь между двумя этими характеристиками положим, что в формуле (6.48) i=0. Тогда это выражение можно переписать в следующем виде:
где g0=sу2, gi – i-й коэффициент автоковариации. Последнее слагаемое в правой части выражения (6.55) получено путем замены в выражении (6.46) в произведении M[yt× × et] переменной yt на ее модель (6.45). Поскольку ряды у t–1,..., у t–k и e t являются независимыми, то это произведение оказывается равным se2. Далее, поскольку gi =ri× g0, то выразив все gi, i=1, 2,..., k через g0и перенеся слагаемые с g0в левую часть, из выражения (6.55) получим
Подставив в (6.56) вместо ri значения оценок коэффициентов автокорреляции ri и вместо параметров модели ai их оценки аi, i=1, 2,..., k, найдем величину соотношение между дисперсией процесса sу2 и дисперсией ошибки описывающей этот модели авторегрессии (белого шума) se2.
Модель авторегрессии считается “достаточно хорошей”, если sу2> > se2, т. е. когда дисперсия ошибки модели много меньше дисперсии процесса. В этом случае использование модели при описании процесса yt позволяет значительно снизить его неопределенность, выражаемую через дисперсию sу2. Здесь также следует отметить, что в моделях временных ярдов нельзя ожидать значительного уменьшения дисперсии ошибки se2 по сравнению с дисперсией процесса sу2, как это имело место в моделях “классической” эконометрики, где отношение sу2/se2 нередко превосходит несколько десятков. Чтобы показать это, рассмотрим свойства наиболее часто используемых в практике финансовых исследований моделей авторегрессии первого и второго порядков. Модели АР(1) и АР(2). Модель авторегрессии первого порядка АР(1) записывается в следующем виде:
Легко видеть, что система Юла-Уокера в этом случае сводится к одному уравнению, непосредственно определяющему оценку a1 коэффициента a1 a1=r1. (6.59)
Из выражения (6.57) вытекает, что
Поскольку ½ r1½ < 1, то из (6.60) следует, что, например, при r1=0, 9 se2»0, 2× sу2. Это означает, что использование расчетных значений процесса yt, определяемых по формуле Модель авторегрессии второго порядка – АР(2) представляется в виде следующего уравнения:
Система уравнений Юла-Уокера в этом случае состоит из двух уравнений
Выразив a1 и a2 через коэффициенты автокорреляции с использованием, например, метода определителей (6.51), получим
Из выражения (6.57) непосредственно вытекает, что в этом случае соотношение между дисперсиями исходного процесса yt и ошибкой модели et определяется следующим выражением:
На практике и в случае АР(2) соотношение между sу2 и se2 обычно не превосходит 5: 1. В этом смысле следует отметить, что по сравнению с эконометрическими моделями, где это соотношение достигает 50 к 1 и даже 100 к 1, модели авторегрессии, на первый взгляд, не обладают высокой точностью описания рассматриваемых процессов. Однако не следует забывать, что в “классической” эконометрике зависимая переменная yt не обладает свойством стационарности и она характеризуется гораздо большей изменчивостью (и, как следствие, дисперсией) по сравнению со стационарным временным рядом. Поэтому адекватные рассматриваемому процессу многофакторные эконометрические модели могут значительно уменьшить остаточную изменчивость (дисперсию ошибки) по сравнению с исходной (дисперсией процесса), но при этом изменчивость ошибки может оставаться относительно большой. Модели же авторегрессии, как и другие модели стационарных временных рядов, как бы уточняют” исходный процесс yt, как правило, благодаря свойству стационарности не отличающийся значительной изменчивостью. Вследствие этого у этих моделей имеется лишь незначительный резерв для уменьшения исходной дисперсии sу2 по сравнению с многофакторными эконометрическими моделями, описывающими нестационарные процессы. Автокорреляционная функция моделей авторегрессии. По аналогии с реальными стационарными процессами, автокорреляционные функции могут быть сформированы и для их теоретических аналогов – моделей авторегрессии. Заметим, что значения коэффициентов автокорреляции модели k-го порядка связаны между собой соотношением (6.49). Несложно заметить, что для модели авторегрессии первого порядка это соотношение приводит к следующей зависимости между коэффициентами автокорреляции:
В самом деле, из выражения (6.58)) для i=2 имеем r2=a1r1 и, учитывая, что a1=r1, получим r2=r12, аналогично, для i=3 имеем r3=a1r2=r13 и т.д. Если учесть, что ô r1ô < 1, то нетрудно заметить, что модули значений коэффициентов автокорреляции модели АР(1) авторегрессии уменьшаются по экспоненте с ростом сдвига i. Можно показать, что поскольку модель авторегрессии второго порядка является стационарным процессом, то ее автокорреляционная функция представляет собой либо затухающую экспоненту, либо затухающую синусоиду. В первом случае абсолютные значения коэффициентов автокорреляции ri с ростом i уменьшаются согласно следующей зависимости:
где d – положительный коэффициент экспоненциальной зависимости, отличный от единицы, d ¹ 1. Заметим, что для модели АР(1) этот коэффициент равен единице (см. выражение (6.65)). Во втором случае значения коэффициентов ri аппроксимируются функцией следующего вида:
где f и F – параметры синусоиды (частота и фаза соответственно), рассчитываемые на основе значений коэффициентов модели. В частности,
Модели скользящего среднего В моделях скользящего среднего текущее значение стационарного случайного процесса второго порядка yt представляется в виде линейной комбинации текущего и прошедших значений ошибки et, et–1, et–2,..., по своим свойствам соответствующей “белому шуму”. Такое представление может быть выражено следующим уравнением (модель скользящего среднего порядка m – СС(m)):
где b1, b2,..., bm – параметры модели. В соответствии с определением белого шума ошибка et характеризуется следующими свойствами:
gi=M[et , et–i ] =
Вследствие этого и автокорреляционная функция белого шума имеет очень простую форму
ri(e)=1, i=0; ri(e)=0, i¹ 0. (6.70)
С учетом свойств ошибки et несложно построить автокорреляционную функцию модели СС(т), определяемой выражением (6.68). Ее коэффициент ковариации i-го порядка определяется следующим образом:
При i=0 выражение (6.71) представляет собой дисперсию процесса yt, которая в силу свойства (6.69) выражается через коэффициенты модели СС(т) bi, i=1, 2,..., т; и дисперсию ошибки se2 следующим образом:
Для i=1 из (6.72) получим, что первый коэффициент ковариации определяется выражением
Для произвольного i имеем
Из соотношения (6.74) вытекает, что автокорреляционная функция модели СС(т) становится равной нулю после задержки т (обрывается на задержке т). С учетом выражений (6.72) и (6.74) несложно также заметить, что коэффициенты автокорреляции модели скользящего среднего т-го порядка – СС(т) определяются через ее параметры bi, i=1, 2,..., т; следующим образом:
Система из т уравнений (6.75), сформированных для i=1, 2,..., т может служить основой для получения оценок b1, b2,..., bm неизвестных параметров модели СС(т) – b1, b2,..., bm. Для этого необходимо подставить в каждое ее уравнение вместо значений коэффициентов автокорреляции r1,..., rm рассматриваемого процесса yt их рассчитанные оценки r1,..., rm. Однако в отличие от уравнений Юла-Уокера эта система нелинейная и ее решение требует использования специальных итеративных процедур расчетов за исключением наиболее простой модели СС(1). Она представляется следующим выражением:
Из (6.72) следует, что дисперсии процесса sу2 и ошибки этой модели se2 связаны следующим соотношением:
а ее единственный отличный от нуля первый коэффициент автокорреляции выража< Популярное:
|
Последнее изменение этой страницы: 2016-03-25; Просмотров: 1829; Нарушение авторского права страницы
 различных структур, под которыми понимаются последовательности с различающимися порядками следования элементов из первой и второй совокупностей. Иными словами, структуры, у которых изменились места элементов одной и той же совокупности различными не считаются.
различных структур, под которыми понимаются последовательности с различающимися порядками следования элементов из первой и второй совокупностей. Иными словами, структуры, у которых изменились места элементов одной и той же совокупности различными не считаются.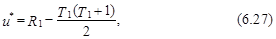





 ò
ò 
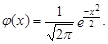
 , где
, где  – среднее значение ряда уt. Далее интервал (1, Т) разделяется на две части (желательно равные), так что на первой из них располагаются элементы первой центрированной совокупности у1, а на второй – элементы второй совокупности – у2. Далее элементы из двух центрированных совокупностей у1 и у2 объединяются в одной таблице с запоминанием “своей совокупности” согласно следующему правилу ранжирования. Ранг 1 приписывается наименьшему отрицательному значению, которое располагается на первом месте вверху таблицы. Ранг 2 приписывается наибольшему положительному значению, которое располагается на последнем месте внизу таблицы. Ранг 3 приписывается значению следующему за наименьшим, которое располагается на втором месте вверху таблицы. Ранг 4 – значению, следующему за наибольшим, которое располагается в таблице на втором месте снизу. Ранг 5 приписывается третьему по порядку наименьшему значению. Оно располагается в таблице на третьем месте сверху. Ранг 6 приписывается третьему по порядку наибольшему значению, которое располагается на третьем месте таблицы снизу и т. д.
– среднее значение ряда уt. Далее интервал (1, Т) разделяется на две части (желательно равные), так что на первой из них располагаются элементы первой центрированной совокупности у1, а на второй – элементы второй совокупности – у2. Далее элементы из двух центрированных совокупностей у1 и у2 объединяются в одной таблице с запоминанием “своей совокупности” согласно следующему правилу ранжирования. Ранг 1 приписывается наименьшему отрицательному значению, которое располагается на первом месте вверху таблицы. Ранг 2 приписывается наибольшему положительному значению, которое располагается на последнем месте внизу таблицы. Ранг 3 приписывается значению следующему за наименьшим, которое располагается на втором месте вверху таблицы. Ранг 4 – значению, следующему за наибольшим, которое располагается в таблице на втором месте снизу. Ранг 5 приписывается третьему по порядку наименьшему значению. Оно располагается в таблице на третьем месте сверху. Ранг 6 приписывается третьему по порядку наибольшему значению, которое располагается на третьем месте таблицы снизу и т. д.













 и т. д. В каждом конкретном случае, выбирая преобразование, необходимо исходить из примерной формы временного графика зависимости уt. “Удачное” преобразование должно обеспечивать приблизительное выполнение условия xt=f(уt)»const.
и т. д. В каждом конкретном случае, выбирая преобразование, необходимо исходить из примерной формы временного графика зависимости уt. “Удачное” преобразование должно обеспечивать приблизительное выполнение условия xt=f(уt)»const. r0 r1 r2 r3 r4 r5 i
r0 r1 r2 r3 r4 r5 i r0 1 0, 9 0, 6 0, 3 –0, 2 0, 1
r0 1 0, 9 0, 6 0, 3 –0, 2 0, 1 r–1 0, 9 1 0, 9 0, 6 0, 3 –0, 2
r–1 0, 9 1 0, 9 0, 6 0, 3 –0, 2 r–2 0, 6 0, 9 1 0, 9 0, 6 0, 3
r–2 0, 6 0, 9 1 0, 9 0, 6 0, 3
 r–3 0, 3 0, 6 0, 9 1 0, 9 0, 6 5
r–3 0, 3 0, 6 0, 9 1 0, 9 0, 6 5
 r–4 –0, 2 0, 3 0, 6 0, 9 1 0, 9 3
r–4 –0, 2 0, 3 0, 6 0, 9 1 0, 9 3
 r–5 0, 1 –0, 2 0, 3 0, 6 0, 9 1 1
r–5 0, 1 –0, 2 0, 3 0, 6 0, 9 1 1
 ,
,  , где
, где  – оценка M[уt ]. Легко видеть, что M[
– оценка M[уt ]. Легко видеть, что M[ 


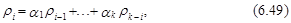




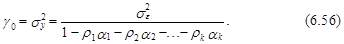



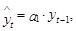 вместо среднего значения временного ряда
вместо среднего значения временного ряда 






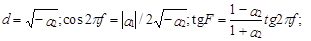
 если a1 > 0 и
если a1 > 0 и  если a1 < 0.
если a1 < 0.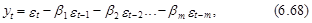
 M[et]=0, D(et)=se2=const,
M[et]=0, D(et)=se2=const,